
1. Background
近年來,隨著LLM (Large Language Model) 規模的逐漸增大(200M->7B->175B),LLM的推理加速技術正逐步引起NLP學界的廣泛關注。尤其是像ChatGPT[1],Bard[2]這種線上實時交互的應用,LLM的inference latency(推理耗時)極大程度地影響了用戶的使用體驗。那么,LLM的Latency主要來自哪里呢?
相關研究表明,LLM推理主要是受內存帶寬限制的(memory-bandwidth bound)[3][4]-- LLM每個解碼步所用的推理時間大部分并不是用于模型的前向計算,而是消耗在了將LLM巨量的參數從GPU顯存(High-Bandwidth Memory,HBM)遷移到高速緩存(cache)上(以進行運算操作)。也就是說,LLM推理下的GPU并不是一個合格的打工人:他把每天大多數的時間都耗費在了早晚高峰堵車上,在公司沒干啥實事兒(可不就是我摸魚仙人:P)。
這個問題隨著LLM規模的增大愈發嚴重。并且,如下左圖所示,目前LLM常用的自回歸解碼(autoregressive decoding)在每個解碼步只能生成一個token。這導致GPU計算資源利用率低下(->每個token的生成都需要重復讀寫LLM的巨量參數),并且序列的生成時間隨著序列長度的增加而線性增加。
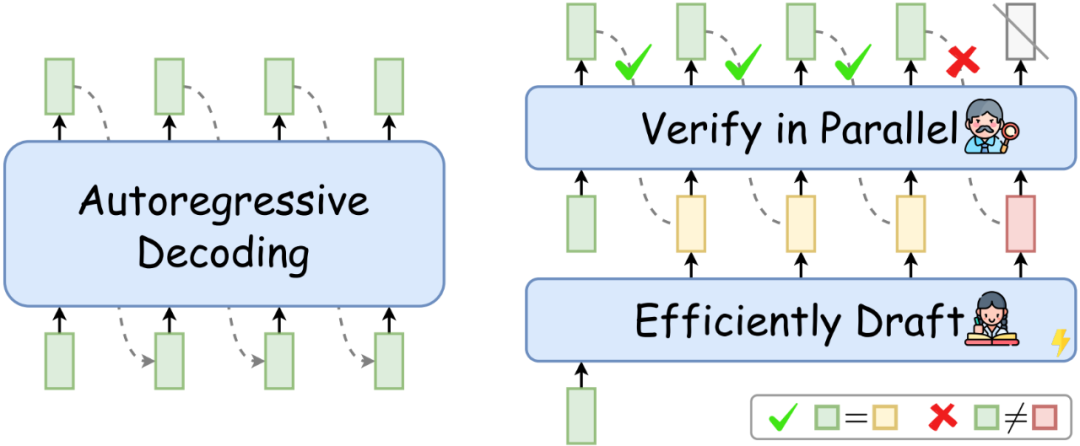
圖1: 自回歸解碼(左),推測解碼(右)
2. Speculative Decoding
那么,如何更好地利用GPU資源,讓它成為一個合格的打工人呢?相信大家心里已經有答案了:把公司當作家,減少通勤次數,就可以少摸魚多打工了(淚目)。
推測解碼(Speculative Decoding),作為2023年新興的一項LLM推理加速技術,正是提出了一種類似的解決方案:通過增加每個解碼步LLM計算的并行性,減少總的解碼步數(即減少了LLM參數的反復讀寫),從而實現推理加速。
