") 為什么要有attention機制,Attention原理
為什么要有attention機制,Attention原理
為什么要有attention機制
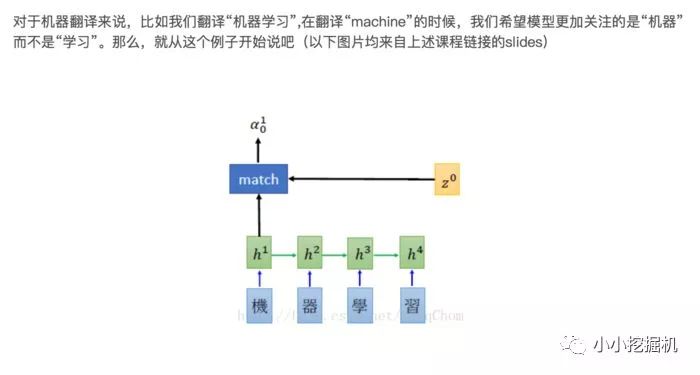
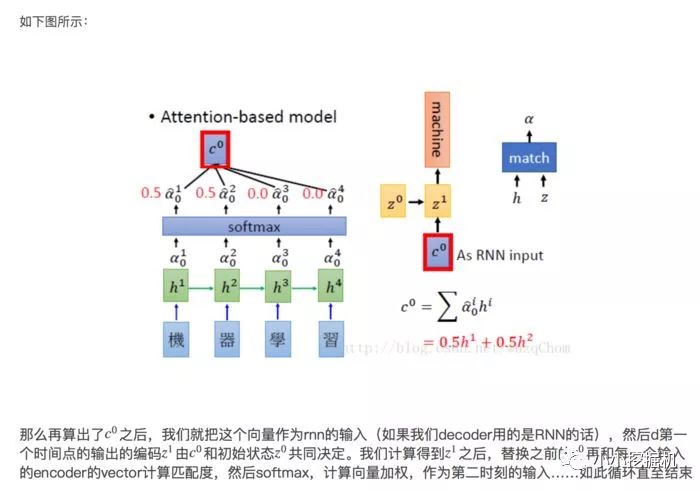
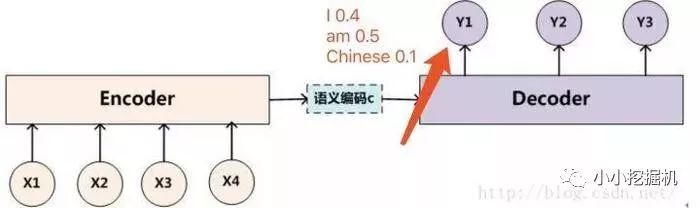
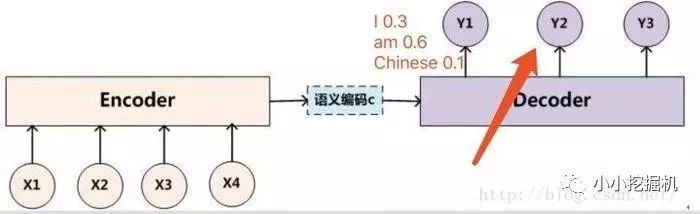
原本的Seq2seq模型只有一個encoder和一個decoder,通常的做法是將一個輸入的句子編碼成一個固定大小的state,然后作為decoder的初始狀態(tài)(當然也可以作為每一時刻的輸入),但這樣的一個狀態(tài)對于decoder中的所有時刻都是一樣的。
attention即為注意力,人腦在對于的不同部分的注意力是不同的。需要attention的原因是非常直觀的,當我們看一張照片時,照片上有一個人,我們的注意力會集中在這個人身上,而它身邊的花草藍天,可能就不會得到太多的注意力。也就是說,普通的模型可以看成所有部分的attention都是一樣的,而這里的attention-based model對于不同的部分,重要的程度則不同,decoder中每一個時刻的狀態(tài)是不同的。
Attention-based Model是什么Attention-based Model其實就是一個相似性的度量,當前的輸入與目標狀態(tài)越相似,那么在當前的輸入的權(quán)重就會越大,說明當前的輸出越依賴于當前的輸入。嚴格來說,Attention并算不上是一種新的model,而僅僅是在以往的模型中加入attention的思想,所以Attention-based Model或者Attention Mechanism是比較合理的叫法,而非Attention Model。
沒有attention機制的encoder-decoder結(jié)構(gòu)通常把encoder的最后一個狀態(tài)作為decoder的輸入(可能作為初始化,也可能作為每一時刻的輸入),但是encoder的state畢竟是有限的,存儲不了太多的信息,對于decoder過程,每一個步驟都和之前的輸入都沒有關(guān)系了,只與這個傳入的state有關(guān)。attention機制的引入之后,decoder根據(jù)時刻的不同,讓每一時刻的輸入都有所不同。
Attention原理

1.2 Beam Search介紹
在sequence2sequence模型中,beam search的方法只用在測試的情況,因為在訓練過程中,每一個decoder的輸出是有正確答案的,也就不需要beam search去加大輸出的準確率。
假設(shè)現(xiàn)在我們用機器翻譯作為例子來說明,
我們需要翻譯中文“我是中國人”--->英文“I am Chinese”
假設(shè)我們的詞表大小只有三個單詞就是I am Chinese。那么如果我們的beam size為2的話,我們現(xiàn)在來解釋,如下圖所示,我們在decoder的過程中,有了beam search方法后,在第一次的輸出,我們選取概率最大的"I"和"am"兩個單詞,而不是只挑選一個概率最大的單詞。
然后接下來我們要做的就是,把“I”單詞作為下一個decoder的輸入算一遍得到y(tǒng)2的輸出概率分布,把“am”單詞作為下一個decoder的輸入算一遍也得到y(tǒng)2的輸出概率分布。
比如將“I”單詞作為下一個decoder的輸入算一遍得到y(tǒng)2的輸出概率分布如下:
比如將“am”單詞作為下一個decoder的輸入算一遍得到y(tǒng)2的輸出概率分布如下:
那么此時我們由于我們的beam size為2,也就是我們只能保留概率最大的兩個序列,此時我們可以計算所有的序列概率:
“I I” = 0.40.3 "I am" = 0.40.6 "I Chinese" = 0.4*0.1
"am I" = 0.50.3 "am am" = 0.50.3 "am Chinese" = 0.5*0.4
我們很容易得出倆個最大概率的序列為 “I am”和“am Chinese”,然后后面會不斷重復這個過程,直到遇到結(jié)束符為止。
最終輸出2個得分最高的序列。
這就是seq2seq中的beam search算法過程。
2.1 tf.app.flags
tf定義了tf.app.flags,用于支持接受命令行傳遞參數(shù),相當于接受argv。看下面的例子:
importtensorflowastf#第一個是參數(shù)名稱,第二個參數(shù)是默認值,第三個是參數(shù)描述tf.app.flags.DEFINE_string('str_name','def_v_1',"descrip1")tf.app.flags.DEFINE_integer('int_name',10,"descript2")tf.app.flags.DEFINE_boolean('bool_name',False,"descript3")FLAGS=tf.app.flags.FLAGS#必須帶參數(shù),否則:'TypeError:main()takesnoarguments(1given)';main的參數(shù)名隨意定義,無要求defmain(_):print(FLAGS.str_name)print(FLAGS.int_name)print(FLAGS.bool_name)if__name__=='__main__':tf.app.run()#執(zhí)行main函數(shù)
使用命令行運行得到的輸出為:
[root@AliHPC-G41-211test]#pythontt.pydef_v_110False[root@AliHPC-G41-211test]#pythontt.py--str_nametest_str--int_name99--bool_nameTruetest_str99True
2.2 tf.clip_by_global_norm
Gradient Clipping的直觀作用就是讓權(quán)重的更新限制在一個合適的范圍。tf.clip_by_global_norm函數(shù)的作用就是通過權(quán)重梯度的總和的比率來截取多個張量的值。使用方式如下:
tf.clip_by_global_norm(t_list,clip_norm,use_norm=None,name=None)
t_list 是梯度張量, clip_norm 是截取的比率, 這個函數(shù)返回截取過的梯度張量和一個所有張量的全局范數(shù)。
t_list[i] 的更新公式如下:
t_list[i]*clip_norm/max(global_norm,clip_norm)
其中g(shù)lobal_norm = sqrt(sum([l2norm(t)**2 for t in t_list]))global_norm 是所有梯度的平方和,如果 clip_norm > global_norm ,就不進行截取。
2.3 tf中注意力機制的實現(xiàn)
注意力機制只在decoder中出現(xiàn),在之前作對聯(lián)的文章中,我們的decoder實現(xiàn)分三步走:定義decoder階段要是用的Cell -》TrainingHelper+BasicDecoder的組合定義解碼器-》調(diào)用dynamic_decode進行解碼。
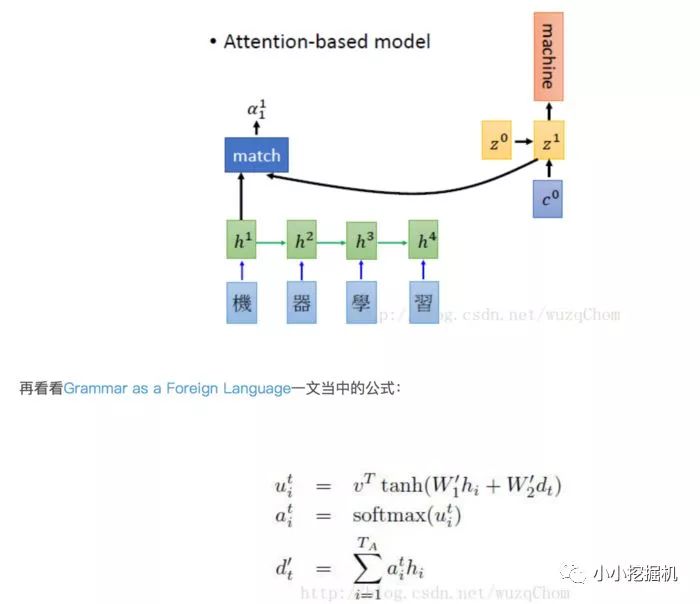
添加注意力機制主要是在第一步,對Cell進行包裹,tf中實現(xiàn)了兩種主要的注意力機制,我們前文中所講的注意力機制我們成為Bahdanau注意力機制,還有一種注意力機制稱為Luong注意力機制,二者最主要的區(qū)別是前者為加法注意力機制,后者為乘法注意力機制。二者的更詳細的介紹參考播客:http://blog.csdn.net/amds123/article/details/65938986
那么我們就來詳細介紹一下 tf中注意力機制的實現(xiàn):
定義cell
def_create_rnn_cell(self):defsingle_rnn_cell():#創(chuàng)建單個cell,這里需要注意的是一定要使用一個single_rnn_cell的函數(shù),不然直接把cell放在MultiRNNCell#的列表中最終模型會發(fā)生錯誤single_cell=tf.contrib.rnn.LSTMCell(self.rnn_size)#添加dropoutcell=tf.contrib.rnn.DropoutWrapper(single_cell,output_keep_prob=self.keep_prob_placeholder)returncell#列表中每個元素都是調(diào)用single_rnn_cell函數(shù)cell=tf.contrib.rnn.MultiRNNCell([single_rnn_cell()for_inrange(self.num_layers)])returncelldecoder_cell=self._create_rnn_cell()
