 機器學習應用中的常見問題分類問題你了解多少
機器學習應用中的常見問題分類問題你了解多少
分類問題是機器學習應用中的常見問題,而二分類問題是其中的典型,例如垃圾郵件的識別。本文基于UCI機器學習數據庫中的銀行營銷數據集,從對數據集進行探索,數據預處理和特征工程,到學習模型的評估與選擇,較為完整的展示了解決分類問題的大致流程。文中包含了一些常見問題的處理方式,例如缺失值的處理、非數值屬性如何編碼、如何使用過抽樣和欠抽樣的方法解決分類問題中正負樣本不均衡的問題等等。
1. 數據集選取與問題定義
本次實驗選取UCI機器學習庫中的銀行營銷數據集(Bank Marketing Data Set:http://archive.ics.uci.edu/ml/datasets/Bank+Marketing) 。這些數據與葡萄牙銀行機構的直接營銷活動有關。這些直接營銷活動是以電話為基礎的。通常來說,銀行機構的客服人員至少需要聯系一次客戶來得知客戶是否將認購銀行的產品(定期存款)。因此,與該數據集對應的任務是分類任務,而分類目標是預測客戶是(yes)否(no)認購定期存款(變量y)。
數據集包含四個csv文件:
1) bank-additional-full.csv: 包含所有的樣例(41188個)和所有的特征輸入(20個),根據時間排序(從2008年5月到2010年9月);
2) bank-additional.csv: 從1)中隨機選出10%的樣例(4119個);
3) bank-full.csv: 包含所有的樣例(41188個)和17個特征輸入,根據時間排序。(該數據集是更老的版本,特征輸入較少);
4) bank.csv: 從3)中隨機選出10%的樣例4119個)。
提供小的數據集(bank-additional.csv和bank.csv)是為了能夠快速測試一些計算代價較大的機器學習算法(例如SVM)。本次實驗將選取較新的數據集,即包含20個特征量的1)和2)。
2. 認識數據
2.1 數據集輸入變量與輸出變量
數據集的輸入變量是20個特征量,分為數值變量(numeric)和分類(categorical)變量。具體描述見數據集網站http://archive.ics.uci.edu/ml/datasets/Bank+Marketing。
輸出變量為y,即客戶是否已經認購定期存款(binary: "yes", "no")。
2.2 原始數據分析
首先載入數據,

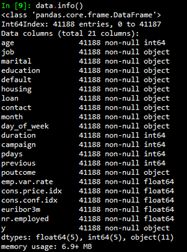
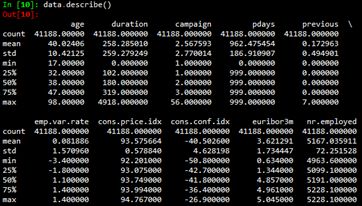
然后使用info()函數和describe()函數查看數據集的基本信息。
3. 數據預處理與特征工程
3.1 缺失值處理
從2.2節給出的數據集基本信息可以看出,數值型變量(int64和float64)沒有缺失。非數值型變量可能存在unknown值。使用如下代碼查看字符型變量unknown值的個數。
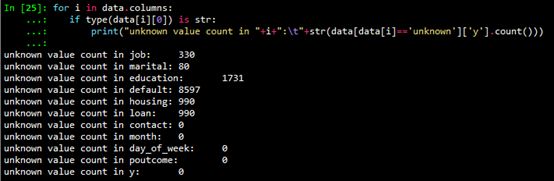
缺失值處理通常有如下的方法:
對于unknown值數量較少的變量,包括job和marital,刪除這些變量是缺失值(unknown)的行;
如果預計該變量對于學習模型效果影響不大,可以對unknown值賦眾數,這里認為變量都對學習模型有較大影響,不采取此法;
可以使用數據完整的行作為訓練集,以此來預測缺失值,變量housing,loan,education和default的缺失值采取此法。由于sklearn的模型只能處理數值變量,需要先將分類變量數值化,然后進行預測。本次實驗使用隨機森林預測缺失值,代碼如下:
def fill_unknown(data, bin_attrs, cate_attrs, numeric_attrs):
# fill_attrs = ['education', 'default', 'housing', 'loan']
fill_attrs = []
for i in bin_attrs+cate_attrs:
if data[data[i] == 'unknown']['y'].count() < 500:
# delete col containing unknown
data = data[data[i] != 'unknown']
else:
fill_attrs.append(i)
data = encode_cate_attrs(data, cate_attrs)
data = encode_bin_attrs(data, bin_attrs)
data = trans_num_attrs(data, numeric_attrs)
data['y'] = data['y'].map({'no': 0, 'yes': 1}).astype(int)
for i in fill_attrs:
