 基于單目圖像的深度估計算法,大幅度提升基于單目圖像深度估計的精度
基于單目圖像的深度估計算法,大幅度提升基于單目圖像深度估計的精度
基于視覺的自動駕駛系統需要基于單目攝像頭獲取的圖像,判斷當前車輛與周圍車輛、行人和障礙物的距離,距離判斷的精度對自動駕駛系統的安全性有著決定性的影響,商湯科技在CVPR 2018發表亮點報告(Spotlight)論文,提出基于單目圖像的深度估計算法,大幅度提升基于單目圖像深度估計的精度,進一步提升自動駕駛系統的安全性。該論文由商湯科技見習研究員羅越在研究院研究員任思捷指導下完成。本文為商湯科技CVPR 2018論文解讀第5期。
簡介
基于單目圖像的深度估計算法具有方便部署、計算成本低等優點,受到了學術界和工業界日益增長的關注。現有的單目深度估計方法通常利用單一視角的圖像數據作為輸入,直接預測圖像中每個像素對應的深度值,這種解決方案導致現有方法通常需要大量的深度標注數據,而這類數據通常需要較高的采集成本。近年來的改進思路主要是在訓練過程中引入隱式的幾何約束,通過幾何變換,使用一側攝像機圖像(以下稱右圖)監督基于另一側攝像機圖像(以下稱左圖)預測的深度圖,從而減少對數據的依賴。但這類方法在測試過程中仍然缺乏顯式的幾何約束。為了解決上述問題,本文提出單視圖雙目匹配模型(Single View Stereo Matching, SVS),該模型把單目深度估計分解為兩個子過程,視圖合成過程和雙目匹配過程,其算法框架如圖1所示。
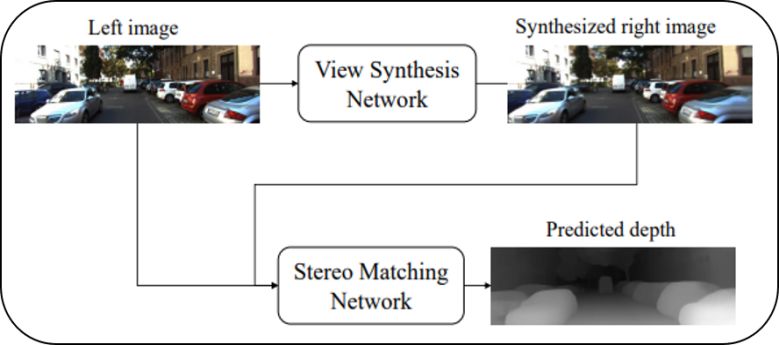
圖1:
單視圖雙目匹配模型的示意圖
通過這樣的分解,使得提出的模型有如下兩個優點:
極大地減少深度標注數據的依賴;
在測試階段顯式地引入幾何約束。
實驗證明,本文提出的模型僅用少量的深度標注數據就可以在KITTI數據集上超過之前的所有單目深度估計方法,并首次僅靠單目圖像數據就超過了雙目匹配算法Block Matching的深度估計精度。
SVS模型
現有基于深度學習的單目深度估計方法,通常把CNN作為黑盒使用,學習圖像塊至深度值的直接映射,這類方法完全依賴高級語義信息作為預測深度的依據,盡管有些方法在損失函數上引入一些特殊的約束條件,學習這樣的語義信息仍然是非常困難的。另一方面,即使這樣的映射能夠被成功訓練,算法通常也需要大量帶深度值標簽的真實數據,而這類數據的采集成本非常高且耗時,極大的限制了這類技術的適用場景。
