 電子發燒友App
電子發燒友App


回歸問題的條件/前提:
1) 收集的數據
2) 假設的模型,即一個函數,這個函數里含有未知的參數,通過學習,可以估計出參數。然后利用這個模型去預測/分類新的數據。
1. 線性回歸
假設 特征 和 結果 都滿足線性。即不大于一次方。這個是針對 收集的數據而言。
收集的數據中,每一個分量,就可以看做一個特征數據。每個特征至少對應一個未知的參數。這樣就形成了一個線性模型函數,向量表示形式:
![]()
這個就是一個組合問題,已知一些數據,如何求里面的未知參數,給出一個最優解。 一個線性矩陣方程,直接求解,很可能無法直接求解。有唯一解的數據集,微乎其微。
基本上都是解不存在的超定方程組。因此,需要退一步,將參數求解問題,轉化為求最小誤差問題,求出一個最接近的解,這就是一個松弛求解。
求一個最接近解,直觀上,就能想到,誤差最小的表達形式。仍然是一個含未知參數的線性模型,一堆觀測數據,其模型與數據的誤差最小的形式,模型與數據差的平方和最小:
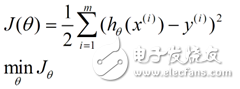
這就是損失函數的來源。接下來,就是求解這個函數的方法,有最小二乘法,梯度下降法。
最小二乘法
是一個直接的數學求解公式,不過它要求X是列滿秩的,

梯度下降法
分別有梯度下降法,批梯度下降法,增量梯度下降。本質上,都是偏導數,步長/最佳學習率,更新,收斂的問題。這個算法只是最優化原理中的一個普通的方法,可以結合最優化原理來學,就容易理解了。
2. 邏輯回歸
邏輯回歸與線性回歸的聯系、異同?
邏輯回歸的模型 是一個非線性模型,sigmoid函數,又稱邏輯回歸函數。但是它本質上又是一個線性回歸模型,因為除去sigmoid映射函數關系,其他的步驟,算法都是線性回歸的。可以說,邏輯回歸,都是以線性回歸為理論支持的。
只不過,線性模型,無法做到sigmoid的非線性形式,sigmoid可以輕松處理0/1分類問題。
另外它的推導含義:仍然與線性回歸的最大似然估計推導相同,最大似然函數連續積(這里的分布,可以使伯努利分布,或泊松分布等其他分布形式),求導,得損失函數。
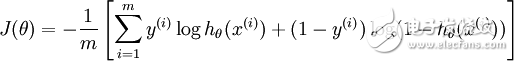
邏輯回歸函數
表現了0,1分類的形式。
應用舉例:
是否垃圾郵件分類?
是否腫瘤、癌癥診斷?
是否金融欺詐?
3. 一般線性回歸
線性回歸 是以 高斯分布 為誤差分析模型; 邏輯回歸 采用的是 伯努利分布 分析誤差。
而高斯分布、伯努利分布、貝塔分布、迪特里特分布,都屬于指數分布。
![]()
而一般線性回歸,在x條件下,y的概率分布 p(y|x) 就是指 指數分布。
經歷最大似然估計的推導,就能導出一般線性回歸的 誤差分析模型(最小化誤差模型)。
softmax回歸就是 一般線性回歸的一個例子。
有監督學習回歸,針對多類問題(邏輯回歸,解決的是二類劃分問題),如數字字符的分類問題,0-9,10個數字,y值有10個可能性。
而這種可能的分布,是一種指數分布。而且所有可能的和 為1,則對于一個輸入的結果,其結果可表示為:
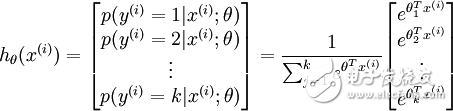
參數是一個k維的向量。
而代價函數:

