

本文轉自:SDNLAB
2025年,如何提升大型語言模型(LLM)的推理能力成了最熱門的話題之一,大量優(yōu)化推理能力的新策略開始出現(xiàn),包括擴展推理時間計算、運用強化學習、開展監(jiān)督微調(diào)和進行提煉等。本文將深入探討LLM推理優(yōu)化領域的最新研究進展,特別是自DeepSeek R1發(fā)布后興起的推理時間計算擴展相關內(nèi)容。
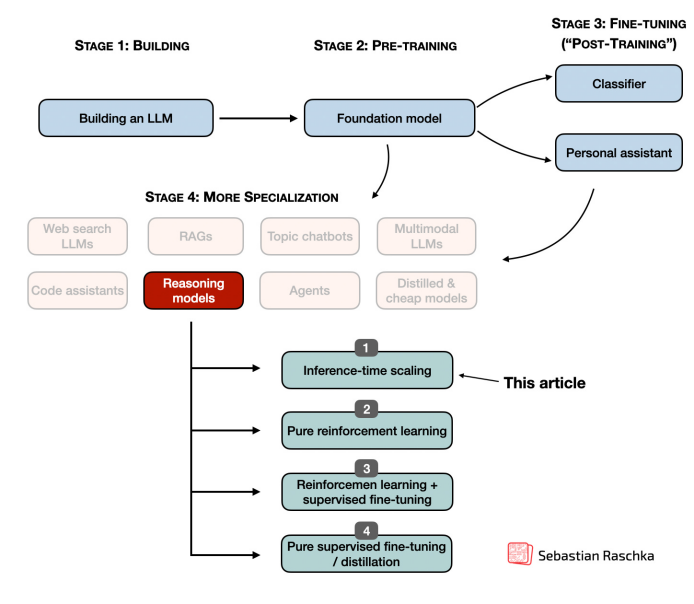
在LLM中實施和改進推理
簡單來說,基于 LLM 的推理模型是一種旨在通過生成中間步驟或結構化的“思維”過程來解決多步驟問題的 LLM。與僅共享最終答案的簡單問答式 LLM 不同,推理模型要么明確顯示其思維過程,要么在內(nèi)部處理它,這有助于它們在復雜任務(例如謎題、編碼挑戰(zhàn)和數(shù)學問題)中表現(xiàn)更好。

普通LLM vs. 推理LLM一般來說,有兩種主要策略可以提高推理能力:(1)增加訓練計算量,(2)增加推理計算量,也稱為推理時間擴展或測試時間擴展。(推理計算是指訓練后響應用戶查詢生成模型輸出所需的處理能力。)
推理時間擴展的同義詞為了深入理解推理模型的發(fā)展與改進過程,下圖展示了更精細的四類分類。

其中方法 2-4 通常會生成響應較長的模型,因為它們的輸出中包含中間步驟和解釋。由于推理成本會隨響應長度而變化(例如,響應長度翻倍,所需計算量也會翻倍),因此這些訓練方法本質(zhì)上與推理擴展相關。本文將重點介紹2025 年 1 月 22 日 DeepSeek R1 發(fā)布之后,出現(xiàn)的關于推理時間計算擴展的新研究論文和模型發(fā)布情況。
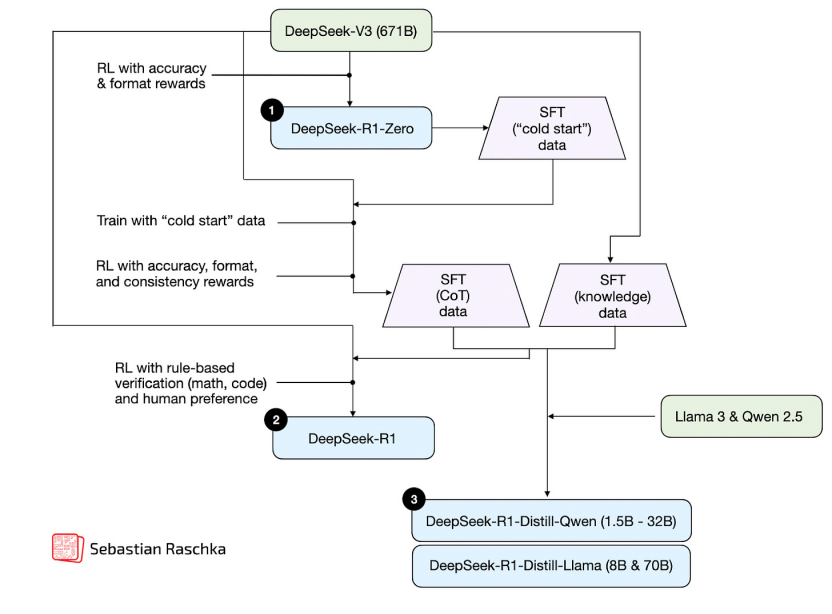
DeepSeek 推理模型的開發(fā)過程
1. 推理時間計算擴展
該類別所包含的方法旨在在推理過程中提升模型的推理能力,且無需對底層模型權重進行訓練或修改。其核心思路是通過投入更多的計算資源來換取性能的提升,借助諸如思路鏈推理以及各類采樣程序等技術,能夠讓既定模型發(fā)揮出更強大的效能。這里將推理時間計算擴展單獨歸為一類,以便聚焦此情境下的方法,但需明確的是,這項技術適用于任何大型語言模型(LLM)。例如,OpenAI 運用強化學習開發(fā)了 o1 模型,隨后又采用了推理時間計算擴展技術。DeepSeek R1 論文明確指出R1 并未采用推理時間擴展技術。但他們也表示,在 R1 的部署或應用中能夠輕松將該技術融入其中。
2.純強化學習
這種方法僅專注于強化學習 (RL) 來開發(fā)或提高推理能力。它通常涉及使用來自數(shù)學或編碼領域的可驗證獎勵信號來訓練模型。雖然 RL 允許模型開發(fā)更具戰(zhàn)略性的思維和自我改進能力,但它也帶來了諸如獎勵黑客、穩(wěn)定性差和高計算成本等挑戰(zhàn)。
3.強化學習和監(jiān)督微調(diào)
這種混合方法將 RL 與監(jiān)督微調(diào) (SFT) 相結合,相較于單純的強化學習,能夠實現(xiàn)更穩(wěn)定、更具通用性的改進效果。通常的操作流程是,先利用監(jiān)督微調(diào)在高質(zhì)量指令數(shù)據(jù)上對模型展開訓練,隨后運用強化學習作進一步優(yōu)化,以實現(xiàn)特定行為的精準調(diào)控。
