 詳解基于深度學習的偽裝目標檢測
詳解基于深度學習的偽裝目標檢測
最后是O2OGM模塊,將Conv6-3提取的顯著性目標特征信息與Conv2-2提取的邊緣特征結合后的特征分別與Conv3-3、Conv4-3、Conv5-3、Conv6-3每層提取的顯著性目標特征進行融合,即圖中FF模塊的操作。FF操作很簡單,就是將高層特征上采樣然后進行拼接的操作,就可以達到融合的效果。
PFANet的結構相對簡單,采用VGG網絡作為特征提取網絡,然后將前兩層特征稱為低層特征,后三層特征稱為高層特征,對他們采用了不同的方式進行特征增強,以增強檢測效果。
首先是對于高層特征,先是采用了一個CPFE來增大感受野,然后再接一個通道注意力模塊,即完成了對高層特征的特征增強(這里的這個CPFE,其實就是ASPP)。
然后再對經過了CPFE后的高層特征使用通道注意力(CA)。
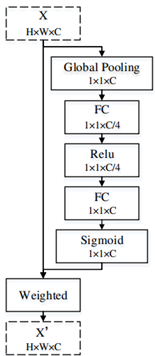
以上即是高層特征的增強方法,而對于低層特征,處理得則更為簡單,只需要使用空間注意力模塊(SA),即可完成。
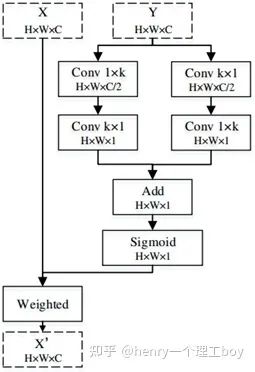
整個PFANet的網絡結構很清晰,如下圖所示。
介紹完EGNet和PFANet兩種方法以后,就剩下SINet了。SINet的思路來自于19年的一篇CVPR的文章《.Cascaded partial decoder for fast and accurate salient object detection》。這篇文章里提出了CPD的這樣一個結構,具體的可以取搜索一下這篇論文,詳細了解一下。
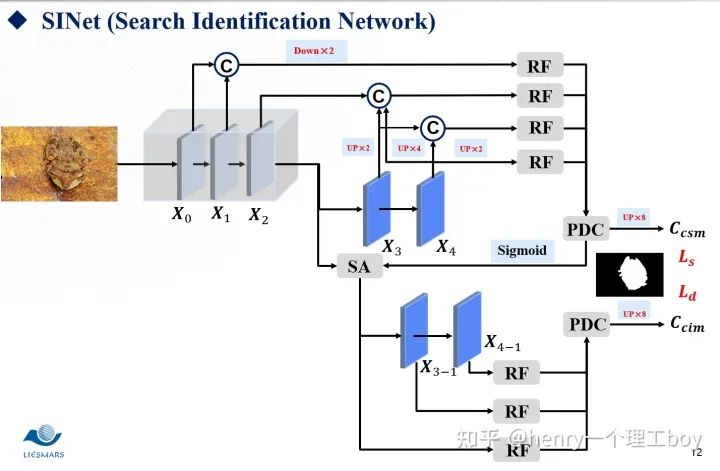
接下來我將介紹一個用于偽裝目標檢測的網絡SINet。假設你是一頭饑腸轆轆的雄獅,此刻你掃視著周圍,視線突然里出現了兩匹斑馬,他們就是你今天的獵物,美食。確定好了目標之后,那么就開始你的獵殺時刻。所以整個過程是你先掃視周圍,我們稱之為搜索,然后,就是確認目標,開始獵殺,我們稱之為確認。我們的SINet就是這樣的一個結構,他分為搜索和確認兩個模塊,前者用于搜索偽裝目標,后者用于精確定位去檢測他。
我們現在就具體來看看我們的SINet到底是怎么一回事。首先,我們都知道低層特征有著較多的空間細節,而我們的高層特征,卻有著較多的語義信息。所以低層的特征我們可以用來構建目標區域,而高層特征我們則可以用來進行目標定位。我們將這樣一張圖片,經過一個ResNet的特征提取器。按照我們剛才的說法,于是我們將前兩層稱為低層特征,最后兩層稱之為高層特征,而第三層我們稱之為中層特征。那么有了這樣的五層特征圖,東西已經給我們了?我們該怎么去利用好這些東西呢?
首先是我們的搜索模塊,通過特征提取,我們得到了這么一些特征,我們希望能夠從這些特征中搜索到我們想要的東西。那我們想要的是什么呢?自然就是我們的偽裝線索了。所以我們需要對我們的特征們做一些增強的處理,來幫助我們完成搜索的這樣一個任務。而我們用到的方法就是RF。我們來看一下具體是怎么樣實現的。首先我們把整個模塊分為5個分支,這五個分支都進行了1×1的卷積降維,我們都知道,空洞卷積的提出,其目的就是為了增大感受野,所以我們對第一個分支進行空洞數為3的空洞卷積,對第二個分支進行空洞數為5的空洞卷積,對第3個分支進行空洞數為7的空洞卷積,然后將前四個分支的特征圖拼接起來,這時候,我們再采用一個1×1卷積降維的操作,與第五個分支進行相加的操作,最后輸出增強后的特征圖。

