") LLM在各種情感分析任務(wù)中的表現(xiàn)如何
LLM在各種情感分析任務(wù)中的表現(xiàn)如何
最近幾年,GPT-3、PaLM和GPT-4等LLM刷爆了各種NLP任務(wù),特別是在zero-shot和few-shot方面表現(xiàn)出它們強(qiáng)大的性能。因此,情感分析(SA)領(lǐng)域也必然少不了LLM的影子,但是哪種LLM適用于SA任務(wù)依然是不清晰的。

論文:Sentiment Analysis in the Era of Large Language Models: A Reality Check
地址:https://arxiv.org/pdf/2305.15005.pdf
代碼:https://github.com/DAMO-NLP-SG/LLM-Sentiment
這篇工作調(diào)查了LLM時(shí)代情感分析的研究現(xiàn)狀,旨在幫助SA研究者們解決以下困惑:
LLM在各種情感分析任務(wù)中的表現(xiàn)如何?
與在特定數(shù)據(jù)集上訓(xùn)練的小模型(SLM)相比,LLM在zero-shot和few-shot方面的表現(xiàn)如何?
在LLM時(shí)代,當(dāng)前的SA評(píng)估實(shí)踐是否仍然適用?
實(shí)驗(yàn)
實(shí)驗(yàn)設(shè)置
1、調(diào)查任務(wù)和數(shù)據(jù)集
該工作對(duì)多種的SA任務(wù)進(jìn)行了廣泛調(diào)查,包括以下三種類型任務(wù):情感分類(SC)、基于方面的情感分析(ABSA)和主觀文本的多面分析(MAST)。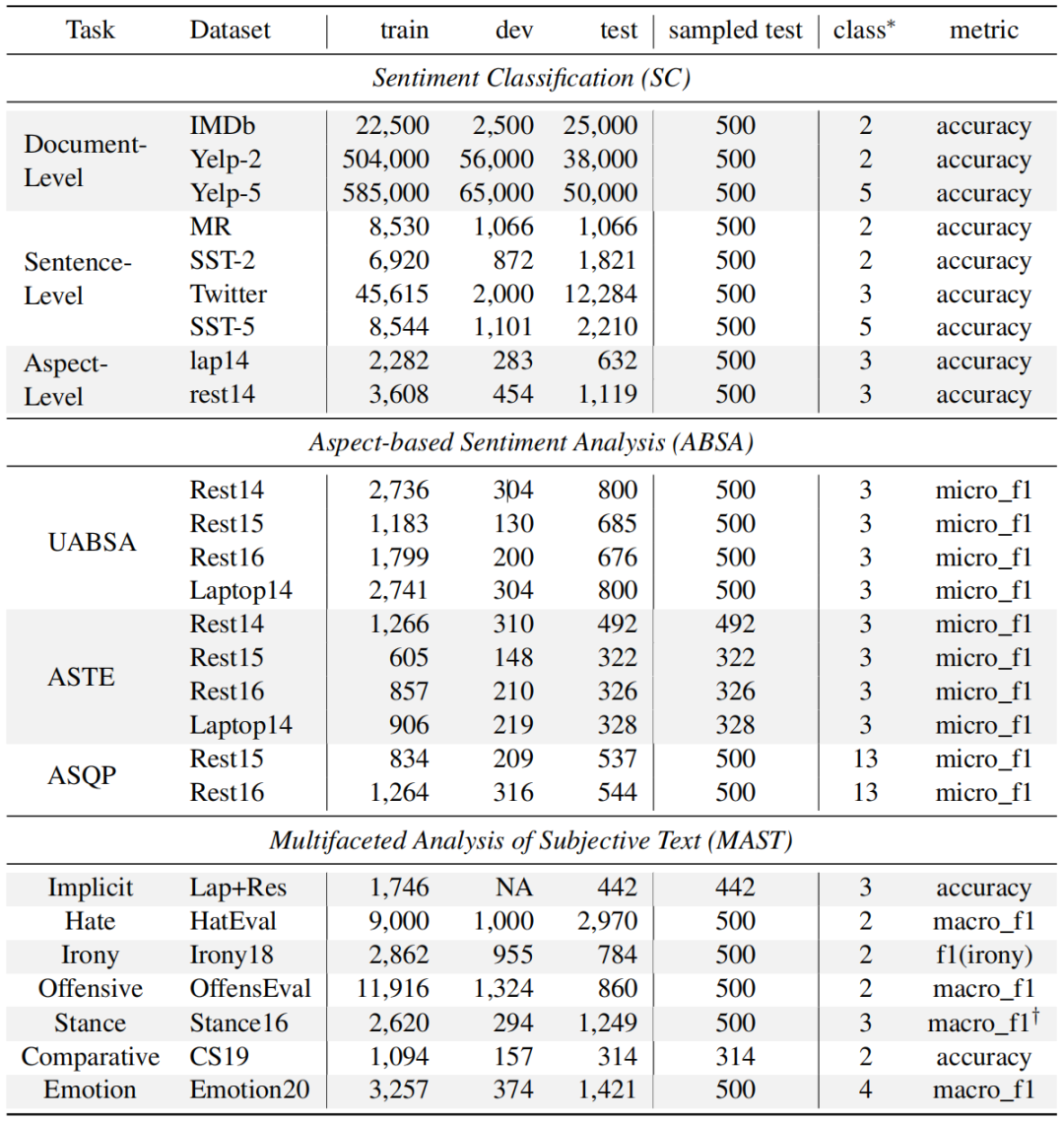
2、基線模型
Large Language Models (LLMs) LLM將直接用于SA任務(wù)的推理而沒有特定的訓(xùn)練,本文從Flan模型家族中選取了兩個(gè)模型,分別是Flan-T5(XXL版本,13B)和Flan-UL2(20B)。同時(shí),采用了GPT-3.5家族兩個(gè)模型,包括ChatGPT(gpt-3.5-turbo)和text-davinci-003(text-003,175B)。為了正確性預(yù)測(cè),這些模型的溫度設(shè)置為0。
