") 國產(chǎn)AI卷翻硅谷,奧特曼發(fā)文“陰陽”,類o1模型都在卷什么?
國產(chǎn)AI卷翻硅谷,奧特曼發(fā)文“陰陽”,類o1模型都在卷什么?

兩個(gè)國產(chǎn)推理模型的發(fā)布,讓全球AI圈“提前過年”了。
前兩天,月之暗面推出了Kimi k1.5多模態(tài)思考模型,DeepSeek也發(fā)布了DeepSeek-R1文本推理模型,二者都在推理能力上對標(biāo)OpenAI正式版o1。
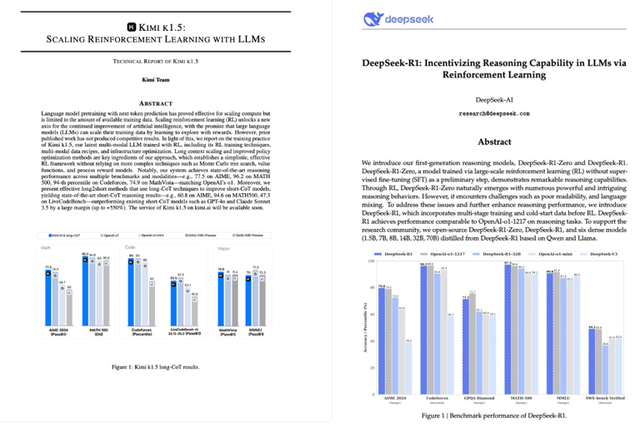
不到兩個(gè)月,國產(chǎn)推理模型就實(shí)現(xiàn)了對OpenAI o1滿血版(2024年12月上線)的對標(biāo),而且與OpenAI藏著掖著的技術(shù)秘訣不同,兩家中國公司雙雙公開了他們的特色技術(shù)道理:DeepSeek R1的極高性價(jià)比,kimi k1.5原創(chuàng)技術(shù)long2short 高效思維鏈+原生多模態(tài)。
因此Kimi/DeepSeek“雙子星”一夜卷翻硅谷,技術(shù)報(bào)告paper一放出,就吸引了大量海內(nèi)外同行的關(guān)注和解讀,在github的熱度飆升。
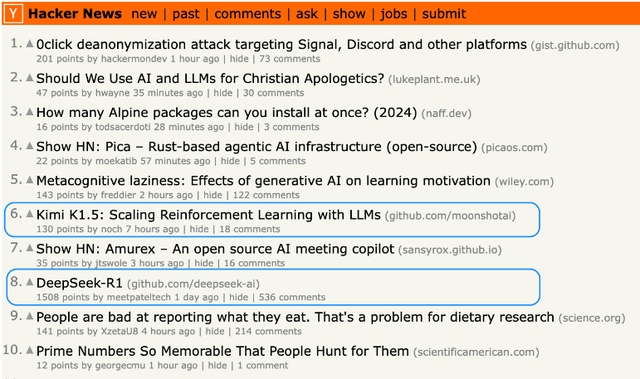
目前來看,海外同行的反饋以振奮為主流。比如Answera公司的創(chuàng)始人保羅·庫弗特(Paul Couvert)就感嘆,兩款中國o1同日發(fā)布,(中國AI)追趕速度越來越快了!

當(dāng)然,自然也少不了“潑冷水”的。
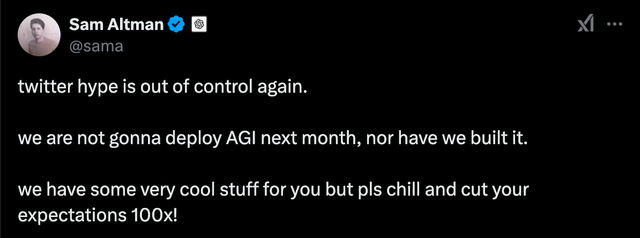
OpenAI CEO奧特曼在社交媒體說,“twitter hype is out of control”(推特上的各種炒作已經(jīng)失控了)。他認(rèn)為外界猜測的“AI即將取代大部分中層崗位”(主要靠推理模型)過度夸大了。希望大家冷靜下來,把期待值降低100倍(cut your expectations 100x)。
或許有人好奇,國產(chǎn)推理模型真的崛起了嗎?大模型技術(shù)如何從“規(guī)模擴(kuò)展”發(fā)展到“推理擴(kuò)展”?對于推理模型這個(gè)路線,我們到底該保持興奮還是冷靜一下?本文就來給大家一一解讀。