這個RF的結構來自于ECCV2018的一篇論文《 Receptive field block net for accurate and fast object detection》,其作用就是幫助我們獲得足夠的感受野。
我們用RF對感受野增大來進行搜索,那么搜索過后,我們得到了增強后的候選特征。我們要從候選特征得到我們最后要的偽裝目標的檢測結果,這里我們用到的方法是PDC模塊(即是部分解碼組件)。
具體操作是這樣的,所以接下來就應該是對它們進行處理了逐元素相乘方式來減少相鄰特征之間的差距。我們把RF增強后的特征圖作為輸入,輸入到網絡里面。首先對低層的進行一個上采樣,然后進行3×3的卷積操作(這里面包含了卷積層,BN層還有Relu層),然后與更高一層的特征圖進行乘法的這樣一個操作,我們為什么使用逐元素相乘呢?因為逐元素相乘方式能減少相鄰特征之間的差距。然后我們再與輸入的低層特征進行拼接。
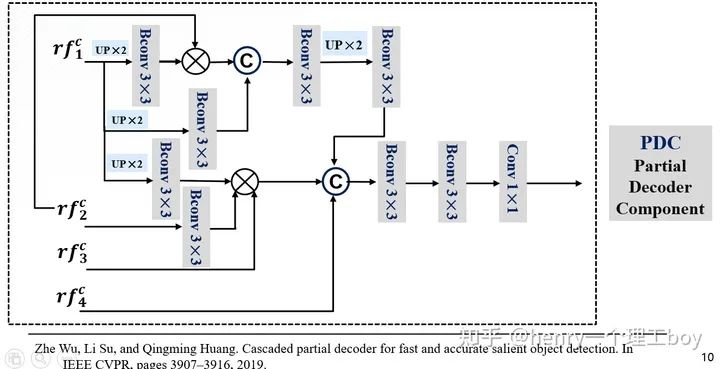
我們前面提到了,我們利用增強后的特征通過PDC得到了我們想要得到的檢測結果,但這樣的一個結果足夠精細嗎?其實,這樣得到的檢測結果是比較粗略的。這是為什么呢?這是因為我們的特征之間并不是有和偽裝檢測不相關的特征?對于這樣的多余的特征,我們要消滅掉。我們將前面得到的檢測圖稱之為,而我們要得到精細的結果圖,就得使用我們的注意力機制了。這里我們引入了搜索注意力,具體是怎么實現的呢?大家想一想我們前面把特征分成了低層特征、高層特征還有中層特征。我們平時一般都叫低層特征和高層特征,很少有提到中層特征的。其實我們這里這樣叫,是有打算的,我們認為中層特征他既不像低層特征那么淺顯,也不像高層特征那樣抽象,所以我們對他進行一個卷積操作(但是我們的卷積核用的是高斯核函數方差取32,核的尺寸我們取為4,我們學過數字圖像處理,都知道這樣的一個操作能起到一個濾波的作用,我們的不相關特征能被過濾掉)但是有同學就會問了,那你這樣一過濾,有用的特征不也過濾掉了嗎?基于這樣的考慮,我們把過濾后的特征圖與剛才的這個再來做一個函數,什么函數呢?就是一個最大化函數,這樣我們不就能來突出偽裝圖初始的偽裝區域了嗎?
SINet整體的框架如圖所示:
講了這么多,我們最后來看看實驗的效果,通過對這三篇文章的復現,我得到了下面的這樣一些結果。
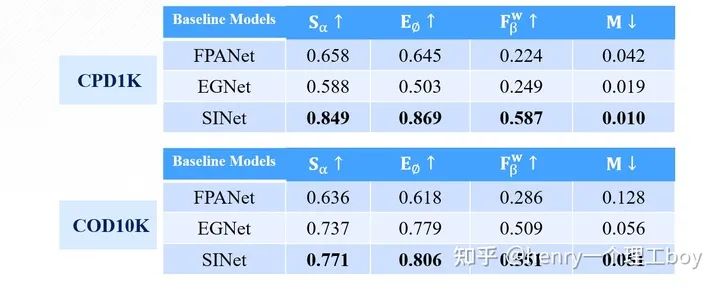
可以看出,在精度指標的評價方面,SINet相比于其他兩種方法都有很大提升,而PFANet模型結構雖然很簡單,但他的效果也是最差的。
下面我們再看看可視化的效果:
責任編輯:lq
-
模塊
+關注
關注
7文章
2730瀏覽量
47650 -
檢測
+關注
關注
5文章
4509瀏覽量
91653 -
深度學習
+關注
關注
73文章
5511瀏覽量
121392
原文標題:詳解基于深度學習的偽裝目標檢測
文章出處:【微信號:cas-ciomp,微信公眾號:中科院長春光機所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI模型部署邊緣設備的奇妙之旅:目標檢測模型
慧視小目標識別算法 解決目標檢測中的老大難問題

深度學習在工業機器視覺檢測中的應用
基于深度學習的無人機檢測與識別技術
基于AI深度學習的缺陷檢測系統
深度學習在視覺檢測中的應用
基于深度學習的小目標檢測
深度學習模型訓練過程詳解
深入了解目標檢測深度學習算法的技術細節

深度解析深度學習下的語義SLAM



陸基條件下典型地物和偽裝光譜影響因子分析1.0

在ELF 1 開發板上實現讀取攝像頭視頻進行目標檢測






 工商網監
工商網監
評論