 電子發(fā)燒友App
電子發(fā)燒友App


作者 |?Timothée Lacroix
選擇正確的 LLM 推理棧意味著選擇適合你的任務(wù)的正確模型,并配以適當(dāng)?shù)耐评泶a在適當(dāng)?shù)?a href="http://m.1cnz.cn/v/tag/1751/" target="_blank">硬件上運行。本文介紹了流行的 LLM 推理堆棧和設(shè)置,詳細(xì)說明其推理的成本構(gòu)成;并討論當(dāng)前的開源模型以及如何充分利用它們,同時還涉及當(dāng)前開源服務(wù)棧中仍然缺失的功能,以及未來模型將解鎖的新功能。
本文源自 Mistral AI 首席技術(shù)官 Timothée Lacroix 的演講。他于 2015 年在 Facebook AI Research 擔(dān)任工程師,于 2016 年至 2019 年間與école des Ponts 合作完成了關(guān)于推薦系統(tǒng)的張量分解的論文。2023 年他成為 Mistral AI 的聯(lián)合創(chuàng)始人。Mistral AI 于近期發(fā)布了業(yè)內(nèi)首個開源 MoE 大模型 Mixtral-8x7B。
本次演講的很多內(nèi)容都基于我在網(wǎng)上找到的信息或通過對第一個 LLaMA 版本模型進(jìn)行實驗時的發(fā)現(xiàn)。我認(rèn)為,現(xiàn)在的 Mistral 更關(guān)注推理成本,而非訓(xùn)練成本。因此,我將分享推理成本的構(gòu)成、吞吐、時延及其影響因素。

很多人想要部署語言大模型,我將分享如何使用開源工具部署自己的語言大模型。當(dāng)然,你也可以使用一些出色的公共 API,但我對開源工具更感興趣,所以接下來我將深入討論部署一個 70 億參數(shù)模型的重要細(xì)節(jié)。我將分享的許多內(nèi)容也同樣適用于更大規(guī)模的模型,但那需要更多 GPU。
影響推理的指標(biāo)
我們將首先討論有哪些重要指標(biāo),以及這些指標(biāo)的影響因素,包括硬件和軟件層面。接下來,我將介紹一些能夠改善性能的技巧,據(jù)我所知,其中一些技巧還未獲得廣泛實現(xiàn)。我嘗試在各種不同的硬件上運行了一系列模型,并嘗試獲得性能曲線,我認(rèn)為實例非常重要,所以我將通過這些數(shù)據(jù)得出結(jié)論。

首先,我們該關(guān)注哪些指標(biāo)?第一是吞吐量,以每秒查詢數(shù)(Query/second)表示,我們希望在批處理作業(yè)中將這一指標(biāo)最大化,或者希望允許更多用戶使用我們的服務(wù)。第二是時延,以每詞元每秒(seconds/token)表示,即輸出下一個詞元所需的時間,這決定了你的應(yīng)用程序的速度和靈敏度。在 ChatGPT 中,這一速度相當(dāng)快。對于較小的模型,可以更輕松地實現(xiàn)快速響應(yīng),因此我們希望將這個值最小化以提升用戶體驗。較為優(yōu)秀的閾值是每分鐘輸出 250 個單詞,我認(rèn)為這是人類的平均閱讀速度,只要你的時延低于這個值,用戶就不會感到無聊。第三是成本,毫無疑問,這一數(shù)值越低越好。
影響推理指標(biāo)的因素

現(xiàn)在我將深入探討這些指標(biāo)的影響因素。我只會談?wù)撟曰貧w解碼,即基于一批批詞元通過神經(jīng)網(wǎng)絡(luò)確定下一批詞元,這部分不包括處理查詢的第一部分。提示處理有時被稱為預(yù)填充(prefill)部分,我們會一次性將大量詞元輸入到神經(jīng)網(wǎng)絡(luò)中,這部分處理通常已經(jīng)經(jīng)過充分優(yōu)化,挑戰(zhàn)性相對較低。

考慮到這一點,我們對大小為 P 的模型的推理感興趣。可以假設(shè) P 是 7B,為執(zhí)行一步推理,大約需要 2xPxBatch_size 的 FLOPs(浮點運算數(shù))。在進(jìn)行這些浮點運算時,我們需要將整個模型加載到實際運行計算的 GPU,并且需要一次性加載整個模型,即大致上需要的內(nèi)存搬運(memory movement)量等于模型的參數(shù)數(shù)量。