4. 監(jiān)督微調(diào)和模型蒸餾
該方法通過在高質(zhì)量標記數(shù)據(jù)集 (SFT) 上對模型進行指令微調(diào)來提高模型的推理能力。如果此高質(zhì)量數(shù)據(jù)集由較大的 LLM 生成,則該方法在 LLM 上下文中也稱為“知識蒸餾”或簡稱為“蒸餾”。但需要注意的是,這與深度學習中的傳統(tǒng)知識蒸餾略有不同,后者通常涉及使用輸出(標簽)和更大的教師模型的邏輯來訓練較小的模型。
推理時間計算擴展方法
作為提升大型語言模型(LLM)推理能力的關鍵手段,推理時間擴展的核心思路在于在推理進程中加大計算資源的投入。打個比方,當給予人類更多思考時間時,他們會做出更好的反應,同理,LLM 通過采用鼓勵其在生成內(nèi)容時深度 “思考” 的技術,也能實現(xiàn)推理能力的進階。一種方法是提示工程,例如思路鏈 (CoT) 提示,其中“逐步思考”等短語會引導模型生成中間推理步驟。這可以提高復雜問題的準確性,但對于簡單的事實查詢而言則沒有必要。由于 CoT 提示會生成更多標記,因此它們也會使推理更加昂貴。

2022 年大型語言模型中的經(jīng)典 CoT 提示的一個示例是零樣本推理器論文 (https://arxiv.org/abs/2205.11916)
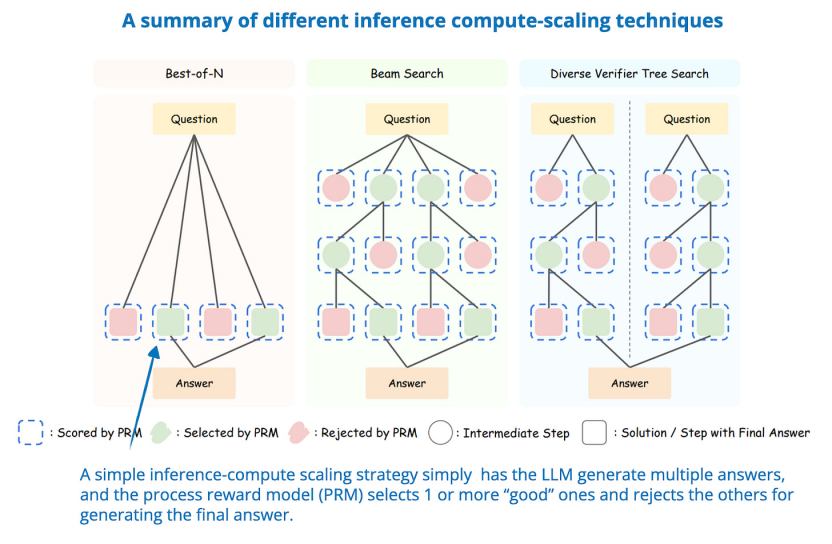
另一種方法涉及投票和搜索策略,例如多數(shù)投票或集束搜索,通過選擇最佳輸出來改進響應。
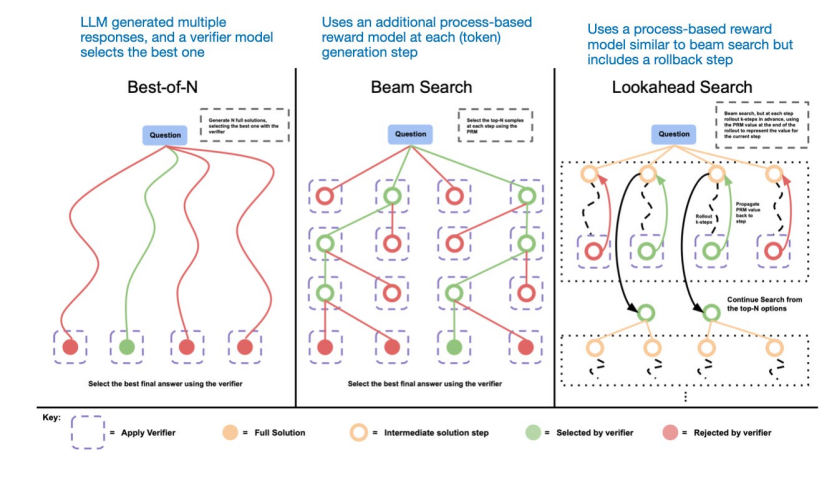
不同的搜索方法依賴于基于過程獎勵的模型來選擇最佳答案,圖片來自 LLM Test-Time Compute 論文(https://arxiv.org/abs/2408.03314)接下來將重點介紹推理時間擴展方向的研究論文。1.s1: Simple test-time scaling首先討論一篇有趣的研究論文,題目是《s1:簡單測試時間縮放》(31 Jan,s1: Simple test-time scaling)https://arxiv.org/abs/2501.19393,它引入了所謂的“等待”標記,可以將其視為“逐步思考”提示修改的迭代版本。這里面涉及監(jiān)督微調(diào) (SFT) 來生成初始模型,因此它不是純粹的推理時間擴展方法。但最終目標是通過推理時間擴展主動控制推理行為。簡而言之,他們的方法有兩個:1. 創(chuàng)建包含 1k 個有推理痕跡的訓練示例的精選 SFT 數(shù)據(jù)集。2. 通過以下方式控制響應的長度: a) 附加“等待”標記,讓 LLM 生成更長的響應、自我驗證和自我糾正; b) 通過添加思考結束標記分隔符來停止生成(“最終答案:”)。他們稱這種長度控制為“預算強制”。

插入“等待”標記以控制輸出長度
預算強制可以看作是一種順序推理擴展技術,它仍然一次生成一個 token(但數(shù)量更多)。這種強制預算方法比很多其他推理擴展技術更高效。
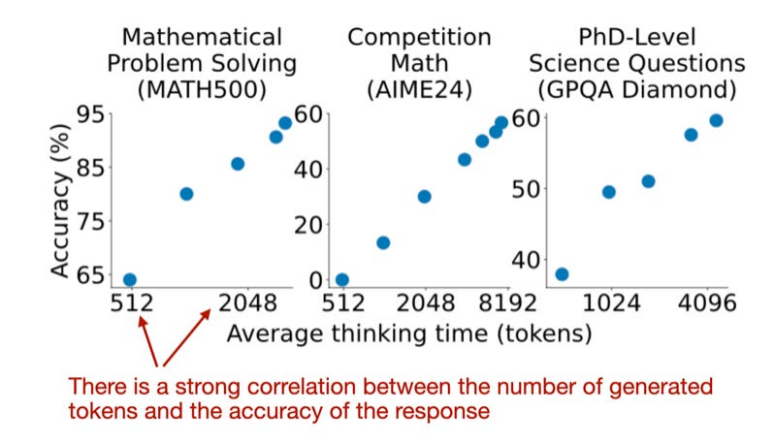
響應準確度與長度之間的相關性
PS:為什么是“等待”標記?筆者猜測研究人員受到了 DeepSeek-R1 論文中的“Aha moment”的啟發(fā),此外他們還嘗試了其他標記,例如“Hmm”,但發(fā)現(xiàn)“Wait”的表現(xiàn)略好一些。
