") UC Berkeley大學(xué)的研究人員們利用深度姿態(tài)估計(jì)和深度學(xué)習(xí)技術(shù)
UC Berkeley大學(xué)的研究人員們利用深度姿態(tài)估計(jì)和深度學(xué)習(xí)技術(shù)
UC Berkeley大學(xué)的研究人員們利用深度姿態(tài)估計(jì)和深度學(xué)習(xí)技術(shù),讓智能體從單一視頻中學(xué)習(xí)人物動(dòng)作,并生成近乎相同的結(jié)果。更重要的是,智能體還能將所學(xué)到的技能應(yīng)用于不同環(huán)境中。以下是論智對(duì)其博文的編譯。
不論是像洗手這樣日常的動(dòng)作,還是表演雜技,人類都可以通過(guò)觀察學(xué)習(xí)一系列技能。隨著網(wǎng)絡(luò)上越來(lái)越多視頻資源的出現(xiàn),想找到自己感興趣的視頻比之前更容易了。在YouTube,每分鐘都有300小時(shí)的視頻上傳成功。但是,對(duì)于機(jī)器來(lái)說(shuō),從如此大量的視覺(jué)數(shù)據(jù)中學(xué)習(xí)技能仍然困難。大多數(shù)動(dòng)作模仿的學(xué)習(xí)方法都需要有簡(jiǎn)潔地表示,例如從動(dòng)作捕捉獲取的記錄。但想得到動(dòng)作捕捉的數(shù)據(jù)可能也非常麻煩,需要大量設(shè)備。另外,動(dòng)作捕捉系統(tǒng)也僅限于遮擋較少的室內(nèi)環(huán)境,所以有很多無(wú)法記錄的動(dòng)作技能。那么,如果智能體可以通過(guò)觀看視頻片段來(lái)學(xué)習(xí)技能,不是很好嗎?
在這一項(xiàng)目中,我們提出了一種可以從視頻中學(xué)習(xí)技能的框架,通過(guò)結(jié)合計(jì)算機(jī)視覺(jué)和強(qiáng)化學(xué)習(xí)中出現(xiàn)的先進(jìn)技術(shù),該框架能讓智能體學(xué)會(huì)視頻中出現(xiàn)的全部技能。例如給定一段單目視頻,其中一個(gè)人在做側(cè)手翻或后空翻,該系統(tǒng)的智能體就可以學(xué)習(xí)這些動(dòng)作,并重現(xiàn)出一樣的行為,無(wú)需人類對(duì)動(dòng)作進(jìn)行標(biāo)注。
從視頻中學(xué)習(xí)身體動(dòng)作的技能最近得到很多人的關(guān)注,此前的技術(shù)大多依靠人們手動(dòng)調(diào)整框架結(jié)構(gòu),對(duì)生成的行為有很多限制。所以,這些方法也僅在有限的幾種情境下使用,生成的動(dòng)作看起來(lái)也不太自然。最近,深度學(xué)習(xí)在視覺(jué)模擬領(lǐng)域表現(xiàn)出了良好的前景,例如能玩雅達(dá)利游戲,機(jī)器人任務(wù)
框架
我們提出的框架包含三個(gè)階段:姿態(tài)估計(jì)、動(dòng)作重建和動(dòng)作模擬。在第一階段,框架首先對(duì)輸入的視頻進(jìn)行處理,在每一幀預(yù)測(cè)人物動(dòng)作。第二步,動(dòng)作重建階段會(huì)將預(yù)測(cè)出的動(dòng)作合并成參考動(dòng)作,并對(duì)動(dòng)作預(yù)測(cè)生成的人工痕跡做出修正。最后,參考動(dòng)作被傳遞到動(dòng)作模擬階段,其中的模擬人物經(jīng)過(guò)訓(xùn)練,可以用強(qiáng)化學(xué)習(xí)模仿動(dòng)作。
動(dòng)作估計(jì)
給定一段視頻,我們用基于視覺(jué)的動(dòng)作估計(jì)器預(yù)測(cè)每一幀演員的動(dòng)作qt。該動(dòng)作預(yù)測(cè)器是建立在人類網(wǎng)格復(fù)原這一工作之上的(akanazawa.github.io/hmr/),它用弱監(jiān)督對(duì)抗的方法訓(xùn)練動(dòng)作估計(jì)器,從單目圖像中預(yù)測(cè)動(dòng)作。雖然在訓(xùn)練該估計(jì)器的時(shí)候需要標(biāo)注動(dòng)作,不過(guò)一旦訓(xùn)練完成,估計(jì)器在應(yīng)用到新圖片上時(shí)就無(wú)需再次訓(xùn)練了。
用于估計(jì)人物動(dòng)作的姿態(tài)估計(jì)器
動(dòng)作重建
姿態(tài)估計(jì)給視頻中的每一幀都做出了單獨(dú)的動(dòng)作預(yù)測(cè),但兩幀之間的預(yù)測(cè)可能會(huì)出現(xiàn)抖動(dòng)偽影。另外,雖然近些年基于是覺(jué)得姿態(tài)估計(jì)器得到了很大進(jìn)步,但有時(shí)它們也可能會(huì)出現(xiàn)較大失誤。所以,這一步的動(dòng)作重建就是減少出現(xiàn)的偽影,從而生成更逼真的參考動(dòng)作,能讓智能體更輕易地模擬。為了實(shí)現(xiàn)這一點(diǎn),我們對(duì)參考動(dòng)作進(jìn)行了優(yōu)化Q={q0,q1,…,qt},以滿足以下目標(biāo):
