") 1024塊TPU在燃燒!將BERT預(yù)訓(xùn)練模型的訓(xùn)練時(shí)長從3天縮減到了76分鐘
1024塊TPU在燃燒!將BERT預(yù)訓(xùn)練模型的訓(xùn)練時(shí)長從3天縮減到了76分鐘
“Jeff Dean稱贊,TensorFlow官方推特支持,BERT目前工業(yè)界最耗時(shí)的應(yīng)用,計(jì)算量遠(yuǎn)高于ImageNet。我們將BERT的訓(xùn)練時(shí)間從三天縮短到了一小時(shí)多。”UC Berkeley大學(xué)在讀博士尤洋如是說道。
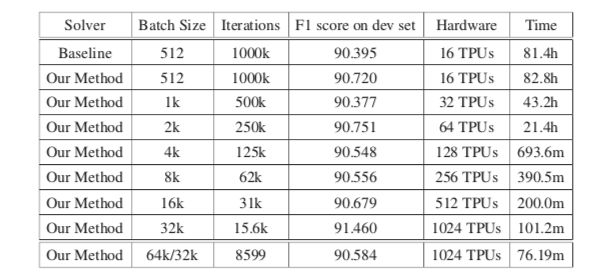
近日,來自Google、UC Berkeley、UCLA研究團(tuán)隊(duì)再度合作,成功燃燒1024塊TPU,將BERT預(yù)訓(xùn)練模型的訓(xùn)練時(shí)長從3天縮減到了76分鐘。batch size技術(shù)是加速神經(jīng)網(wǎng)絡(luò)訓(xùn)練的關(guān)鍵,在“Reducing BERT Pre-Training Time from 3 Days to 76 Minutes”這篇論文中,作者提出了LAMB優(yōu)化器,它支持自適應(yīng)元素更新和分層校正。
論文傳送門:https://arxiv.org/pdf/1904.00962.pdf
論文摘要:batch size增加到很大時(shí)的模型訓(xùn)練是加速大型分布式系統(tǒng)中深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練的關(guān)鍵。但是,這種模型訓(xùn)練很難,因?yàn)樗鼤?huì)導(dǎo)致一種泛化差距。直接優(yōu)化通常會(huì)導(dǎo)致測試集上的準(zhǔn)確性下降。
BERT是一種先進(jìn)的深度學(xué)習(xí)模型,它建立在語義理解的深度雙向轉(zhuǎn)換器上。當(dāng)我們增加batch size的大小(如超過8192)時(shí),此前的模型訓(xùn)練技巧在BERT上表現(xiàn)得并不好。BERT預(yù)訓(xùn)練也需要很長時(shí)間才能完成,如在16個(gè)TPUv3上大約需要三天。
為了解決這個(gè)問題,我們提出了LAMB優(yōu)化器,可將batch size擴(kuò)展到65536,且不會(huì)降低準(zhǔn)確率。LAMB是一個(gè)通用優(yōu)化器,batch size大小均使用,且除了學(xué)習(xí)率之外不需要?jiǎng)e的參數(shù)調(diào)整。
基線BERT-Large模型需要100萬次迭代才能完成預(yù)訓(xùn)練,而batch size大小為65536/32768的LAMB僅需要8599次迭代。我們還將batch size進(jìn)行內(nèi)存限制,接近TPUv3 pod,結(jié)果可在76分鐘內(nèi)完成BERT訓(xùn)練。
據(jù)悉,該論文的一作是來自UC Berkeley計(jì)算機(jī)科學(xué)部的在讀博士尤洋,同時(shí)也是Google Brain的實(shí)習(xí)生。據(jù)公開信息顯示,尤洋的導(dǎo)師是美國科學(xué)院與工程院院士,ACM/IEEE fellow,伯克利計(jì)算機(jī)系主任,以及首批中關(guān)村海外顧問James Demmel教授。他當(dāng)前的研究重點(diǎn)是大規(guī)模深度學(xué)習(xí)訓(xùn)練算法的分布式優(yōu)化。2017年9月,尤洋等人的新算法以24分鐘完成ImageNet訓(xùn)練,刷新世界紀(jì)錄。
在此之前,他曾在英特爾實(shí)驗(yàn)室、微軟研究院、英偉達(dá)、IBM沃森研究中心等機(jī)構(gòu)實(shí)習(xí)。尤洋本科就讀于中國農(nóng)業(yè)大學(xué)計(jì)算機(jī)系,碩士保送清華大學(xué)計(jì)算機(jī)系,是一名杠杠的理工學(xué)霸!
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4775瀏覽量
100920 -
TPU
+關(guān)注
關(guān)注
0文章
143瀏覽量
20752 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5508瀏覽量
121312 -
訓(xùn)練模型
+關(guān)注
關(guān)注
1文章
36瀏覽量
3872
原文標(biāo)題:1024塊TPU在燃燒!BERT訓(xùn)練從3天縮短到76分鐘 | 技術(shù)頭條
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
什么是大模型、大模型是怎么訓(xùn)練出來的及大模型作用

Llama 3 模型訓(xùn)練技巧
直播預(yù)約 |數(shù)據(jù)智能系列講座第4期:預(yù)訓(xùn)練的基礎(chǔ)模型下的持續(xù)學(xué)習(xí)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論