如上右圖所示,在每個解碼步,推測解碼首先高效地“推測”target LLM(待加速的LLM)未來多個解碼步可能生成的token,然后再用target LLM同時驗證這些token。通過驗證的token作為當前解碼步的解碼結果。如果“推測”足夠準確,推測解碼就可以在單個解碼步并行生成多個token,從而實現LLM推理加速。并且,使用target LLM的驗證過程可以在理論上保證解碼結果和target LLM自回歸解碼結果的完全一致[5][6]。
也就是說,推測解碼在實現對target LLM推理加速的同時,不損失LLM的解碼質量。這種優異的性質導致推測解碼受到了學界和工業界的廣泛關注,從2023年初至今涌現了許多優秀的研究工作和工程項目(如Assisted Generation[7],Medusa[8],Lookahead Decoding[9]等等)。
考慮到推測解碼領域2023年以來飛速的研究進展,我們撰寫了一篇系統性的survey,給出推測解碼的統一定義和通用算法,詳細介紹了推測解碼研究思路的演化,并對目前已有的研究工作進行了分類梳理。在下文中,我們將文章內容凝練為太長不看版——分享一些關于推測解碼關鍵要素的看法,以及目前常用的研究思路,歡迎感興趣的小伙伴一起討論~
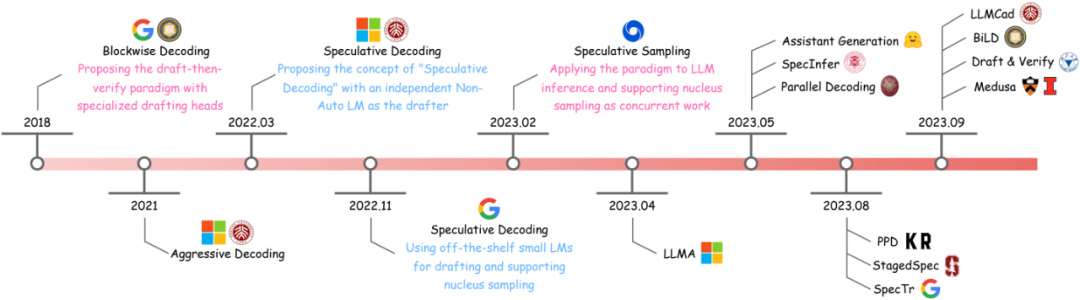
圖2: 推測解碼研究思路的演化
3. Key Facets of Speculative Decoding
首先,我們總結推測解碼的定義:
推測解碼是一種“先推測后驗證” (Draft-then-Verify) 的解碼算法:在每個解碼步,該算法首先高效地“推測”target LLM未來多個解碼步的結果,然后用target LLM同時進行驗證,以加速推理。
也就是說,所有符合在每個解碼步“高效推測->并行驗證“模式的推理算法,都可以稱為是推測解碼(或其變體)。推測解碼實現加速的關鍵要素,主要在于如下三點:
相比于生成單一token,LLM并行計算額外引入的latency很小,甚至可以忽略;
“推測”的高效性&準確性:如何又快又準地“推測”LLM未來多個解碼步的生成結果;
