 電子發燒友App
電子發燒友App


網上有一些關于零樣本學習的討論,但都有其局限性,不全面或者太學術,我學習之后,對其進行加工,加上我自己的的理解,然后對后來想要了解零樣本學習的同學,可能會有幫助,至少能節省點時間。相比于網上的各種五花八門的介紹,我爭取做到更全面,更通俗。
為什么我開始研究零樣本學習?是個巧合。之前我沒聽說過,上個學期,在一次組會上,聽一個師姐做匯報,講她關于小樣本學習的研究。聽了介紹,我瞬間被吸引,很感興趣,但平時忙于上課,也一直沒去深入了解,(懶)。直到前幾天,在某文章里看到零樣本學習,這次我有時間了!于是,就深入了解了下(看了幾篇文獻hhhh)。本人水平有限,難免疏漏,還請讀者多多指正。
01
為什么要搞零樣本學習?(why)
(1)深度學習(deep learning)已經在各個領域取得了廣泛的應用,例如在圖像分類問題下,其準確率目前可以達到不錯的成績。然而,deep learning是一種data hungry的技術,高的準確率建立在預先給模型“喂了”大量的數據,即,需要大量的標注樣本才能發揮作用,大多數方法是通過有標簽的訓練集進行學習,側重于對已經在訓練中出現過標簽類別的樣本進行分類。然而在現實場景中,許多任務需要對模型之前從未見過的實例類別進行分類,這樣就使得原有訓練方法不再適用。因為,現實世界中,有很多問題是沒有這么多的標注數據的,或者獲取標注數據的成本非常大。所以,我們思考,當標注數據量比較少時、甚至樣本為零時,還能不能繼續?我們將這樣的方法稱為小樣本學習Few-Shot Learning,相應的,如果只有一個標注樣本,稱One-Shot Learning,如果不對該類進行樣本標注學習,就是零樣本學習Zero-Shot Learning.(2)人類學習的過程包含了大量零樣本學習的思路,也就是說一個小孩子從來沒見過一些類別的東西,在家長和老師的描述之后,他也能在一堆圖片里找出那件東西。
在2016 年中國計算機大會上,譚鐵牛院士指出,生物啟發的模式識別是一個非常值得關注的研究方向,“比如人識別一個動物(并不需要看到過該動物),只需要一句話的描述就能識別出來該動物”,比如被廣泛引用的人類識別斑馬的例子:假設一個人從來沒有見過斑馬這種動物,即斑馬對這個人來說是未見類別,但他知道斑馬是一種身上有著像熊貓一樣的黑白顏色的、像老虎一樣的條紋的、外形像馬的動物,即熊貓、老虎、馬是已見類別。那么當他第一次看到斑馬的時候, 可以通過先驗知識和已見類,識別出這是斑馬。人類通過語義知識作為輔助信息,識別了未見類,零樣本學習也正是基于這樣的思想、基于人類學習過程,進行算法的研究。
02
什么是零樣本學習?(what)
零樣本學習zero-shot learning,是最具挑戰的機器識別方法之一。
定義:(數學描述在此略過)2019年冀中等人在綜述文章中將零樣本分類的定義分為廣義和狹義兩種:
零樣本分類的技術目前正處于高速發展時期, 所涉及的具體應用已經從最初的圖像分類任務擴展到了其他計算機視覺任務乃至自然語言處理等多個相關領域。 對此, 本文將其稱為廣義零樣本分類。 相應地, 我們將針對圖像分類任務的零樣本分類任務稱為狹義零樣本分類。
在冀中和 WEI WANG的文章中,零樣本學習均被視為遷移學習的一個特例。零樣本學習中,源特征空間是訓練樣本的特征空間和目標特征空間是測試樣本的特征空間,這兩者是相同的。但是源標注空間和目標標注空間分別是可見類別和未見類別,兩者是不同的。因此零樣本學習屬于異質遷移學習(heterogeneous transfer learning)。一個最通俗的例子就是在本文第1部分里提得到的斑馬的例子。
零樣本學習的實現與另外兩個研究領域密不可分,其一是表征學習(representation learning),其二是度量學習(metric learning)。表征學習是指通過對數據進行變換從而提取數據中的有效信息的一種學習方式,涉及到人工智能相關的諸多領域,如信號處理、目標識別、自然語言處理,以及遷移學習等。度量學習通常建立在表征學習的基礎之上,其本質是根據不同的任務,根據特定空間中的數據,自主學習出針對某個特定任務的距離度量函數,目前已被廣泛應用于諸多計算機視覺相關的任務, 如人臉識別、圖像檢索、目標跟蹤、多模態匹配等。對于零樣本學習,在獲取到合適的數據表征空間之后,則需要對跨模態樣本間的距離度量進行學習,目的是保證嵌入到語義空間后樣本間的語義相似度關系得以保持。綜上所述,零樣本學習可以看作是在進行表征學習和度量學習的基礎上,通過借助輔助信息(屬性或文本) 實現跨模態知識的遷移,從而完成可見類信息到未見類信息推斷的遷移學習過程。
