

在一些非自然圖像中要比傳統(tǒng)模型表現(xiàn)更好
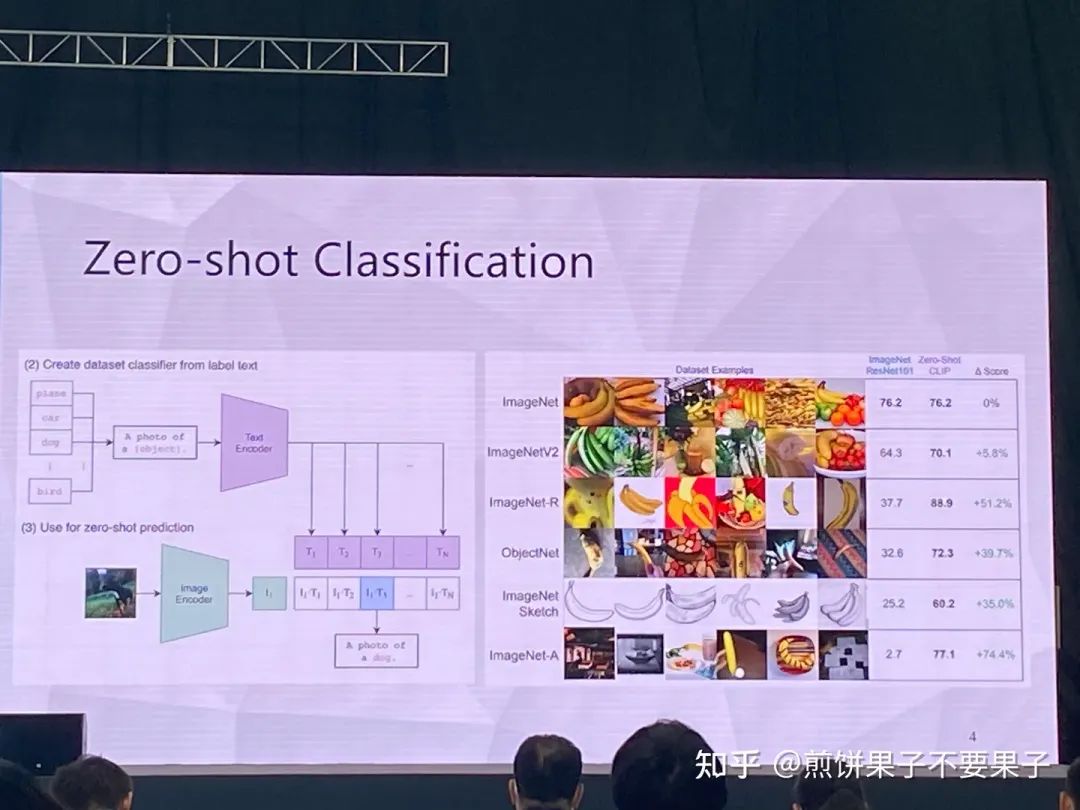
CoOp 增加一些 prompt 會讓模型能力進一步提升

怎么讓能力更好?可以引入其他知識,即其他的預訓練模型,包括大語言模型、多模態(tài)模型
也包括 Stable Diffusion 多模態(tài)預訓練模型

考慮多標簽圖像分類任務——每幅圖像大于一個類別
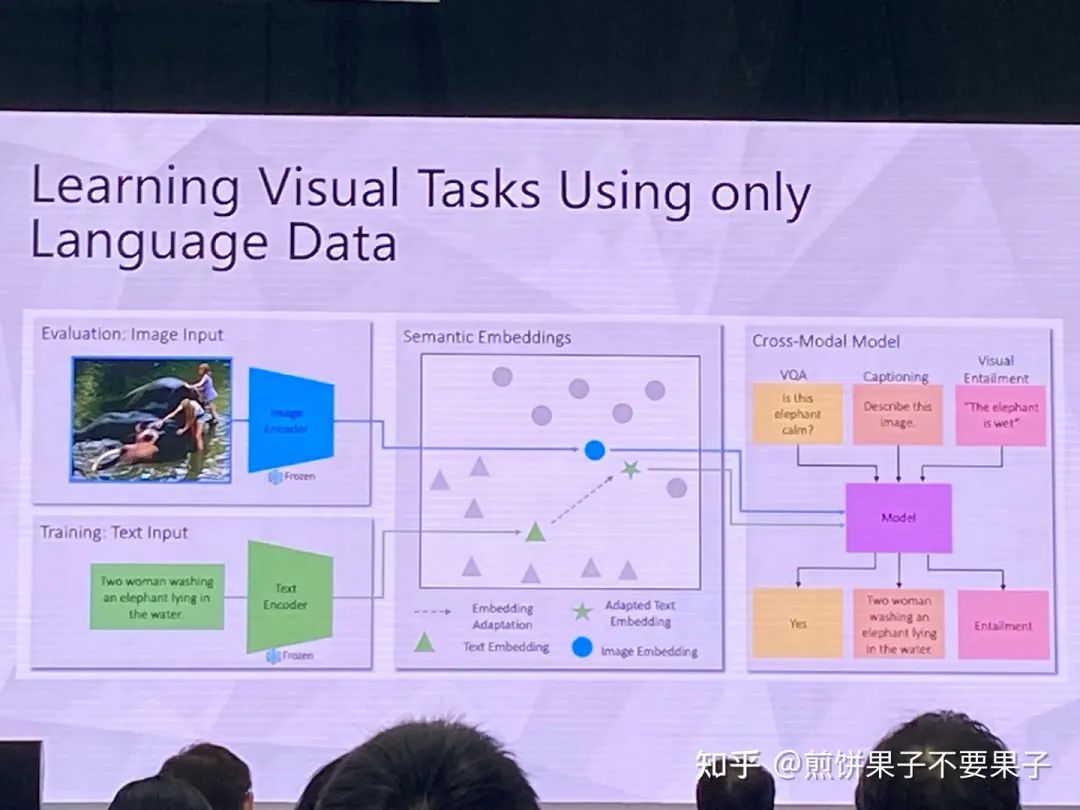