“驗證“策略的選擇:如何在確保質量的同時,讓盡可能多的“推測”token通過驗證,提高解碼并行性。
如上文所述,LLM推理的主要latency瓶頸在于推理過程中參數的反復讀寫。在只考慮一個解碼步的情況下,decoder-only LLM的forward latency主要和decoder層數有關——層數越深,推理時間越長。相比于這兩者,LLM運算并行性帶來的額外latency很小,這一點在非自回歸解碼的多個相關工作中有所討論[10][11]。
因此,推測解碼的算法設計主要考慮如下兩點:“推測”(Drafting)的高效性和準確性,以及“驗證“策略(Verification)的選擇:
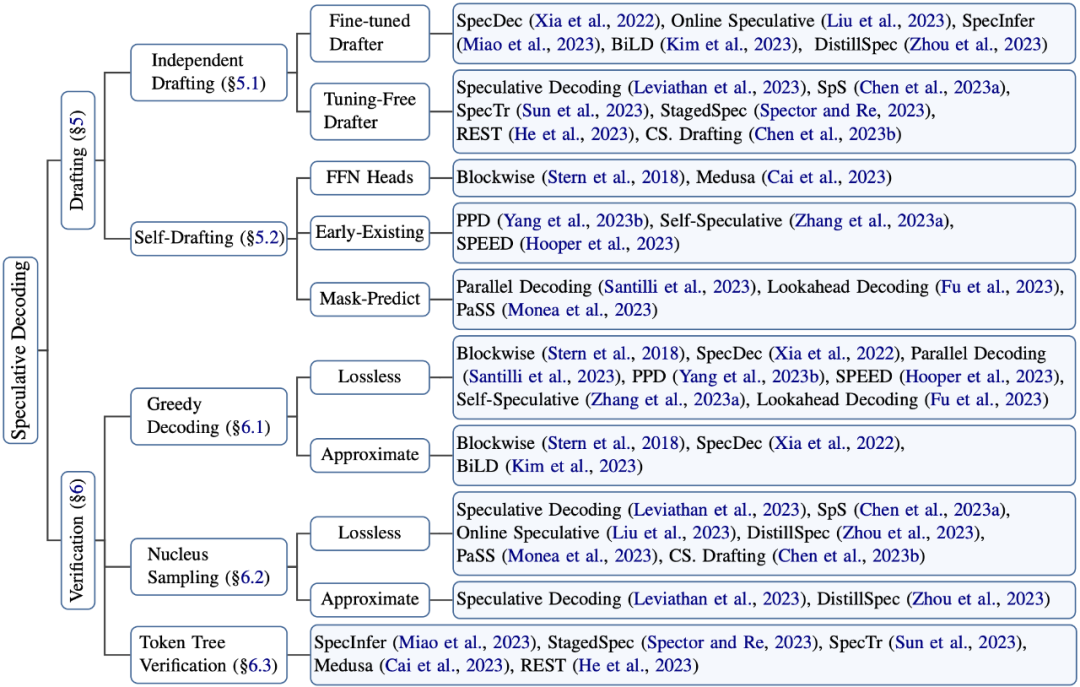
圖3: 推測解碼相關研究的歸納分類
4. “推測”的高效性和準確性
“推測“階段(Drafting)的目的是精準地“預測”LLM未來多個解碼步的生成結果,且不引入過多的latency。
因此,“推測”階段的設計聚焦在“推測精度(accuracy)”和“推測耗時(latency)“的權衡上。一般來說,用以推測的模型越大,推測精度越高(即通過驗證的token越多),但是推測階段的耗時越大。如何在這兩者之間達到權衡,使得推測解碼總的加速比較高,是推測階段主要關注的問題。
4.1 Independent Drafting
最簡單的Drafting思路是,拿一個跟target LLM同系列的smaller LM進行“推測”[12][13]。比如OPT-70B的加速可以用OPT-125M進行推測,T5-XXL可以用T5-small。這樣的好處是可以直接利用現有的模型資源,無需進行額外的訓練。而且,由于同系列的模型使用相近的模型結構、分詞方法、訓練語料和訓練流程,小模型本身就存在一定的和target LLM之間的“行為相似性“(behavior alignment),適合用來作為高效的“推測“模型。
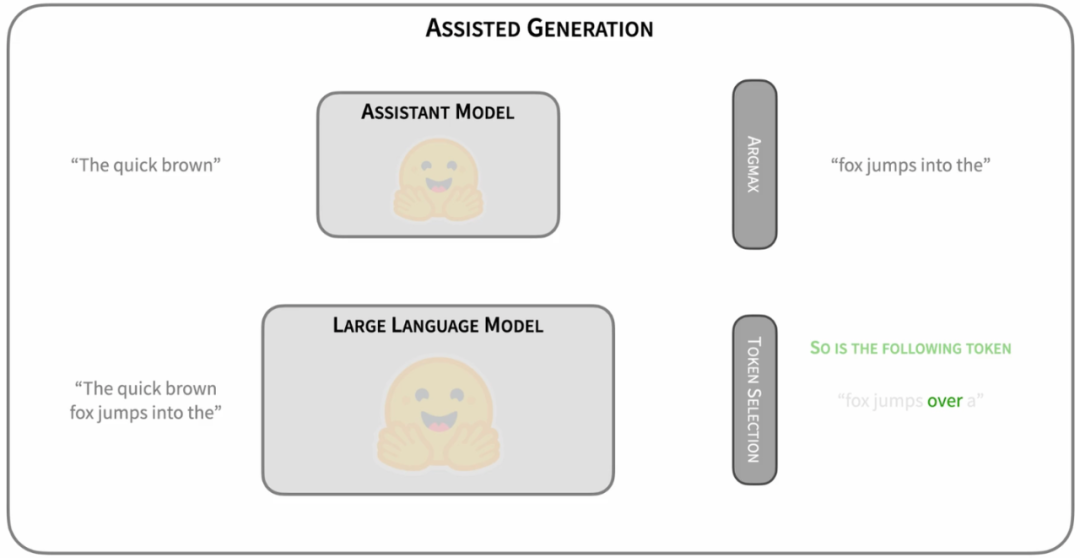
圖4: https://huggingface.co/blog/assisted-generation