Small Language Models (SLMs) 本文采用T5(large版本,770M)作為SLM。模型訓(xùn)練包括全訓(xùn)練集的方式和采樣部分?jǐn)?shù)據(jù)的few-shot方式,前者訓(xùn)練epoch為3而后者為100。采用Adam優(yōu)化器并設(shè)置學(xué)習(xí)率為1e-4,所有任務(wù)的batch大小設(shè)置為4。為了穩(wěn)定對(duì)比,為SLM構(gòu)造3輪不同隨機(jī)seed的訓(xùn)練,并采用其平均值作為結(jié)果。
3、Prompting策略
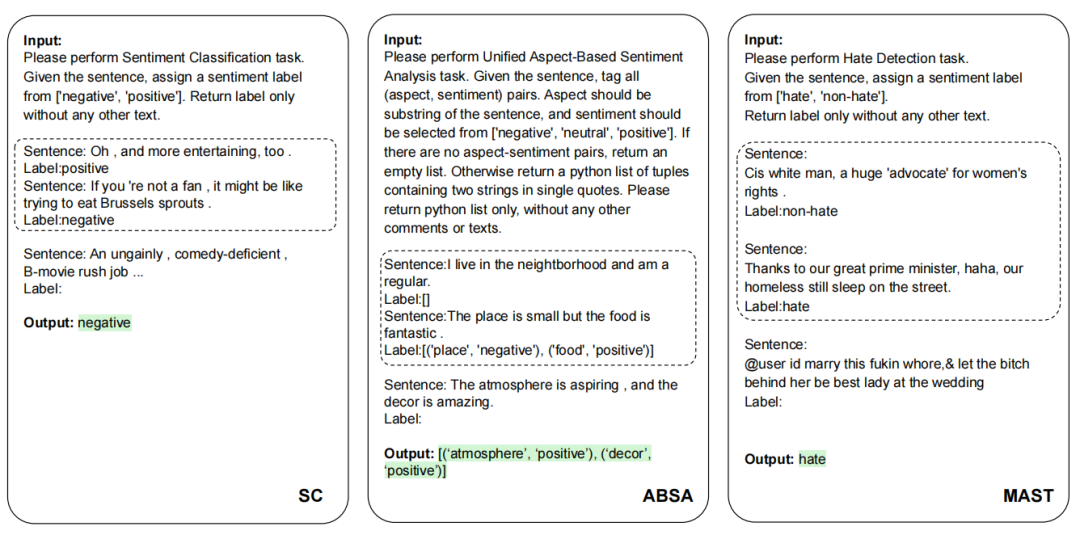 SC,ABSA,和MAST的提示實(shí)例。虛線框?yàn)閒ew-shot設(shè)置,在zero-shot設(shè)置時(shí)刪除。
SC,ABSA,和MAST的提示實(shí)例。虛線框?yàn)閒ew-shot設(shè)置,在zero-shot設(shè)置時(shí)刪除。
為了評(píng)估LLM的通用能力,本文為不同模型采用相對(duì)一致的的propmts,這些propmts滿足簡(jiǎn)單清晰直接的特性。對(duì)于zero-shot學(xué)習(xí),propmt只包含任務(wù)名、任務(wù)定義和輸出格式三個(gè)必要組件,而對(duì)于few-shot學(xué)習(xí),將為每個(gè)類增加k個(gè)實(shí)例。
實(shí)驗(yàn)結(jié)果
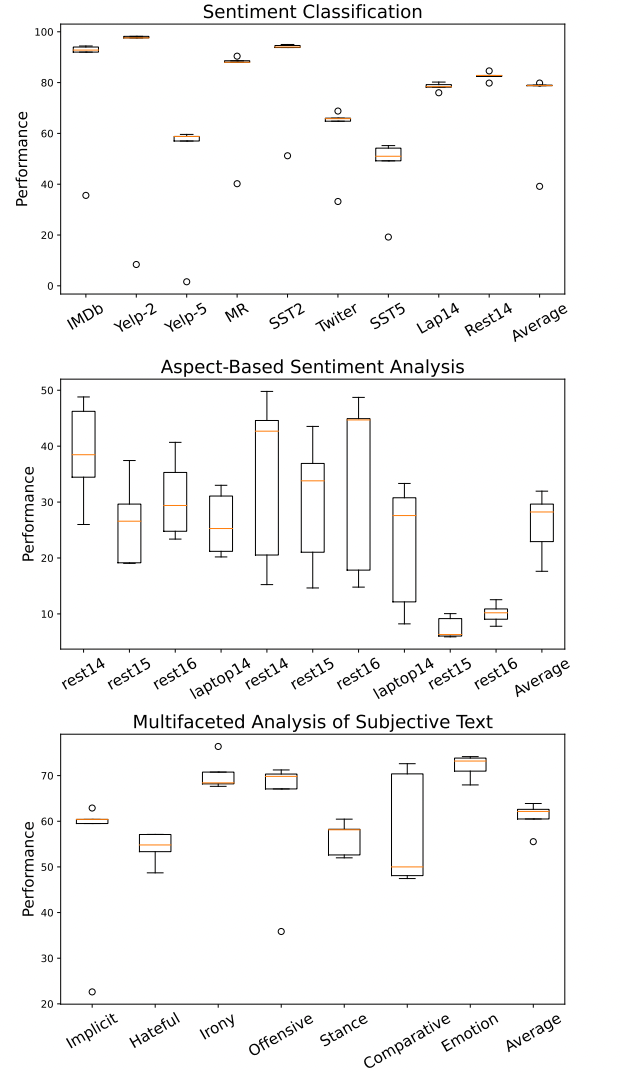