如果已有圖文對齊模型——能否用文本特征代替圖像特征

訓練的時候使用文本組成的句子
對齊總會有 gap,選 loss 的時候使用 rank loss,對模態(tài) gap 更穩(wěn)定
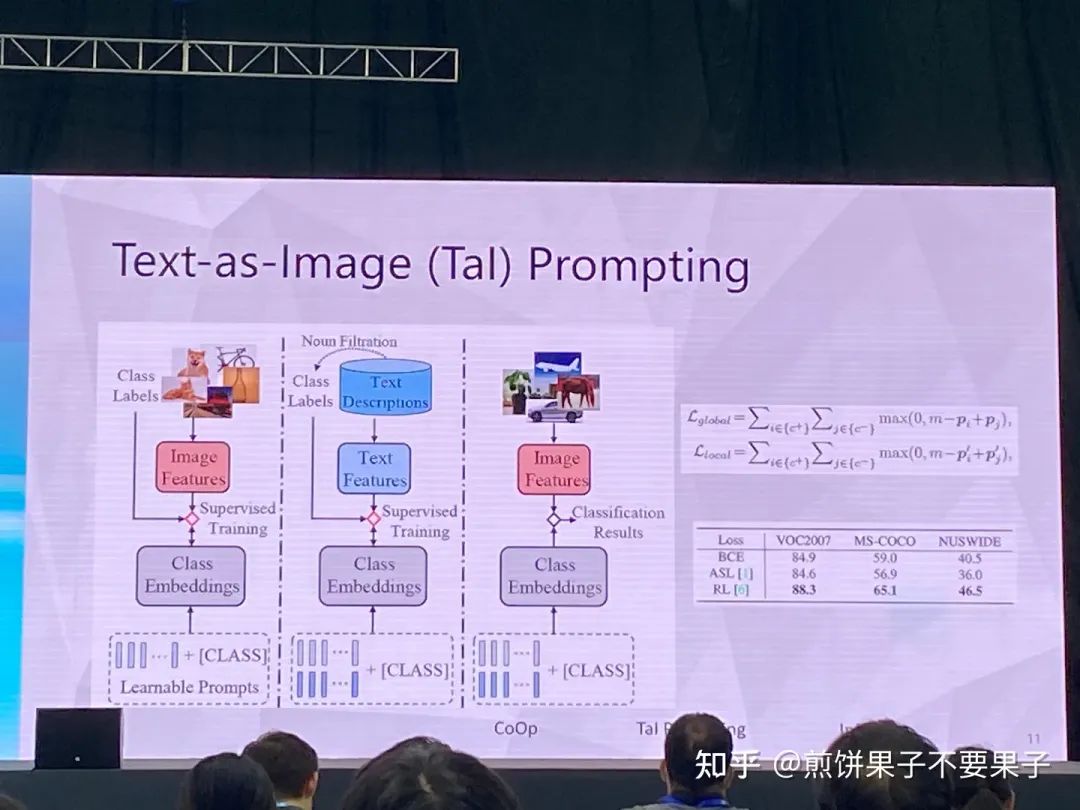
拿到文本后有幾種選擇,比如 Coco 只要其中的 caption 不要圖像,或是 Google 搜句子,抑或是語言模型生成
最后選擇第一種,因為穩(wěn)定性和效果更好,能夠保證同樣數(shù)據(jù)集(同分布?)