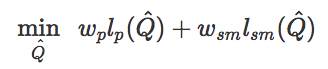
其中l(wèi)p(Q^)是為了讓參考動(dòng)作和原始動(dòng)作預(yù)測(cè)更接近,lsm(Q^)是為了讓相鄰的幀之間的動(dòng)作更相近,從而生成更流暢的動(dòng)作。另外,wp和wsm是不同損失的權(quán)重。
這一過(guò)程可以顯著提高參考動(dòng)作的質(zhì)量,并且修正一些人工生成的痕跡。
動(dòng)作模擬
有了參考動(dòng)作{q^0,q^1,…,q^t}之后,我們就可以訓(xùn)練智能體模仿這些動(dòng)作了。這一階段用到的強(qiáng)化學(xué)習(xí)方法和之前我們?yōu)槟M動(dòng)作捕捉數(shù)據(jù)而提出的方法相似,獎(jiǎng)勵(lì)函數(shù)僅僅是為了讓智能體的動(dòng)作和重建后的參考動(dòng)作之間的差異最小化。
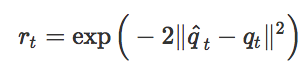
這一方法表現(xiàn)得很好,我們的智能體可以學(xué)習(xí)很多雜技動(dòng)作,每個(gè)動(dòng)作只需要一段視頻就能學(xué)會(huì)。
結(jié)果
最終我們的智能體從YouTube上的視頻中學(xué)習(xí)了20多種不同的技能。
盡管智能體的形態(tài)有時(shí)和視頻中的人物不太一樣,但這一框架仍然能逼真地重現(xiàn)很多動(dòng)作。除此之外,研究人員還用模擬的Atlas機(jī)器人模仿視頻動(dòng)作。
使用模擬人物(智能體)的好處之一就是,在新環(huán)境下可以用模擬對(duì)象生成相應(yīng)的動(dòng)作。這里,我們訓(xùn)練智能體在不規(guī)則平面上采取不同動(dòng)作,而它所對(duì)應(yīng)的原始視頻是在平地上運(yùn)動(dòng)的。
雖然和原始視頻中的環(huán)境大不相同,學(xué)習(xí)算法仍然能生成相對(duì)可靠的策略來(lái)應(yīng)對(duì)不同路面情況。
總的來(lái)說(shuō),我們的框架采用的都是視頻模仿問(wèn)題中常見(jiàn)的方法,關(guān)鍵是要將問(wèn)題分解成更加易處理的組合部分,針對(duì)每個(gè)部分采取正確的方法,然后高效地把它們組合在一起。但是模擬視頻中的動(dòng)作仍然是非常有挑戰(zhàn)性的工作,目前還有很多我們無(wú)法復(fù)現(xiàn)的視頻片段:
這種江南style的舞步,智能體就難以模仿
但是看到目前我們實(shí)現(xiàn)的成果,還是很振奮人心。未來(lái)我們還有很多需要改進(jìn)的地方,希望這項(xiàng)工作能作為基礎(chǔ),為智能體在未來(lái)處理大量視頻數(shù)據(jù)的能力奠定了基礎(chǔ)。
-
計(jì)算機(jī)視覺(jué)
+關(guān)注
關(guān)注
8文章
1698瀏覽量
46032 -
智能體
+關(guān)注
關(guān)注
1文章
157瀏覽量
10596 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5507瀏覽量
121292
原文標(biāo)題:僅需一段視頻,伯克利研究者就讓智能體學(xué)會(huì)了雜技
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
2017全國(guó)深度學(xué)習(xí)技術(shù)應(yīng)用大會(huì)
基于深度學(xué)習(xí)的異常檢測(cè)的研究方法
基于深度學(xué)習(xí)的異常檢測(cè)的研究方法
討論紋理分析在圖像分類中的重要性及其在深度學(xué)習(xí)中使用紋理分析
研究人員們提出了一系列新的點(diǎn)云處理模塊

谷歌發(fā)明自主學(xué)習(xí)機(jī)器人 結(jié)合了深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)兩種類型的技術(shù)
研究人員推出了一種新的基于深度學(xué)習(xí)的策略
研究人員開(kāi)發(fā)了一種基于深度學(xué)習(xí)的智能算法
(KAIST)研究人員提供了一種深度學(xué)習(xí)供電的單應(yīng)變電子皮膚傳感器
研究人員開(kāi)發(fā)出深度學(xué)習(xí)算法用于患者的診斷
基于深度學(xué)習(xí)的二維人體姿態(tài)估計(jì)方法

基于深度學(xué)習(xí)的二維人體姿態(tài)估計(jì)算法

研究人員提出將深度學(xué)習(xí)技術(shù)引入細(xì)胞成像和分析中
AI深度相機(jī)-人體姿態(tài)估計(jì)應(yīng)用

深度解析深度學(xué)習(xí)下的語(yǔ)義SLAM






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論