") 了解BERT原理、技術(shù)、實(shí)踐,只需3分鐘
了解BERT原理、技術(shù)、實(shí)踐,只需3分鐘
本文對(duì)BERT的原理、技術(shù)細(xì)節(jié)以及如何應(yīng)用于實(shí)際場(chǎng)景中,做了簡(jiǎn)明扼要的介紹。看完本文相信您會(huì)對(duì)BERT為什么被認(rèn)為是當(dāng)前最好的NLP模型、實(shí)現(xiàn)原理以及適用場(chǎng)景有所了解。
目前最好的自然語(yǔ)言預(yù)訓(xùn)練方法無(wú)疑是BERT。它的工作流程分為兩步:
首先,使用大量未標(biāo)記的數(shù)據(jù),以預(yù)訓(xùn)練、也就是無(wú)人監(jiān)督的方式學(xué)習(xí)語(yǔ)言表達(dá)。
然后,使用少量經(jīng)過(guò)標(biāo)記的訓(xùn)練數(shù)據(jù)對(duì)模型進(jìn)行fine-tune,以監(jiān)督學(xué)習(xí)的方式,執(zhí)行多種監(jiān)督任務(wù)。
預(yù)訓(xùn)練機(jī)器學(xué)習(xí)模型已經(jīng)在包括視覺(jué)、自然語(yǔ)言處理在內(nèi)的各個(gè)領(lǐng)域取得了成功。
詳解BERT及其原理
BERT是Bidirectional Encoder Representations from Transformers的縮寫(xiě),是一種新型的語(yǔ)言模型,通過(guò)聯(lián)合調(diào)節(jié)所有層中的雙向Transformer來(lái)訓(xùn)練預(yù)訓(xùn)練深度雙向表示。
它基于谷歌2017年發(fā)布的Transformer架構(gòu),通常的Transformer使用一組編碼器和解碼器網(wǎng)絡(luò),而B(niǎo)ERT只需要一個(gè)額外的輸出層,對(duì)預(yù)訓(xùn)練進(jìn)行fine-tune,就可以滿足各種任務(wù),根本沒(méi)有必要針對(duì)特定任務(wù)對(duì)模型進(jìn)行修改。
BERT將多個(gè)Transformer編碼器堆疊在一起。Transformer基于著名的多頭注意力(Multi-head Attention)模塊,該模塊在視覺(jué)和語(yǔ)言任務(wù)方面都取得了巨大成功。
BERT的先進(jìn)性基于兩點(diǎn):首先,使用Masked Langauge Model(MLM)和Next Sentense Prediction(NSP)的新預(yù)訓(xùn)練任務(wù);其次,大量數(shù)據(jù)和計(jì)算能力滿足BERT的訓(xùn)練強(qiáng)度。
相比之下,像Word2Vec、ELMO、OpenAI GPT等傳統(tǒng)SOTA生成預(yù)訓(xùn)練方法,使用從左到右的單向訓(xùn)練,或者淺雙向,均無(wú)法做到BERT的雙向性。
MLM
MLM可以從文本執(zhí)行雙向?qū)W習(xí),即允許模型從單詞前后相鄰的單詞,學(xué)習(xí)每個(gè)單詞的上下文,這是傳統(tǒng)方法做不到的。
MLM預(yù)訓(xùn)練任務(wù)將文本轉(zhuǎn)換為符號(hào),并使用符號(hào)表示作為訓(xùn)練的輸入和輸出。15%的符號(hào)隨機(jī)子集在訓(xùn)練期間被屏蔽(類(lèi)似被隱藏起來(lái)),目標(biāo)函數(shù)則用來(lái)預(yù)測(cè)符號(hào)識(shí)別的正確率。
這與使用單向預(yù)測(cè)作為目標(biāo)、或使用從左到右和從右到左訓(xùn)練,來(lái)近似雙向性的傳統(tǒng)訓(xùn)練方法形成了對(duì)比。
但是MLM中的BERT屏蔽策略,將模型偏向于實(shí)際的單詞,還沒(méi)有數(shù)據(jù)顯示這種偏見(jiàn)對(duì)訓(xùn)練所產(chǎn)生的影響。
NSP
NSP使得BERT可以通過(guò)預(yù)測(cè)上下句之間是否連貫來(lái)得出句子之間的關(guān)系。
給出50%正確上下句配對(duì),并補(bǔ)充50%的隨機(jī)上下句配對(duì),然后對(duì)模型進(jìn)行訓(xùn)練。
MLM和NSP是同時(shí)進(jìn)行的。
數(shù)據(jù)和TPU/GPU runtime
BERT的訓(xùn)練總共使用了33億單詞。其中25億來(lái)自維基百科,剩下8億來(lái)自BooksCorpus。
訓(xùn)練使用TPU完成,GPU估算如下所示。

