") 使用MLC-LLM支持RWKV-5推理的過(guò)程思考
使用MLC-LLM支持RWKV-5推理的過(guò)程思考
自從2023年3月左右,chatgpt火熱起來(lái)之后,我把關(guān)注的一些知乎帖子都記錄到了這個(gè)markdown里面,:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/large-language-model-note ,從2023年3月左右到現(xiàn)在保持了持續(xù)動(dòng)態(tài)更新整理,有關(guān)于LLM基礎(chǔ)知識(shí),LLM訓(xùn)練,LLM推理等各個(gè)方面的知乎文章鏈接,感興趣的讀者可以看一下。
0x0. 前言
繼續(xù)填 使用MLC-LLM將RWKV 3B模型跑在Android手機(jī)上(redmi k50每s可解碼8個(gè)token 這篇文章留下的坑。由于上面這篇文章支持的是RWKV4模型,不支持最近RWKV社區(qū)正在訓(xùn)練的RWKV5模型,所以利用業(yè)余時(shí)間在MLC-LLM里面支持了最新的RWKV5模型的推理,同時(shí)也可以帶大家看一下RWKV5的3B模型表現(xiàn)是否有驚艷之處。目前我跑通了Metal和Android平臺(tái)的RWKV5推理(包含1.5B和3B),并且也編譯出了一個(gè)3B int8模式的apk提供給android用戶(hù)使用,地址為:https://github.com/BBuf/run-rwkv-world-4-in-mlc-llm/releases/download/v1.0.0/rwkv5-3b-int8.apk 。大家可以下載這個(gè)apk來(lái)體驗(yàn)最新的RWKV-5-3B模型。
另外,我在測(cè)試RWKV-5-3B的時(shí)候也發(fā)現(xiàn)了RWKV4的表現(xiàn)和HuggingFace版本的表現(xiàn)相差比較多,也修復(fù)了這個(gè)bug。總的來(lái)說(shuō),在MLC-LLM里面適配一個(gè)新的RWKV5模型是比較麻煩的,我前后肝了幾個(gè)周末,并且在Hzfengsy的熱心幫助下解決了一個(gè)關(guān)鍵的TIR實(shí)現(xiàn)問(wèn)題后。這篇文章我會(huì)分享一下適配過(guò)程中的主要問(wèn)題是什么,給想使用MLC-LLM適配其它不支持的模型的讀者一個(gè)踩坑經(jīng)驗(yàn)。
關(guān)于RWKV模型的更多信息大家可以關(guān)注bo的兩篇博客:
RWKV-5 的訓(xùn)練進(jìn)展,與 SOTA GPT 模型的性能對(duì)比:https://zhuanlan.zhihu.com/p/659872347
RWKV-5 的訓(xùn)練進(jìn)展(之二),與 SotA GPT 模型的性能對(duì)比:https://zhuanlan.zhihu.com/p/664079347
再次感謝@Hzfengsy 在適配RWKV-5過(guò)程中的指導(dǎo)。
本文涉及到的工程代碼體現(xiàn)在下面的2個(gè)PR:
https://github.com/mlc-ai/mlc-llm/pull/1275 (MLC-LLM中支持RWKV5)
https://github.com/mlc-ai/tokenizers-cpp/pull/19 (對(duì)RWKV World Tokenzier的bug修復(fù),也提升了RWKV-4-World系列模型的效果)
另外,目前MLC-LLM支持RWKV-5在Metal和Android的推理,但是在nvidia gpu上因?yàn)橐粋€(gè)已知的tvm bug導(dǎo)致編譯失敗,如果要在Nvidia GPU上部署RWKV-5-World模型需要等官方完成這個(gè)bug fix,具體請(qǐng)關(guān)注 https://github.com/mlc-ai/mlc-llm/pull/1275 進(jìn)展。
0x1. 筆者為何關(guān)注RWKV
對(duì)LLM的理解比較有限,從代碼實(shí)現(xiàn)的角度來(lái)說(shuō),RWKV的狀態(tài)和KV Cache不同,不依賴(lài)序列長(zhǎng)度,這讓RWKV模型在各種長(zhǎng)度下運(yùn)行內(nèi)存和運(yùn)行速度都是趨于穩(wěn)定的,所以我感覺(jué)工程價(jià)值是比基于Transformer架構(gòu)比如Llama更好的,部署的性?xún)r(jià)比會(huì)天然更優(yōu)。這個(gè)特點(diǎn)讓他在更長(zhǎng)的序列比如100K長(zhǎng)度下的推理也更有前景吧。但是,RWKV是否可以取得和Transformer主流架構(gòu)相同的效果呢?我個(gè)人感覺(jué)還是需要等待時(shí)間的檢驗(yàn),目前最新的RWKV5模型最多scale up到7B,并且數(shù)據(jù)也是很有限只有1.12TB,這個(gè)信息我是從HuggingFace的項(xiàng)目看到的,如下圖所示。(這里的v2就是最新的RWKV5架構(gòu),內(nèi)部小版本命名稍顯混亂,這一點(diǎn)也可以從ChatRWKV的model.py看出)。