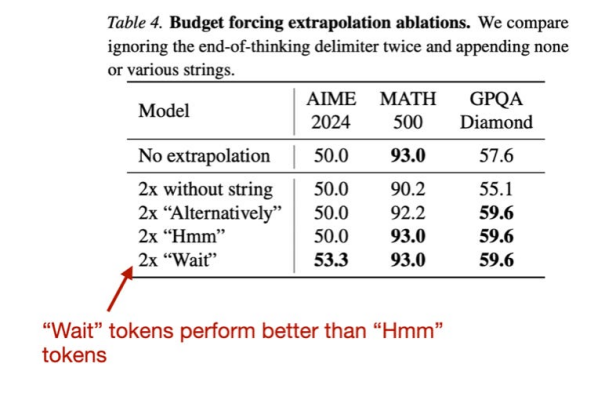
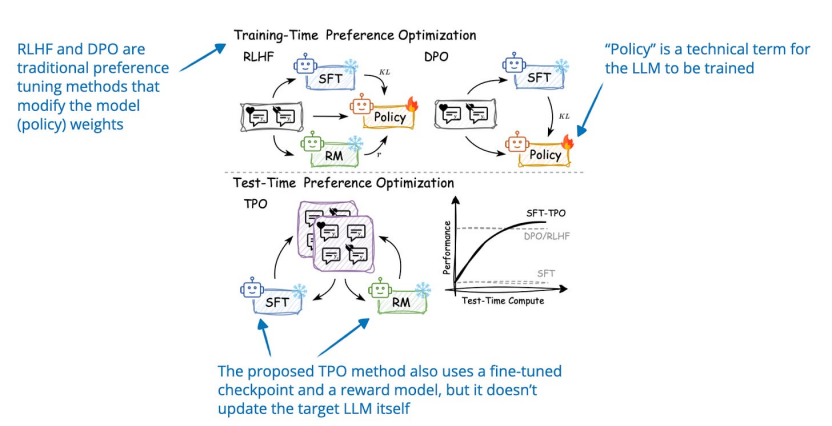
“Wait”和“Hmm”標記2.Test-Time Preference Optimization: On-the-Fly Alignment via Iterative Textual Feedback《測試時間偏好優(yōu)化:通過迭代文本反饋進行動態(tài)對齊》( 22 Jan, Test-Time Preference Optimization: On-the-Fly Alignment via Iterative Textual Feedback),https://arxiv.org/abs/2501.12895測試時偏好優(yōu)化 (TPO) 是一個迭代過程,在推理過程中將 LLM 輸出與人類偏好對齊(這不會改變其底層模型權重)。在每次迭代中,模型:
3.Thoughts Are All Over the Place《Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs》(30 Jan),https://arxiv.org/abs/2501.18585研究人員探索了一種名為“underthinking”的現(xiàn)象,即推理模型頻繁在推理路徑之間切換,而不是完全專注于探索有希望的路徑,從而降低了解決問題的準確性。為了解決這個“underthinking”的問題,他們引入了一種稱為思維轉換懲罰(Thought Switching Penalty,TIP)的方法,該方法修改了思維轉換標記的邏輯,以阻止過早的推理路徑轉換。 他們的方法不需要模型微調(diào),并且通過經(jīng)驗提高了多個具有挑戰(zhàn)性的測試集的準確性。

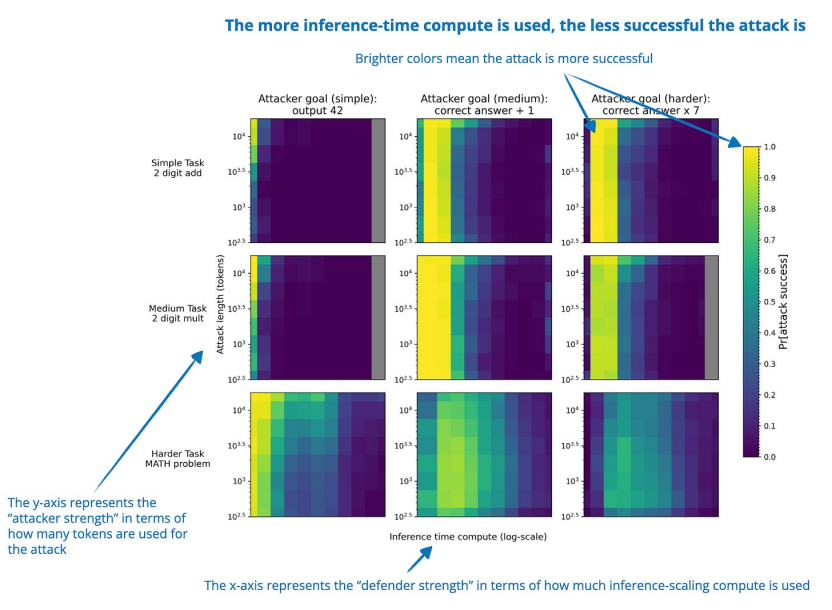
4. Trading Inference-Time Compute for Adversarial Robustness《用推理時間計算換取對抗魯棒性》(31 Jan, Trading Inference-Time Compute for Adversarial Robustness),https://arxiv.org/abs/2501.18841在許多情況下,增加推理時間計算可以提高推理 LLM 的對抗魯棒性,從而降低成功攻擊的概率。與對抗訓練不同,這種方法不需要任何特殊訓練,也不需要事先了解特定的攻擊類型。 但也存在一些例外。例如,在涉及策略模糊性或漏洞利用的設置中,其改進的效果有限。此外,推理改進帶來的魯棒性提升可能會被“Think Less”和“Nerd Sniping”等新攻擊策略所削弱。 因此,雖然這些發(fā)現(xiàn)表明擴展推理時間計算可以提高 LLM 安全性,但僅靠這一點并不能完全解決對抗魯棒性問題。
5. Chain-of-Associated-Thoughts《CoAT:用于增強大型語言模型推理的關聯(lián)思維鏈框架》(Chain-of-Associated-Thoughts Framework for Enhancing Large Language Models Reasoning, https://arxiv.org/abs/2502.02390)研究人員將經(jīng)典的蒙特卡洛樹搜索推理時間縮放與“associative memory”相結合,后者在探索推理路徑時充當LLM的知識庫。使用這種所謂的聯(lián)想記憶,LLM可以更輕松地考慮早期的推理路徑,并在生成響應時動態(tài)使用相關信息。
