") 雙塔模型擴(kuò)量負(fù)樣本的方法比較
雙塔模型擴(kuò)量負(fù)樣本的方法比較
之前有一段時間做過雙塔的召回模型[1],線上各個指標(biāo)有了不錯的提升。目前雙塔模型也是被各大公司鐘愛的召回模型。對主流召回模型的分享整理在:總結(jié)下自己做過的深度召回模型
雙塔模型在訓(xùn)練時是對一個batch內(nèi)樣本訓(xùn)練。一個batch內(nèi)每個樣本 (user和item對)為正樣本,該user與batch內(nèi)其它item為負(fù)樣本。這樣訓(xùn)練的方式可能有以下問題:
負(fù)樣本的個數(shù)不足。訓(xùn)練時負(fù)樣本個數(shù)限制在了batch內(nèi)樣本數(shù)減1,而線上serving時需要在所有候選集中召回用戶感興趣的樣本。模型只能從當(dāng)前batch內(nèi)區(qū)分出batch內(nèi)正樣本,無法很好地從所有候選集中區(qū)分正樣本。
未點擊的item沒有做負(fù)樣本。由于batch內(nèi)的item都是被點擊過的,因此沒有被點擊item無法成為負(fù)樣本,在線上serving容易它們被召回出來。一種解決方法是之前沒被點擊過的item不導(dǎo)出到候選集中,然而這樣存在的問題是召回的item很多是之前點擊的熱門item,而很多冷門的item沒有機(jī)會召回。
最近,有兩篇文章提出了雙塔模型擴(kuò)量負(fù)樣本的方法。這兩種方法我也曾嘗試過,線下線上指標(biāo)也有一定的提升。
一、Two Tower Model
再介紹其它方法之前,先回顧一下經(jīng)典的雙塔模型建模過程。
用 表示雙塔模型計算的user 和item 的相似性:
是表示user塔,輸出user表示向量; 是item,輸出item表示向量。最后相似性是兩個向量的余弦值。batch內(nèi)概率計算公式為:表示一個batch的意思。損失函數(shù)是交叉熵。
作者在計算user和item的相似度時,用了兩個優(yōu)化方法:
。 可以擴(kuò)大相似度范圍,擴(kuò)大差距。
。 是item 在隨機(jī)樣本中被采樣的概率,也就是被點擊的概率。
關(guān)于優(yōu)化2的解釋有很多。論文中說熱門item出現(xiàn)在batch內(nèi)概率較大,因此會被大量做負(fù)樣本。另一種解釋是增加對冷門item的相似度。相比熱門item,冷門item更能反映用戶興趣。