所以如果RWKV架構(gòu)真的可以取得和Transformer開(kāi)源SOTA架構(gòu)一樣的效果,前景是很好的。RWKV-5 的訓(xùn)練進(jìn)展(之二),與 SotA GPT 模型的性能對(duì)比:https://zhuanlan.zhihu.com/p/664079347 這里已經(jīng)貼出一些BenchMark結(jié)果:
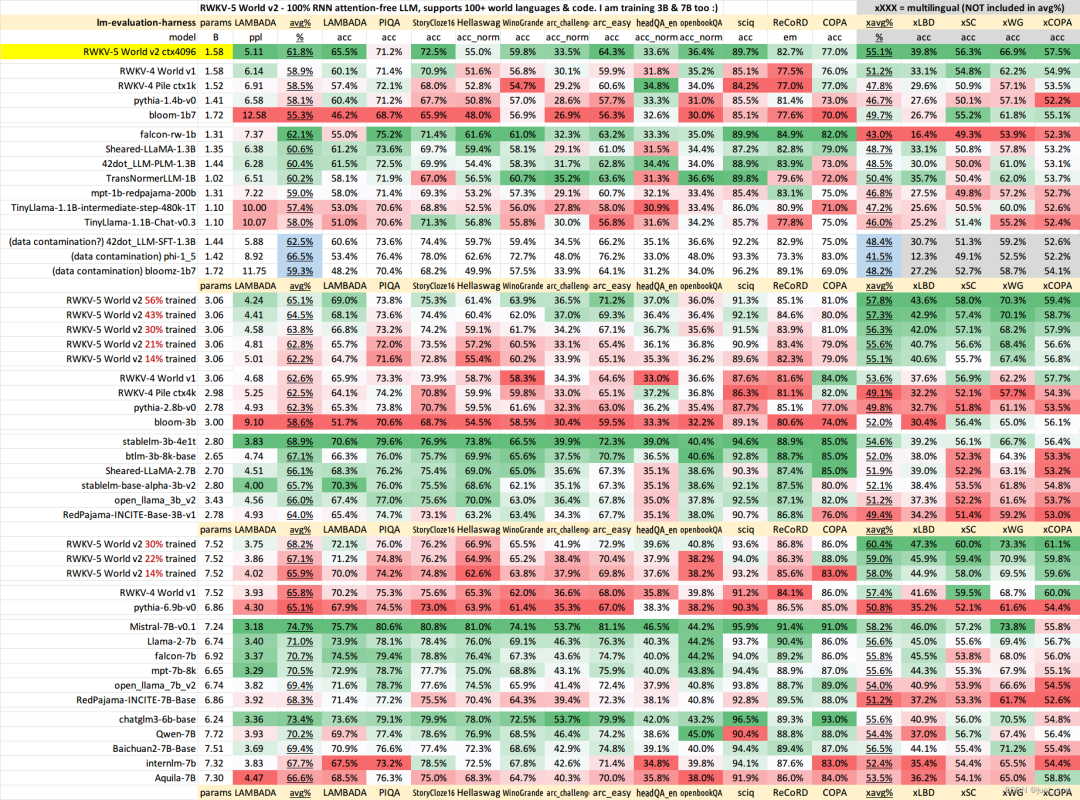
從作者這里選取的一些數(shù)據(jù)集來(lái)看,RWKV-5-World 7B目前僅訓(xùn)練30%的checkpoint的效果已經(jīng)和Baichuan2-7B-Base非常接近了,還是值得期待一下的。
不過(guò),這里存在的問(wèn)題是這里的這些測(cè)試的數(shù)據(jù)集可能需要使用一些更加有說(shuō)服力的,比如MMLU/CMMLU/HummanEval/MBPP/CMRC2018等等。這個(gè)屬于開(kāi)源大模型評(píng)測(cè)的知識(shí),大家應(yīng)該能找到很多榜單,RWKV官方是否考慮去opencompass打一下榜,更全面的做個(gè)對(duì)比。
因?yàn)檫@里有個(gè)明顯的疑問(wèn)就是,按照官方的說(shuō)法,為什么使用1.12T數(shù)據(jù)訓(xùn)練30%之后在上面的任務(wù)里面就可以幾乎持平使用2.6T數(shù)據(jù)進(jìn)行全量預(yù)訓(xùn)練的Baichuan2-7B-Base模型的效果呢?所以我個(gè)人感覺(jué)這里需要更多的榜單數(shù)據(jù)來(lái)看效果。