兩個(gè)中國AI公司的新模型,吸引了全球海內(nèi)外同行的高度關(guān)注。原因很簡單,推理模型太火了。
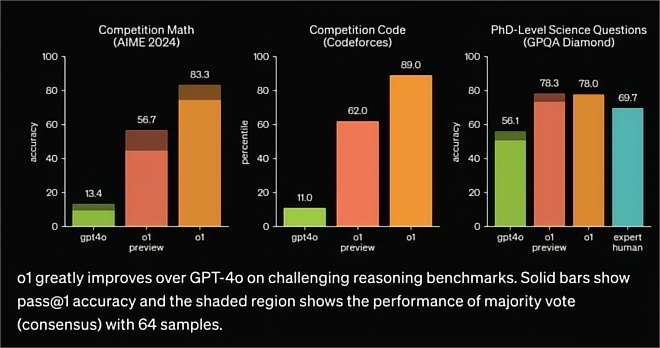
2024年第四季度,出現(xiàn)了reasoning model的新形態(tài)LLM,采用思維鏈進(jìn)行“慢思考”,在推理階段投入更多計(jì)算(推理拓展思路),這種創(chuàng)新帶給大模型超前的推理能力,可以減少幻覺,提高可靠性,處理更為復(fù)雜的任務(wù),達(dá)到人類專家/研究生級別的智能,被認(rèn)為是規(guī)模拓展Scaling Law撞墻后最具潛力的新技術(shù)。
o1系列之后,頭部模廠都開始向“慢思考”的推理模型技術(shù)路線投入,包括大廠谷歌、百度、阿里、科大訊飛、夸克,以及AI六小虎中的智譜、DeepSeek、階躍星辰等,此前也都推出過準(zhǔn)o1的推理模型,但一直沒有全面對標(biāo)正式版o1的國產(chǎn)推理模型。
要證明國產(chǎn)推理模型的崛起,有兩個(gè)前提條件:一是經(jīng)得起全球同行的審視;二是具備原創(chuàng)能力而非簡單跟隨,全面對標(biāo)而非部分達(dá)標(biāo)。
目前來看,Kimi k1.5/ DeepSeeK R1達(dá)到了上述條件。
Kimi k1.5/ DeepSeeK R1首次真正對標(biāo)了正式版o1,取得了SOTA成績。其中,k1.5還是國內(nèi)首個(gè)多模態(tài)o1,同時(shí)支持文本和圖像推理。這在全球推理模型領(lǐng)域都是比較亮眼的成績。
而且,不同于OpenAI o1藏著掖著的風(fēng)格,Kimi和DeepSeeK都發(fā)布了詳細(xì)的技術(shù)報(bào)告,分享模型訓(xùn)練技術(shù)的探索經(jīng)驗(yàn),立刻在海外AI圈掀起了解讀論文的熱潮。
比如英偉達(dá)的研究科學(xué)家第一時(shí)間開扒,得出的結(jié)論是,Kimi和DeepSeeK的研究“振奮人心”。
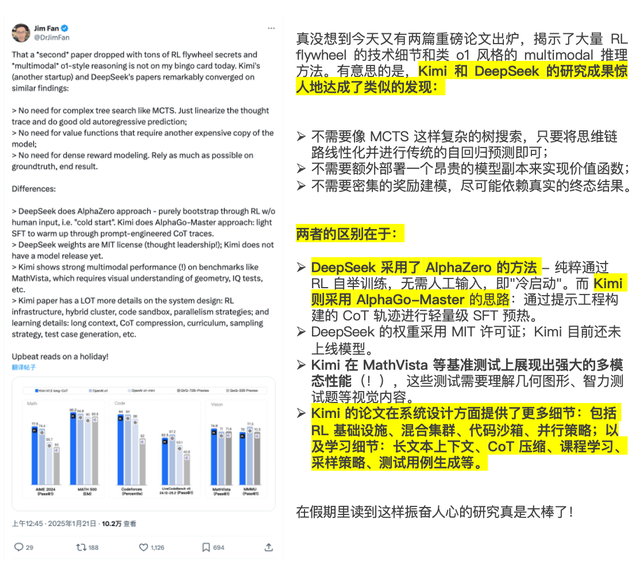
作為當(dāng)前AI領(lǐng)域最主流的敘事和技術(shù)高地,推理模型的風(fēng)吹草動(dòng),都會引發(fā)全球從業(yè)者的目光。而中國公司一口氣在推理模型賽道上,拿出兩個(gè)重磅論文,模型含金量高,經(jīng)過了目光聚焦且嚴(yán)苛的審視,其中還包含很多原創(chuàng)技術(shù)。
可以說,從Kimi k1.5/ DeepSeeK R1的“雙子星”開始,國產(chǎn)推理模型是真的崛起了。

