") LLM推理任務(wù)中GPU的選擇策略
LLM推理任務(wù)中GPU的選擇策略
去年十月,美商務(wù)部禁令的出現(xiàn),使中國客戶無法使用NVIDIA H100/H200旗艦芯片。一時間,各種NV存貨、中國限定卡型、其他廠商NPU紛至沓來。在大模型推理場景中,如何客觀比較不同硬件的能力,成為一大難題,比如:
Q1:輸入輸出都很長,應(yīng)該選H20還是A800?
Q2:高并發(fā)情況下,用L20還是RTX 4090?
最直接的解決方法是,使用SOTA推理服務(wù)框架,對不同硬件X不同負(fù)載做全面的評估。但是,大模型任務(wù)推理的負(fù)載變化范圍很大,導(dǎo)致全面評估耗時耗力。主要來源以下幾個方面:
輸入參數(shù)batch size、input sequence length、output sequence length變化多樣。
大模型種類很多,從7B到170B,不同尺寸模型都有。
硬件種類很多。參考許欣然的文章,備選的NVIDIA GPU就有15種,而且還有其他廠商的硬件。
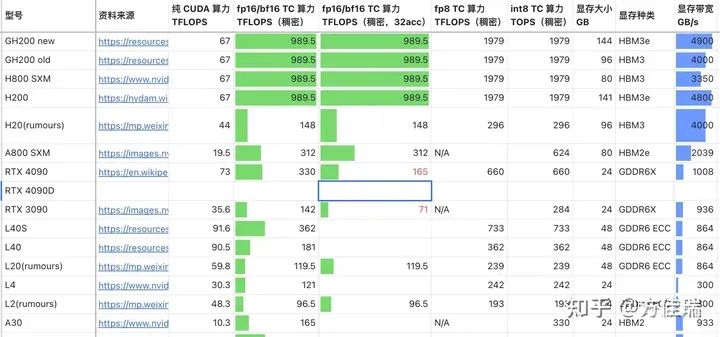
如何在繁重的benchmark任務(wù)前,對不同硬件在不同推理任務(wù)上的表現(xiàn)有一個直觀的認(rèn)識?為此,我做了一個簡單的性能評估工具LLMRoofline,它使用Roofline模型,不需要運(yùn)行程序,來簡單比較不同硬件。
Roofline模型
Roofline模型是一種非常簡化的性能模型,但可以清晰地展示出應(yīng)用程序的硬件性能極限。
在Roofline模型可以直觀展示一張曲線圖,其中x軸表示AI(Arithmetic Intensity),即每個內(nèi)存操作對應(yīng)的浮點(diǎn)運(yùn)算次數(shù);y軸表示性能,通常以每秒浮點(diǎn)運(yùn)算次數(shù)(Tflops)表示。圖中的“屋頂”(Roofline)由兩部分組成:一部分是峰值內(nèi)存帶寬(Memory Bandwidth)限制的斜線,另一部分是峰值計(jì)算性能(Peak Performance)限制的水平線。這兩部分相交的點(diǎn)是應(yīng)用程序從內(nèi)存帶寬受限轉(zhuǎn)變?yōu)?strong>計(jì)算性能受限的轉(zhuǎn)折點(diǎn)。
下圖繪制了多個不同GPU(包括NVIDIA的A100、H20、A800、L40S、L20和4090)的Roofline模型。如果一個硬件的屋頂Roof越高,那么它在處理計(jì)算密集型任務(wù)時的性能更好;如果屋頂?shù)腖ine斜率越高,表示它的HBM帶寬越高,處理訪存密集型任務(wù)時,性能越好。
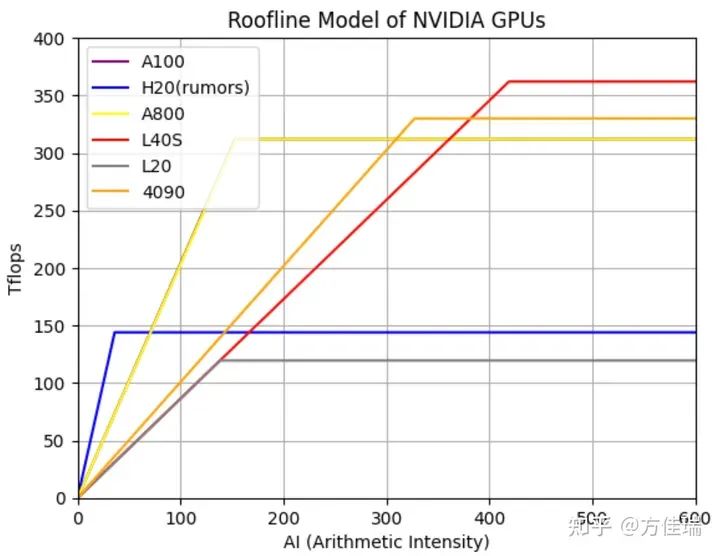
圖1,不同GPU的Roofline模型