可以建一個同義詞表

兩種 prompt,global 關注句子里有沒有貓,local 關心這個詞是不是跟貓有關系

測試的時候就將句子變成圖像,global 不變,local 變成了跟圖像里的 token 做比較
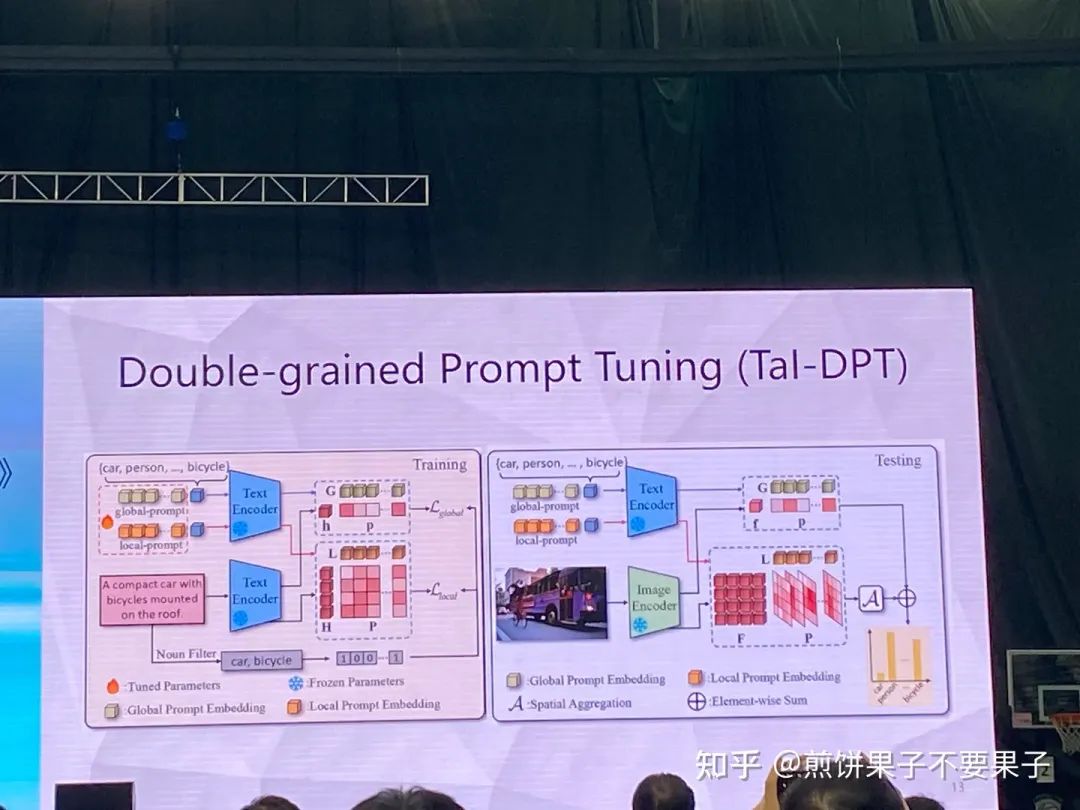
如果再加上少量文本(大量句子和少量文本)性能會進一步提升

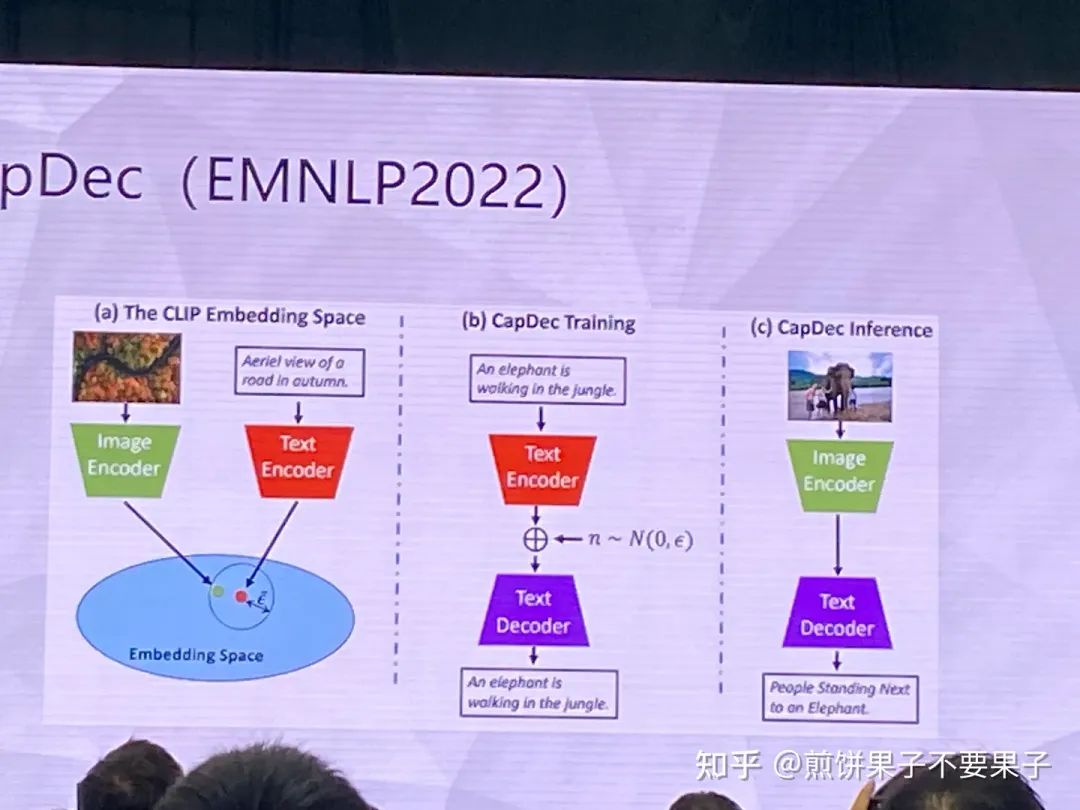
一些相關工作,提完文本特征加一些噪聲提高魯棒性,消解圖文 gap