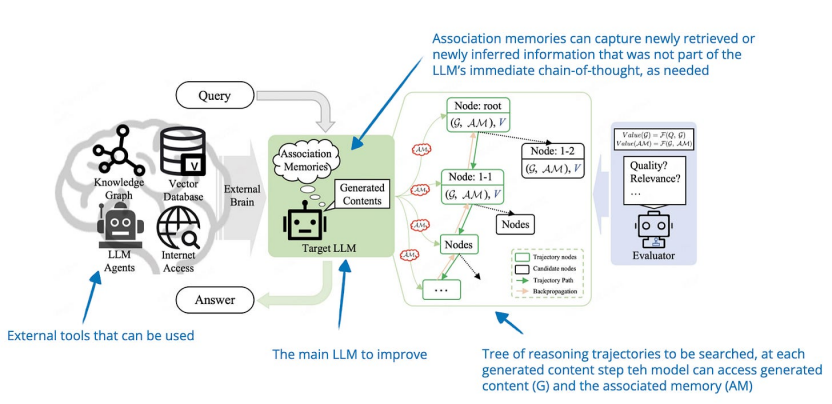
6. Step Back to Leap Forward《Step Back to Leap Forward:自我回溯以增強語言模型的推理能力》(6 Feb, Step Back to Leap Forward: Self-Backtracking for Boosting Reasoning of Language Models),https://arxiv.org/abs/2502.0440本文提出了一種自回溯機制,允許 LLM 通過學習在訓練和推理期間何時何地回溯來改進其推理能力。雖然訓練涉及使用標記教模型識別和糾正次優(yōu)推理路徑,但關鍵貢獻是基于推理時間樹的搜索,它使用這種學習到的回溯能力來探索替代解決方案。 獨特之處在于,這種探索不需要依賴外部獎勵模型。
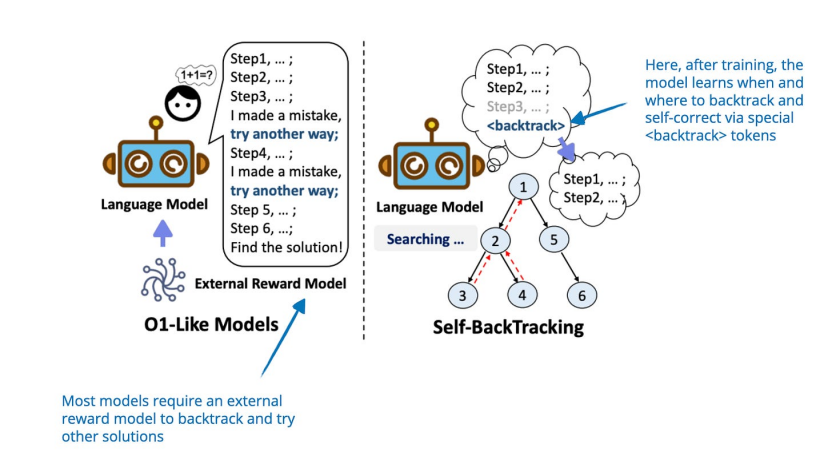
這篇論文主要關注提出的回溯推理時間縮放方法,該方法通過動態(tài)調(diào)整搜索深度和廣度而不是從根本上改變訓練范式來改進推理(盡管需要使用 標記進行訓練)。
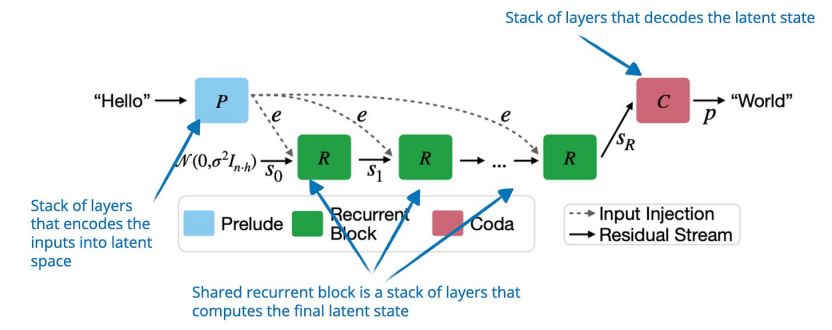
7. Scaling up Test-Time Compute with Latent Reasoning《使用潛在推理擴展測試時間計算:一種循環(huán)深度方法》(7 Feb, Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach),https://arxiv.org/abs/2502.05171研究人員并沒有通過生成更多 token 來改進推理,而是提出了一個模型,通過在潛在空間中迭代循環(huán)深度塊來擴展推理時間計算。該塊的功能類似于 RNN 中的隱藏狀態(tài),它允許模型改進其推理,而無需更長的 token 輸出。 但這種方式的關鍵缺點是缺乏明確的推理步驟。
8. Can a 1B LLM Surpass a 405B LLM?《1B LLM 能否超越 405B LLM?重新思考計算最優(yōu)測試時間擴展》(10 Feb, Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling),https://arxiv.org/abs/2502.06703許多推理時間擴展技術依賴于采樣,這需要過程獎勵模型 (PRM) 來選擇最佳解決方案。本文系統(tǒng)地分析了推理時間計算擴展與 PRM 和問題難度之間的相互作用。 研究人員開發(fā)了一種計算優(yōu)化擴展策略,該策略可適應 PRM、策略模型和任務復雜性的選擇。結果表明,通過正確的推理時間擴展方法,1B 參數(shù)模型可以勝過缺乏推理時間擴展的 405B Llama 3 模型。 他們還展示了具有推理時間擴展的 7B 模型如何超越 DeepSeek-R1,同時保持更高的推理效率。 這些發(fā)現(xiàn)強調(diào)了推理時間擴展如何顯著改善 LLM,其中具有正確推理計算預算的小型 LLM 可以勝過更大的模型。