推理模型,國內(nèi)AI公司是怎么追趕的?我們和海外AI圈一起“黑著眼眶熬著夜”,苦讀kimi/ DeepSeek論文,簡單總結(jié)一下:
總路線上,k1.5和R1都使用了強(qiáng)化學(xué)習(xí)(RL)技術(shù),來提升模型推理能力。但在技術(shù)細(xì)節(jié)上,kimi/ DeepSeek都拿出了全新的思路。
DeepSeek沒有采用業(yè)界普遍的監(jiān)督微調(diào)(SFT)作為冷啟動(dòng)的方案,提出了一種多階段循環(huán)的訓(xùn)練方式,用少量冷啟動(dòng)數(shù)據(jù),微調(diào)模型作為強(qiáng)化學(xué)習(xí)的起點(diǎn),然后在RL環(huán)境中通過獎(jiǎng)勵(lì)信號來自我進(jìn)化,實(shí)現(xiàn)了非常好的推理效果。
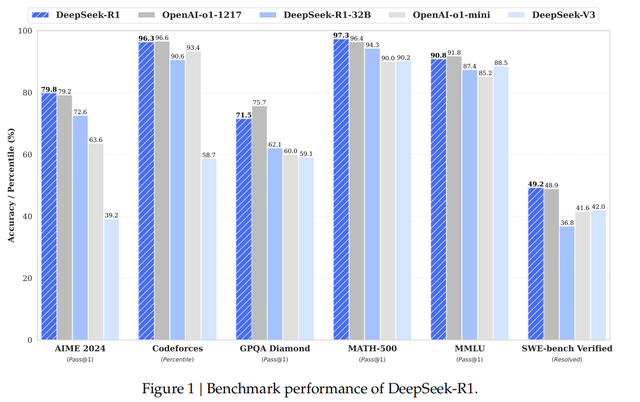
Kimi k1.5則首創(chuàng)了long2short思維鏈,讓LLM通過獎(jiǎng)勵(lì)機(jī)制進(jìn)行探索性學(xué)習(xí),自主擴(kuò)展訓(xùn)練數(shù)據(jù),來擴(kuò)展上下文長度,從而優(yōu)化RL訓(xùn)練表現(xiàn),在短鏈思維推理方面取得了SOTA成績。
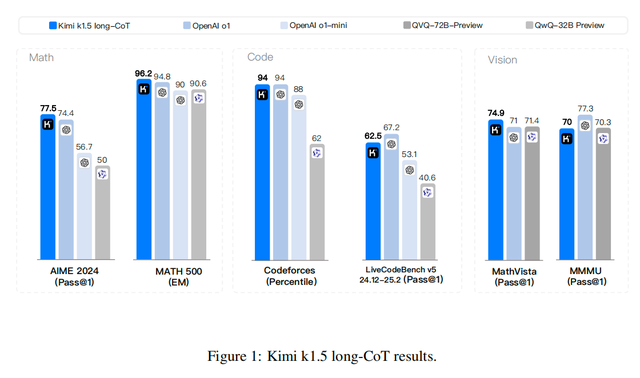
性能最強(qiáng)的long-CoT版本Kimi k1.5,數(shù)學(xué)、代碼、多模態(tài)推理能力可以達(dá)到長思考SOTA模型OpenAI o1正式版的水平。
基于long-CoT版本簡化的short-CoT,性能依舊強(qiáng)悍,但推理更加高效,大幅超越了全球范圍內(nèi)短思考SOTA模型GPT-4o和Claude 3.5 Sonnet的水平,領(lǐng)先達(dá)到550%。
除此之外,兩大國產(chǎn)推理模型還各有亮點(diǎn)。
DeepSeek-R1延續(xù)了“AI界拼多多”的優(yōu)秀傳統(tǒng),API每百萬輸出tokens 16 元,與o1每百萬輸出tokens 60美元的定價(jià)一比,性價(jià)比拉滿。
Kimi k1.5則是OpenAI之外,首個(gè)達(dá)到o1多模態(tài)推理性能的模型,k1.5支持文本、圖像交疊的多模態(tài)輸入,可以進(jìn)行聯(lián)合推理,填補(bǔ)了國內(nèi)多模態(tài)思考模型的空白。
在人類的感官中,視覺信息占比超過70%,有了多模態(tài)能力,認(rèn)識自家的Benchmark圖表自然不在話下。
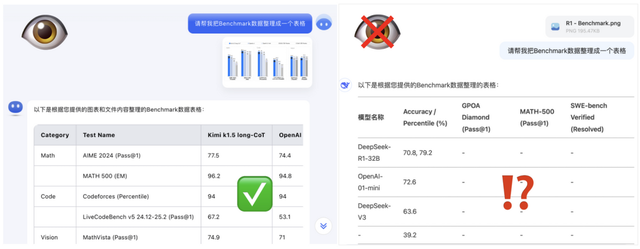
眾所周知,o1要么用起來貴(200美元每月的訂閱費(fèi)),要么根本用不上(OpenAI不向國內(nèi)提供服務(wù))。因此,國產(chǎn)推理模型的上述亮點(diǎn),帶給海內(nèi)外AI開發(fā)者的價(jià)值不是一般大,很多開發(fā)者都倍感興奮。
一位開發(fā)者在論壇感嘆,這兩個(gè)中國實(shí)驗(yàn)室“用更少的資源做更多的事情,他們對模型效率和精煉的巨大關(guān)注,造福我們所有人”。