是邏輯回歸代價函數的推廣。
而對于softmax的求解,沒有閉式解法(高階多項方程組求解),仍用梯度下降法,或L-BFGS求解。
當k=2時,softmax退化為邏輯回歸,這也能反映softmax回歸是邏輯回歸的推廣。
線性回歸,邏輯回歸,softmax回歸 三者聯系,需要反復回味,想的多了,理解就能深入了。
4. 擬合:擬合模型/函數
由測量的數據,估計一個假定的模型/函數。如何擬合,擬合的模型是否合適?可分為以下三類
合適擬合
欠擬合
過擬合
看過一篇文章(附錄)的圖示,理解起來很不錯:
欠擬合:
合適的擬合
過擬合
過擬合的問題如何解決?
問題起源?模型太復雜,參數過多,特征數目過多。
方法: 1) 減少特征的數量,有人工選擇,或者采用模型選擇算法
2) 正則化,即保留所有特征,但降低參數的值的影響。正則化的優點是,特征很多時,每個特征都會有一個合適的影響因子。
5. 概率解釋:線性回歸中為什么選用平方和作為誤差函數?
假設模型結果與測量值 誤差滿足,均值為0的高斯分布,即正態分布。這個假設是靠譜的,符合一般客觀統計規律。
數據x與y的條件概率:
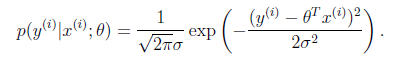
若使 模型與測量數據最接近,那么其概率積就最大。概率積,就是概率密度函數的連續積,這樣,就形成了一個最大似然函數估計。對最大似然函數估計進行推導,就得出了求導后結果: 平方和最小公式
6. 參數估計 與 數據的關系
擬合關系
7. 錯誤函數/代價函數/損失函數:
線性回歸中采用平方和的形式,一般都是由模型條件概率的最大似然函數 概率積最大值,求導,推導出來的。
統計學中,損失函數一般有以下幾種:
1) 0-1損失函數
L(Y,f(X))={1,0,Y≠f(X)Y=f(X)
2) 平方損失函數
L(Y,f(X))=(Y?f(X))2
3) 絕對損失函數
L(Y,f(X))=|Y?f(X)|
4) 對數損失函數
L(Y,P(Y|X))=?logP(Y|X)
損失函數越小,模型就越好,而且損失函數 盡量 是一個凸函數,便于收斂計算。
線性回歸,采用的是平方損失函數。而邏輯回歸采用的是 對數 損失函數。 這些僅僅是一些結果,沒有推導。
8. 正則化:
為防止過度擬合的模型出現(過于復雜的模型),在損失函數里增加一個每個特征的懲罰因子。這個就是正則化。如正則化的線性回歸 的 損失函數:
lambda就是懲罰因子。
正則化是模型處理的典型方法。也是結構風險最小的策略。在經驗風險(誤差平方和)的基礎上,增加一個懲罰項/正則化項。
線性回歸的解,也從
θ=(XTX)?1XTy
轉化為
括號內的矩陣,即使在樣本數小于特征數的情況下,也是可逆的。
邏輯回歸的正則化:
從貝葉斯估計來看,正則化項對應模型的先驗概率,復雜模型有較大先驗概率,簡單模型具有較小先驗概率。這個里面又有幾個概念。
什么是結構風險最小化?先驗概率?模型簡單與否與先驗概率的關系?
經驗風險、期望風險、經驗損失、結構風險
期望風險(真實風險),可理解為 模型函數固定時,數據 平均的 損失程度,或“平均”犯錯誤的程度。 期望風險是依賴損失函數和概率分布的。
只有樣本,是無法計算期望風險的。
所以,采用經驗風險,對期望風險進行估計,并設計學習算法,使其最小化。即經驗風險最小化(Empirical Risk Minimization)ERM,而經驗風險是用損失函數來評估的、計算的。
對于分類問題,經驗風險,就訓練樣本錯誤率。
對于函數逼近,擬合問題,經驗風險,就平方訓練誤差。
對于概率密度估計問題,ERM,就是最大似然估計法。
而經驗風險最小,并不一定就是期望風險最小,無理論依據。只有樣本無限大時,經驗風險就逼近了期望風險。
如何解決這個問題? 統計學習理論SLT,支持向量機SVM就是專門解決這個問題的。
有限樣本條件下,學習出一個較好的模型。
由于有限樣本下,經驗風險Remp[f]無法近似期望風險R[f] 。因此,統計學習理論給出了二者之間的關系:R[f] 《= ( Remp[f] + e )
而右端的表達形式就是結構風險,是期望風險的上界。而e = g(h/n)是置信區間,是VC維h的增函數,也是樣本數n的減函數。