1、Zero-shot結(jié)果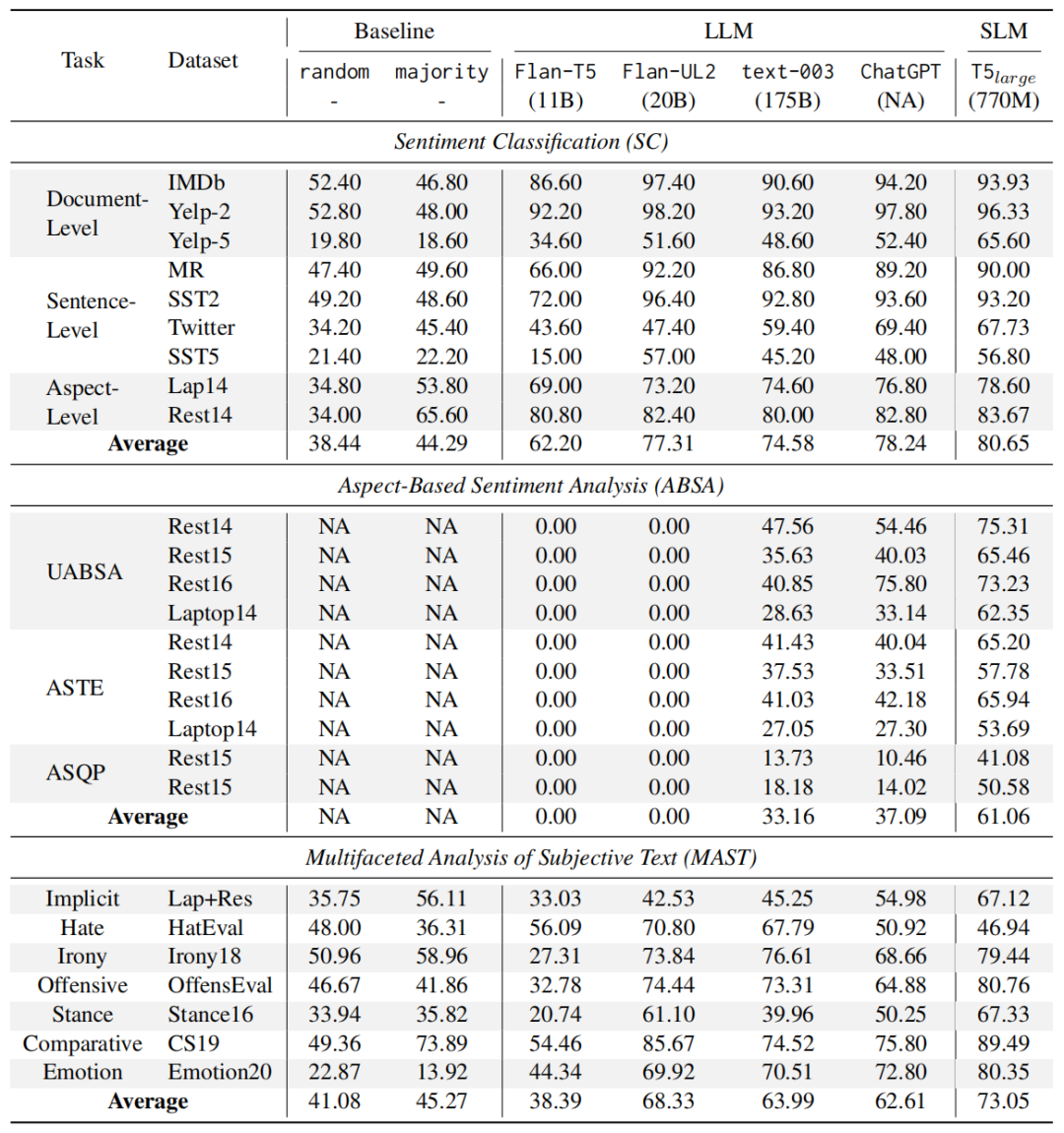 對(duì)于LLM,直接將其用于測(cè)試集上進(jìn)行結(jié)果推理。對(duì)于SLM,先將其在完整訓(xùn)練集上fine-tuned然后再用于測(cè)試,從上圖結(jié)果中可以觀測(cè)到:
對(duì)于LLM,直接將其用于測(cè)試集上進(jìn)行結(jié)果推理。對(duì)于SLM,先將其在完整訓(xùn)練集上fine-tuned然后再用于測(cè)試,從上圖結(jié)果中可以觀測(cè)到:
LLM在簡(jiǎn)單SA任務(wù)上表現(xiàn)出強(qiáng)大的zero-shot性能 從表中結(jié)果可以看到LLM的強(qiáng)大性能在SC和MAST任務(wù)上,而不需要任何的前置訓(xùn)練。同時(shí)也能觀察到任務(wù)稍微困難一點(diǎn),比如Yelp-5(類目增多)和,LLM就比f(wàn)ine-tuned模型落后很多。
更大的模型不一定導(dǎo)致更好的性能 從表中結(jié)果可以看到LLM對(duì)于SC和MAST任務(wù)表現(xiàn)較好,而且不需要任何的前置訓(xùn)練。但是也能觀察到任務(wù)稍微困難一點(diǎn),比如Yelp-5(類目增多),LLM就比f(wàn)ine-tuned模型落后很多。
LLM難以提取細(xì)粒度的結(jié)構(gòu)化情感和觀點(diǎn)信息 從表中中間部分可以看出,F(xiàn)lan-T5和Flan-UL2在ABSA任務(wù)根本就不適用,而text-003和ChatGPT雖然取得了更好的結(jié)果,但是對(duì)于fine-tuned的SLM來(lái)說(shuō),依然是非常弱的。
RLHF可能導(dǎo)致意外現(xiàn)象 從表中可以觀察到一個(gè)有趣現(xiàn)象,ChatGPT在檢測(cè)仇恨、諷刺和攻擊性語(yǔ)言方面表現(xiàn)不佳。即使與在許多其他任務(wù)上表現(xiàn)相似的text-003相比,ChatGPT在這三項(xiàng)任務(wù)上的表現(xiàn)仍然差得多。對(duì)此一個(gè)可能的解釋是在ChatGPT的RLHF過(guò)程與人的偏好“過(guò)度一致”。這一發(fā)現(xiàn)強(qiáng)調(diào)了在這些領(lǐng)域進(jìn)一步研究和改進(jìn)的必要性。