圖1反映了雙塔模型的batch采樣過程。query也可以表示user。我們采樣一個batch的user和對應(yīng)正樣本的item,計算各自的embedding后,通過點乘得到logits(B*B)的矩陣。label矩陣是一個單位矩陣。logit矩陣與label矩陣的每對行向量一起求交叉熵。
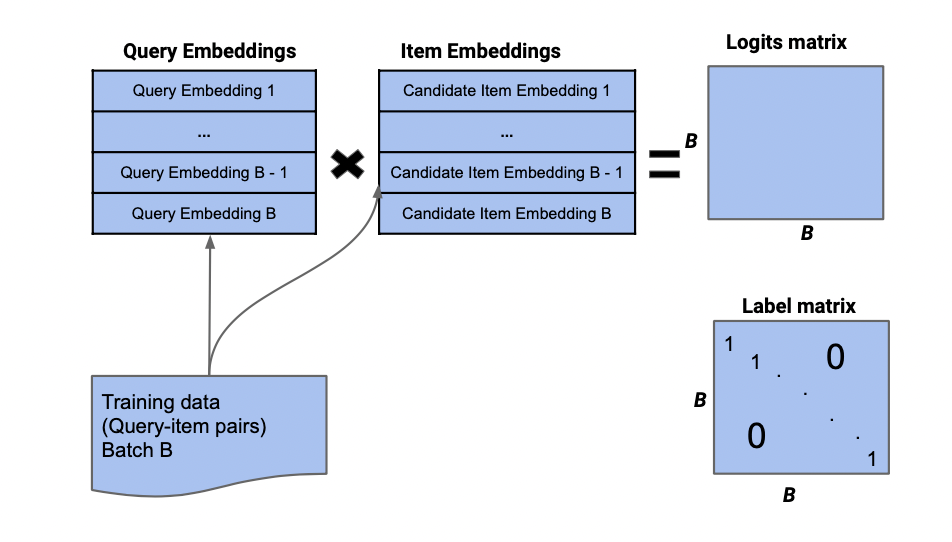
圖1:雙塔模型batch采樣
二、Mixed Negative Samping(MNS)
MNS[2]與雙塔模型[1]出自谷歌團(tuán)隊的同一批作者。用一個batch數(shù)據(jù)訓(xùn)練時,MNS還會在所有的數(shù)據(jù)集中采樣出 個item。這樣可以讓所有的item參與到訓(xùn)練中,一些曝光未點擊的item也會當(dāng)作負(fù)樣本。同時,雙塔模型中使用的 等于訓(xùn)練樣本中的頻率加上所有數(shù)據(jù)集中的頻率分布。概率公式重新定義如下:
作者在這里只對負(fù)樣本的相似性減去了頻率的log值。
MNS的batch采樣方法見圖2。最終計算的logits和label矩陣是一個B*(B+B')維的。其實就是在圖1展示的基礎(chǔ)上再增加B'列。logits的最后B'列是user與B‘內(nèi)的item計算的相似性,label的最后B'列是全0矩陣。
相比于每個樣本都隨機(jī)采樣出一定量的負(fù)樣本,為每個batch都采樣出B‘個負(fù)樣本的不僅有先前雙塔模型的計算效率,也緩和負(fù)樣本不足的問題,并且讓每個樣本均有機(jī)會做負(fù)樣本。
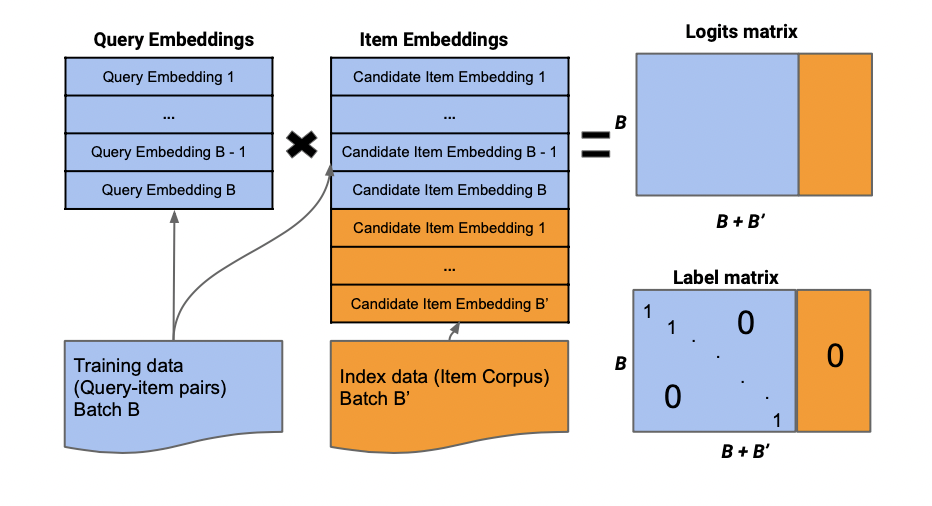
圖2:MNS的batch采樣
三、Cross Batch Negative Samping(CBNS)
CBNS[2]是清華大學(xué)和華為合作提出的方法。文中提到,雙塔模型的計算優(yōu)勢在于利用了batch內(nèi)的負(fù)樣本,減小的計算量。如果我們想擴(kuò)大batch內(nèi)樣本個數(shù),加大負(fù)樣本個數(shù),需要很多的內(nèi)存。因此,作者提出一個使用之前訓(xùn)練過的item作為負(fù)樣本的方法。
神經(jīng)網(wǎng)絡(luò)訓(xùn)練達(dá)到一定輪數(shù)后,會對相同的樣本產(chǎn)生穩(wěn)定的向量。作者在論文中定義了這個想法。因此把之前訓(xùn)練過的item作為當(dāng)前訓(xùn)練的負(fù)樣本時,模型只需要把這些item的向量拿過來使用,不需要再輸出到神經(jīng)網(wǎng)絡(luò)中產(chǎn)生新的向量,畢竟這兩種向量的差距較小。