VC維的定義在 SVM,SLT中有詳細介紹。e依賴h和n,若使期望風險最小,只需關心其上界最小,即e最小化。所以,需要選擇合適的h和n。這就是結構風險最小化Structure Risk Minimization,SRM.
SVM就是SRM的近似實現,SVM中的概念另有一大筐。就此打住。
1范數,2范數 的物理意義:
范數,能將一個事物,映射到非負實數,且滿足非負性,齊次性,三角不等式。是一個具有“長度”概念的函數。
1范數為什么能得到稀疏解?
壓縮感知理論,求解與重構,求解一個L1范數正則化的最小二乘問題。其解正是 欠定線性系統的解。
2范數為什么能得到最大間隔解?
2范數代表能量的度量單位,用來重構誤差。
以上幾個概念理解需要補充。
9. 最小描述長度準則:
即一組實例數據,存儲時,利用一模型,編碼壓縮。模型長度,加上壓縮后長度,即為該數據的總的描述長度。最小描述長度準則,就是選擇 總的描述長度最小的模型。
最小描述長度MDL準則,一個重要特性就是避免過度擬合現象。
如利用貝葉斯網絡,壓縮數據,一方面, 模型自身描述長度 隨模型復雜度的增加而增加 ; 另一方面, 對數據集描述的長度隨模型復雜度的增加而下降。因此, 貝葉斯網絡的 MD L總是力求在模型精度和模型復雜度之間找到平衡。當模型過于復雜時,最小描述長度準則就會其作用,限制復雜程度。
奧卡姆剃刀原則:
如果你有兩個原理,它們都能解釋觀測到的事實,那么你應該使用簡單的那個,直到發現更多的證據。
萬事萬物應該盡量簡單,而不是更簡單。
11. 凸松弛技術:
將組合優化問題,轉化為易于求解極值點的凸優化技術。凸函數/代價函數的推導,最大似然估計法。
12. 牛頓法求解 最大似然估計
前提條件:求導迭代,似然函數可導,且二階可導。
迭代公式:
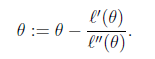
若是 向量形式,
![]()
H就是 n*n 的hessian矩陣了。
特征:當靠近極值點時,牛頓法能快速收斂,而在遠離極值點的地方,牛頓法可能不收斂。 這個的推導?
這點是與梯度下降法的收斂特征是相反的。
線性與非線性:
線性,一次函數;非線性,輸入、輸出不成正比,非一次函數。
線性的局限性:xor問題。線性不可分,形式:
x 0
0 x
而線性可分,是只用一個線性函數,將數據分類。線性函數,直線。
線性無關:各個獨立的特征,獨立的分量,無法由其他分量或特征線性表示。
核函數的物理意義:
映射到高維,使其變得線性可分。什么是高維?如一個一維數據特征x,轉換為(x,x^2, x^3),就成為了一個三維特征,且線性無關。一個一維特征線性不可分的特征,在高維,就可能線性可分了。
邏輯回歸logicalistic regression 本質上仍為線性回歸,為什么被單獨列為一類?
其存在一個非線性的映射關系,處理的一般是二元結構的0,1問題,是線性回歸的擴展,應用廣泛,被單獨列為一類。
而且如果直接應用線性回歸來擬合 邏輯回歸數據,就會形成很多局部最小值。是一個非凸集,而線性回歸損失函數 是一個 凸函數,即最小極值點,即是全局極小點。模型不符。
若采用 邏輯回歸的 損失函數,損失函數就能形成一個 凸函數。
多項式樣條函數擬合
多項式擬合,模型是一個多項式形式;樣條函數,模型不僅連續,而且在邊界處,高階導數也是連續的。好處:是一條光滑的曲線,能避免邊界出現震蕩的形式出現(龍格線性)
以下是幾個需慢慢深入理解的概念:
無結構化預測模型
結構化預測模型
什么是結構化問題?
adaboost, svm, lr 三個算法的關系。
三種算法的分布對應 exponential loss(指數 損失函數), hinge loss, log loss(對數損失函數), 無本質區別。應用凸上界取代0、1損失,即凸松弛技術。從組合優化到凸集優化問題。凸函數,比較容易計算極值點。








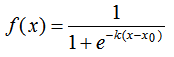



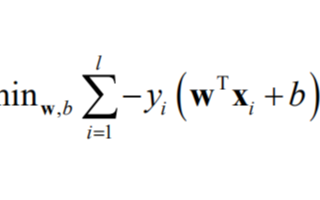








 工商網監
工商網監
評論