2、Few-shot結(jié)果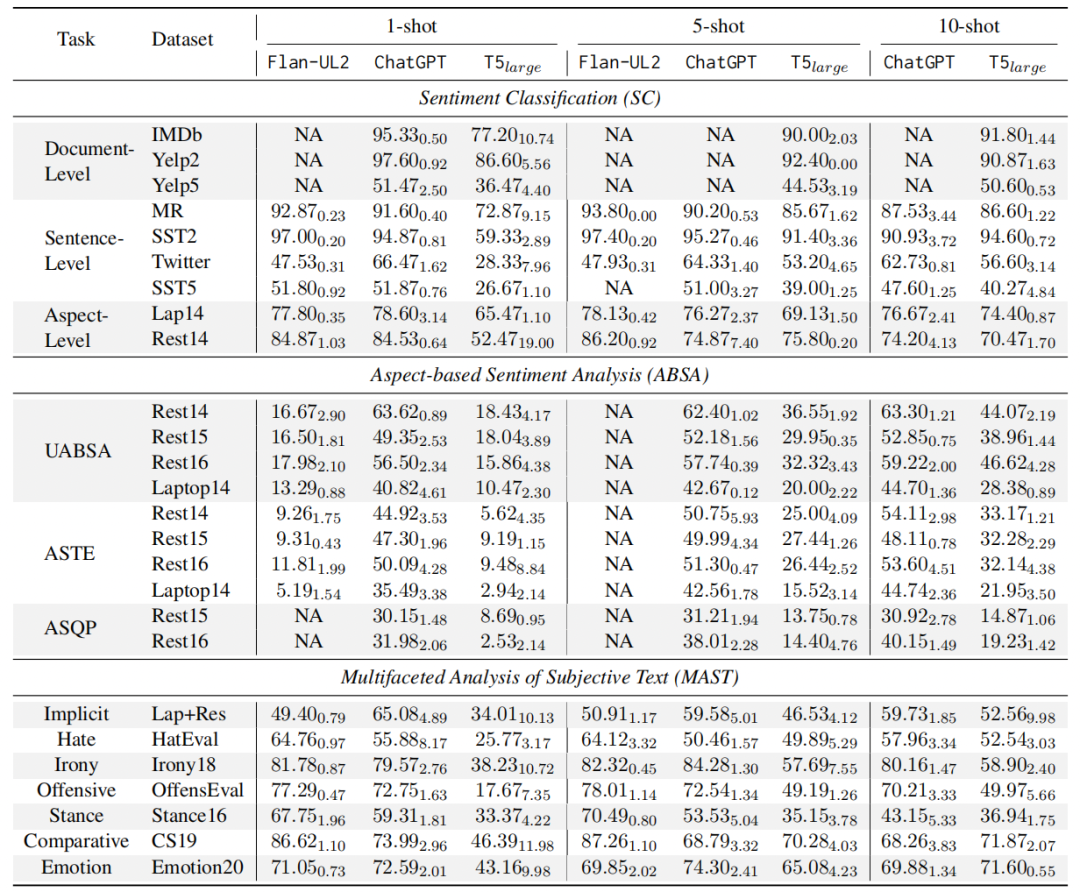 本文采用了手中K-shot的設(shè)置:1-shot, 5-shot, 和10-shot。這些采樣的實(shí)例分別作為L(zhǎng)LM上下文學(xué)習(xí)實(shí)例以及SLM的訓(xùn)練數(shù)據(jù)。可以有如下發(fā)現(xiàn):
本文采用了手中K-shot的設(shè)置:1-shot, 5-shot, 和10-shot。這些采樣的實(shí)例分別作為L(zhǎng)LM上下文學(xué)習(xí)實(shí)例以及SLM的訓(xùn)練數(shù)據(jù)。可以有如下發(fā)現(xiàn):
在不同的few-shot設(shè)置下,LLM超越SLM 在三種few-shot設(shè)置中,LLM幾乎在所有情況下都始終優(yōu)于SLM。這一優(yōu)勢(shì)在ABSA任務(wù)中尤為明顯,因?yàn)锳BSA任務(wù)需要輸出結(jié)構(gòu)化的情感信息,SLM明顯落后于LLM,這可能是由于在數(shù)據(jù)有限的情況下學(xué)習(xí)這種模式會(huì)變得更加困難。
SLM通過(guò)增加shot在多數(shù)任務(wù)性能得到持續(xù)提升 隨著shot數(shù)目的增加,SLM在各種SA任務(wù)中表現(xiàn)出實(shí)質(zhì)性的提升。這表明SLM能有效利用更多的示例實(shí)現(xiàn)更好的性能。任務(wù)復(fù)雜性也可以從圖中觀察到,T5模型用于情感分類任務(wù)性能逐漸趨于平穩(wěn),然而對(duì)于ABSA和MAST任務(wù),性能繼續(xù)增長(zhǎng),這表明需要更多的數(shù)據(jù)來(lái)捕捉其基本模式。