Amarok開發(fā)者M(jìn)ark Kretschmann也在社交媒體上不吝褒獎(jiǎng),直呼k1.5是“多模態(tài)AI領(lǐng)域的重大突破”。
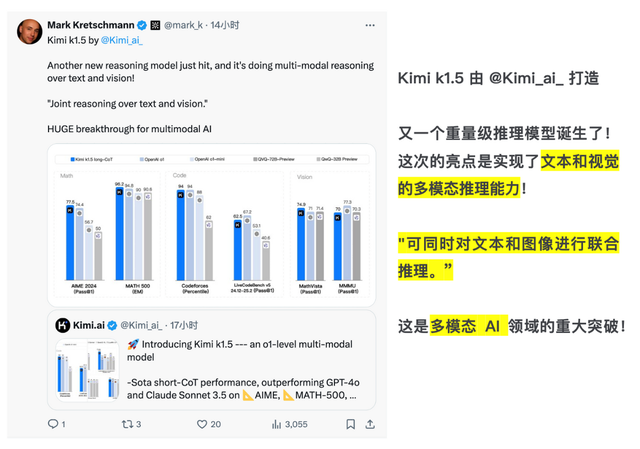
可以看到,面對“推理拓展”這個(gè)全新技術(shù)領(lǐng)域,中國AI“雙子星”靠原創(chuàng)硬實(shí)力穩(wěn)穩(wěn)拿下,并走出了一條有別于OpenAI的發(fā)展創(chuàng)新之路。