在這里插入圖片描述
0x2. RWKV-5-3B模型在Mac上的一些文創(chuàng)和代碼生成效果演示
我個(gè)人感覺(jué)7B模型和3B模型就是為了手機(jī)上離線運(yùn)行而生的尺寸,所以我這里使用上面編譯的Apk來(lái)演示一下使用MLC-LLM推理的RWKV-5-3B模型的一些文創(chuàng)效果和代碼生成效果。下面演示的文創(chuàng)問(wèn)題大多數(shù)來(lái)自昆侖天工的Skywork-13B例子(https://github.com/SkyworkAI/Skywork),感謝。下面的User是我問(wèn)的問(wèn)題,Assistant是RWKV-5-3B模型的回答,運(yùn)行環(huán)境為Mac M2 FP16模式。由于這個(gè)模型是基礎(chǔ)模型,所以對(duì)話效果會(huì)受到上下文多輪對(duì)話干擾,所以在測(cè)試不同種類(lèi)的問(wèn)題時(shí),可以使用/reset來(lái)重置對(duì)話。
概念介紹

在這里插入圖片描述
廣告文案

在這里插入圖片描述
作文生成

在這里插入圖片描述
演講稿生成

在這里插入圖片描述
心得體會(huì)

在這里插入圖片描述
科技文稿


記錄文

在這里插入圖片描述
評(píng)論評(píng)語(yǔ)