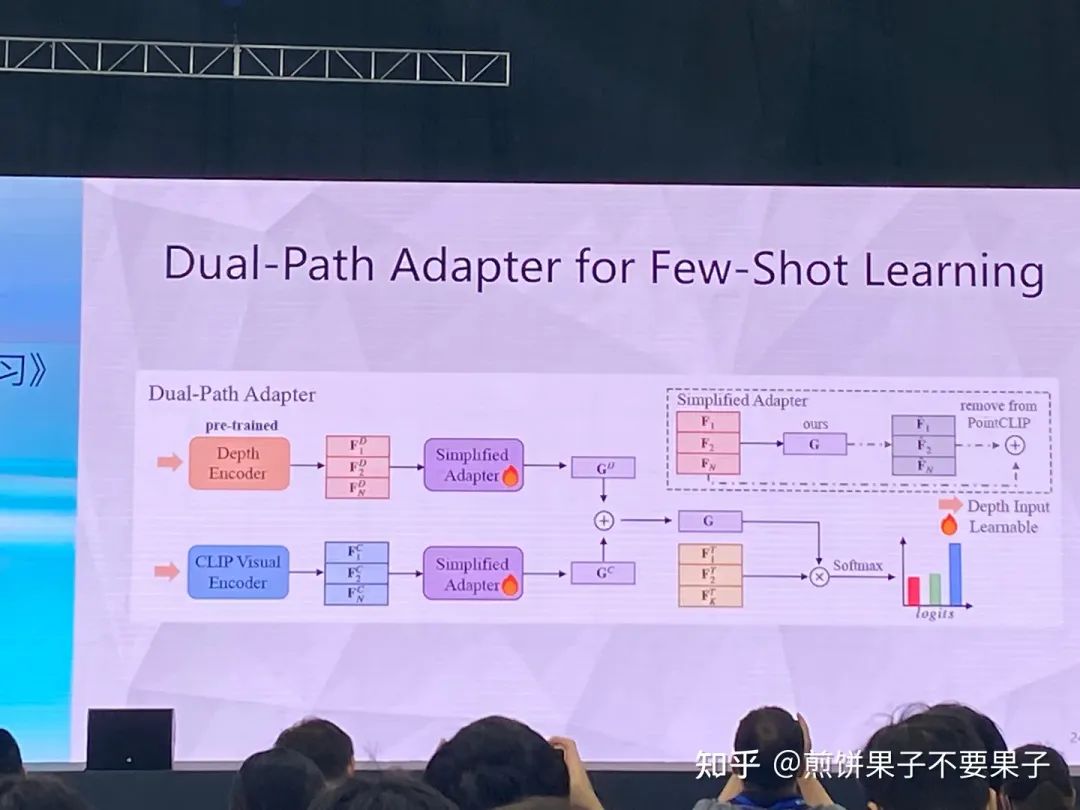
3d 樣本較難,因為點云-文本對較少,很難獲取
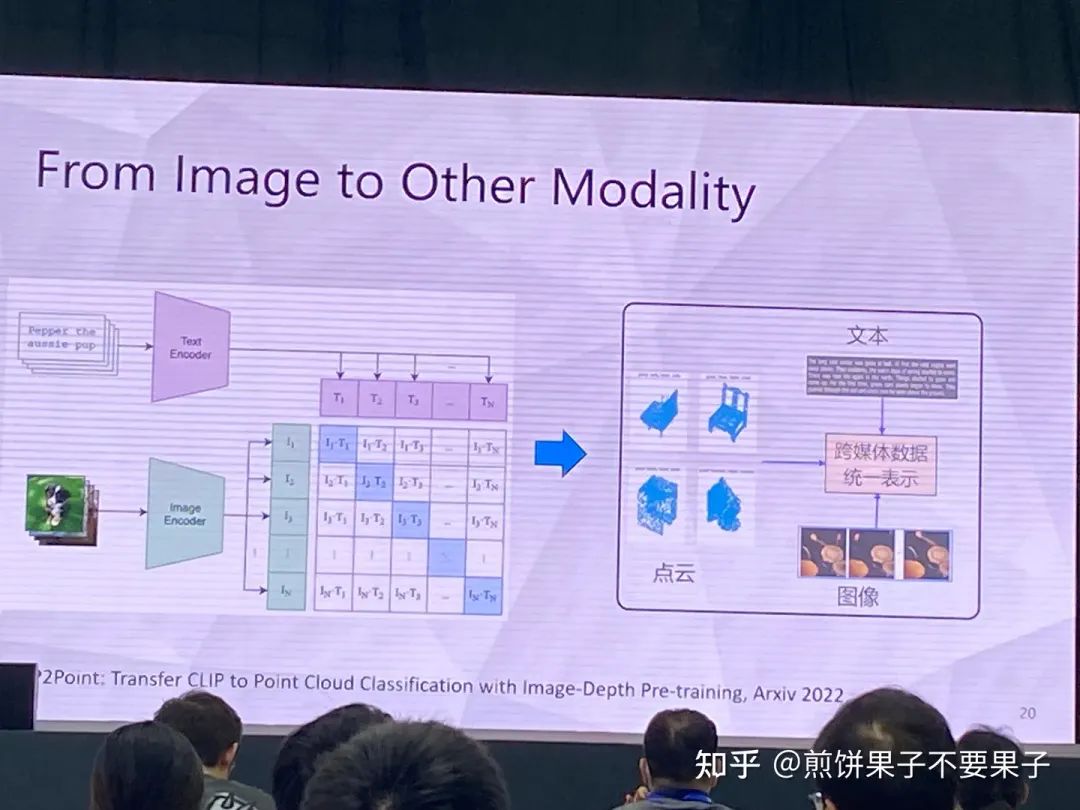
投影后的 3d 點云可以被視作 2d 圖像處理,使用圖像 encoder
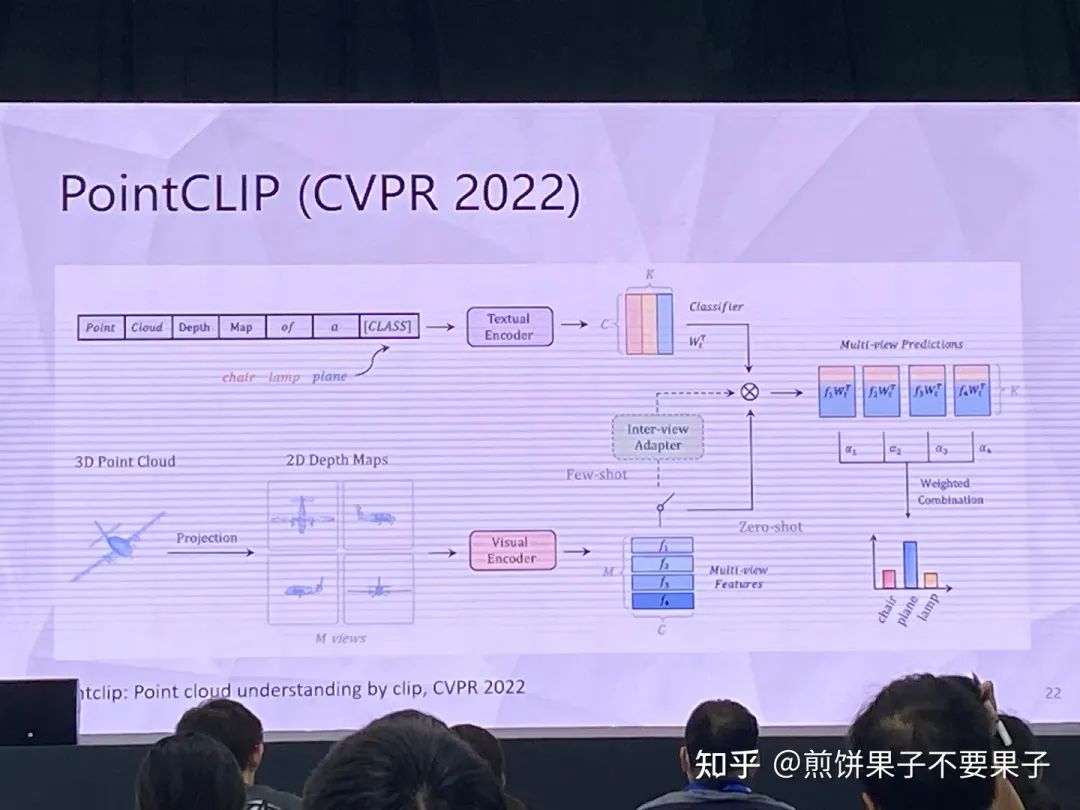
但投影點云依然與圖像存在 gap,于是采取另一種思路
投影的確與圖像相關,但依然有調整空間,所以轉換成某個方向的圖像和該方向點云的投影圖像做匹配
