 基于AI深度學習的缺陷檢測系統
基于AI深度學習的缺陷檢測系統
在工業生產中,缺陷檢測是確保產品質量的關鍵環節。傳統的人工檢測方法不僅效率低下,且易受人為因素影響,導致誤檢和漏檢問題頻發。隨著人工智能技術的飛速發展,特別是深度學習技術的崛起,基于AI深度學習的缺陷檢測系統逐漸成為工業界關注的焦點。本文將深入探討這一系統的構建、應用及優勢,并附上相關代碼示例。
一、基于AI深度學習的缺陷檢測系統概述
1. 系統背景與需求
在工業生產中,由于生產和運輸環境的復雜性,產品表面往往會出現劃痕、壓傷、擦掛等微小缺陷。這些缺陷不僅影響產品的美觀度,還可能對產品的性能和使用壽命造成嚴重影響。因此,開發一種高效、準確的缺陷檢測系統對于提高產品質量、降低不良品率具有重要意義。
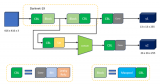
2. 系統架構
基于AI深度學習的缺陷檢測系統通常由數據采集、圖像預處理、模型訓練、缺陷檢測與結果輸出等模塊組成。其中,數據采集模塊負責通過相機或傳感器等設備獲取待檢測產品的圖像信息;圖像預處理模塊對原始圖像進行去噪、增強對比度等操作,以提高后續檢測的準確性;模型訓練模塊利用深度學習算法對標注好的缺陷樣本進行訓練,構建出能夠識別缺陷的模型;缺陷檢測模塊則利用訓練好的模型對新的圖像進行缺陷檢測,并輸出檢測結果。
二、深度學習在缺陷檢測中的應用
1. 數據準備
數據是深度學習模型訓練的基礎。在缺陷檢測系統中,需要收集大量的正常樣本和缺陷樣本,并進行標注。標注工作通常由專業人員完成,他們需要根據產品的特性和缺陷類型,對圖像中的缺陷進行精確的定位和分類。數據準備過程包括數據的讀取、預處理和劃分訓練集與測試集等步驟。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
# 讀取數據
data = pd.read_csv('data.csv')
# 預處理數據(示例,具體步驟根據實際需求調整)
def preprocess(data):
# 假設data中包含'image_path'和'label'兩列
# 這里只是示例,實際中需要加載圖像并進行處理
# ...
# 返回預處理后的數據
return data
preprocessed_data = preprocess(data)
# 劃分訓練集和測試集
train_data, test_data = train_test_split(preprocessed_data, test_size=0.2)
2. 模型構建
模型構建是深度學習缺陷檢測的核心步驟。常用的模型包括卷積神經網絡(CNN)和循環神經網絡(RNN)等。在構建模型時,需要定義網絡結構、選擇合適的激活函數和損失函數,并進行參數初始化。
import tensorflow as tf
from tensorflow.keras import layers
# 定義模型結構
model = tf.keras.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid')) # 假設是二分類問題
# 編譯模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
3. 模型訓練
在模型構建完成后,需要使用訓練數據對模型進行訓練。訓練過程中,需要定義訓練的批次大小、迭代次數等超參數,并監控模型的性能。
# 假設train_data和train_labels分別是訓練數據和標簽
# 設置訓練參數
batch_size = 32
epochs = 10
# 訓練模型
model.fit(train_data, train_labels, batch_size=batch_size, epochs=epochs, validation_data=(test_data, test_labels))
4. 模型評估與測試
模型訓練完成后,需要對模型進行評估和測試。評估過程中,可以計算模型在測試集上的準確率、精確率、召回率等指標,并繪制混淆矩陣來分析模型的性能。
# 評估模型
test_loss, test_acc = model.evaluate(test_data, test_labels, verbose=2)
print('Test accuracy:', test_acc)
5. 缺陷檢測
使用訓練好的模型對新的圖像進行缺陷檢測是系統的最終目的。在實際應用中,可以將待檢測的圖像輸入到模型中,模型會輸出該圖像是否存在缺陷的預測結果,并可能給出缺陷的具體位置和類型。
缺陷檢測模塊是系統的核心功能之一。它利用訓練好的深度學習模型對輸入圖像進行快速、準確的缺陷識別。為了提高檢測效率,可以采用批處理或流式處理的方式對圖像進行處理。
# 假設有一個新的待檢測圖像
from PIL import Image
import numpy as np
# 加載圖像
image_path = 'new_image.jpg'
img = Image.open(image_path)
img = img.resize((64, 64)) # 調整為模型輸入所需的尺寸
img_array = np.array(img) / 255.0 # 歸一化處理
img_array = np.expand_dims(img_array, axis=0) # 增加批次維度
# 使用模型進行預測
prediction = model.predict(img_array)
# 預測結果處理
# 假設prediction是一個概率值,可以通過閾值判斷是否存在缺陷
defect_threshold = 0.5
if prediction[0] > defect_threshold:
print("檢測到缺陷!")