這一思路由Google和Deepmind同時提出[12][13]。作為Speculative Decoding的早期探索,這種“推測”思路易于實踐和部署。并且,這兩篇工作同時在理論上證明了推測解碼不僅支持greedy decoding,還支持nucleus sampling的無損加速(我們下文會講到)。這兩種解碼策略涵蓋了LLM應用的大多數場景。因此,這兩篇工作極大地促進推測解碼在LLM推理加速中的應用,吸引了工業界和學術界的大量關注。
然而,同系列小模型的“推測”精度還有提升空間嗎?
顯然是有的。最直接的思路,就是去增強小模型和大模型之間的“行為相似性”(behavior alignment),讓小模型模仿得“更像”一些。目前在這方面的研究進展集中在知識蒸餾(knowledge distillation)上:將target LLM作為教師模型,小模型作為學生模型,通過知識蒸餾讓小模型更加趨向于target LLM的預測行為[14][15]。并且,知識蒸餾還可以有效地增強小模型的生成質量,通過減少低級的預測錯誤,增加通過驗證的token數量。
4.2 Self-Drafting
然而,采用一個獨立的“推測”模型也有缺點:
首先,并不是所有的LLM都能找到現成的小模型,比如LLaMA-7B。重新訓練一個小模型需要較多的額外投入。
另外,引入一個額外的小模型增加了推理過程的計算復雜度,尤其不利于分布式部署場景。
因此,相關研究工作提出利用target LLM自己進行“高效推測”。比如Blockwise Decoding[5]和Medusa[8]在target LLM最后一層decoder layer之上引入了多個額外的FFN Heads(如下所示),使得模型可以在每個解碼步并行生成多個token,作為“推測”結果。
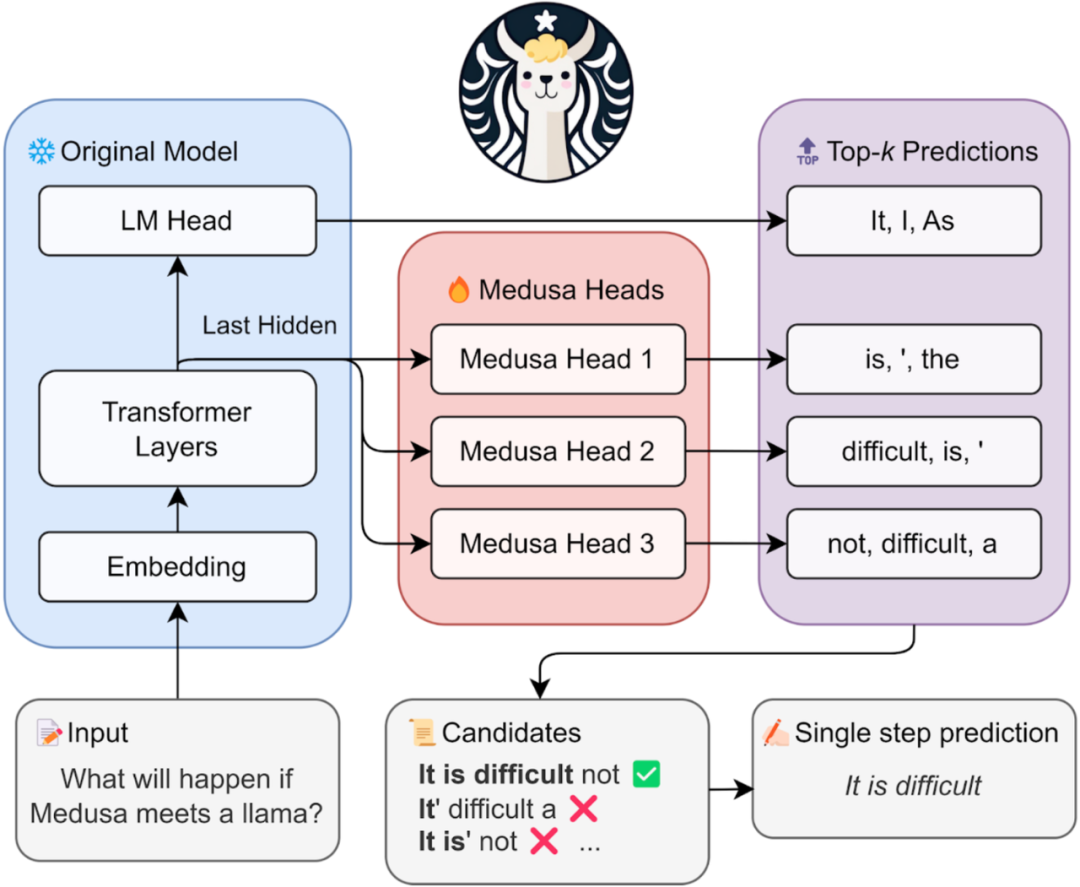
圖5: https://sites.google.com/view/medusa-llm