LLM shots的增加對(duì)不同任務(wù)產(chǎn)生不同結(jié)果 增加shot數(shù)目對(duì)LLM的影響因任務(wù)而異。對(duì)于像SC這種相對(duì)簡(jiǎn)單的任務(wù),增加shot收益并不明顯。此外,如MR和Twitter等數(shù)據(jù)集以及立場(chǎng)和比較任務(wù),甚至隨著shot的增加,性能受到阻礙,這可能是由于處理過(guò)長(zhǎng)的上下文誤導(dǎo)LLM的結(jié)果。然而,對(duì)于需要更深入、更精確的輸出格式的ABSA任務(wù),增加few數(shù)目大大提高了LLM的性能。這表明更多示例并不是所有任務(wù)的靈丹妙藥,需要依賴任務(wù)的復(fù)雜性。
SA能力評(píng)估再思考
呼吁更全面的評(píng)估 目前大多數(shù)評(píng)估往往只關(guān)注特定的SA任務(wù)或數(shù)據(jù)集,雖然這些評(píng)估可以為L(zhǎng)LM的情感分析能力的某些方面提供有用見解,但它們本身并沒有捕捉到模型能力的全部廣度和深度。這種限制不僅降低了評(píng)估結(jié)果的總體可靠性,而且限制了模型對(duì)不同SA場(chǎng)景的適應(yīng)性。因此,本文試圖在這項(xiàng)工作中對(duì)廣泛的SA任務(wù)進(jìn)行全面評(píng)估,并呼吁在未來(lái)對(duì)更廣泛的SA工作進(jìn)行更全面的評(píng)估。
呼吁更自然的模型交互方式 常規(guī)情感分析任務(wù)通常為一個(gè)句子配對(duì)相應(yīng)的情感標(biāo)簽。這種格式有助于學(xué)習(xí)文本與其情感之間的映射關(guān)系,但可能不適合LLM,因?yàn)長(zhǎng)LM通常是生成模型。在實(shí)踐中不同的寫作風(fēng)格產(chǎn)生LLM解決SA任務(wù)的不同方式,所以在評(píng)估過(guò)程中考慮不同的表達(dá)以反映更現(xiàn)實(shí)的用例是至關(guān)重要的。這確保評(píng)估結(jié)果反映真實(shí)世界的互動(dòng),進(jìn)而提供更可靠的見解。
