 使用知識圖譜作為輸入的表征,研究一個端到端的graph-to-text生成系統
使用知識圖譜作為輸入的表征,研究一個端到端的graph-to-text生成系統
背景
生成表達復雜含義的多句文本需要結構化的表征作為輸入,本文使用知識圖譜作為輸入的表征,研究一個端到端的graph-to-text生成系統,并將其應用到科技類文本寫作領域。作者使用一個科技類文章數據集的摘要部分,使用一個IE來為每個摘要提取信息,再將其重構成知識圖譜的形式。作者通過實驗表明,將IE抽取到知識用圖來表示會比直接使用實體有更好的生成效果。
graph-to-text的一個重要任務是從 Abstract Meaning Representation (AMR) graph生成內容,其中圖的編碼方法主要有graph convolution encoder,graph attention encoder,graph LSTM,本文的模型是graph attention encoder的一個延伸。
數據集
作者構建了一個Abstract GENeration Dataset(AGENDA),該數據包含40k個AI會議的論文標題和摘要。對于數據集中的每篇摘要,首先使用SciIE來獲取摘要中的命名實體及實體之間的關系(Compare, Used-for, Feature-of, Hyponymof,Evaluate-for, and Conjunction),隨后將得到的這些組織成無連接帶標簽圖的形式。
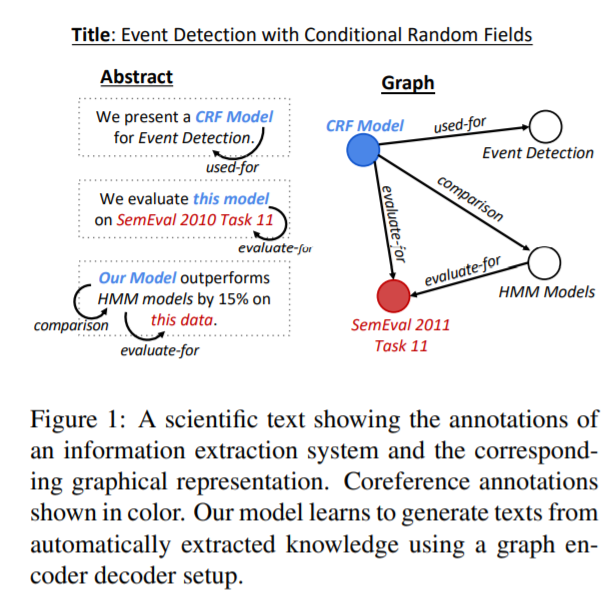
模型
GraphWriter模型總覽

構建圖
將之前數據集中的無連接帶標簽圖,轉化為有連接無標簽圖,具體做法為:原圖中的每個表示關系的邊用兩個節點替代,一個表示正向的關系,一個表示反向的關系;增加一個與所有實體節點連接全局向量節點,該向量將會被用來作為解碼器的初始輸入。下圖中表示實體節點,表示關系,表示全局向量節點

最終得到的有連接,無標簽圖為G=(V,E),其中V表示實體/關系/全局向量節點,E表示連接矩陣(注意這里的G和V區別上述圖中的G和v)。
Graph Transformer

Graph Transformer由L個Block Network疊加構成,在每個Block內,節點的嵌入首先送入Graph Attention模塊。這里使用多頭自注意力機制,每個節點表征通過與其連接的節點使用注意力,來得到上下文相關的表征。得到的表征隨后再送入正則化層和一個兩層的前饋神經網絡層。最后一層的得到的即表示上下文后的實體,關系,全局向量節點。

解碼器
在每個時間步t使用隱藏狀態來計算圖和標題的上下文向量和,其中通過使用多頭注意力得到,

也通過類似的方式得到,最終的上下文向量是兩者的疊加。隨后使用類似pointer-network的方法來生成一個新詞或復制一個詞,
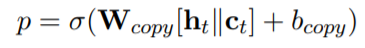

實驗
實驗包含自動和人工評估,在自動評估中,GraphWriter代表本篇文章的模型,GAT中將Graph Transformer encoder使用一個Graph Attention Network替換,Entity Writer僅使用到了實體和標題沒有圖的關系信息,Rewriter僅僅使用了文章的標題,

從上圖可以看到,使用標題,實體,關系的模型(GraphWriter和GAT)的表現要顯著好于使用更少信息的模型。在人工評估中,使用Best-Worst Scaling,

-
數據集
+關注
關注
4文章
1209瀏覽量
24827 -
Transformer
+關注
關注
0文章
145瀏覽量
6045 -
知識圖譜
+關注
關注
2文章
132瀏覽量
7738
原文標題:【論文解讀】基于圖Transformer從知識圖譜中生成文本
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
端到端自動駕駛技術研究與分析
黑芝麻智能端到端算法參考模型公布
爆火的端到端如何加速智駕落地?
連接視覺語言大模型與端到端自動駕駛

三星電子將收購英國知識圖譜技術初創企業
知識圖譜與大模型之間的關系
佐思汽研發布《2024年端到端自動駕駛研究報告》

利用知識圖譜與Llama-Index技術構建大模型驅動的RAG系統(下)






 工商網監
工商網監
評論