投影和圖像對齊,圖像和文本對齊,因此就可以實現(xiàn)零樣本學習
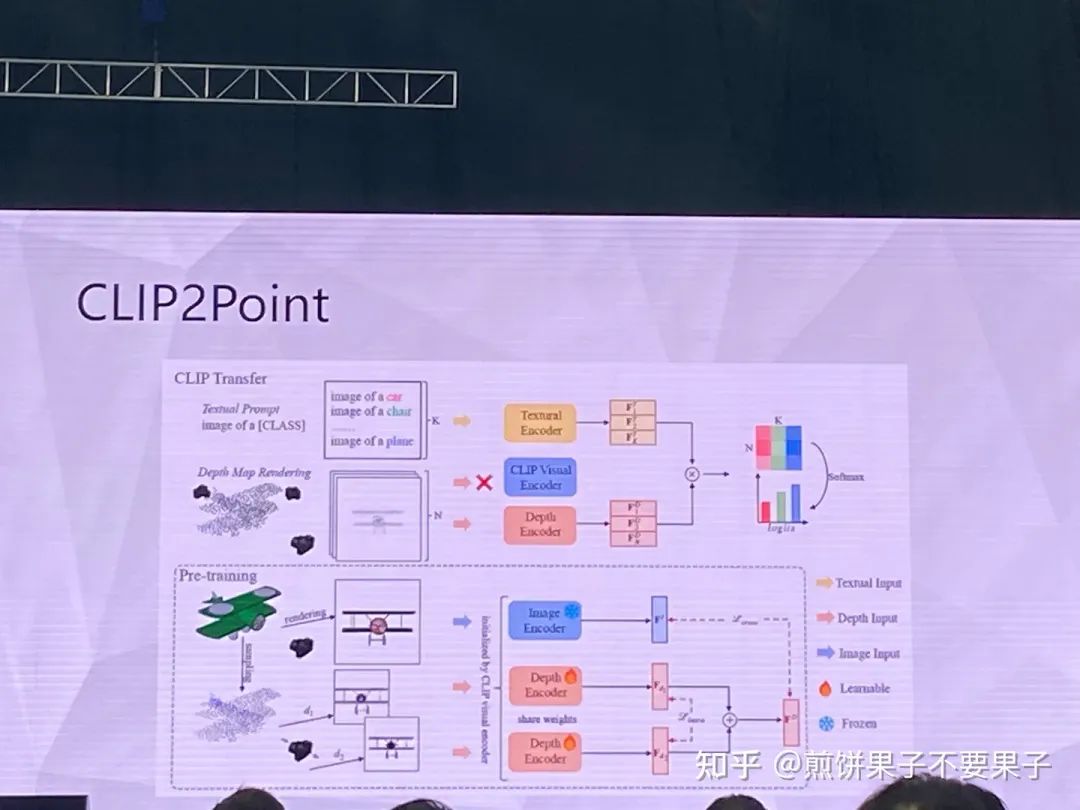
如果有一些少量的有標簽監(jiān)督,相當于 few-shot,效果也相當好
全監(jiān)督效果也很好
當時覺得圖像可以做中介,那么紅外、熱成像等其他模態(tài)都可以
ImageBind 以圖像為中介將六種模態(tài)對齊到一起,重新訓練
但大家依然可以做自己領域相關的方向,以圖像作為中介對比,還有很大的空間