LLM推理性能模型
方法一:全局Roofline模型
基于Roofline模型,可以計(jì)算出不同LLM模型推理任務(wù)的AI。我們用Decode階段的AI來代表整體推理階段的AI,因?yàn)镻refill階段,是計(jì)算密集的,且在一次推理任務(wù)中只算一次,時間占比很小。因?yàn)長LM的Transformers layer數(shù)比較大,所以只考慮Transformers的計(jì)算和訪存,忽略包括Embedding在內(nèi)的前后處理開銷。
AI = 總計(jì)算量FLOPS/(總參數(shù)大小+總KVCache大小)
為了簡化,沒考慮中間activation的內(nèi)存讀取,因?yàn)樗恼急韧ǔ:苄。铱梢员籉lashAttention之類的Kernel Fusion方法優(yōu)化掉。
總計(jì)算量和參數(shù)量可以參考如下文章,文章中的數(shù)據(jù)還是針對GPT2的,這里在LLAMA2模型下進(jìn)行一些修改,主要包括取消intermediate_size=4*hidden_size限制,并考慮GQA和MoE等模型結(jié)構(gòu)的優(yōu)化。
這里約定,bs(batch size),in_len(輸入序列長度,Decoder階段一直是1),kv_len(KVCache長度),h(hidden_size),i(intermediate_size)。
總計(jì)算量
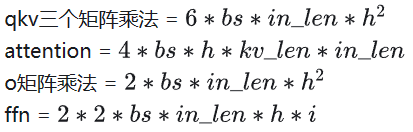
總參數(shù)量
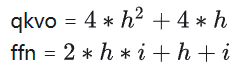
KVCache參數(shù)量
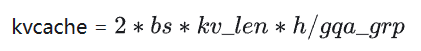
如果使用MoE結(jié)構(gòu),我們計(jì)算參數(shù)時對ffn 乘以 #Expert,計(jì)算量對ffn乘以topk。
有了任務(wù)的AI,可以在圖1中,min(peak_flops, ai * bandwidth)查找對應(yīng)位置的Tflops性能,從而比較兩個硬件上該任務(wù)的性能優(yōu)劣。
使用多卡Tensor Parallel并行,分子分母都近似除以GPU數(shù)目,因此AI幾乎不變。使用FP8會增加Roof高度,但是Line的斜率不變。
方法二:算子Roofline模型
上述方法還是將整個Transformers看成整體算出AI,還可以對Decoder中每一個算子算出它的AI,然后使用Roofline模型計(jì)算該算子的延遲。計(jì)算算子的AI可以考慮Activation的讀寫開銷,相比方法一訪存計(jì)算會更加精確。
我找到了一個現(xiàn)成的項(xiàng)目LLM-Viewer做了上述計(jì)算,該項(xiàng)目也是剛發(fā)布不久。