test_data = data[data[i] == 'unknown']
testX = test_data.drop(fill_attrs, axis=1)
train_data = data[data[i] != 'unknown']
trainY = train_data[i]
trainX = train_data.drop(fill_attrs, axis=1)
test_data[i] = train_predict_unknown(trainX, trainY, testX)
data = pd.concat([train_data, test_data])
return data
3.2 分類變量數值化
為了能使分類變量參與模型計算,我們需要將分類變量數值化,也就是編碼。分類變量又可以分為二項分類變量、有序分類變量和無序分類變量。不同種類的分類變量編碼方式也有區別。
3.2.1 二分類變量編碼
根據上文的輸入變量描述,可以認為變量default 、housing 和loan 為二分類變量,對其進行0,1編碼。代碼如下:
def encode_bin_attrs(data, bin_attrs):
for i in bin_attrs:
data.loc[data[i] == 'no', i] = 0
data.loc[data[i] == 'yes', i] = 1
return data
3.2.2 有序分類變量編碼
根據上文的輸入變量描述,可以認為變量education是有序分類變量,影響大小排序為"illiterate", "basic.4y", "basic.6y", "basic.9y", "high.school", "professional.course", "university.degree", 變量影響由小到大的順序編碼為1、2、3、...,。代碼如下:
def encode_edu_attrs(data):
values = ["illiterate", "basic.4y", "basic.6y", "basic.9y",
"high.school", "professional.course", "university.degree"]
levels = range(1,len(values)+1)
dict_levels = dict(zip(values, levels))
for v in values:
data.loc[data['education'] == v, 'education'] = dict_levels[v]
return data
3.2.3 無序分類變量編碼
根據上文的輸入變量描述,可以認為變量job,marital,contact,month,day_of_week為無序分類變量。需要說明的是,雖然變量month和day_of_week從時間角度是有序的,但是對于目標變量而言是無序的。對于無序分類變量,可以利用啞變量(dummy variables)進行編碼。一般的,n個分類需要設置n-1個啞變量。例如,變量marital分為divorced、married、single,使用兩個啞變量V1和V2來編碼。
| marital | V1 | V2 |
| divorced | 0 | 0 |
| married | 1 | 0 |
| single | 0 | 1 |
Python的pandas包提供生成啞變量的函數,故代碼如下:
def encode_cate_attrs(data, cate_attrs):
data = encode_edu_attrs(data)
cate_attrs.remove('education')
for i in cate_attrs:
dummies_df = pd.get_dummies(data[i])
dummies_df = dummies_df.rename(columns=lambda x: i+'_'+str(x))
data = pd.concat([data,dummies_df],axis=1)
data = data.drop(i, axis=1)
return data
3.3 數值特征預處理
3.3.1 連續型特征離散化
將連續型特征離散化的一個好處是可以有效地克服數據中隱藏的缺陷: 使模型結果更加穩定。例如,數據中的極端值是影響模型效果的一個重要因素。極端值導致模型參數過高或過低,或導致模型被虛假現象"迷惑",把原來不存在的關系作為重要模式來學習。而離散化,尤其是等距離散,可以有效地減弱極端值和異常值的影響。
通過觀察2.2節的原始數據集的統計信息,可以看出變量duration的最大值為4918,而75%分位數為319,遠小于最大值,而且該變量的標準差為259,相對也比較大。因此對變量duration進行離散化。具體地,使用pandas.qcut()函數來離散化連續數據,它使用分位數對數據進行劃分(分箱: bining),可以得到大小基本相等的箱子(bin),以區間形式表示。然后使用pandas.factorize()函數將區間轉為數值。