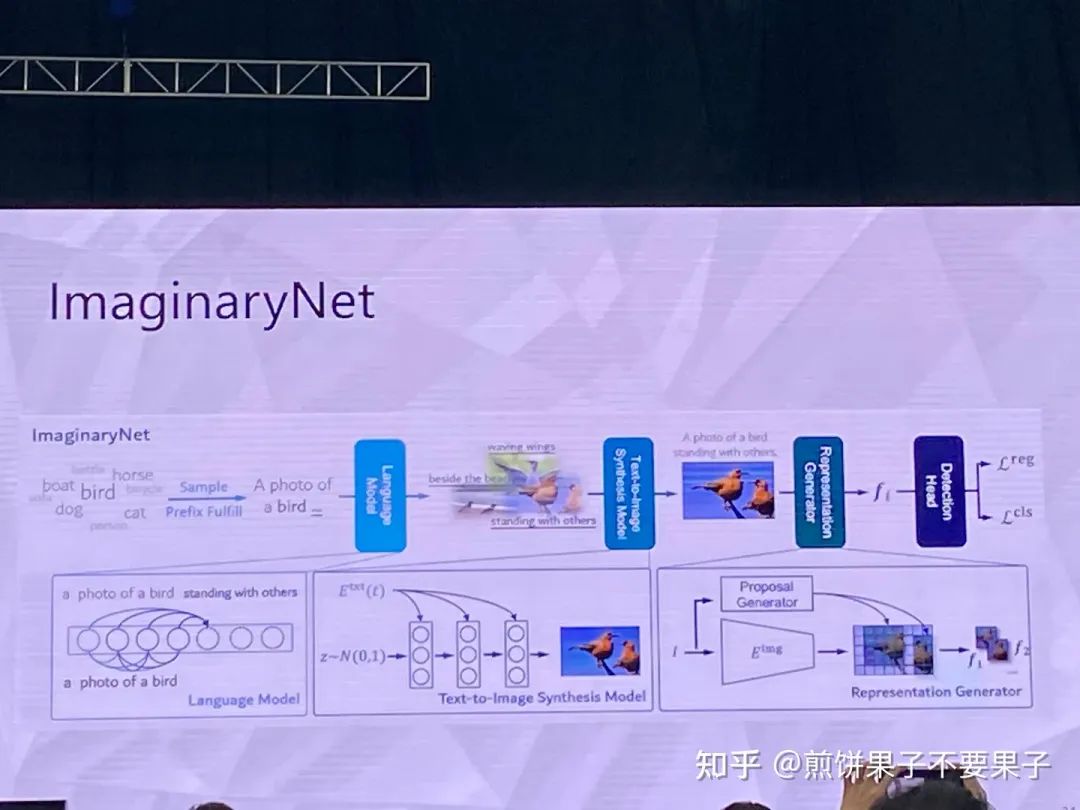
用想象的方式開展學習

假設有一些類別,使用語言模型生成一些句子,再根據(jù)句子使用生成模型生成圖像
因此有了圖像和類別匹配對(弱監(jiān)督目標檢測)
希望即使使用合成圖像,模型在真實圖像上也可以比較好
因為類別本身和圖像會比較簡單,但如果使用語言模型,比如貓變成趴著的貓,這樣圖像多樣性會很高

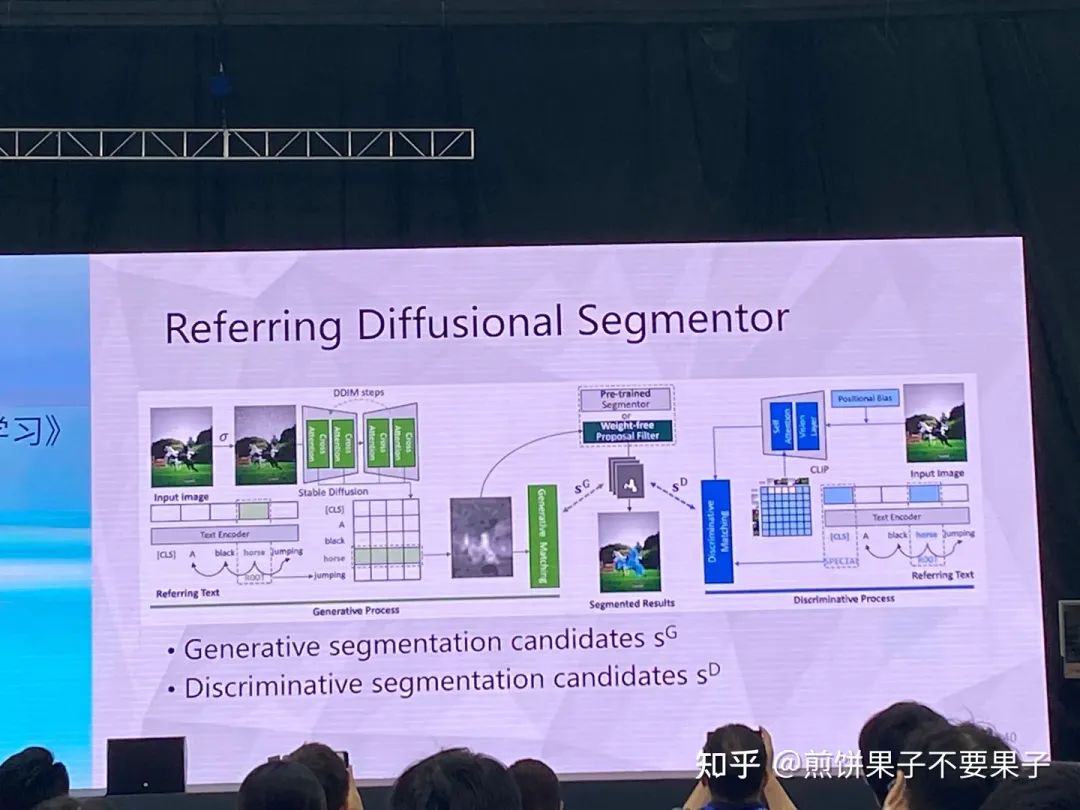
考慮 SAM 和 Stable diffusion 特定完成分割任務
