 基于增量K均值分段HMM的識別算法在微機器人控制系統中的應用
基于增量K均值分段HMM的識別算法在微機器人控制系統中的應用
引言
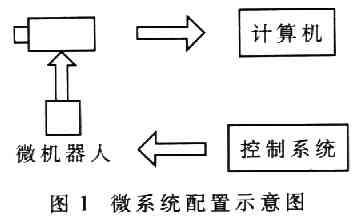
據統計,人類日常生活中的溝通大約有75%左右是通過語言來完成的。語言作為人類特有的功能,不但是相互傳遞信息的主要手段,也是人們最理想的人機交互方式之一。在現代社會機器人這個詞語已經不再新鮮。有些機器人已經走進了我們的生活,成為我們生活的組成部分。在下文我們要講的是基于毫米級全方位無回轉半徑移動機器人課題。我們微系統配置示意圖如圖1所示。主要由主機Host(配有圖像采集卡)、兩個CCD攝像頭(其中一個為顯微攝像頭)、微移動裝配平臺、微機器人本體和系統控制電路板等組成。計算機和攝像機組用于觀察微機器人的方位,控制系統控制微機器人的移動。
與機器進行語音交流,讓機器明白你說什么,這是人們長期以來夢寐以求的事情。語音識別技術就是讓機器通過識別和理解過程把語音信號轉變為相應的文本或命令的高技術。語音識別技術主要包括特征提取技術、模式匹配準則及模型訓練技術三個方面。 本文在系統控制電路中嵌入式實現語音識別算法,通過語音控制微機器人。也就是說可以通過你的話微型機器人做出相應的動作。
微機器人控制系統的資源有限,控制方法比較復雜,并且需要有較高人的實時性,因此本文采用的語音識別算法必須簡單、識別率高、占用系統資源少。畢竟微型機器人里面能放的東西有限,放多了東西雖然提高了語音識別率或者工作效率,但是也加大了微型機器人的體積,說不定就不能做有些工作。
隱馬爾可夫模型(Hidden Markov Model,HMM)作為一種統計分析模型,創立于20世紀70年代。80年代得到了傳播和發展,成為信號處理的一個重要方向,現已成功地用于語音識別,行為識別,文字識別以及故障診斷等領域。HMM(隱馬爾可夫模型)的適應性強、識別率高,是當前語音識別的主流算法。使用基于HMM非特定人的語音識別算法雖然借助模板匹配減小了識別所需的資源,但是前期的模板儲存工作需要大量的計算和存儲空間,因此移植到嵌入式系統還有一定的難度,所以很多嵌入式應用平臺的訓練部分仍在PC機上實現。
為了使訓練和識別都在嵌入式系統上實現,本文給出了一種基于K均值分段HMM模型的實時學習語音識別算法,不僅解決了上述問題,而且做到了智能化,實現了真正意義上的自動語音識別。
1 增量K均值分段HMM的算法及實現
由于語音識別過程中非特定的因素較多,為了提高識別的準確率,針對本系統的特點,采用動態改變識別參數的方法提高系統的識別率。
語音識別方法主要是模式匹配法。 在訓練階段,用戶將詞匯表中的每一詞依次說一遍,并且將其特征矢量作為模板存入模板庫。 在識別階段,將輸入語音的特征矢量依次與模板庫中的每個模板進行相似度比較,將相似度最高者作為識別結果輸出。
訓練算法是HMM中運算量最大、最復雜的部分,訓練算法的輸出是即將存儲的模型。目前的語音識別系統大都使用貝斯曼參數的HMM模型,采取最大似然度算法。這些算法通常是批處理函數,所有的訓練數據要在識別之前訓練好并存儲。因此很多嵌入式系統因為資源有限不能達到高識別率和實時輸出。