03
之前的學者們都是怎么做的?(how)
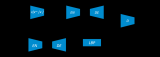
Zero-Shot Learning 這一問題和概念的提出,源于2009年Lampert在CVPR上發表的Learning to Detect Unseen Object Class by Between-Class Attribute Transfer這一篇文章。同樣是這一年,Hinton等在NIPS也上發表了一篇Zero Shot Learning with Semantic Output Codes的文章。這算得上零樣本學習開宗明義的文章,所以先介紹這兩篇。Lampert在論文中所提到的Between-Class Attribute Transfer,通常我們做有監督學習的思路,是實現數據的特征空間到數據標簽之間的映射,而這里,我們利用數據特征預測的卻是樣本的某一屬性。類間屬性遷移應用到上文提到的斑馬案例,見下圖:
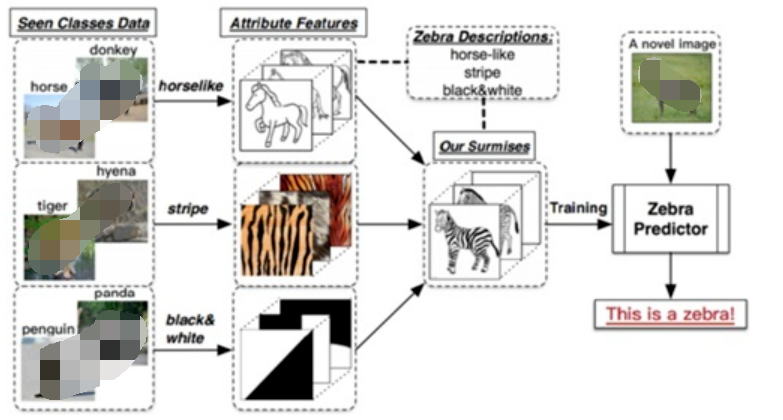
Between-Class Attribute Transfer的核心思想在于:
雖然物體的類別不同,但是物體間存在相同的屬性,提煉出每一類別對應的屬性并利用若干個學習器學習。在測試時對測試數據的屬性預測,再將預測出的屬性組合,對應到類別,實現對測試數據的類別預測。Lampert在該論文中給出了兩種屬性預測的結構:DAP和IAP。
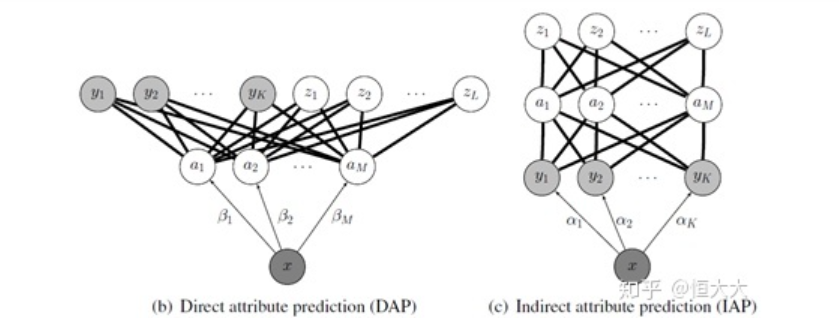
直接屬性預測 Direct attribute prediction (DAP)
這一方法先將數據從特征空間映射到中間層的屬性向量層,屬性向量層的標簽是通過收集來的每一類特征的總結,比如是否有尾巴,有幾只腳等等,通過利用數據預測屬性,再通過屬性映射到標簽來實現對于未知類別的預測,這一方法也是接受和應用最為廣泛的一種。
間接屬性預測 Indirect attribute prediction (IAP)
這一方法使用了兩層標簽,屬性層作為中間層,在實際中使用較少,這里不多做介紹
Hinton等在2009年的Zero-shot learning with semantic output codes這篇論文里,提到的語意輸出編碼方式,思想其實與DAP的思路類似,也是在之前的特征空間與標簽之間增加了一層,這里增加的一層不再是數據本身的屬性,而是標簽本身的編碼,說簡單點就是NLP里面的詞向量(word2vec),通過將標簽進行詞向量的編碼,利用模型基于數據矩陣對編碼進行預測,得到結果之后,通過衡量輸出與各個類別詞向量之間距離,判別樣本的類別。
簡單說就是,該論文里使用詞向量來實現零樣本學習。如果我們將原先的表示類別的詞(馬、熊貓、老虎等)編碼為詞向量,那么我們就可以用距離來衡量一個未知的詞向量的歸屬。
語義輸出編碼的核心思想在于:
將訓練標簽編碼為詞向量,基于訓練數據和詞向量訓練學習器。測試時輸入測試數據,輸出為預測的詞向量,計算預測結果與未知類別詞向量的距離,數據距離最近的類別。(所以未知類別的詞向量在此是已知的)由以上兩個模型,我們可以總結出一個零樣本學習的簡單模式:
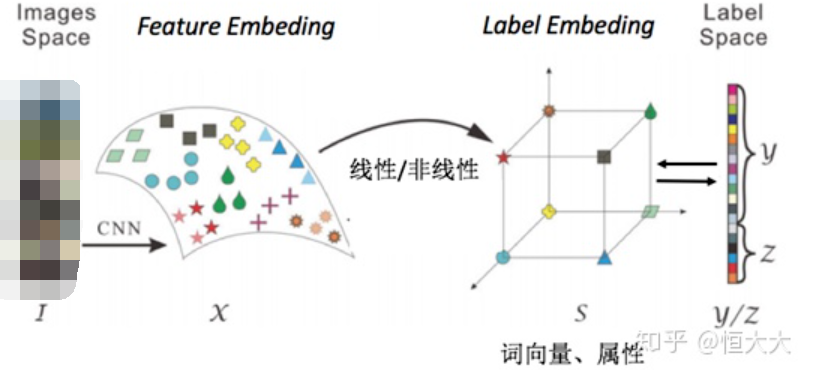
上圖中,images space和label space分別為初始的圖像空間和標簽空間,在零樣本學習中,一般會通過一些方法將圖片映射到特征空間中,這個空間稱為feature embedding ;同樣的標簽也會被映射到一個label embedding 當中,學習feature embedding 和label embedding 中的線性或非線性關系用于測試時的預測轉化取代之前的直接由images space 到 label space的學習。