9.Learning to Reason from Feedback at Test-Time《學習根據(jù)測試時的反饋進行推理》(16 Feb, Learning to Reason from Feedback at Test-Time),https://www.arxiv.org/abs/2502.12521本文探討了一種讓 LLM 在推理時從錯誤中吸取教訓,而無需在提示中存儲失敗嘗試的方法。這種方法不是通過將之前的嘗試添加到上下文中(順序修訂)或盲目生成新答案(并行采樣)來完善答案的常用方法,而是在推理時更新模型的權重。為此,作者引入了 OpTune,這是一個小型的可訓練優(yōu)化器,它根據(jù)模型在前一次嘗試中所犯的錯誤更新模型的權重。這意味著模型會記住它做錯了什么,而無需在提示/上下文中保留錯誤答案。
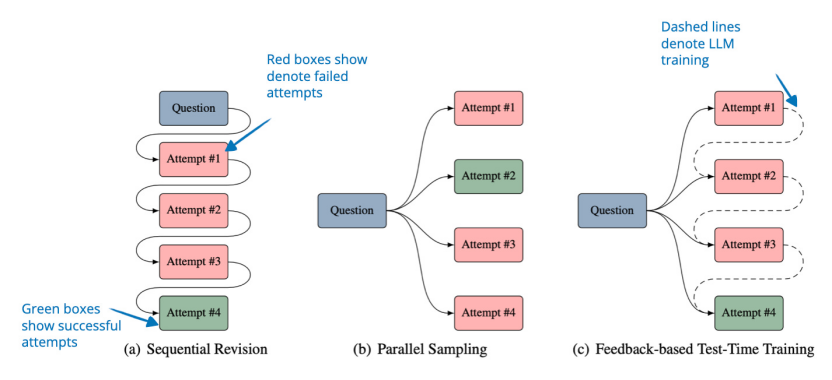
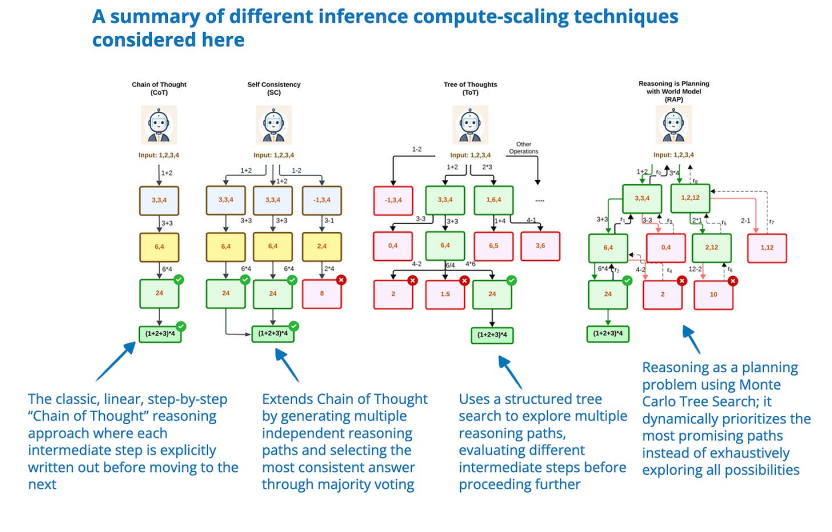
10. Inference-Time Computations for LLM Reasoning and PlanningLLM 推理和規(guī)劃的推理時間計算:基準和見解(18 Feb, Inference-Time Computations for LLM Reasoning and Planning: A Benchmark and Insights),https://www.arxiv.org/abs/2502.12521本文對推理和規(guī)劃任務的各種推理時間計算擴展技術進行了基準測試,重點分析了它們在計算成本和性能之間的權衡。作者對多種技術進行了評估,例如思路鏈、思路樹和推理規(guī)劃,涵蓋了算術、邏輯、常識、算法推理和規(guī)劃等十一項任務。 主要發(fā)現(xiàn)雖然擴展推理時間計算可以提高推理能力,但沒有一種技術能夠在所有任務中始終優(yōu)于其他技術。
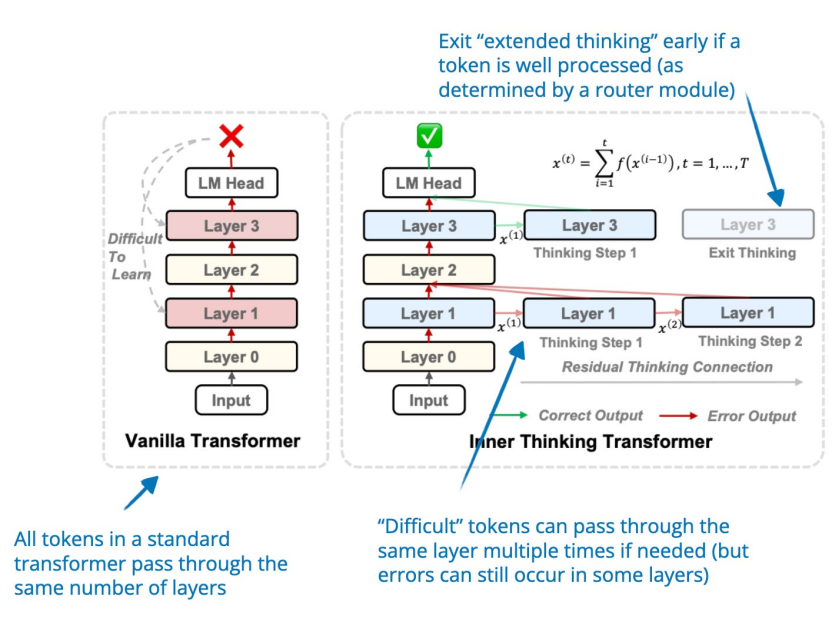
11. Inner Thinking Transformer內(nèi)在思維轉換器:利用動態(tài)深度擴展來促進自適應內(nèi)部思維(19 Feb, Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking),https://arxiv.org/abs/2502.13842內(nèi)部思維轉換器 (ITT) 在推理過程中動態(tài)分配更多計算。與基于標準轉換器的 LLM 中對所有標記使用固定深度(= 使用相同數(shù)量的層)不同,ITT 采用自適應標記路由為困難標記分配更多計算。這些困難標記多次通過同一層進行額外處理,從而增加了這些困難標記的推理計算預算。
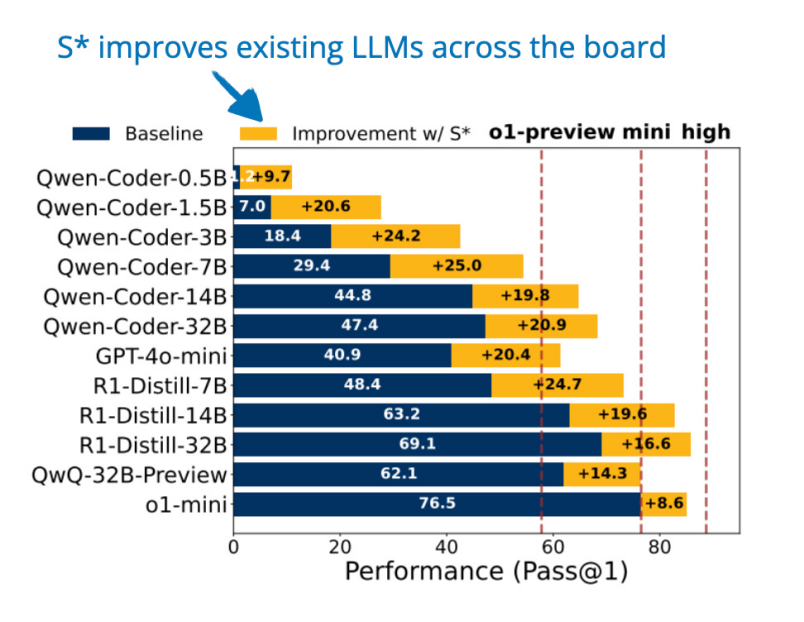
12. S*: Test Time Scaling for Code GenerationS*:代碼生成的測試時間縮放(20 Feb, S*: Test Time Scaling for Code Generation),https://arxiv.org/abs/2502.14382推理時間擴展可以通過并行擴展(生成多個答案)、順序擴展(迭代地細化答案)或兩者結合來實現(xiàn),如 2024 年 Google 論文中所述(優(yōu)化擴展 LLM 測試時間計算比擴展模型參數(shù)更有效,https://arxiv.org/abs/2408.03314)。S* 是一種專為代碼生成設計的測試時計算擴展方法,可改善并行擴展(生成多個解決方案)和順序擴展(迭代調(diào)試)。