本系統采用了自適應增量K均值分段算法。在每次輸入新的語句時都連續地計算而不對前面的數據進行存儲,這可以節約大量的時間和成本。輸入語句時由系統的識別結果判斷輸入語句的序號,并對此語句的參數動態地修改,真正做到了實時學習。
K均值分段算法是基于最佳狀態序列的理論,因此可以采用Viterbi算法得到最佳狀態序列,從而方便地在線修改系統參數,使訓練的速度大大提高。
為了達到本系統所需要的功能,對通常的K均值算法作了一定的改進。在系統無人監管的情況下,Viterbi解碼計算出最大相似度的語音模型,根據這個假設計算分段K均值算法的輸入參數,對此模型進行參數重估。首先按照HMM模型的狀態數進行等間隔分段,每個間隔的數據段作為某一狀態的訓練數據,計算模型的初始參數λ=f(a,A,B)。采用Viterbi的最佳狀態序列搜索,得到當前最佳狀態序列參數和重估參數θ,其中概率密度函數P(X,S|θ)代替了最大似然度算法中的P(X,θ),在不同的馬爾科夫狀態和重估之間跳轉。基于K均值算法的參數重估流程如下:

為了使參數能更快地收斂,在每幀觀察語音最佳狀態序列的計算結束后,加入一個重估過程,以求更快地響應速度。

可以看到,增量K均值算法的特點為:在每次計算完觀察值最佳狀態序列后,插入一個重估過程。隨時調整參數以識別下一個句子。
由于采用混合高斯密度函數作為輸出概率分布可以達到較好的識別效果,因此本文采用M的混合度對數據進行訓練。
對λ重估,并比較收斂性,最終得到HMM模型參數訓練結果。
可見,用K均值法在線修改時,一次數據輸入會有多次重估過程,這使系統使用最近的模型估計后續語句的最佳狀態序列成為可能。但是對于在線修改參數要求,快速收斂是很重要的。為了得到更好的Viterbi序列,最佳狀態序列使用了漸增的算法模型,即快速收斂算法。
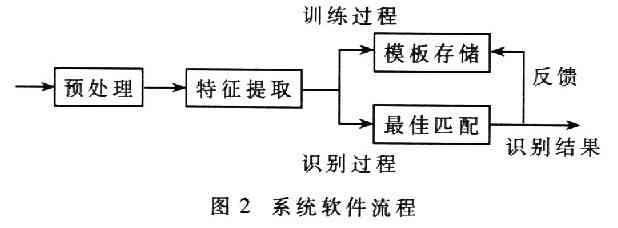
語音識別的具體實現過程為:數字語音信號通過預處理和特征向量的提取,用戶通過按鍵選擇學習或者識別模式;如果程序進入訓練過程,即用戶選擇進行新詞條的學習,則用分段K均值法對數據進行訓練得到模板;如果進入識別模式,則從Flash中調出聲音特征向量,進行HMM算法識別。在識別出結果后,立即將識別結果作為正確結果與前一次的狀態做比較,得到本詞條更好的模板,同時通過LED數字顯示和語音輸出結果。系統軟件流程如圖2所示。
對采集到的語音進行16kHz、12位量化,并對數字語音信號進行預加重:

L選擇為320個點,用短時平均能量和平均過零率判斷起始點,去除不必要的信息。
對數據進行FFT運算,得到能量譜,通過24通道的帶通濾波輸出X(k),然后再通過DCT運算,提取12個MFCC系數和一階二階對數能量,提取38個參數可以使系統識別率得到提高。
為了進行連接詞識別,需要由訓練數據得到單個詞條的模型。方法為:首先從連接詞中分離出每個孤立的詞條,然后再進行孤立詞條的模型訓練。對于本系統不定長詞條的情況,每個詞條需要有一套初始的模型參數,然后按照分層構筑的HMM算法將所有詞串分成孤立的詞條。對每個詞條進行參數的重估,判斷是否收斂。如果差異小于某個域值就判斷為收斂;否則將得到的參數作為新的初始參數再進行重估,直到收斂。