使用2500-392000標(biāo)記的樣品進(jìn)行fine-tune。重要的是,100K以上訓(xùn)練樣本的數(shù)據(jù)集在各種超參數(shù)上表現(xiàn)出強(qiáng)大的性能。
每個(gè)fine-tune實(shí)驗(yàn)在單個(gè)云TPU上運(yùn)行1小時(shí),在GPU上需要運(yùn)行幾個(gè)小時(shí)不等。
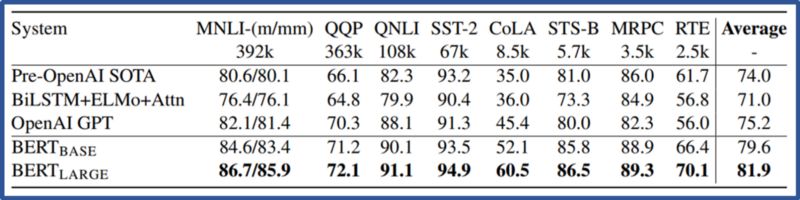
結(jié)果顯示,BERT優(yōu)于11項(xiàng)NLP任務(wù)。在SQUAD和SWAG兩個(gè)任務(wù)中,BERT成為第一個(gè)超越人類(lèi)的NLP模型!
BERT能夠解決的實(shí)際任務(wù)類(lèi)型
BERT預(yù)訓(xùn)練了104種語(yǔ)言,已在TensorFlow和Pytorch中實(shí)現(xiàn)并開(kāi)源。Clone地址:
https://github.com/google-research/Bert
BERT可以針對(duì)幾種類(lèi)型的任務(wù)進(jìn)行fine-tune。例如文本分類(lèi)、文本相似性、問(wèn)答、文本標(biāo)簽、如詞性、命名實(shí)體識(shí)別等。
但是,預(yù)訓(xùn)練BERT是很貴的,除非使用類(lèi)似于Nvidia V100這樣的TPU或GPU。
BERT人員還發(fā)布了一個(gè)單獨(dú)的多語(yǔ)種模型,該模型使用整個(gè)維基百科的100種語(yǔ)言進(jìn)行訓(xùn)練,性能比單語(yǔ)種的低幾個(gè)百分點(diǎn)。
-
編碼器
+關(guān)注
關(guān)注
45文章
3663瀏覽量
135019 -
自然語(yǔ)言
+關(guān)注
關(guān)注
1文章
289瀏覽量
13381 -
nlp
+關(guān)注
關(guān)注
1文章
489瀏覽量
22066
原文標(biāo)題:3分鐘看懂史上最強(qiáng)NLP模型BERT
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
OPPO閃充,15分鐘充滿一部手機(jī)電量
新型有機(jī)電池ORB 充電只需1分鐘
深圳現(xiàn)身會(huì)炒菜機(jī)器人:最快只需3分鐘炒好酸辣土豆絲
三星改革智能手機(jī)充電技術(shù),充滿只需十分鐘
華為推出一款快速充電電池,只需5分鐘就可以充滿50%電量
1024塊TPU在燃燒!將BERT預(yù)訓(xùn)練模型的訓(xùn)練時(shí)長(zhǎng)從3天縮減到了76分鐘
OPPO Reno Ace曝光搭載65W超級(jí)閃充只需要30分鐘就能充滿電
OPPO Reno 3 Pro將搭載增強(qiáng)版的VOOC 4.0最快56分鐘充滿電
3分鐘了解嵌入式的硬件構(gòu)架資料下載

3分鐘了解ePort關(guān)鍵設(shè)計(jì)技巧

3分鐘了解ePort關(guān)鍵設(shè)計(jì)技巧

【產(chǎn)品應(yīng)用】3分鐘了解ePort關(guān)鍵設(shè)計(jì)技巧





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論