封裝attention wrapper
attention_mechanism=tf.contrib.seq2seq.BahdanauAttention(num_units=self.rnn_size,memory=encoder_outputs,memory_sequence_length=encoder_inputs_length)#attention_mechanism=tf.contrib.seq2seq.LuongAttention(num_units=self.rnn_size,memory=encoder_outputs,memory_sequence_length=encoder_inputs_length)decoder_cell=tf.contrib.seq2seq.AttentionWrapper(cell=decoder_cell,attention_mechanism=attention_mechanism,attention_layer_size=self.rnn_size,name='Attention_Wrapper')
訓練階段,使用TrainingHelper+BasicDecoder的組合
training_helper=tf.contrib.seq2seq.TrainingHelper(inputs=decoder_inputs_embedded, sequence_length=self.decoder_targets_length,time_major=False,name='training_helper')training_decoder=tf.contrib.seq2seq.BasicDecoder(cell=decoder_cell,helper=training_helper,initial_state=decoder_initial_state,output_layer=output_layer)
調(diào)用dynamic_decode進行解碼
decoder_outputs,_,_=tf.contrib.seq2seq.dynamic_decode(decoder=training_decoder,impute_finished=True,maximum_iterations=self.max_target_sequence_length)
decoder_outputs是一個namedtuple,里面包含兩項(rnn_outputs, sample_id)rnn_output: [batch_size, decoder_targets_length, vocab_size],保存decode每個時刻每個單詞的概率,可以用來計算loss sample_id: [batch_size], tf.int32,保存最終的編碼結(jié)果。可以表示最后的答案。
代碼目錄如下圖所示:
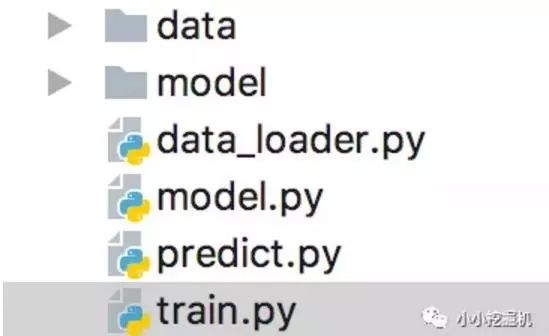
其中,data存放我們的數(shù)據(jù),model存放我們保存的訓練模型,data_loader是我們處理數(shù)據(jù)的代碼,model是我們建立seq2seq模型的代碼,train是我們訓練模型的代碼,predict是我們進行模型預測的部分。這里我們只介紹model部分,其它部分的代碼大家可以參照github自己練習。
定義基本的輸入輸出
def__init__(self,rnn_size,num_layers,embedding_size,learning_rate,word_to_idx,mode,use_attention,beam_search,beam_size,max_gradient_norm=5.0):self.learing_rate=learning_rateself.embedding_size=embedding_sizeself.rnn_size=rnn_sizeself.num_layers=num_layersself.word_to_idx=word_to_idxself.vocab_size=len(self.word_to_idx)self.mode=modeself.use_attention=use_attentionself.beam_search=beam_searchself.beam_size=beam_sizeself.max_gradient_norm=max_gradient_norm#執(zhí)行模型構(gòu)建部分的代碼self.build_model()