data[bining_attr] = pd.qcut(data[bining_attr], bining_num)
data[bining_attr] = pd.factorize(data[bining_attr])[0]+1
3.3.3 規范化
由于不同變量常常使用不同的度量單位,從數值上看它們相差很大,容易使基于距離度量的學習模型更容易受數值較大的變量影響。數據規范化就是將數據壓縮到一個范圍內,從而使得所有變量的單位影響一致。
for i in numeric_attrs:
scaler = preprocessing.StandardScaler()
data[i] = scaler.fit_transform(data[i])
3.3.4 持久化預處理后的數據
由于需要訓練模型預測unknown值,預處理過程的時間代價比較大。因此將預處理后的數據持久化,保存到文件中,之后的學習模型直接讀取文件數據進行訓練預測,無須再預處理。
def preprocess_data():
input_data_path = "../data/bank-additional/bank-additional-full.csv"
processed_data_path = '../processed_data/bank-additional-full.csv'
print("Loading data...")
data = pd.read_csv(input_data_path, sep=';')
print("Preprocessing data...")
numeric_attrs = ['age', 'duration', 'campaign', 'pdays', 'previous',
'emp.var.rate', 'cons.price.idx', 'cons.conf.idx',
'euribor3m', 'nr.employed',]
bin_attrs = ['default', 'housing', 'loan']
cate_attrs = ['poutcome', 'education', 'job', 'marital',
'contact', 'month','day_of_week']
data = shuffle(data)
data = fill_unknown(data, bin_attrs, cate_attrs, numeric_attrs)
data.to_csv(processed_data_path, index=False)
需要注意的是,由于原始數據是有序的(以時間為序),讀取原始數據后,需要將其隨機打亂,變成無序數據集。這里使用sklearn.utils包中的shuffle()函數進行打亂。
一些情況下原始數據維度非常高,維度越高,數據在每個特征維度上的分布就越稀疏,這對機器學習算法基本都是災難性(維度災難)。當我們又沒有辦法挑選出有效的特征時,需要使用PCA等算法來降低數據維度,使得數據可以用于統計學習的算法。但是,如果能夠挑選出少而精的特征了,那么PCA等降維算法沒有很大必要。在本次實驗中,數據集中的特征已經比較有代表性而且并不過多,所以應該不需要降維(實驗證明降維確實沒有幫助)。關于降維的介紹可以參考之前寫的這個博客(http://www.cnblogs.com/llhthinker/p/5522054.html)。
總之,數據預處理對于訓練機器學習算法非常重要,正所謂“garbage in, garbage out”。
4. 模型的訓練與評估
4.1 劃分數據集
首先,需要將處理好的數據集劃分為3部分,分別是訓練集(train set)、交叉檢驗集(Cross validation set)和測試集(test set)。(另見博客學習模型的評估和選擇)。訓練集是用于訓練模型。交叉檢驗集用來進行模型的選擇,包括選擇不同的模型或者同一模型的不同參數,即選擇在交叉檢驗集上的測試結果最優的模型。測試集用于檢測最終選擇的最優模型的質量。通常,可以按照6:2:2的比例劃分,代碼如下:
def split_data(data):
data_len = data['y'].count()
split1 = int(data_len*0.6)
split2 = int(data_len*0.8)
train_data = data[:split1]
cv_data = data[split1:split2]
test_data = data[split2:]
return train_data, cv_data, test_data
4.2 訓練集重采樣
對導入的數據集按如下方式進行簡單統計可以發現,正樣本(y=1)的數量遠小于負樣本(y=0)的數量,近似等于負樣本數量的1/8。