這兩個數(shù)量有趣的地方在于,第一個數(shù)量受硬件浮點運算能力的限制,即 GPU 可以實現(xiàn)的浮點運算次數(shù),并且與批大小呈線性關(guān)系,在上述圖表上呈增長趨勢。除非批大小特別大,內(nèi)存移動量并不隨批大小而變化。但正如我所說,這種情況已經(jīng)得到了相當(dāng)程度的優(yōu)化,所以我們并不太關(guān)心內(nèi)存移動量。我們還有一個常量,即模型大小除以內(nèi)存帶寬,這是一次性加載整個模型所需的最短時間,每次都需要重新執(zhí)行這個操作。
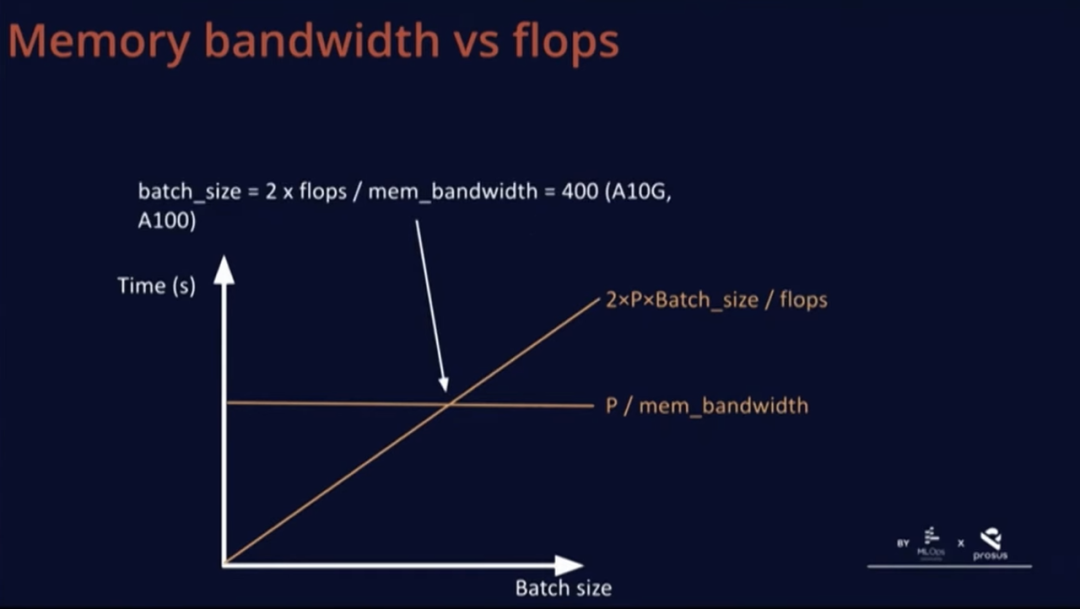
還有一個與批次大小有關(guān)的數(shù)量,它們在一個有趣的點上相交。這個點不取決于硬件之外的任何因素。舉例來說,在 A10G 和 A100 上,硬件可以實現(xiàn)的總浮點運算次數(shù)的兩倍除以內(nèi)存帶寬為 400。

B*這個批大小非常有趣,因為低于這一批大小,基本上是在浪費 FLOPs,因為計算受到了內(nèi)存限制,我們在等待 GPU 加載數(shù)據(jù),而計算速度太快,圖中某部分的時延是恒定的。如果超過這個 B*這個閾值,時延就會開始增加,就變成了計算受限。
因此,B* 的真正優(yōu)勢在于,這個批大小的時延范圍是最優(yōu)的,因此用戶體驗是最佳的,同時也沒有浪費任何 FLOPs。

不管怎樣,我們理想的批大小 B* 是 400,這個值似乎相當(dāng)大,所以我們來計算一下 LLaMA 等模型規(guī)模的幾項指標(biāo)。LLaMA 模型有 4K 個維度,深度 32 層,模型大小很容易計算,在 FP16 中每個模型權(quán)重占兩個字節(jié),所以只需 2x7=14GB 內(nèi)存。
然后,我們用 KV 緩存存儲計算結(jié)果,這樣當(dāng)我們重新編碼一個新詞元時,就不必重新從頭計算。KV 緩存的大小為 2,包括 K 緩存和 V 緩存,且使用 FP16 格式,每個都乘以 2,然后每層有一個 KV 緩存,并且必須為批次中的每個元素保存數(shù)據(jù),每個位置在序列中表示一個詞元,然后乘以維度。