定義我們多層LSTM的網(wǎng)絡(luò)結(jié)構(gòu)這里,不論是encoder還是decoder,我們都定義一個兩層的LSTMCell,同時每一個cell都添加上DropoutWrapper。
def_create_rnn_cell(self):defsingle_rnn_cell():#創(chuàng)建單個cell,這里需要注意的是一定要使用一個single_rnn_cell的函數(shù),不然直接把cell放在MultiRNNCell#的列表中最終模型會發(fā)生錯誤single_cell=tf.contrib.rnn.LSTMCell(self.rnn_size)#添加dropoutcell=tf.contrib.rnn.DropoutWrapper(single_cell,output_keep_prob=self.keep_prob_placeholder)returncell#列表中每個元素都是調(diào)用single_rnn_cell函數(shù)cell=tf.contrib.rnn.MultiRNNCell([single_rnn_cell()for_inrange(self.num_layers)])returncell
定義模型的placeholder
self.encoder_inputs=tf.placeholder(tf.int32,[None,None],name='encoder_inputs')self.encoder_inputs_length=tf.placeholder(tf.int32,[None],name='encoder_inputs_length')self.batch_size=tf.placeholder(tf.int32,[],name='batch_size')self.keep_prob_placeholder=tf.placeholder(tf.float32,name='keep_prob_placeholder')self.decoder_targets=tf.placeholder(tf.int32,[None,None],name='decoder_targets')self.decoder_targets_length=tf.placeholder(tf.int32,[None],name='decoder_targets_length')self.max_target_sequence_length=tf.reduce_max(self.decoder_targets_length,name='max_target_len')self.mask=tf.sequence_mask(self.decoder_targets_length,self.max_target_sequence_length,dtype=tf.float32,name='masks')
定義encoder
withtf.variable_scope('encoder'):#創(chuàng)建LSTMCell,兩層+dropoutencoder_cell=self._create_rnn_cell()#構(gòu)建embedding矩陣,encoder和decoder公用該詞向量矩陣embedding=tf.get_variable('embedding',[self.vocab_size,self.embedding_size])encoder_inputs_embedded=tf.nn.embedding_lookup(embedding,self.encoder_inputs)#使用dynamic_rnn構(gòu)建LSTM模型,將輸入編碼成隱層向量。#encoder_outputs用于attention,batch_size*encoder_inputs_length*rnn_size,#encoder_state用于decoder的初始化狀態(tài),batch_size*rnn_szieencoder_outputs,encoder_state=tf.nn.dynamic_rnn(encoder_cell,encoder_inputs_embedded,sequence_length=self.encoder_inputs_length,dtype=tf.float32)