else:
print("未檢測到缺陷。")
# 如果需要更詳細的缺陷信息(如位置、類型),則模型可能需要設計為多輸出或多任務學習
# 這通常涉及更復雜的網絡結構和后處理步驟
6. 結果輸出與反饋
檢測結果通常以可視化的形式(如標記缺陷位置的圖像)或數值報告的形式輸出給用戶。同時,系統還可以根據檢測結果生成反饋信號,如觸發警報、停止生產線等,以便及時采取措施處理缺陷產品。
7. 系統優化與迭代
在實際應用中,基于AI深度學習的缺陷檢測系統需要不斷優化和迭代。這包括收集更多的訓練數據以提高模型的泛化能力、調整模型結構和參數以優化性能、引入新的算法和技術以應對更復雜的缺陷類型等。此外,系統的穩定性和實時性也是優化過程中需要考慮的重要因素。
三、系統優勢與挑戰
優勢 :
- 高效性 :深度學習模型能夠快速處理大量圖像數據,顯著提高缺陷檢測的效率。
- 準確性 :通過訓練大量標注數據,深度學習模型能夠學習到復雜的特征表示,從而提高檢測的準確性。
- 靈活性 :深度學習模型具有較強的泛化能力,能夠適應不同產品和缺陷類型的檢測需求。
挑戰 :
- 數據標注成本高 :高質量的標注數據是深度學習模型訓練的基礎,但數據標注過程耗時且成本高。
- 模型可解釋性差 :深度學習模型通常具有復雜的結構和參數,難以解釋其做出決策的具體原因。
- 計算資源要求高 :深度學習模型的訓練和推理過程需要大量的計算資源支持,包括高性能的GPU和大規模的數據存儲設備等。
四、結論
基于AI深度學習的缺陷檢測系統是工業4.0時代的重要技術之一。它利用深度學習算法的強大能力,實現了對生產線上產品的高效、準確檢測,為提高產品質量、降低不良品率提供了有力支持。然而,在實際應用中仍面臨數據標注成本高、模型可解釋性差等挑戰。未來隨著技術的不斷發展和完善,相信基于AI深度學習的缺陷檢測系統將在更多領域發揮重要作用。
-
AI
+關注
關注
87文章
31077瀏覽量
269412 -
缺陷檢測
+關注
關注
2文章
143瀏覽量
12252 -
深度學習
+關注
關注
73文章
5507瀏覽量
121266
發布評論請先 登錄
相關推薦
全網唯一一套labview深度學習教程:tensorflow+目標檢測:龍哥教你學視覺—LabVIEW深度學習教程
labview缺陷檢測算法寫不出來?你OUT了!直接上深度學習吧!
labview深度學習應用于缺陷檢測
【HarmonyOS HiSpark AI Camera】基于深度學習的目標檢測系統設計
labview深度學習檢測藥品兩類缺陷
射頻系統的深度學習【回映分享】
AI視覺檢測在工業領域的應用
基于深度學習的小樣本墻壁缺陷目標檢測及分類
基于深度學習的工業缺陷檢測方法
基于深度學習的焊接焊點缺陷檢測
一文梳理缺陷檢測的深度學習和傳統方法
深度學習在工業缺陷檢測中的應用

基于深度學習的缺陷檢測方案





 工商網監
工商網監
評論