把實際數(shù)值代入這個公式發(fā)現(xiàn),每個批次元素需要約 2G 內(nèi)存才能支持最大長度 4K,因此,在 A10(24GB 內(nèi)存)上,我們的最大批大小約為 5,在更大的 A100(80GB 內(nèi)存)上,最大批大小只有 33 左右,這仍遠(yuǎn)低于理想值 400。
因此,對于所有實際用例,使用 70 億參數(shù)的模型進(jìn)行推理時,解碼過程將嚴(yán)重受限于內(nèi)存帶寬。這也證明了 Mistral 從一開始就非常謹(jǐn)慎的一點:模型和 KV 緩存所占內(nèi)存的大小確實影響了可允許的最大批大小,而最大批大小直接決定了效率的高低。
實用技巧
現(xiàn)在我將深入討論一些已經(jīng)存在但我個人很喜歡的技巧。其中一部分已經(jīng)為 Mistral 所用,其他一些尚未在 Mistral 中得到應(yīng)用,還有些則更多地涉及軟件部署層面。
分組查詢注意力

第一個技巧是分組查詢注意力。分組查詢注意力是通過每個查詢使用更少的鍵和值來減少 KV 緩存的方法。這在 LLaMA 2 中使用過,但只用于較大的模型尺寸,而非 70 億參數(shù)模型。在標(biāo)準(zhǔn)的多頭注意力中,有多少查詢,就有多少鍵和值。而在分組查詢注意力中,一對鍵值與一組查詢相關(guān)聯(lián)。在 Mistral,我們的每個鍵和值使用四個查詢,因此要執(zhí)行的浮點運算量將保持不變,但內(nèi)存開銷只有原來的四分之一。這是一個簡單的技巧,不會對性能造成實質(zhì)性損害,這一做法很不錯。
量化

第二個技巧是量化,對此我們并沒有進(jìn)行專門研究,但尤其在 LLaMA 發(fā)布后,這項技術(shù)發(fā)展得非常迅速。很多優(yōu)秀的現(xiàn)成解決方案為許多開源社區(qū)的人所使用,提供了模型的 int8 或 int4 版本。使用 int8 時,模型尺寸會減半,在使用 int4 時,會減少至四分之一。
這不會改變最優(yōu)批大小,因為這一比率只取決于硬件,與其他因素?zé)o關(guān)。就計算速度而言,量化后的速度為原來的兩倍,但我們發(fā)現(xiàn),對于 Mistral 模型規(guī)模以及其他模型,很難達(dá)到這個速度,如果以純浮點運算量衡量,1.5 倍的速度更為合理。使用 int8 還會機械地增加 KV 緩存的可用內(nèi)存。
因此,如果你處于內(nèi)存受限的狀態(tài),一切操作都會快兩倍,這很不錯。另一個好處是,int8 幾乎沒有或者只有極小的精度損失,而在 int4 下會有一些性能損失,但似乎可以通過 QLoRA 來恢復(fù),或者如果你只關(guān)心特定用例,那么我認(rèn)為這也可以正常運作,且 serving 成本會低得多。
分頁注意力(Paged Attention)

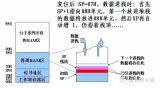
第三個技巧是分頁注意力,由來自伯克利的 vLLM 專家提出。沒有分頁注意力的 KV 緩存是矩形的,需要分配一個大矩形內(nèi)存,其中一個維度是批大小,即模型一次可以處理的最大序列數(shù),另一個維度是,允許用戶使用的最大序列長度。當(dāng)一個新序列進(jìn)來時,會為這個用戶分配一整行內(nèi)存,但這并不理想,因為用戶中很可能只有 10% 會使用整行內(nèi)存,而大多數(shù)用戶可能只會發(fā)起短請求。因此,這最終會浪費硬件內(nèi)存中的大量寶貴空間。