https://github.com/hahnyuan/LLM-Viewergithub.com/hahnyuan/LLM-Viewer
值得注意的是,目前無論方法一還是方法二都無法精確估計(jì)運(yùn)行的延遲。比如,我們用LLM-Viewer估計(jì)A100的延遲,并和TensorRT-LLM的數(shù)據(jù)對比,可見最后兩列差距還是比較大的。因?yàn)镽oofline模型只能估計(jì)性能上限,并不是實(shí)際的性能。
| Model | Batch Size | Input Length | Output Length |
TRT-LLM Throughput (token/sec) |
LLM-Viewer Throughput (token/sec) |
| LLaMA 7B | 256 | 128 | 128 | 5,353 | 8,934 |
| LLaMA 7B | 32 | 128 | 2048 | 1,518 | 2,796 |
| LLaMA 7B | 32 | 2048 | 128 | 547 | 788 |
| LLaMA 7B | 16 | 2048 | 2048 | 613 | 1,169 |
但是,應(yīng)該可以基于LLM-Viewer的數(shù)據(jù)進(jìn)行一些擬合來精確估計(jì)不同GPU的性能,不過據(jù)我了解還沒有對LLM做精確Performance Model的工作。
效果
LLMRoofline可以使用上述兩種方式比較不同硬件的性能。它會畫出一個Mesh,橫軸時序列長度(可以看成生成任務(wù)的平均KVCache length),縱軸時Batch Size。
比如,我們比較NVIDIA H20 rumors和A100在推理任務(wù)上的差異。這兩款芯片一個帶寬很高4TBps vs 2 TBps,一個峰值性能高 312 Tflops vs 148 Flops。
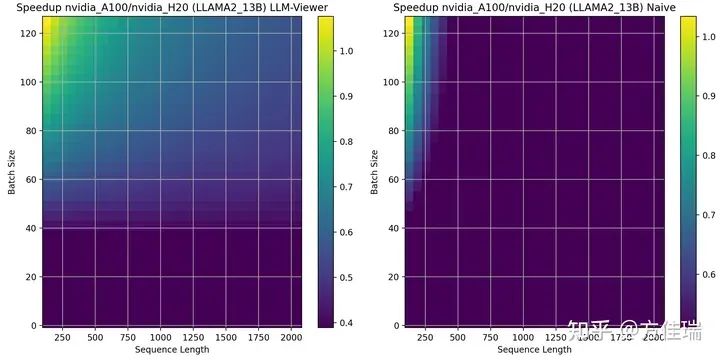
使用LLAMA2 13B時,左圖是方法二、右圖是方法一的A100/H20的比較結(jié)果,大于1表示有優(yōu)勢。兩張圖有差異,但是分布近似。A100比H20的優(yōu)勢區(qū)域在網(wǎng)格的左上角。當(dāng)序列長度越短、Batch Size越大,A100相比H20越有優(yōu)勢。這是因?yàn)椋藭r任務(wù)更偏計(jì)算密集型的,A100的峰值性能相比H20更具優(yōu)勢。
借助性能模型,我們可以澄清一些誤解。例如,有人可能會認(rèn)為在H20上增大Batch Size會使任務(wù)變得更加計(jì)算密集,且由于H20的計(jì)算能力非常低,因此增大Batch Size是無效的。這里忽略了序列長度對AI的影響,對于處理長序列的任務(wù)來說,任務(wù)一直是訪存密集的,增大Batch Size仍然是一種有效的優(yōu)化策略。