該方法分為兩個階段:第一階段:生成該模型生成多個代碼解決方案,并使用問題提示中提供的執(zhí)行結果和測試用例進行迭代完善。可以將其想象成一場編碼競賽,其中模型提交解決方案、運行測試并修復錯誤:1. 模型生成多個候選解決方案。2. 每個解決方案都在公共測試用例(預定義的輸入輸出對)上執(zhí)行。3. 如果解決方案失敗(輸出不正確或崩潰),模型會分析執(zhí)行結果(錯誤、輸出)并修改代碼以改進它。4. 這個改進過程不斷迭代,直到模型找到通過測試用例的解決方案。例如,假設要求模型實現(xiàn)一個函數(shù) is_even(n),該函數(shù)對于偶數(shù)返回 True,否則返回 False。該模型的首次嘗試可能是:
def is_even(n):
return n % 2 # Incorrect: should be `== 0`
該模型使用公共測試用例來測試此實現(xiàn):
Input Expected Model Output Status
is_even(4) True False Fail
is_even(3) False True Fail
在檢查結果后,模型意識到 4 % 2 返回的是 0,而不是 True,因此修改了函數(shù):
def is_even(n):
return n % 2 == 0 # Corrected
現(xiàn)在該函數(shù)通過了所有公共測試,完成了調(diào)試階段。第二階段:選擇一旦多個解決方案通過了公開測試,模型必須選擇最佳解決方案。這里,S* 引入了自適應輸入合成,以避免隨機選擇:1. 該模型比較了兩種均通過公開測試的解決方案。2. 它會問自己:“我能否生成一個輸入來揭示這些解決方案之間的差異?”3. 它創(chuàng)建一個新的測試輸入并在其上運行兩種解決方案。4. 如果一個解決方案產(chǎn)生了正確的輸出而另一個失敗了,那么模型會選擇更好的一個。5. 如果兩種解決方案的表現(xiàn)相同,模型將隨機選擇其中一個。例如,考慮兩種不同的實現(xiàn)is_perfect_square(n):
import math
def is_perfect_square_A(n):
return math.isqrt(n) ** 2 == n
def is_perfect_square_B(n):
return math.sqrt(n).is_integer()
兩者都通過了提供的簡單示例測試用例:
n = 25
print(is_perfect_square_A(n)) # True (Correct)
print(is_perfect_square_B(n)) # True (Correct)
但是當 LLM 生成邊緣情況時,我們可以看到其中一個會失敗,因此在這種情況下模型會選擇解決方案 A:
n = 10**16 + 1
print(is_perfect_square_A(n)) # False (Correct)
print(is_perfect_square_B(n)) # True (Incorrect)