在這里插入圖片描述
問(wèn)題生成

在這里插入圖片描述
起名字

在這里插入圖片描述
簡(jiǎn)單代碼


總的來(lái)說(shuō),對(duì)于大多數(shù)文學(xué)創(chuàng)作問(wèn)題,RWKV-5-3B的回答還算像那回事,不過(guò)也可以明顯感覺(jué)到一些瑕疵以及指令跟隨的能力很有限,比如對(duì)數(shù)字非常不敏感,讓他說(shuō)5個(gè)字他似乎不明白意思。此外,3b模型擁有了一定的代碼能力,可以寫(xiě)有限的簡(jiǎn)單代碼。
最后,我比較期待7b最終訓(xùn)練完之后的效果,希望RWKV可以在opencompass榜單上證明自己。
0x3. MLC-LLM支持RWKV-5步驟
這一節(jié)可能會(huì)寫(xiě)得流水賬一點(diǎn)。模型實(shí)現(xiàn)文件:https://github.com/mlc-ai/mlc-llm/pull/1275 里的 rwkv5.py
首先,由于MLC-LLM已經(jīng)支持了RWKV4架構(gòu),所以我們大體上是可以使用RWKV4的實(shí)現(xiàn)的,然后把RWKV5的改動(dòng)加上去。
我們可以從ChatRWKV的rwkv4/rwkv5模型實(shí)現(xiàn)(https://github.com/BlinkDL/ChatRWKV/blob/main/rwkv_pip_package/src/rwkv/model.py)看出rwkv4和rwkv5的不同之處主要在于RWKV5引入了多頭的線性Attention,代碼上體現(xiàn)為對(duì)Attention部分的重寫(xiě),包括state的個(gè)數(shù)也從5個(gè)變成了3個(gè)。從MLC-LLM的模型實(shí)現(xiàn)代碼上來(lái)看,如果要在同一個(gè)實(shí)現(xiàn)中進(jìn)行兼容會(huì)相當(dāng)麻煩,所以我使用了一個(gè)新的文件來(lái)實(shí)現(xiàn)RWKV5,接下來(lái)就是對(duì)著ChatRWKV修改代碼把RWKV5的初版本改上去。