基于上述分析,本文方法提出了一種新穎的面向單目深度估計的算法框架,把單目深度估計分解為兩個過程,即視圖合成過程和雙目匹配過程。模型的主要設計思路在于:
把雙目深度估計模型中有效的幾何約束顯式地結合到單目深度估計模型中,提高模型的可解釋性;
減少使用難以采集的真實深度數據,從而擴大模型的適用范圍;
整個模型以端到端的的方式訓練,從而提升深度估計準確性。
模型的視圖合成過程由視圖合成網絡完成,輸入一張左圖,網絡合成該圖像對應的右圖;而雙目匹配過程由雙目匹配網絡完成,接收左圖以及合成的右圖,預測出左圖每一個像素的視差值,詳細的網絡結構(如圖2所示)。
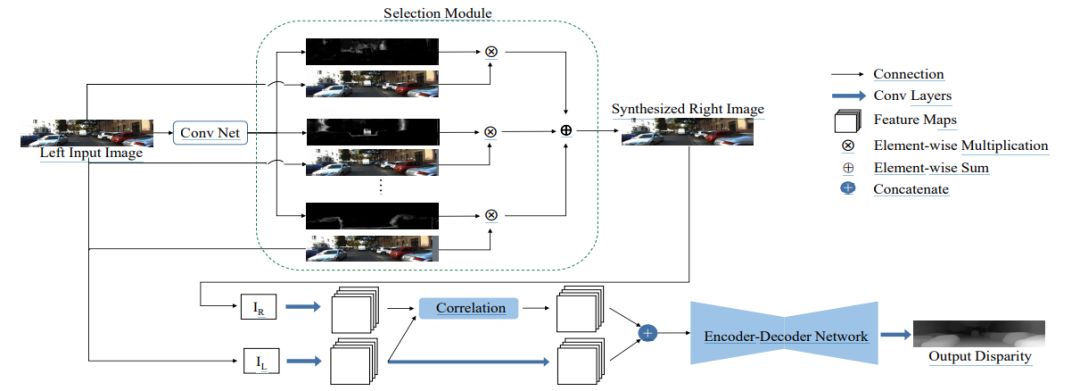
圖2:
算法網絡結構圖
上半部分網絡對應視圖合成網絡
下半部分網絡對應雙目匹配網絡
視圖合成網絡:
一般情況下,左圖中的像素均可以在右圖中找到匹配的像素,因此可以首先把左圖平移多個不同像素距離,得到多張不同的圖片,再使用神經網絡預測組合系數,把多張平移后的左圖和預測的系數組合得到預測的右圖。具體地,視圖合成網絡基于Deep3D [1] 模型,圖2 中的上半部分展示了視圖合成網絡的示意圖。輸入一張左圖,首先主干網絡對其提取不同尺度的特征,再經過上采樣層把不同尺度的特征統一至同一個尺寸,然后經過累加操作融合成輸出特征并預測出概率視差圖,最后經過選擇模塊(selection module)結合概率視差圖以及輸入的左圖,得到預測的右圖。本文采用L1 損失函數訓練這個網絡。
雙目匹配網絡:
雙目匹配需要把左圖像素和右圖中其對應像素進行匹配,再由匹配的像素差算出左圖像素對應的深度,而之前的單目深度估計方法均不能顯式引入類似的幾何約束。由于深度學習模型的引入,雙目匹配算法的性能近年來得到了極大的提升。本文的雙目匹配網絡基于DispNetC [2] 模型, 該模型目前在KITTI雙目匹配數據集上能夠達到理想的精度,其網絡如圖2的下半部分所示,左圖以及合成的右圖經過幾個卷積層之后,得到的特征會經過1D相關操作(correlation)。相關操作被證明在雙目匹配深度學習算法中起關鍵性的作用,基于相關操作,本文方法顯式地引入幾何約束;其得到的特征圖和左圖提取到的特征圖進行拼接作為編碼-解碼網絡(encoder-decoder network)的輸入,并最終預測視差圖。該網絡的訓練也同樣使用L1損失函數。