分頁注意力的作用是在 GPU 內(nèi)存中分配塊(block)。首先,加載模型以了解剩余空間大小,然后用內(nèi)存塊填充剩余部分。這些塊可以容納多達(dá) 16 到 32 個詞元,當(dāng)新序列到來時,就可以為 prompt 分配所需的內(nèi)存塊,然后根據(jù)需要逐漸擴(kuò)展。
在上述示意圖中,可以看到序列并不一定分配在連續(xù)的內(nèi)存塊上,例如橙色、藍(lán)色或綠色并不在連續(xù)的塊上,這并不重要。這種方式能夠更精細(xì)地控制內(nèi)存分配,因此在示意圖中,右側(cè)完全空閑的部分可以用于新來的序列,一旦序列解碼完成,就可以釋放已使用的塊,非常高效。分頁注意力的提出者稱,與標(biāo)準(zhǔn)的實現(xiàn)方法相比,分頁注意力可以增加約 20 倍的吞吐量,這聽起來并不是那么遙不可及。
滑動窗口注意力 (Sliding Window Attention)
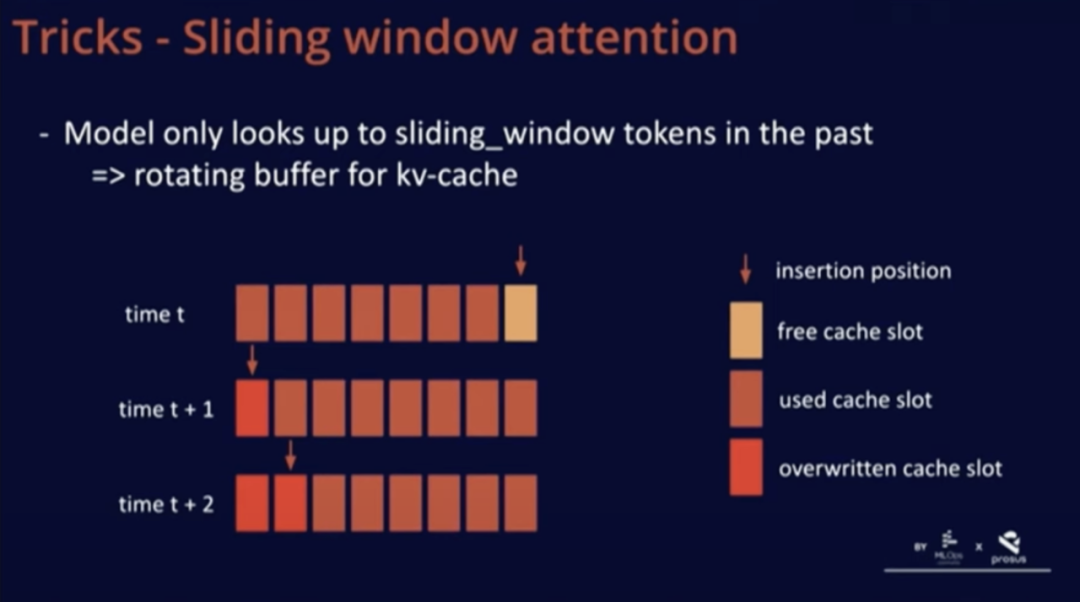
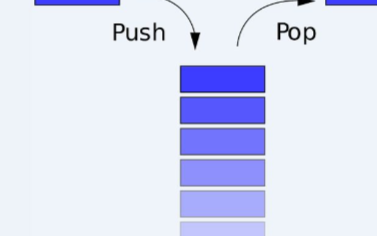
我們在 Mistral 中添加了一個技巧,即滑動窗口注意力。通過這個技巧,我們可以訓(xùn)練模型在緩存中僅使用過去的 K 個詞元。這樣做的好處在于,我們可以使用一個固定的緩存大小。
眾所周知,一個序列一旦超過滑動窗口的詞元數(shù)量,我們就可以在緩存中循環(huán)覆寫,從而重新開始,而這不會影響模型性能。
進(jìn)一步來說,通過這個技巧,我們可以使用比滑動窗口更大的長下文長度。我們在博客文章或 GitHub 上對此進(jìn)行了簡要描述。
對于這個技巧的良好實現(xiàn)是將 KV 緩存看作是一個循環(huán)緩沖區(qū)。在上圖中的 t 時刻,我們在緩存的最后位置插入;在 t+1 時刻,由于序列超出了滑動窗口,所以只進(jìn)行了覆寫操作。這種實現(xiàn)非常簡單,因為緩存中的位置并不重要,所有與位置相關(guān)的信息都通過位置嵌入進(jìn)行編碼。總之,這種方法兼具易可實現(xiàn)性和有效性。
連續(xù)批處理(Continuous Batching)