當然本系統還要對語音進行前端處理工作。主要是指在特征提取之前,先對原始語音進行處理,部分消除噪聲和不同說話人帶來的影響,使處理后的信號更能反映語音的本質特征。最常用的前端處理有端點檢測和語音增強。端點檢測是指在語音信號中將語音和非語音信號時段區分開來,準確地確定出語音信號的起始點。經過端點檢測后,后續處理就可以只對語音信號進行,這對提高模型的精確度和識別正確率有重要作用。語音增強的主要任務就是消除環境噪聲對語音的影響。目前通用的方法是采用維納濾波,該方法在噪聲較大的情況下效果好于其它濾波器。
2 實驗結果
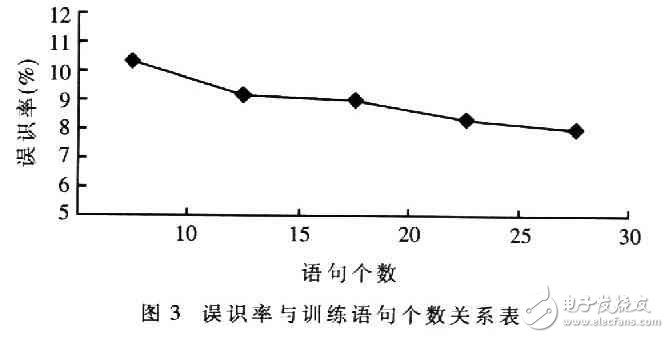
實驗采用30個人(15男,15女)的聲音模型進行識別。首先由10人(5男,5女)對5個命令詞(前進、后退、左移、右移、快速)分別進行初始數據訓練,每人每詞訓練10次,得到訓練模板。然后再由這30人隨機進行非特定人語音識別。采用6狀態的HMM模型,高斯混合度選為14,得到圖3的實驗結果。
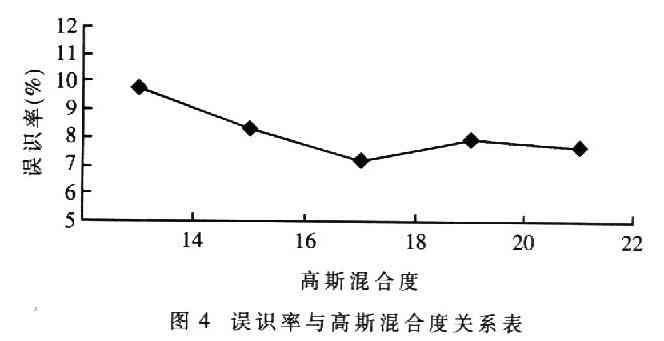
逐步增加高斯混合度數目,可以得到圖4的實驗結果。可見高斯混合度在18的時候達到較好的識別效果,混合度太高識別率反而會有所下降,這是由于嵌入式系統的資源有限,運算復雜度的增長超過了嵌入式設備的限制所造成的。
為了使微機器人能夠正確地執行人的聲音指令,本文將語音識別的過程嵌入微機器人的控制系統中,根據微機器人控制系統資源有限、對實時性要求高的特點,使用增量K均值分段HMM的算法,簡化計算節省了所需的硬件資源,實現了實時學習的語音識別,能方便地對微機器人進行控制。
本系統的識別率達到了較高的標準,又由于加入了智能化的用戶選擇部分,用戶可隨時選擇學習新的語句,使其有更廣闊的應用前景。
結論
本文介紹了一種應用于微機器人控制平臺的語音識別算法,可實現簡單命令詞語的識別,控制微機器人的移動。利用K均值分段法,在每次計算完觀察值最佳狀態序列后,插入一個重估過程,隨時調整參數以識別下一個句子。實驗結果表明,這種實時學習的語音識別算法適合嵌入式應用。當然由于嵌入式平臺受到處理速度、存儲空間的限制,所以能夠對微機器人發出的指令十分有限,識別率還有待提高。因此,研究語音識別算法,比較各種算法的優缺點,進而在嵌入式微機器人控制系統上實現大詞匯量非特定人的語音識別,實現真正意義上的人機交流是今后進一步的工作。相信在科學技術的發展迅速社會背景下,這個語音控制微型機器人的技術會逐漸發展起來,最終達到人機交流與人人交流一般。讓微型機器人的應用更加廣泛。
-
控制系統
+關注
關注
41文章
6655瀏覽量
110771 -
機器人
+關注
關注
211文章
28618瀏覽量
207916 -
攝像頭
+關注
關注
60文章
4860瀏覽量
96079
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論