作者使用了FIFO(先進(jìn)先出)隊列,item塔輸出向量時,會放進(jìn)FIFO中。當(dāng)warm-up training達(dá)到一定的輪數(shù)后,訓(xùn)練模型時,會從FIFO拿出一批向量作為負(fù)樣本的向量。這樣做不僅減少了計算量,在擴(kuò)充負(fù)樣本的時候也減少了內(nèi)存的使用。計算公式與MNS差別不大:
也就是內(nèi)容一中的優(yōu)化2。B'在這里是從FIFO中取出的一批向量。
圖3展示了CBNS與只用batch內(nèi)負(fù)樣本的不同。CBNS維持了一個memory bank。在訓(xùn)練時,會從里面拿出一定量的向量。
然而,CBNS的負(fù)樣本只有點擊過的樣本,未點擊的樣本無法作為負(fù)樣本。
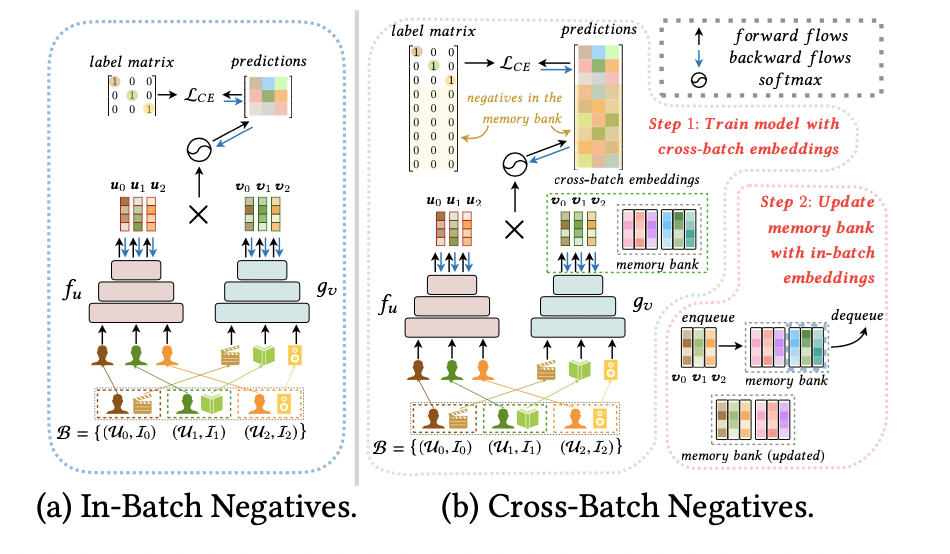
圖3:CBNS采樣方法
審核編輯:郭婷
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4774瀏覽量
100896 -
fifo
+關(guān)注
關(guān)注
3文章
389瀏覽量
43742
原文標(biāo)題:雙塔模型如何選擇負(fù)樣本?
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
云端語言模型開發(fā)方法
RNN與LSTM模型的比較分析
常見AI大模型的比較與選擇指南
AI大模型的性能優(yōu)化方法
氣密性檢測:為什么在負(fù)壓測試中泄漏量是正值,什么時候出現(xiàn)負(fù)值
BP神經(jīng)網(wǎng)絡(luò)樣本的獲取方法
人臉識別模型訓(xùn)練失敗原因有哪些
助聽器降噪神經(jīng)網(wǎng)絡(luò)模型
【大語言模型:原理與工程實踐】大語言模型的應(yīng)用
淺析比較器出現(xiàn)負(fù)輸入電壓的原因、影響及其解決辦法
小紅書搜索團(tuán)隊研究新框架:負(fù)樣本在大模型蒸餾中的重要性
大模型Reward Model的trick應(yīng)用技巧

2023年LLM大模型研究進(jìn)展
傳導(dǎo)的測試與量測介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論