然而,這些FFN Heads依然需要進行額外的訓練。除了這兩個工作,還有一些研究提出利用Early-Existing或者Layer-Skipping來進行“高效推測“[16][17],甚至僅僅是在模型輸入的最后插入多個[PAD] token,從而實現并行的“推測”[18]。然而,“部署的便捷性”和“推測精度”之間依然存在一定的權衡關系。如何選擇合適的“推測”策略,達到令人滿意的加速效果,就見仁見智了。
感興趣的友友可以移步具體論文查看細節,我們后續也準備提供一個公平的加速評測,給大家提供一個參考~
5. 驗證策略的選擇
“驗證“階段(Verification)的首要目的是保證解碼結果的質量。
讓我們重新回顧推測解碼的驗證過程:
如下圖所示,在給定“草稿”(即推測結果)時,LLM的并行驗證其實和訓練階段teacher-forcing的形式是一致的——在生成每個token時,都假設LLM的前綴輸入是正確的。比如,在驗證第三個“推測”token時,LLM以綠色前綴和兩個黃色的"推測“token作為前綴輸入。以貪婪解碼(greedy decoding)為例,以該前綴作為輸入時,LLM會自己生成一個概率最大的token。如果這個token(綠色)和第三個“推測”token相同,就說明第三個“推測”token通過了“驗證”——這個token本來就是LLM自己會生成的結果。
因此,第一個沒有通過驗證的“推測”token (圖中的紅色token)后續的“推測”token都將被丟棄。因為這個紅色token不是LLM自己會生成的結果,那么前綴正確性假設就被打破,這些后續token的驗證都無法保證前綴輸入是“正確”的了。
圖6:recap of Speculative Decoding
由此可見,推測解碼是可以保證最終解碼結果和target LLM原先的貪婪解碼結果完全一致的。因此,貪婪解碼經常被用于推測解碼的demo展示[8],用以清晰直觀地表示推測解碼在保持和target LLM解碼結果等同的前提下,實現了數倍的推理加速。
然而,嚴格要求和target LLM解碼結果完全匹配(exact-match)是最好的策略嗎?