實驗結果
本文在KITTI公開數據集上對提出的模型進行驗證,遵循Eigen等人[3]的實驗設置,把697張圖片作為測試圖片,其余的數據作為訓練圖片,從定量和定性兩方面對所提出的模型進行驗證。
數值結果
表1總結了本文模型和其他現有方法結果的對比,可以看出,本文模型在大多數指標上均達到世界領先水平。其中,就ARD指標來說,提出的模型比之前最好的方法誤差減小16.8%(0.094 vs. 0.113);表中同時也顯示,經過端到端優化之后,SVS模型的性能能夠進一步得到提升。
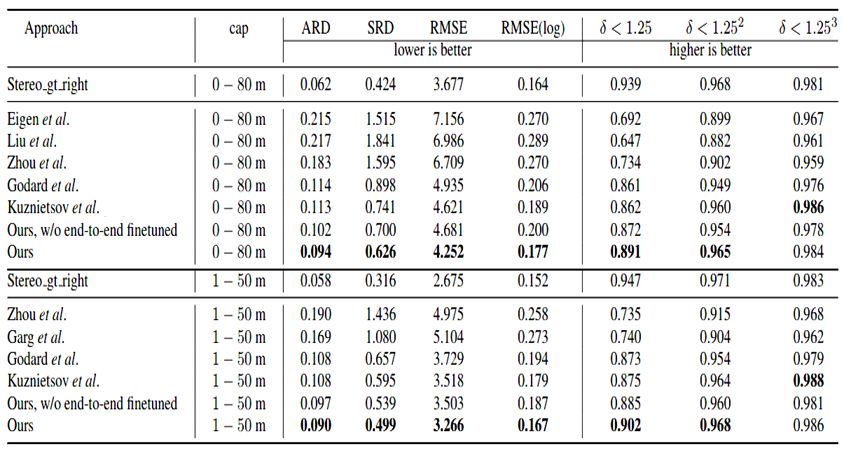
表1:
KITTI數據集上SVS模型和其他方法的數值結果
表中加粗表示性能最好的結果
可視化結果對比
圖3顯示了在KITTI Eigen測試集上的深度估計結果的可視化效果,從圖中可以看出本文提出的SVS模型能夠得到更加精準的深度圖。
圖3:
在KITTI Eigen測試集上的深度估計結果的可視化
提出的SVS模型能夠得到更加準確的深度圖
在其他數據集上結果的可視化
為了驗證SVS模型在其他數據集上的泛化能力,本文將在KITTI數據集上訓練好的SVS模型直接應用至Cityscape和 Make3D數據集上,結果可視化效果分別展示在圖4及圖5中。可以看到即使在訓練數據集中沒有出現過的場景,本文方法仍然可以得到合理準確的深度估計結果,證實了本文方法較為強大的泛化能力。
圖4:
在Cityscape數據集上深度估計結果的可視化
SVS模型能夠生成理想的深度圖
圖5:
在Make3D數據集上深度估計結果的可視化
本文提出的SVS模型可以得到較為準確的結果
與雙目匹配算法Block-Matching的對比:
為了進一步確認目前性能最優異的單目深度估計方法和雙目深度估計方法的差距,本文在KITTI 2015雙目匹配測試集上對比了SVS模型與現有最優性能的單目深度估計方法以及雙目匹配Block-Matching方法 (OCV-BM),相關結果總結在表2中,本文的SVS模型首次超越了雙目匹配Block-Matching算法。