在RWKV5的prefill階段,會(huì)調(diào)用一個(gè)新的CUDA Kernel:https://github.com/BlinkDL/ChatRWKV/blob/main/rwkv_pip_package/src/rwkv/model.py#L465-L497 。而這個(gè)Kernel的原始實(shí)現(xiàn)則對(duì)應(yīng)這里的Python公式:https://github.com/BlinkDL/RWKV-CUDA/blob/main/wkv5/run.py#L67-L87
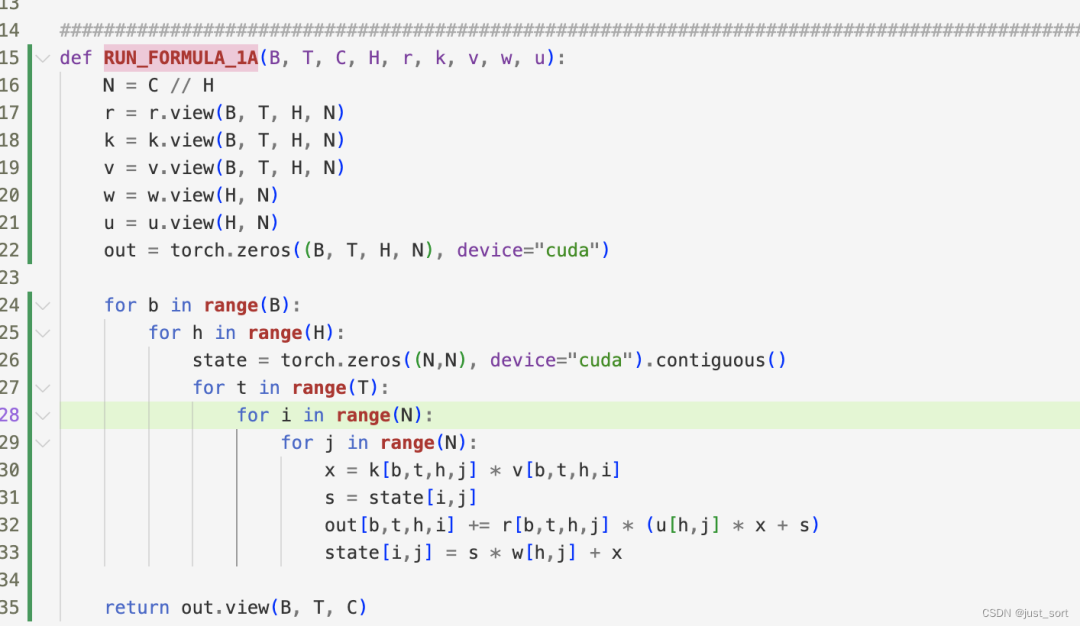
在這里插入圖片描述
但需要注意的是,在真正的模型實(shí)現(xiàn)中,這里的state是需要更新的全局變量而非local的。由于這個(gè)函數(shù)有一個(gè)循環(huán)會(huì)在T的維度上進(jìn)行迭代,而T是序列長(zhǎng)度是可變的,所以這里需要類(lèi)似于RWKV4的實(shí)現(xiàn)寫(xiě)一個(gè)TIR來(lái)模擬這個(gè)python程序的邏輯,在馮博的幫助下得到了一版初始的TIR實(shí)現(xiàn):
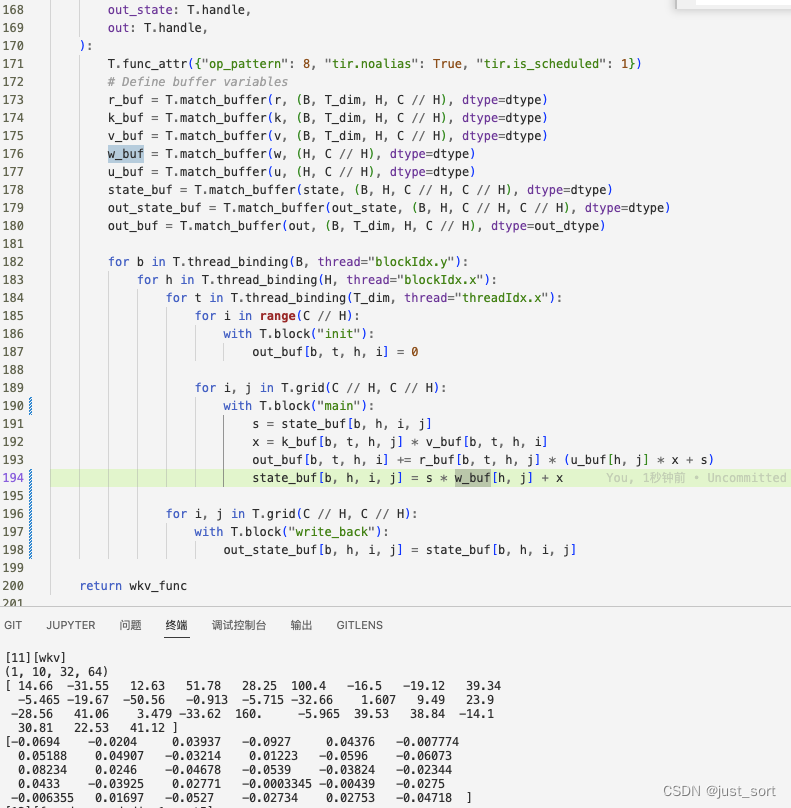
這個(gè)實(shí)現(xiàn)過(guò)程中也幫助發(fā)現(xiàn)一個(gè)DLight的bug,由@Hzfengsy在tvm里面進(jìn)行了修復(fù)。https://github.com/apache/tvm/pull/16124
解決了上面的TIR問(wèn)題之后就可以在MLC-LLM里面編譯RWKV5模型了,然后使用TVM的dump ir工具和ChatRWKV來(lái)對(duì)比精度,這里需要固定輸入的Tensor才行,為了方便我將輸入固定為一個(gè)全1的十個(gè)元素的ids。然后在對(duì)比精度的實(shí)現(xiàn)發(fā)現(xiàn),上面實(shí)現(xiàn)的TIR的輸入的所有值都是可以對(duì)上的,但是TIR的輸出out卻是錯(cuò)誤的。仍舊是馮博幫我解決了這個(gè)bug,原因是因?yàn)樯厦娴陌姹局袑?duì)于state來(lái)說(shuō)T不應(yīng)該是spatial的而是reduction。修復(fù)后的正確版本長(zhǎng)這樣:

在這里插入圖片描述
接著又從dump的結(jié)果觀察到attention部分的groupnorm的結(jié)果無(wú)法對(duì)上,但輸入都是可以對(duì)上的,然后我手動(dòng)實(shí)現(xiàn)了一下groupnorm的過(guò)程(下面的237-247行)發(fā)現(xiàn)結(jié)果竟然是可以對(duì)上的。

后面經(jīng)Hzfengsy提醒確認(rèn)是開(kāi)始的groupnorm調(diào)用參數(shù)寫(xiě)錯(cuò)了,修復(fù)之后繼續(xù)下一步。這一下attention和ffn的結(jié)果是可以對(duì)上了。
然后開(kāi)始使用mlc chat程序嘗試進(jìn)行對(duì)話,發(fā)現(xiàn)輸出會(huì)亂碼。又懷疑中間某個(gè)地方精度沒(méi)對(duì)齊,所以繼續(xù)完整模擬了一遍prefill+decode,發(fā)現(xiàn)prefill+第一輪decode的結(jié)果完全能對(duì)上,想擺爛了。。
然后我使用相同的問(wèn)題問(wèn)了一下ChatRWKV,發(fā)現(xiàn)ChatRWKV的結(jié)果也是亂碼。。。直覺(jué)告訴我一定是烏龍了,由于我這里對(duì)比的ChatRWKV是我自己fork的,可能不小心改了bug。我重新拉官方的ChatRWKV一一對(duì)比,找到了問(wèn)題所在。是因?yàn)槲业拇a里錯(cuò)誤的去掉一個(gè)transpose op,我也忘記了為什么要這么做,但是這個(gè)transpose op去transpose的兩個(gè)維度的大小是相同的,所以輸出shape也是相同的,導(dǎo)致了對(duì)精度浪費(fèi)了很多時(shí)間。
解決這個(gè)問(wèn)題之后,發(fā)現(xiàn)輸出就是正常的了。但,真的正常嗎?
我在嘗試一些問(wèn)題時(shí)發(fā)現(xiàn)輸出非常奇怪:

感覺(jué)這里一定還有bug,既然模型精度方面沒(méi)有bug,要么就是prompt技巧,tokenizer,sampling。sampling是比較正常并且經(jīng)過(guò)眾多模型檢驗(yàn)的,應(yīng)該問(wèn)題不大。然后恰好想起daquexian的faster-rwkv里面更新過(guò)tokenzier,之前的實(shí)現(xiàn)應(yīng)該有bug:
接下來(lái)就是更新tokenzier的代碼修復(fù)bug,最后在review 初始化prompt的時(shí)候也發(fā)現(xiàn)了一個(gè)bug,將其修復(fù)。
最終獲得的代碼效果就是0x2節(jié)展示的了,這些prompt的輸出和ChatRWKV相差不大,理論上來(lái)說(shuō)應(yīng)該是完成了正確的適配。
0x4. 總結(jié)
本文記錄了筆者使用 MLC-LLM 支持RWKV-5推理的過(guò)程以及對(duì)RWKV-5的一些思考,謝謝。
編輯:黃飛
-
Android
+關(guān)注
關(guān)注
12文章
3938瀏覽量
127572 -
gpu
+關(guān)注
關(guān)注
28文章
4753瀏覽量
129064 -
LLM
+關(guān)注
關(guān)注
0文章
294瀏覽量
354
原文標(biāo)題:0x4. 總結(jié)
文章出處:【微信號(hào):GiantPandaCV,微信公眾號(hào):GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
對(duì)比解碼在LLM上的應(yīng)用
【飛凌嵌入式OK3576-C開(kāi)發(fā)板體驗(yàn)】rkllm板端推理
思考驅(qū)動(dòng)創(chuàng)新,創(chuàng)新驅(qū)動(dòng)發(fā)展:基于假設(shè)(Assumption)的思考技術(shù)
如何識(shí)別slc和mlc芯片及slc mlc區(qū)別
基準(zhǔn)數(shù)據(jù)集(CORR2CAUSE)如何測(cè)試大語(yǔ)言模型(LLM)的純因果推理能力
MLC-LLM的編譯部署流程

mlc-llm對(duì)大模型推理的流程及優(yōu)化方案
如何使用MLC-LLM在A100/Mac M2上部署RWKV模型

Hugging Face LLM部署大語(yǔ)言模型到亞馬遜云科技Amazon SageMaker推理示例

怎樣使用Accelerate庫(kù)在多GPU上進(jìn)行LLM推理呢?
安霸發(fā)布N1系列生成式AI芯片支持前端設(shè)備運(yùn)行本地LLM應(yīng)用
自然語(yǔ)言處理應(yīng)用LLM推理優(yōu)化綜述






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論