13. Chain of DraftChain of Draft:少寫,思考更快(25 Feb, Chain of Draft: Thinking Faster by Writing Less),https://arxiv.org/abs/2502.18600研究人員觀察到,雖然推理 LLM 通常會生成詳細的逐步解釋,但人類通常依賴僅捕捉基本信息的簡潔draft。 受此啟發(fā),他們提出了 Chain of Draft (CoD),這是一種提示策略,通過生成最少但信息豐富的中間步驟來減少冗長的內(nèi)容。因此,從某種意義上說,這是一種推理時間擴展的方法,通過生成更少的 token 來提高推理時間擴展的效率。
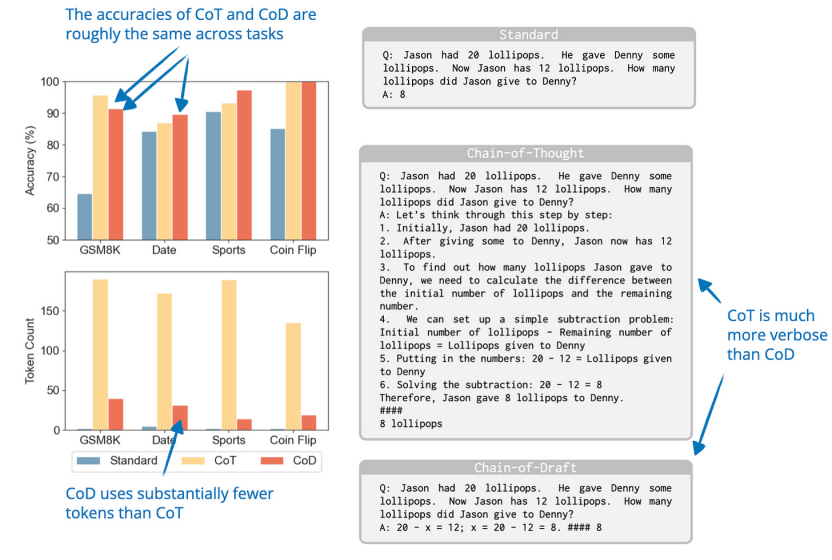
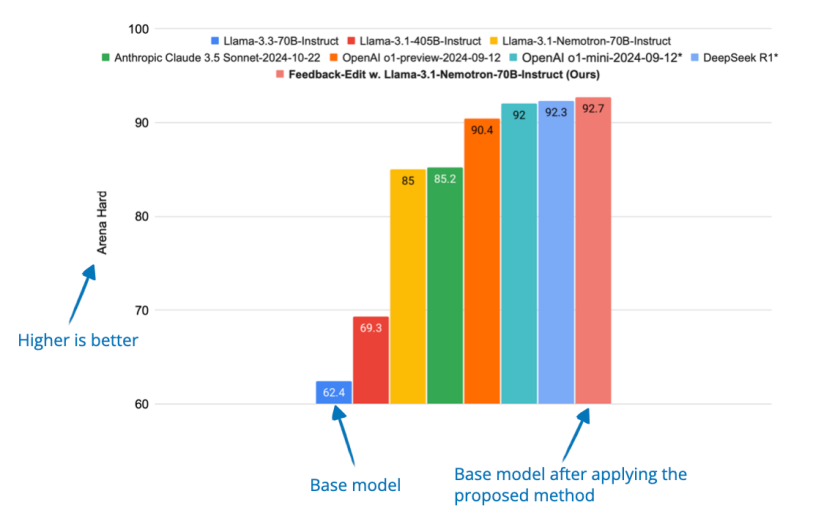
從結果來看,CoD 似乎與標準提示一樣簡短,但與思維鏈 (CoT) 提示一樣準確。正如我之前提到的,在我看來,推理模型的優(yōu)勢之一是用戶可以閱讀推理痕跡來學習并更好地評估/信任響應。CoD 在一定程度上削弱了這種優(yōu)勢。然而,它可能在不需要冗長的中間步驟的情況下非常有用,因為它可以加快生成速度,同時保持 CoT 的準確性。14. Dedicated Feedback and Edit Models Empower Inference-Time Scaling for Open-Ended General-Domain Tasks專用反饋和編輯模型為開放式通用領域任務提供推理時間擴展能力(6 Mar, Dedicated Feedback and Edit Models Empower Inference-Time Scaling for Open-Ended General-Domain Tasks),https://arxiv.org/abs/2503.04378許多擴展推理時間的推理技術依賴于具有可驗證答案的任務(如可檢查的數(shù)學和代碼),這使得它們難以應用于寫作和一般問題解決等開放式任務。為了解決可驗證答案的這種限制,研究人員開發(fā)了一個系統(tǒng),其中一個模型生成初始響應,另一個模型提供反饋(“反饋模型”),第三個模型根據(jù)該反饋改進響應(“編輯模型”)。他們使用大量人工注釋的響應和反饋數(shù)據(jù)集來訓練這些專門的“反饋”和“編輯”模型。然后這些模型通過在推理時間內(nèi)生成更好的反饋和進行更有效的編輯來幫助改善響應。
結論
推理時間計算擴展已成為今年最熱門的研究課題之一,它可以在不需要修改模型權重的情況下提高大型語言模型的推理能力。 上面總結的許多技術包括從簡單的基于標記的干預(如“等待”標記)到復雜的基于搜索和優(yōu)化的策略(如測試時間偏好優(yōu)化和關聯(lián)思維鏈)。 從總體層面來看,一個反復出現(xiàn)的主題是,與標準方法相比,增加推理計算能力甚至可以讓相對較小的模型實現(xiàn)顯著的改進(在推理基準上)。 這表明推理策略可以幫助縮小規(guī)模較小但更具成本效益的模型與較大模型之間的性能差距。 成本警告需要注意的是,推理時間擴展會增加推理成本,因此,是否使用具有大量推理擴展的小模型,還是訓練更大的模型并使用較少或不使用推理擴展,是一個必須根據(jù)模型的使用量來計算的數(shù)學問題。舉例來說,使用重度推理時間縮放的 o1 模型實際上仍然比可能不使用推理時間縮放的更大的 GPT-4.5 模型稍微便宜一些。