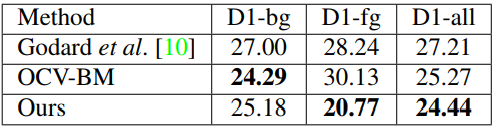
表2:
在KITTI 2015雙目匹配測試集上的數值結果
技術潛在應用
單目深度估計對比雙目深度估計具有方便部署、成本低等優點,在很多領域有著豐富的潛在應用場景,如三維重建、增強現實等。
a) 三維重建
b) 增強現實
結論
本文提出一種簡單而有效的單目深度估計模型——單視圖雙目匹配(SVS)。該模型通過把單目深度估計問題分解為兩個子問題,即視圖合成問題和雙目匹配問題,避免把神經網絡模型直接作為黑盒使用,提高了模型的可解釋性。同時,為了更好的解決這兩個子問題,顯式地把幾何變換編碼到兩個子網絡中,提升網絡模型的表達能力。實驗結果表明,該方法僅使用少量帶深度標簽的訓練數據,就能夠超越所有之前的單目深度估計方法,并且首次僅使用單目數據就超過雙目匹配算法Block-Matching的性能,在眾多領域中有著豐富的潛在應用。
-
圖像
+關注
關注
2文章
1091瀏覽量
40686 -
深度學習
+關注
關注
73文章
5527瀏覽量
121893 -
商湯科技
+關注
關注
8文章
527瀏覽量
36332
原文標題:CVPR 2018 | 商湯科技Spotlight論文詳解:單目深度估計技術
文章出處:【微信號:SenseTime2017,微信公眾號:商湯科技SenseTime】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
單目攝像頭和FPGA的ADAS產品原型系統
UC Berkeley大學的研究人員們利用深度姿態估計和深度學習技術
基于多孔卷積神經網絡的圖像深度估計模型



基于深度學習的二維人體姿態估計算法

密集單目SLAM的概率體積融合概述
一種用于自監督單目深度估計的輕量級CNN和Transformer架構
介紹第一個結合相對和絕對深度的多模態單目深度估計網絡
使用python和opencv實現單目攝像機測距

一種利用幾何信息的自監督單目深度估計框架
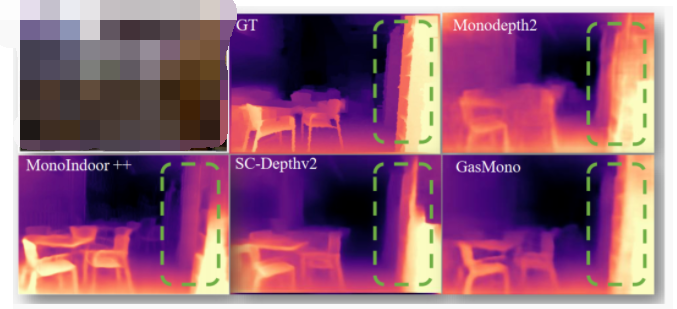
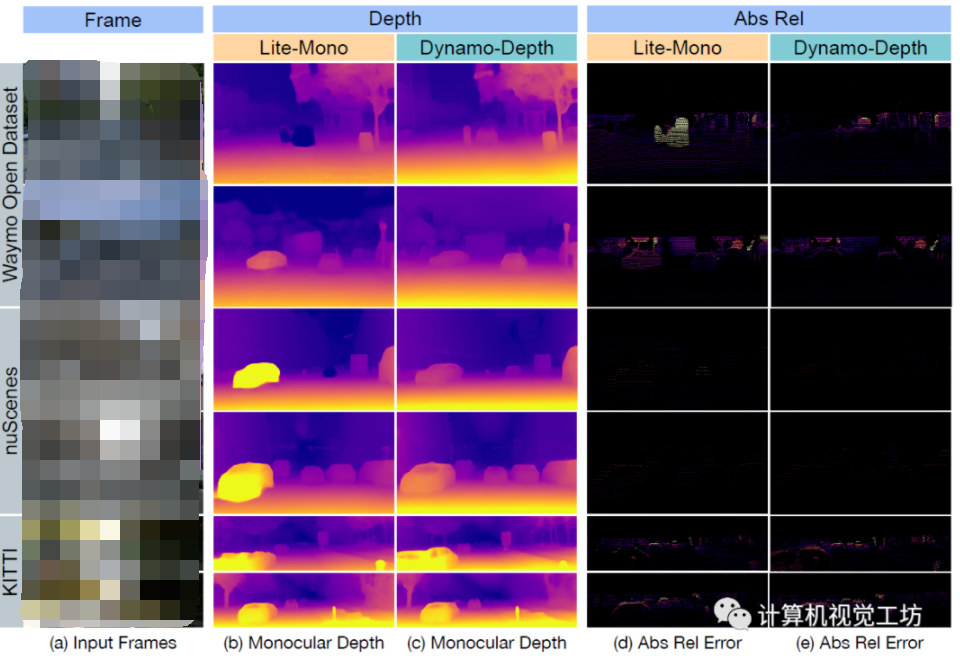
動態場景下的自監督單目深度估計方案






 工商網監
工商網監
評論