定義decoder在decoder階段,我們?nèi)匀皇嵌x了兩種模式,一種是訓練,一種是預測,在訓練模式下,decoder的輸入是真實的target序列,而在預測時,我們可以使用貪心策略或者是beam_search策略。
withtf.variable_scope('decoder'):encoder_inputs_length=self.encoder_inputs_length#ifself.beam_search:##如果使用beam_search,則需要將encoder的輸出進行tile_batch,其實就是復制beam_size份。#print("usebeamsearchdecoding..")#encoder_outputs=tf.contrib.seq2seq.tile_batch(encoder_outputs,multiplier=self.beam_size)#encoder_state=nest.map_structure(lambdas:tf.contrib.seq2seq.tile_batch(s,self.beam_size),encoder_state)#encoder_inputs_length=tf.contrib.seq2seq.tile_batch(self.encoder_inputs_length,multiplier=self.beam_size)attention_mechanism=tf.contrib.seq2seq.BahdanauAttention(num_units=self.rnn_size,memory=encoder_outputs,memory_sequence_length=encoder_inputs_length)#attention_mechanism=tf.contrib.seq2seq.LuongAttention(num_units=self.rnn_size,memory=encoder_outputs,memory_sequence_length=encoder_inputs_length)#定義decoder階段要是用的LSTMCell,然后為其封裝attentionwrapperdecoder_cell=self._create_rnn_cell()decoder_cell=tf.contrib.seq2seq.AttentionWrapper(cell=decoder_cell,attention_mechanism=attention_mechanism,attention_layer_size=self.rnn_size,name='Attention_Wrapper')#如果使用beam_seach則batch_size=self.batch_size*self.beam_size。因為之前已經(jīng)復制過一次#batch_size=self.batch_sizeifnotself.beam_searchelseself.batch_size*self.beam_sizebatch_size=self.batch_size#定義decoder階段的初始化狀態(tài),直接使用encoder階段的最后一個隱層狀態(tài)進行賦值decoder_initial_state=decoder_cell.zero_state(batch_size=batch_size,dtype=tf.float32).clone(cell_state=encoder_state)output_layer=tf.layers.Dense(self.vocab_size,kernel_initializer=tf.truncated_normal_initializer(mean=0.0,stddev=0.1))ifself.mode=='train':#定義decoder階段的輸入,其實就是在decoder的target開始處添加一個
訓練階段對于訓練階段,需要執(zhí)行self.train_op, self.loss, self.summary_op三個op,并傳入相應(yīng)的數(shù)據(jù)