冀中等在文獻[4]中,將零樣本學習的發展分為兩個階段,上文我們介紹的屬于第一階段,即提出階段,這個階段主流的研究思路是,利用“淺層視覺特征+ 屬性+ 傳統機器學習方法” 的分析模式;第2 階段的時間大致為2013-2019 年, 稱為發展階段,這個階段的主流研究思路是利用“深度視覺特征+ 屬性/詞向量+ 傳統機器學習方法” 的分析模式。在這一階段,受益于深度學習技術的發展,特別是CNN模型、Word2Vec的提出,零樣本學習得到了較快的發展。
篇幅有限,在這里就先介紹Lampert和Hinton的一些思想和做法,這是比較基礎的也是一般的方法。其他最新的方法,有空再寫一篇新的吧,不然這篇內容寫太多了。詳見參考文獻[5]。
介紹一下數據集:
在零樣本學習中, 最為常用的數據集是Animals with Attributes (AwA) 數據集,此外,在零樣本學習中廣泛應用的屬性數據集還有三個: Caltech-UCSD-Birds200-2111(CUB)、Attribute Pascal and Yahoo (aPY) 數據集 以及SUN attribute 數據集。這些數據集很容易下載到。
04
一些主要的挑戰?(challenge)從入門到放棄?哈哈哈哈,是的,有一些很難解決的問題在這里。
雖然如前文所說,零樣本學習仍處于快速發展的階段,但零樣本學習由于其自身方法中存在的問題,這些問題使得零樣本學習的研究遇到很大的障礙。這三個障礙分別是廣義(泛化)零樣本學習(Generalized zero-shot learning)、樞紐化問題(Hubness)、映射域偏移問題(The projection domain shift problem)。下面簡單介紹一下這幾個問題:
(1) 廣義零樣本學習
在實際的應用中, 目前的零樣本學習與現實應用的學習環境,出現了一定程度的矛盾, 這是因為,在零樣本學習的假設在測試階段,只有未見類樣例出現。這在實際應用中這種假設是不現實的,往往已見類的樣例是現實世界中最為常見的樣例,而且,如果在訓練階段已見類樣本容易得到、未見類樣本難以獲取, 那么在測試階段就也不應只有未見類樣例出現。所以, 為了讓零樣本學習真實的反應實際應用中的樣例識別場景, 零樣本學習模型應對包括未見類和已見類的所有輸入樣例進行識別,即大量的已見類樣例中夾雜著少量的未見類樣例,輸入樣例的可能類標簽大概率屬于已見類, 但也有可能屬于未見類。如果在測試階段,模型可以準確識別已見類樣例,且可以識別從未見過的未見類樣例,那么就認為該模型實現了廣義零樣本學習 。
由于模型在訓練時,只使用了已見類樣本進行訓練, 且已見類的先驗知識也更加豐富,這就導致已見類模型占主導地位。所以在測試時,模型會更加傾向于對未見類樣例標注為已見類的標簽,進而導致識別的準確率和傳統零樣本學習相比大幅度下跌。
(2)樞紐化問題
樞紐化問題(Hubness) ,并不是ZSL所特有的問題,凡是利用特征子空間的學習模型,在實驗中都發現了這個現象。由于目前零樣本學習中,最為流行的方法就是將輸入樣例嵌入到特征子空間中,這就導致了ZSL中的Hubness尤為突出。樞紐化問題是指,將原始空間(如圖像特征空間或類標簽空間)中的某個元素映射到特征子空間中,得到原始空間中某個元素的在特征子空間中的新表示,這時如果使用K 近鄰,可能會有某些原始空間中的無關元素映射到多個測試樣本特征空間中表示最近的幾個近鄰中,而這些無關向量,就稱為樞紐(hub)。
(3) 映射域偏移問題
產生映射域偏移問題的根源在于映射模型較差的泛化能力:模型使用了訓練類樣本學習由樣例特征空間到類標簽語義空間的映射,由于沒有測試類的未見類樣例可以用于訓練,因此,在映射測試類的輸入樣例的時候,就會產生一定的偏差。
05
未來可能會怎么樣?(future)
(1) 如果可以使用更好的算法,利用網絡上現有的文本內容(例如各個類標簽的維基百科),因為網絡中的文本內容都是唾手可得的,可以大大減少零樣本學習的工作成本,使得零樣本學習推廣到更多方面。
(2) 圖像特征映射函數以及語義向量映射函數是零樣本學習的核心,可以考慮將語義向量映射至圖像特征空間中,或是同時引入這兩種映射,可能會得到更好的實驗結果。
(3) 和單樣本、小樣本學習結合,構建較為統一的模型。