還有一個技巧是連續(xù)批處理。正如我在前面提到的,預(yù)填充階段同時處理的詞元數(shù)量要比解碼階段多得多。因此,我們可以嘗試將這些詞元與解碼詞元一起進(jìn)行批處理。我在 vLLM 和 TGI 中都注意到了同一個問題,即它們沒有嘗試對預(yù)填充階段進(jìn)行分塊處理。如果一個用戶向模型發(fā)送一個包含 4K 詞元的提示,這將增加所有用戶的時延,因為我們需要花費大量時間一次性處理這些詞元。
這其實是一種浪費,因為這時模型就不再處于既能實現(xiàn)低時延,又能充分利用計算資源的最佳狀態(tài)。因此,我建議在這些軟件中對預(yù)填充進(jìn)行分塊處理,這樣我們一次只處理 K 個詞元。這種方法能夠更加精細(xì)地分配資源,并且能夠更好地對解碼和預(yù)填充進(jìn)行批處理。
代碼

最后一種技巧是代碼。在處理這些規(guī)模的模型時,代碼性能非常重要。通常,我們可以觀察到 Python 代碼的開銷很大。雖然我沒有詳細(xì)分析過 vLLM 和 TGI 的性能,但它們運行的是 Python 代碼,根據(jù)經(jīng)驗,在這些規(guī)模下通常會存在一定的額外開銷。我們可以采取一些方法,在不影響 Python 大部分優(yōu)點的前提下緩解這一問題。
xFormers 庫就是一個很好的示例,它使用 CUDA 圖實現(xiàn)了零開銷。NVIDIA 的 TensorRT 可以通過追蹤推理并利用模式匹配來自動提高性能。此外,我們還可以使用自定義內(nèi)核(如融合)來減少內(nèi)存帶寬,這樣可以避免在內(nèi)存中來回移動數(shù)據(jù)。在數(shù)據(jù)已加載的情況下,我們可以執(zhí)行激活等操作,通常可以找到激活函數(shù)等優(yōu)化技巧,然后輕松地將它們插入到代碼中。