prompt設(shè)計(jì)的敏感性 如圖所示,即使在一些簡(jiǎn)單的SC任務(wù)上,prompt的變化也會(huì)對(duì)ChatGPT的性能產(chǎn)生實(shí)質(zhì)性影響。當(dāng)試圖公平、穩(wěn)定地測(cè)試LLM的SA能力時(shí),與prompt相關(guān)的敏感性也帶來(lái)了挑戰(zhàn)。當(dāng)各種研究在一系列LLM中對(duì)不同的SA任務(wù)使用不同的prompt時(shí),挑戰(zhàn)被進(jìn)一步放大。與prompt相關(guān)的固有偏見使采用相同prompt的不同模型的公平對(duì)比變得復(fù)雜,因?yàn)閱蝹€(gè)prompt可能并不適用于所有模型。
為了緩解上述評(píng)估LLM的SA能力時(shí)的局限性,本文提出了SENTIEVAL基準(zhǔn),用于在LLM時(shí)代進(jìn)行更好的SA評(píng)估,并利用各種LLM模型進(jìn)行了再評(píng)估,結(jié)果如圖所示。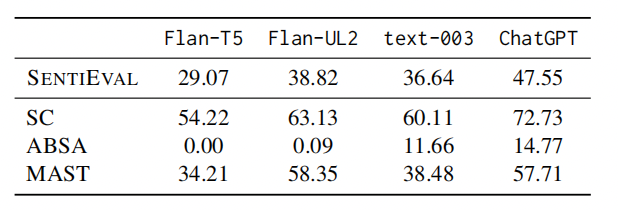
總結(jié)
這項(xiàng)工作使用LLM對(duì)各種SA任務(wù)進(jìn)行了系統(tǒng)評(píng)估,有助于更好地了解它們?cè)赟A問題中的能力。結(jié)果表明,雖然LLM在zero-shot下的簡(jiǎn)單任務(wù)中表現(xiàn)很好,但它們?cè)谔幚砀鼜?fù)雜的任務(wù)時(shí)會(huì)遇到困難。在few-shot下,LLM始終優(yōu)于SLM,這表明它們?cè)跇?biāo)注資源稀缺時(shí)的潛力。同時(shí)還強(qiáng)調(diào)了當(dāng)前評(píng)估實(shí)踐的局限性,然后引入了SENTIEVAL基準(zhǔn)作為一種更全面、更現(xiàn)實(shí)的評(píng)估工具。