顯然,并不是所有概率最大的token都是最合適的解碼結果(比如beam search)。當推測模型的性能較好時,嚴格要求和target LLM結果匹配會導致大量高質量的“推測”token被丟棄,僅僅是因為它們和target LLM top-1解碼結果不一致。這導致通過驗證的“推測”token數量較小,從而影響推測解碼的加速比。
因此,有一些工作提出可以適當地放松“驗證”要求,使得更多高質量的“推測”token被接受,增大每個解碼步通過驗證的“推測”token數量,進一步提升加速比[12][14][15]。
除了支持貪婪解碼,推測解碼還可以在理論上保障和target LLM nucleus sampling的分布相同[12][13],具體證明感興趣的朋友可以查看相關paper~。另外,相比于只驗證單一的“推測”序列,相關研究還提出可以讓target LLM并行驗證多條“推測”序列,從而進一步增大通過驗證的“推測”token數量[19]。
6. 總結
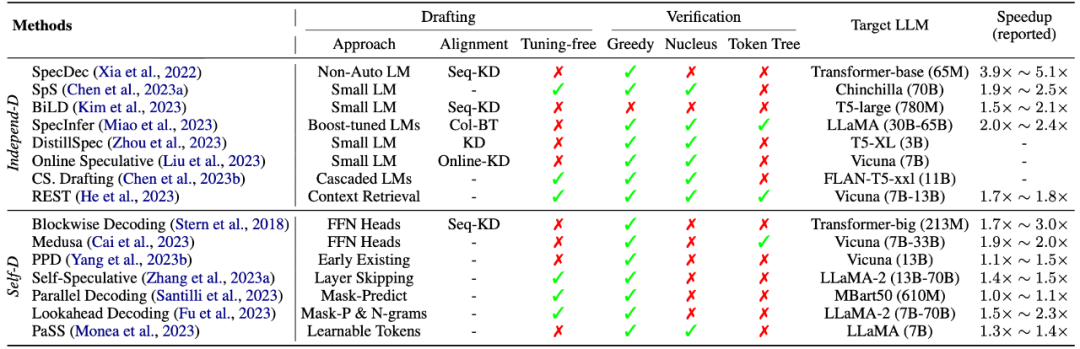
表1: 推測解碼算法總結
在上表中,我們給出目前常用的推測解碼算法的總結~。作為一種新興的推理加速算法,推測解碼在實現對target LLM推理加速的同時保障了解碼結果的質量,具有廣闊的應用前景和極大的科研潛力,個人比較看好~。然而,推測解碼研究本身也存在許多尚未解答的問題,比如如何更好地實現target LLM和“推測”模型之間的行為對齊、如何結合具體任務的特點設計相應的推測解碼策略(比如多模態模型加速),都是值得思考的問題。
-
解碼
+關注
關注
0文章
184瀏覽量
27645 -
模型
+關注
關注
1文章
3443瀏覽量
49678 -
LLM
+關注
關注
1文章
316瀏覽量
598
原文標題:LLM推理加速新范式!推測解碼(Speculative Decoding)最新綜述
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
對比解碼在LLM上的應用
壓縮模型會加速推理嗎?
mlc-llm對大模型推理的流程及優化方案
周四研討會預告 | 注冊報名 NVIDIA AI Inference Day - 大模型推理線上研討會
Hugging Face LLM部署大語言模型到亞馬遜云科技Amazon SageMaker推理示例

基于LLM的表格數據的大模型推理綜述

自然語言處理應用LLM推理優化綜述

LLM大模型推理加速的關鍵技術
高效大模型的推理綜述

在NVIDIA TensorRT-LLM中啟用ReDrafter的一些變化

中國電提出大模型推理加速新范式Falcon

新品| LLM630 Compute Kit,AI 大語言模型推理開發平臺

新品 | Module LLM Kit,離線大語言模型推理模塊套裝
詳解 LLM 推理模型的現狀






 工商網監
工商網監

評論