deftrain(self,sess,batch):#對于訓練階段,需要執(zhí)行self.train_op,self.loss,self.summary_op三個op,并傳入相應(yīng)的數(shù)據(jù)feed_dict={self.encoder_inputs:batch.encoder_inputs,self.encoder_inputs_length:batch.encoder_inputs_length,self.decoder_targets:batch.decoder_targets,self.decoder_targets_length:batch.decoder_targets_length,self.keep_prob_placeholder:0.5,self.batch_size:len(batch.encoder_inputs)}_,loss,summary=sess.run([self.train_op,self.loss,self.summary_op],feed_dict=feed_dict)returnloss,summary
評估階段對于eval階段,不需要反向傳播,所以只執(zhí)行self.loss, self.summary_op兩個op,并傳入相應(yīng)的數(shù)據(jù)
defeval(self,sess,batch):#對于eval階段,不需要反向傳播,所以只執(zhí)行self.loss,self.summary_op兩個op,并傳入相應(yīng)的數(shù)據(jù)feed_dict={self.encoder_inputs:batch.encoder_inputs,self.encoder_inputs_length:batch.encoder_inputs_length,self.decoder_targets:batch.decoder_targets,self.decoder_targets_length:batch.decoder_targets_length,self.keep_prob_placeholder:1.0,self.batch_size:len(batch.encoder_inputs)}loss,summary=sess.run([self.loss,self.summary_op],feed_dict=feed_dict)returnloss,summary
預測階段infer階段只需要運行最后的結(jié)果,不需要計算loss,所以feed_dict只需要傳入encoder_input相應(yīng)的數(shù)據(jù)即可
definfer(self,sess,batch):#infer階段只需要運行最后的結(jié)果,不需要計算loss,所以feed_dict只需要傳入encoder_input相應(yīng)的數(shù)據(jù)即可feed_dict={self.encoder_inputs:batch.encoder_inputs,self.encoder_inputs_length:batch.encoder_inputs_length,self.keep_prob_placeholder:1.0,self.batch_size:len(batch.encoder_inputs)}predict=sess.run([self.decoder_predict_decode],feed_dict=feed_dict)returnpredict
-
Decoder
+關(guān)注
關(guān)注
0文章
25瀏覽量
10728 -
梯度
+關(guān)注
關(guān)注
0文章
30瀏覽量
10335 -
機器翻譯
+關(guān)注
關(guān)注
0文章
139瀏覽量
14922
原文標題:使用Seq2Seq+attention實現(xiàn)簡單的Chatbot
文章出處:【微信號:atleadai,微信公眾號:LeadAI OpenLab】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Attention的具體原理詳解
深度學習模型介紹,Attention機制和其它改進
將自注意力機制引入GAN,革新圖像合成方式

究竟Self-Attention結(jié)構(gòu)是怎樣的?
知識蒸餾是一種模型壓縮常見方法

首個基于深度學習的端到端在線手寫數(shù)學公式識別模型
使用知識圖譜作為輸入的表征,研究一個端到端的graph-to-text生成系統(tǒng)
基于BERT+Bo-LSTM+Attention的病歷短文分類模型

一種Attention-CNN惡意代碼檢測模型

簡述深度學習中的Attention機制
解析ChatGPT背后的技術(shù)演進
計算機視覺中的注意力機制

詳細介紹?注意力機制中的掩碼
降低Transformer復雜度O(N^2)的方法匯總

深入淺出理解PagedAttention CUDA實現(xiàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論