總之,驅(qū)動這些性能指標(biāo)的因素主要是硬件中的固定浮點運算與內(nèi)存帶寬之間的比率。這給出了最小批大小 B*,以充分利用硬件資源,避免浪費不必要的浮點運算。這個大小主要由硬件決定,不太受模型影響,除非你使用了 Transformer 之外的非傳統(tǒng)架構(gòu)。由于設(shè)備的內(nèi)存有限,因此要達(dá)到最佳批大小并不容易。
我檢查了兩個用于部署模型的開源庫,它們?nèi)栽谶\行 Python 代碼,在這一規(guī)模下,模型會產(chǎn)生很多額外開銷。我還研究了 Faster Transformer 項目,它沒有額外開銷,但部署起來會比較困難。上述信息主要來自博文《語言大模型的推理演算》。
不同配置下的吞吐、時延與成本
現(xiàn)在讓我們談?wù)勍掏铝?- 時延平面圖,這通常是我評判這些指標(biāo)的方式。在這個平面中,x 軸表示時延,y 軸表示吞吐量,我們主要關(guān)注上方和左方,即更好的吞吐量和更低的時延。
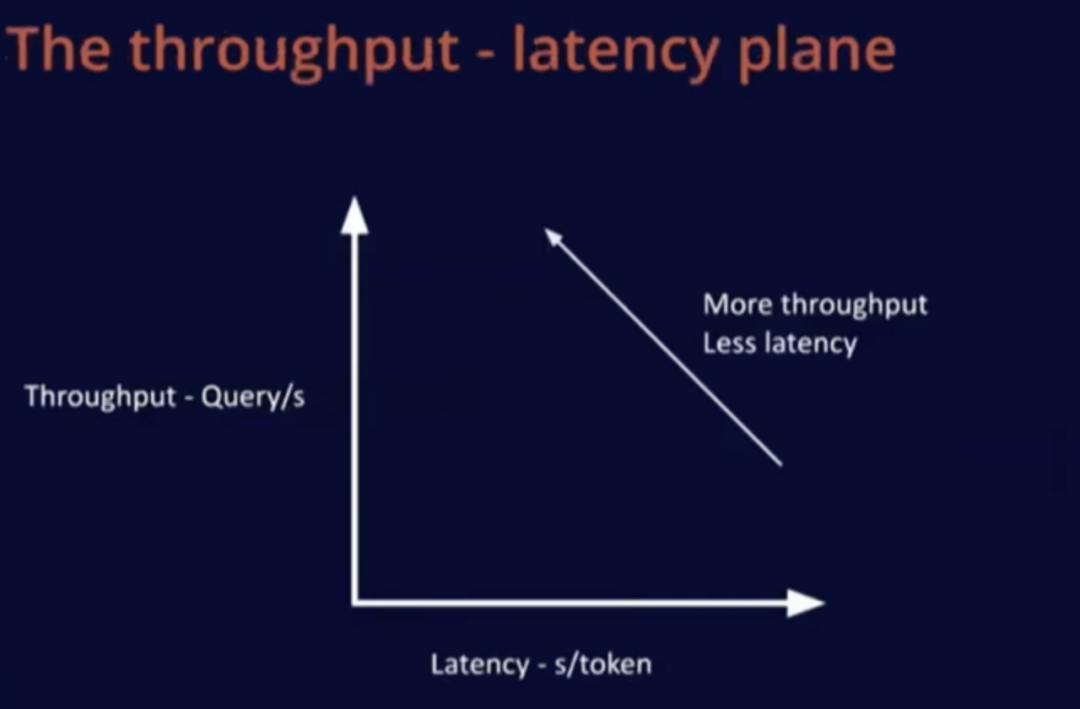
如果購買更好的硬件,會改變這一吞吐量 - 時延性能曲線。對于固定硬件,左下角區(qū)域是固定時延,即內(nèi)存受限區(qū)域。隨著批大小增加,系統(tǒng)從內(nèi)存受限區(qū)域轉(zhuǎn)變?yōu)橛嬎闶芟迏^(qū)域。如果購買更先進(jìn)的硬件,成本會更高,但吞吐量 - 時延上的所有曲線會整體向左上方移動。
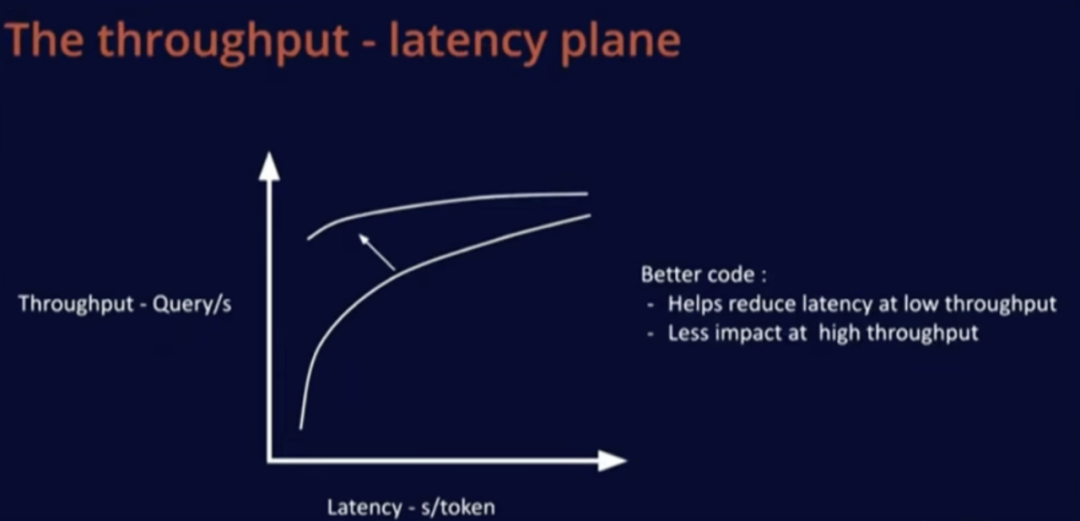
改進(jìn)代碼或采用更好的模型會在低時延區(qū)域產(chǎn)生顯著影響,增加吞吐量,這對大型批大小的影響較小,因為這時候優(yōu)化已經(jīng)相對容易。