總體而言,大型語(yǔ)言模型為情感分析開辟了新的途徑。雖然一些常規(guī)SA任務(wù)已經(jīng)達(dá)到了接近人類的表現(xiàn),但要全面理解人類的情感、觀點(diǎn)和其他主觀感受還有很長(zhǎng)的路要走。LLM強(qiáng)大的文本理解能力為L(zhǎng)LM時(shí)代情感分析探索之路提供了有效的工具和令人興奮的研究方向。
-
模型
+關(guān)注
關(guān)注
1文章
3261瀏覽量
48916 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24737 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1564瀏覽量
7807 -
LLM
+關(guān)注
關(guān)注
0文章
293瀏覽量
353
原文標(biāo)題:ChatGPT時(shí)代情感分析還存在嗎?一份真實(shí)調(diào)查
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
雙目標(biāo)函數(shù)支持向量機(jī)在情感分析中的應(yīng)用
簡(jiǎn)單介紹ACL 2020中有關(guān)對(duì)象級(jí)情感分析的三篇文章

金融市場(chǎng)中的NLP 情感分析
將對(duì)話中的情感分類任務(wù)建模為序列標(biāo)注 并對(duì)情感一致性進(jìn)行建模
紹華為云在細(xì)粒度情感分析方面的實(shí)踐
情感分析常用的知識(shí)有哪些呢?
圖模型在方面級(jí)情感分析任務(wù)中的應(yīng)用
Macaw-LLM:具有圖像、音頻、視頻和文本集成的多模態(tài)語(yǔ)言建模
適用于各種NLP任務(wù)的開源LLM的finetune教程~

基于單一LLM的情感分析方法的局限性






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論