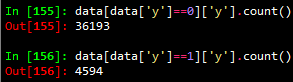
在分類模型中,這種數據不平衡問題會使得學習模型傾向于把樣本分為多數類,但是,我們常常更關心少數類的預測情況。在本次分類問題中,分類目標是預測客戶是(yes:1)否(no:0)認購定期存款(變量y)。顯然,我們更關心有哪些客戶認購定期存款。為減弱數據不均衡問題帶來的不利影響,在數據層面有兩種較簡單的方法:過抽樣和欠抽樣。
過抽樣: 抽樣處理不平衡數據的最常用方法,基本思想就是通過改變訓練數據的分布來消除或減小數據的不平衡。過抽樣方法通過增加少數類樣本來提高少數類的分類性能 ,最簡單的辦法是簡單復制少數類樣本,缺點是可能導致過擬合,沒有給少數類增加任何新的信息,泛化能力弱。改進的過抽樣方法通過在少數類中加入隨機高斯噪聲或產生新的合成樣本等方法。
欠抽樣: 欠抽樣方法通過減少多數類樣本來提高少數類的分類性能,最簡單的方法是通過隨機地去掉一些多數類樣本來減小多數類的規模,缺點是會丟失多數類的一些重要信息,不能夠充分利用已有的信息。
在本次實驗中,采用Smote算法[Chawla et al., 2002]增加新的樣本進行過抽樣;采用隨機地去掉一些多數類樣本的方法進行欠抽樣。Smote算法的基本思想是對于少數類中每一個樣本x,以歐氏距離為標準計算它到少數類樣本集中所有樣本的距離,得到其k近鄰。然后根據樣本不平衡比例設置一個采樣比例以確定采樣倍率N,對于每一個少數類樣本x,從其k近鄰中隨機選擇若干個樣本,構建新的樣本。針對本實驗的數據,為防止新生成的數據噪聲過大,新的樣本只有數值型變量真正是新生成的,其他變量和原樣本一致。重采樣的代碼如下:
def resample_train_data(train_data, n, frac):
numeric_attrs = ['age', 'duration', 'campaign', 'pdays', 'previous',
'emp.var.rate', 'cons.price.idx', 'cons.conf.idx',
'euribor3m', 'nr.employed',]
#numeric_attrs = train_data.drop('y',axis=1).columns
pos_train_data_original = train_data[train_data['y'] == 1]
pos_train_data = train_data[train_data['y'] == 1]
new_count = n * pos_train_data['y'].count()
neg_train_data = train_data[train_data['y'] == 0].sample(frac=frac)
train_list = []
if n != 0:
pos_train_X = pos_train_data[numeric_attrs]
pos_train_X2 = pd.concat([pos_train_data.drop(numeric_attrs, axis=1)] * n)
pos_train_X2.index = range(new_count)
s = smote.Smote(pos_train_X.values, N=n, k=3)
pos_train_X = s.over_sampling()
pos_train_X = pd.DataFrame(pos_train_X, columns=numeric_attrs,
index=range(new_count))
pos_train_data = pd.concat([pos_train_X, pos_train_X2], axis=1)
pos_train_data = pd.DataFrame(pos_train_data, columns=pos_train_data_original.columns)
train_list = [pos_train_data, neg_train_data, pos_train_data_original]
else:
train_list = [neg_train_data, pos_train_data_original]
print("Size of positive train data: {} * {}".format(pos_train_data_original['y'].count(), n+1))
print("Size of negative train data: {} * {}".format(neg_train_data['y'].count(), frac))
train_data = pd.concat(train_list, axis=0)
return shuffle(train_data)
4.3 模型的訓練與評估