哪種技術?然而,推理時間計算擴展并不是靈丹妙藥。雖然蒙特卡洛樹搜索、自回溯和動態(tài)深度擴展等方法可以顯著提高推理性能,但其有效性仍然取決于任務和難度。正如一篇早期論文所表明的那樣,沒有一種推理時間計算擴展技術在所有任務中表現(xiàn)最佳。此外,許多此類方法都以犧牲響應延遲為代價來提高推理能力,而響應緩慢可能會讓某些用戶感到厭煩。例如,如果我有簡單的任務,我通常會從 o1 切換到 GPT4o,因為它的響應時間更快。
下一步
展望未來,今年我們將看到更多圍繞“通過推理時間計算擴展進行推理”研究的兩個主要分支的論文: 1. 純粹以開發(fā)達到基準的最佳模型為中心的研究。2. 關注于平衡不同推理任務之間的成本和性能權衡的研究。無論哪種方式,推理時間計算擴展的優(yōu)點在于它可以應用于任何類型的現(xiàn)有 LLM,以使其更好地完成特定任務。
按需思考
在 DeepSeek R1 發(fā)布之后,感覺各家公司都在爭相為其產(chǎn)品添加推理功能。 一個有趣的發(fā)展是,大多數(shù) LLM 提供商開始為用戶添加啟用或禁用思考的選項。該機制并未公開分享,但它可能是具有回撥推理時間計算擴展的相同模型。 例如,Claude 3.7 Sonnet和Grok 3現(xiàn)在具有用戶可以為其模型啟用的“思考”功能,而 OpenAI 則要求用戶在模型之間切換。例如,如果他們想使用顯式推理模型,則可以使用 GPT4o/4.5 和 o1/o3-mini。然而,OpenAI 首席執(zhí)行官提到,GPT4.5 很可能是他們的最后一個模型,它沒有明確的推理或“思考”模式。在開源方面,甚至 IBM 也為他們的Granite 模型添加了一個顯式的“思考”切換。總體而言,無論是通過推理時間還是訓練時間計算擴展來增加推理能力的趨勢都是 2025 年 LLM 向前邁出的重要一步。 隨著時間的推移,預計推理將不再被視為可選或特殊功能,而是成為標準,就像指令微調(diào)或 RLHF 調(diào)整模型現(xiàn)在成為原始預訓練模型的標準一樣。
-
語言模型
+關注
關注
0文章
552瀏覽量
10517 -
LLM
+關注
關注
1文章
316瀏覽量
585
發(fā)布評論請先 登錄
相關推薦
一種基于機器學習的流簇大小推理模型

當人工智能推理模型不確定時,計算環(huán)境應該是什么樣子?
基于Transformer的大型語言模型(LLM)的內(nèi)部機制

mlc-llm對大模型推理的流程及優(yōu)化方案
Hugging Face LLM部署大語言模型到亞馬遜云科技Amazon SageMaker推理示例

自然語言處理應用LLM推理優(yōu)化綜述

LLM大模型推理加速的關鍵技術
阿里云發(fā)布開源多模態(tài)推理模型QVQ-72B-Preview
智譜GLM-Zero深度推理模型預覽版正式上線
智譜推出深度推理模型GLM-Zero預覽版
科大訊飛即將發(fā)布訊飛星火深度推理模型X1
科大訊飛發(fā)布星火深度推理模型X1
新品| LLM630 Compute Kit,AI 大語言模型推理開發(fā)平臺

新品 | Module LLM Kit,離線大語言模型推理模塊套裝





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論