通過 SAM 得到的 proposal 提取特征

責任編輯:彭菁
-
語言模型
+關注
關注
0文章
557瀏覽量
10607 -
訓練模型
+關注
關注
1文章
37瀏覽量
3918
原文標題:VALSE 2023 | 左旺孟教授:預訓練模型和語言增強的零樣本視覺學習
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
一文詳解知識增強的語言預訓練模型
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】大語言模型的應用
基于深度學習的自然語言處理對抗樣本模型
融合零樣本學習和小樣本學習的弱監(jiān)督學習方法綜述

如何更高效地使用預訓練語言模型
預訓練語言模型的字典描述
如何充分挖掘預訓練視覺-語言基礎大模型的更好零樣本學習能力
使用BLIP-2 零樣本“圖生文”
預訓練數(shù)據(jù)大小對于預訓練模型的影響
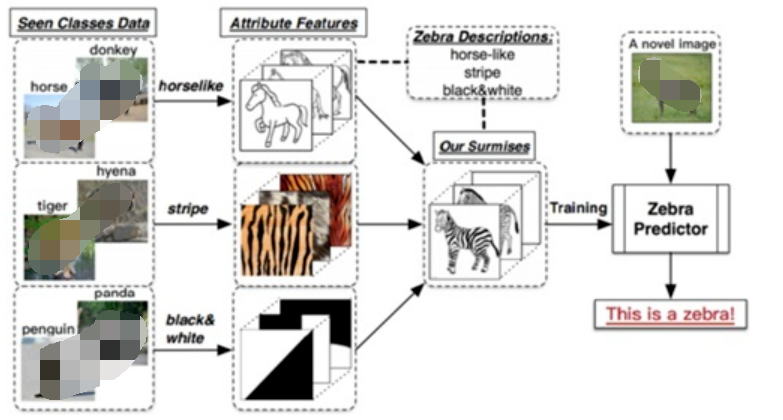
什么是零樣本學習?為什么要搞零樣本學習?





 工商網監(jiān)
工商網監(jiān)

評論