下面是一些性能測試結(jié)果及免責(zé)聲明,這個測試是我在短時間內(nèi)完成的,因為使用 Mistral 和 LLaMA 等配置工具比較容易,我運行了 vLLM 基準(zhǔn)測試腳本。我不確定這些結(jié)果是否是我能取得的最佳結(jié)果,但至少整體方向是正確的,下面是我復(fù)制粘貼過來的 Matplotlib 圖,以供參考。
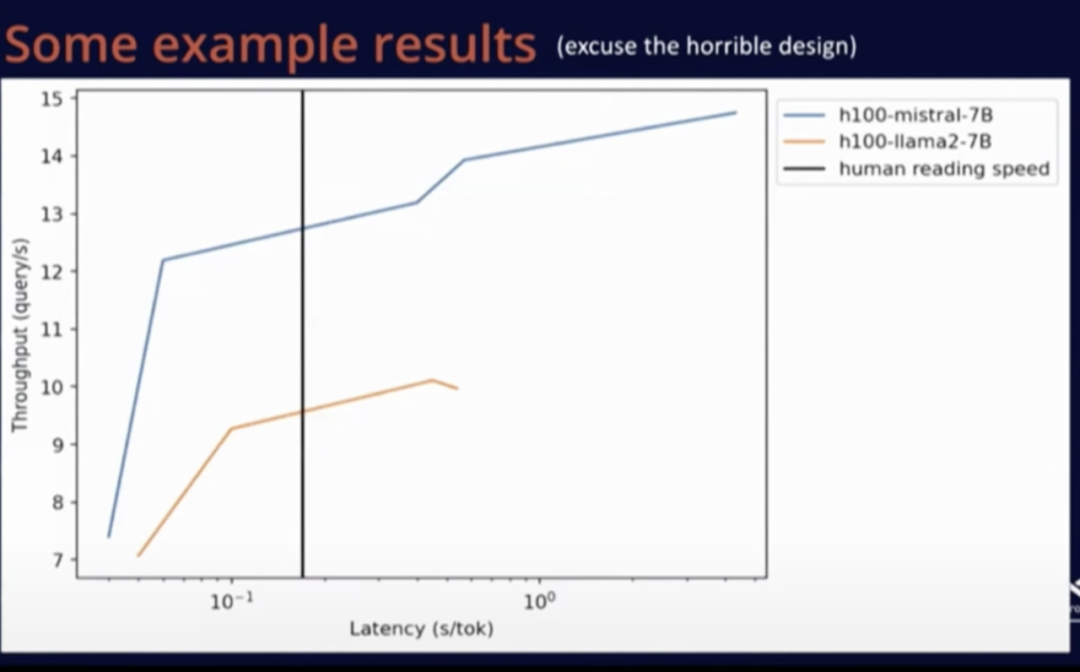
上圖是 Mistral 和 LLaMA 的性能比較。圖中黑線表示人類的閱讀速度。
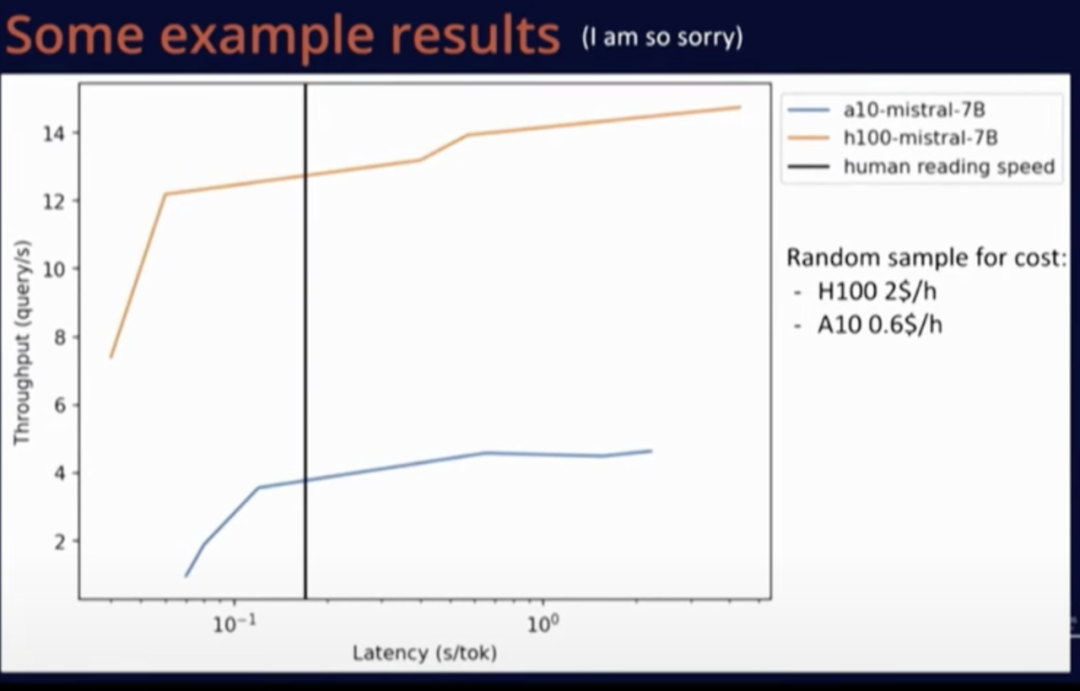
上圖是在同一模型中,A10 和 H100 這兩種硬件之間的比較。可以看到,盡管 H100 價格更高,但由于其卓越的性能,更換硬件是一種更明智的選擇,而不是繼續(xù)使用老硬件。