(4) 開集識別和ZSL結合的GZLS。
(5) 有研究將零樣本學習和強化學習結合,也就是將ZSL的目標設計進強化學習的模型中去,使得agent能夠執行在訓練階段未曾傳授給它的知識。
(6) 更加廣泛的應用。除了常見的圖像分類和視頻事件檢測,還可以將零樣本學習應用到圖像標注、多媒體跨模態檢索、視頻摘要、情感識別、行人再識別、自動問答、目標檢測等不同領域。
06
有沒有代碼可以跑一下?(code)6.1 CVPR2019
l CADA-VAE: Edgar Sch?nfeld, Sayna Ebrahimi, Samarth Sinha, Trevor Darrell, Zeynep Akata. “Generalized Zero- and Few-Shot Learning via Aligned Variational Autoencoders.” CVPR (2019)。 [pdf] [code]
l GDAN: He Huang, Changhu Wang, Philip S. Yu, Chang-Dong Wang. “Generative Dual Adversarial Network for Generalized Zero-shot Learning.” CVPR (2019)。 [pdf] [code]
l DeML: Binghui Chen, Weihong Deng. “Hybrid-Attention based Decoupled Metric Learning for Zero-Shot Image Retrieval.” CVPR (2019)。 [pdf] [code]
l LisGAN: Jingjing Li, Mengmeng Jin, Ke Lu, Zhengming Ding, Lei Zhu, Zi Huang. “Leveraging the Invariant Side of Generative Zero-Shot Learning.” CVPR (2019)。 [pdf] [code]
l DGP: Michael Kampffmeyer, Yinbo Chen, Xiaodan Liang, Hao Wang, Yujia Zhang, Eric P. Xing. “Rethinking Knowledge Graph Propagation for Zero-Shot Learning.” CVPR (2019)。 [pdf] [code]
l Tristan Hascoet, Yasuo Ariki, Tetsuya Takiguchi. “On Zero-Shot Learning of generic objects.” CVPR (2019)。 [pdf] [code]
l AREN: Guo-Sen Xie, Li Liu, Xiaobo Jin, Fan Zhu, Zheng Zhang, Jie Qin, Yazhou Yao, Ling Shao. “Attentive Region Embedding Network for Zero-shot Learning.” CVPR (2019)。 [pdf] [code]
6.2 NeurIPS 2019
l Zero-shot Knowledge Transfer via Adversarial Belief Matching.[code]: https://github.com/polo5/ZeroShotKnowledgeTransfer
l Transductive Zero-Shot Learning with Visual Structure Constraint.[code]: https://github.com/raywzy/VSC
6.3 CVPR 2020
l Instance Credibility Inference for Few-Shot Learning
論文地址:https://arxiv.org/abs/2003.11853
代碼:https://github.com/Yikai-Wang/ICI-FSL
編輯:黃飛















 工商網監
工商網監
評論