常用的分類模型包括感知機,SVM,樸素貝葉斯,決策樹,logistic回歸,隨機森林等等。本次實驗選擇logistic回歸和隨機森林在訓練集上進行訓練,在交叉檢驗集上進行評估,隨機森林的表現更優,所以最終選擇隨機森林模型在測試集上進行測試。
對于不同的任務,評價一個模型的優劣可能不同。正如4.2節中所言,實驗選取的數據集是不平衡的,數據集中負樣本0值占數據集總比例高達88.7%,如果我們的模型"預測"所有的目標變量值都為0,那么準確度(Accuracy)應該在88.7%左右。但是,顯然,這種"預測"沒有意義。所以,我們更傾向于能夠預測出正樣本(y=1)的模型。因此,實驗中將正樣本的f1-score作為評價模型優劣的標準(也可以用其他類似的評價指標如AUC)。訓練與評估的代碼如下:
def train_evaluate(train_data, test_data, classifier, n=1, frac=1.0, threshold = 0.5):
train_data = resample_train_data(train_data, n, frac)
train_X = train_data.drop('y',axis=1)
train_y = train_data['y']
test_X = test_data.drop('y', axis=1)
test_y = test_data['y']
classifier = classifier.fit(train_X, train_y)
prodict_prob_y = classifier.predict_proba(test_X)[:,1]
report = classification_report(test_y, prodict_prob_y > threshold,
target_names = ['no', 'yes'])
prodict_y = (prodict_prob_y > threshold).astype(int)
accuracy = np.mean(test_y.values == prodict_y)
print("Accuracy: {}".format(accuracy))
print(report)
fpr, tpr, thresholds = metrics.roc_curve(test_y, prodict_prob_y)
precision, recall, thresholds = metrics.precision_recall_curve(test_y, prodict_prob_y)
test_auc = metrics.auc(fpr, tpr)
plot_pr(test_auc, precision, recall, "yes")
return prodict_y
利用訓練評估函數可以進行模型的選擇,分別選擇Logistic回歸模型和隨機森林模型,并對其分別調整各自參數的取值,最終選擇f1-score最高的隨機森林模型。具體地,當將n_estimators設置為400,對正樣本進行7倍的過抽樣(n=7),不對負樣本進行負抽樣(frac=1.0),正樣本分類的閾值為0.40(threshold),即當預測某樣本屬于正樣本的概率大于0.4時,就將該樣本分類為正樣本。
forest = RandomForestClassifier(n_estimators=400, oob_score=True) prodict_y = train_evaluate(train_data, test_data, forest, n=7, frac=1, threshold=0.40)
該模型在交叉檢驗集上的評估結果如下:
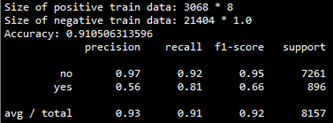
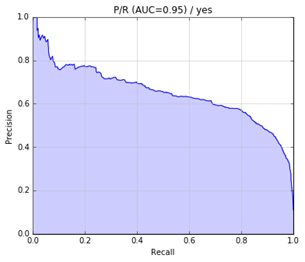
precision-recall曲線如下:
最后,將該模型應用于測試集,測試結果如下:
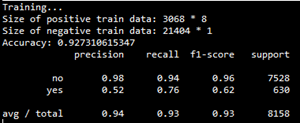
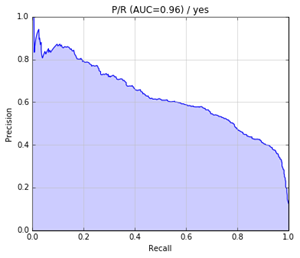
precision-recall曲線如下:
5. 展望
還可以考慮以下幾個方面以提高F1得分:
更細致的特征選擇,如派生屬性;
采用更好的方法解決數據不平衡問題,如代價敏感學習方法;
更細致的調參;
嘗試其他分類模型如神經網絡;
-
編程
+關注
關注
88文章
3637瀏覽量
93905 -
機器
+關注
關注
0文章
784瀏覽量
40777
原文標題:機器學習之分類問題實戰
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
干貨 | 這些機器學習算法,你了解幾個?
講講UCOSIII移植過程中的常見問題
機器學習分類算法中必須要懂的四種算法
你了解機器學習中的線性回歸嗎
目前機器學習面臨的常見問題和挑戰






 工商網監
工商網監
評論