OpenAI奧特曼建議大家放低預(yù)期,那么,中國AI公司發(fā)力推理模型,價(jià)值究竟有沒有、有多大?
對于中國AI公司來說,點(diǎn)亮推理模型的技術(shù)版圖,有兩方面的意義:
一是仰望星空,可以拉近中美AI的技術(shù)距離。大模型的領(lǐng)先不會從天上掉下來,而是日拱一卒、水滴石穿的努力,保持對最新技術(shù)路線的跟進(jìn),能讓中國AI的水平快速提高。對標(biāo)ChatGPT用了半年左右,而對標(biāo)正式版o1只用了不到三個(gè)月,
以Kimi為例,去年11月推出k0-math數(shù)學(xué)模型,12月發(fā)布k1視覺思考模型,今年1月發(fā)布k1.5多模態(tài)思考模型,三個(gè)月三次迭代,進(jìn)化速度極快。說明對天花板技術(shù)的貼身跟進(jìn),是中國AI最快最好的練兵場。
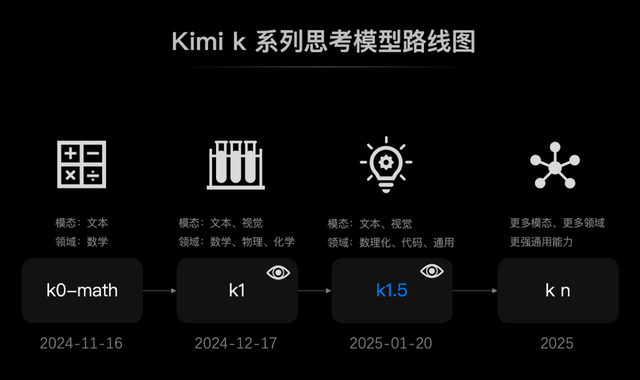
二是腳踏實(shí)地,中國的行業(yè)沃土為國產(chǎn)AI提供了更廣闊的落地場景,推理模型的落地情況會比o1更好。海外AI多以個(gè)人消費(fèi)者為主,o1的主要用例是程序員的代碼助手、數(shù)據(jù)分析師、個(gè)人開發(fā)者,普通人上手門檻高。而國產(chǎn)大模型更多面向行業(yè)場景,AI改造的業(yè)務(wù)場景中包含大量容錯(cuò)率低的嚴(yán)肅生產(chǎn)場景,以前的大語言模型很難解決復(fù)雜任務(wù),十分需要少幻覺、高可靠的推理模型。所以,國產(chǎn)推理模型的落地也許會更快、更廣。
從這些角度看,在各行各業(yè)引入專家級AI的推理模型,加速行業(yè)智能化,恐怕仍會由國產(chǎn)AI率先垂范。k1.5、R1等國產(chǎn)推理模型,將在其中貢獻(xiàn)不可或缺的基座價(jià)值。Kimi官方也表示,2025會繼續(xù)沿著路線圖,加速升級k系列強(qiáng)化學(xué)習(xí)模型,帶來更多模態(tài)、更多領(lǐng)域的能力和更強(qiáng)的通用能力。
所以不出預(yù)料的話,我們很快就能用上花錢少、出活好的專家級國產(chǎn)AI了。
中國AI“雙子星”炸開的2025年大模型開局,分外精彩。推理模型作為模廠的下一個(gè)分水嶺,誰抓住了國產(chǎn)推理模型的崛起時(shí)刻,也就先一步抓住了未來。

審核編輯 黃宇
-
AI
+關(guān)注
關(guān)注
87文章
31427瀏覽量
269821 -
硅谷
+關(guān)注
關(guān)注
1文章
122瀏覽量
16562 -
模型
+關(guān)注
關(guān)注
1文章
3294瀏覽量
49035
發(fā)布評論請先 登錄
相關(guān)推薦
OpenAI發(fā)布o1大模型,數(shù)理化水平比肩人類博士,國產(chǎn)云端推理芯片的新藍(lán)海?
對標(biāo)OpenAI o1,DeepSeek-R1發(fā)布
AN52-凌力爾特雜志電路合集,第1卷

TMS320C54x DSP CPU和外設(shè)參考集,第1卷
OpenAI發(fā)布o1模型API,成本大幅下降60%
ChatGPT新模型o1被曝具備“欺騙”能力
創(chuàng)建一個(gè)5G的邏輯卷
昆侖萬維推出“天工大模型4.0”o1版(Skywork o1)邀請測試
昆侖萬維天工大模型4.0 O1版即將邀測
天工大模型4.0 O1版即將啟動(dòng)邀測
聲智科技打造AI匠心之路
OpenAI o1開辟“慢思考”,國產(chǎn)AI早已集結(jié)在CoE“組團(tuán)”先出發(fā)

鴻蒙開發(fā)文件管理:【@ohos.volumeManager (卷管理)】





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論