總的來說,使用開源代碼在小型實例上部署小型模型非常容易,無需任何額外操作就能取得良好的運行效果。僅需約 15 美元 / 天(并不算太高的費用),我們就可以在 A10 上使用 Mistral-7B 模型處理上百萬個請求。改變模型精度可能使服務(wù)的請求數(shù)量翻倍。
開源部署解決方案在易用性方面表現(xiàn)出色,我認(rèn)為在實際的模型代碼部分還有很多工作要做。此外我認(rèn)為,未來模型的速度會越來越快。
答聽眾問 問題 1:如何選擇用于特定模型的最佳處理器?
Timothe?e Lacroix : 我還沒有測試過專用的 AI 硬件,主要測試過一系列 GPU。我甚至還沒有在 MacBook 上運行過模型,因為目前沒有找到合適的用途,但后續(xù)我可能會嘗試。對于用戶而言,如果只是想與模型聊天,直接在 MacBook 上運行更經(jīng)濟(jì)。當(dāng)每天需要處理的請求達(dá)到一百萬次時,使用 A10 會非常劃算,相當(dāng)于每天 15 美元的費用,如果用戶能夠負(fù)擔(dān)這一費用,那么我建議選擇 A10 處理器,它易于部署,而且效果很好。
關(guān)于選擇何種規(guī)模的硬件,由于硬件在任何地方都很容易部署,我們可以從最便宜的硬件開始,如果沒有達(dá)到所需的吞吐量或速度,再考慮升級。
我曾提到,在考慮成本的情況下,相比使用一堆 A10 處理器,H100 是更明智的選擇。然而,我們也經(jīng)常面臨可用性問題。因此,我建議按照處理器的成本和可用性順序逐個嘗試。如果你嘗試使用這些處理器大約 20 分鐘,這樣做的成本相對較低,并且這大致是運行基準(zhǔn)測試所需的最長時間。通過這種方式,你可以在短時間內(nèi)獲得特定用例的準(zhǔn)確成本和性能數(shù)據(jù),從而更好地選擇適合自己需求的處理器。
問題 2: 是否推薦使用 Mojo 來減少 Python 開銷?你是否嘗試過使用 Mojo?
Timothe?e Lacroix:完全沒有。我首次嘗試減少開銷是通過使用 CUDA 圖,雖然在調(diào)試過程中有一些困難,但隨著時間推移,情況已經(jīng)好轉(zhuǎn)了,XFormers 就是一個很好的例子。在未來,torch.compile 也許能有效降低 Python 開銷,但我不清楚它們在處理可變序列長度等方面的進(jìn)展如何。總之,我非常推薦 CUDA 圖,這是我目前降低開銷的首選方法。
問題 3:如果我們想要 LLM 具備多語理解能力,但目前數(shù)據(jù)集主要是英文,相比起來,使用非英文數(shù)據(jù)進(jìn)行微調(diào)的效果并不理想,對于這種情況,最有效的策略是什么?
Timothe?e Lacroix:LLM 的一切能力都源自數(shù)據(jù),所以我們首先需要獲取目標(biāo)語言數(shù)據(jù)。所有 LLM 都是在維基百科上訓(xùn)練的,這為模型掌握多語能力打下了良好基礎(chǔ),這也解釋了為何模型可以在未經(jīng)特別訓(xùn)練的情況下理解一些法語。我認(rèn)為,讓模型掌握多語能力存在一種權(quán)衡,例如,如果模型在法語方面取得了進(jìn)步,就會略微損失其他語言能力,但這種損失并不明顯,是可以接受的,因為整體而言,在其他語言上的性能提升可能更為顯著。
OneDiff 是一個開箱即用的圖片 / 視頻生成推理引擎。開源版最新功能:1. 切換圖片尺寸無需重新編譯(即沒有時間消耗);2. 更快地保存和加載圖;3. 更小的靜態(tài)內(nèi)存。
?
審核編輯:黃飛
?

























 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論