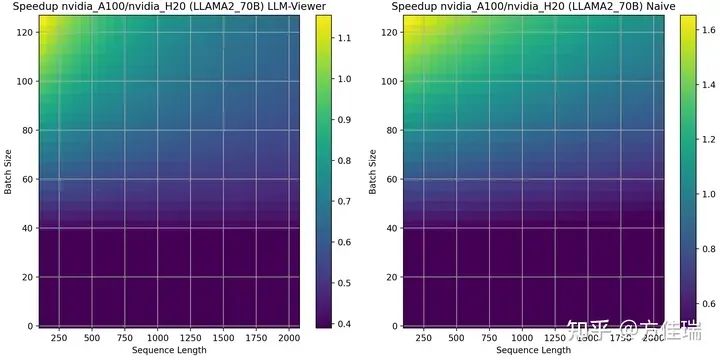
當(dāng)使用LLAMA2 70B時,A100相比H20優(yōu)勢區(qū)域擴(kuò)大。這是因?yàn)長LAMA2 13B沒有用GQA,但LLAMA2 70B用了GQA,這讓推理任務(wù)更偏計(jì)算密集,對A100更有利。
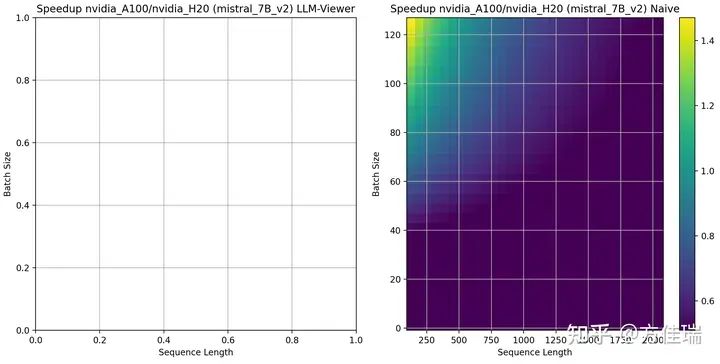
當(dāng)使用Mistral 7B時,LLM-Viewer目前還沒有登記模型信息,我們只有方法一的結(jié)果,A100相比H20的優(yōu)勢區(qū)域相比13B縮小。這說明hidden size越大,越偏計(jì)算密集。
Mixtral 8X7B時,可見A100相比H20一致保持劣勢,說明MoE把推理任務(wù)推向訪存密集的深淵,H20的帶寬優(yōu)勢發(fā)揮明顯作用。
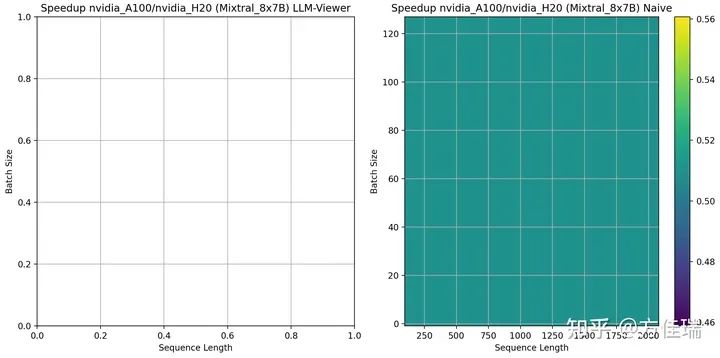
通過使用 LLMRoofline,我們能夠制作出許多兩個硬件比較的 Mesh,從而清晰地觀察到一些類似上述的簡單結(jié)論。
總結(jié)
大模型推理任務(wù)的復(fù)雜性和多變性使得對不同型號GPU的適用范圍的理解變得尤為重要。為了幫助大家直觀地感知這些差異,本文介紹了一款名為LLMRoofline的性能分析工具。該工具采用Roofline模型,能夠直觀地對比不同硬件的性能和適用范圍。具體而言,影響硬件選擇的因素包括任務(wù)的序列長度、批處理大小(Batch Size),以及是否使用了MoE/GQA等優(yōu)化技巧,它們相互作用可以在LLMRoofline中得到體現(xiàn)。
審核編輯:黃飛
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5010瀏覽量
103238 -
gpu
+關(guān)注
關(guān)注
28文章
4752瀏覽量
129041 -
LLM
+關(guān)注
關(guān)注
0文章
292瀏覽量
351
原文標(biāo)題:如何為LLM推理任務(wù)選擇正確的GPU
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
對比解碼在LLM上的應(yīng)用
【飛凌嵌入式OK3576-C開發(fā)板體驗(yàn)】rkllm板端推理
充分利用Arm NN進(jìn)行GPU推理
如何利用LLM做多模態(tài)任務(wù)?
LLM在各種情感分析任務(wù)中的表現(xiàn)如何

基準(zhǔn)數(shù)據(jù)集(CORR2CAUSE)如何測試大語言模型(LLM)的純因果推理能力
適用于各種NLP任務(wù)的開源LLM的finetune教程~

人工智能中的處理器如何選擇

mlc-llm對大模型推理的流程及優(yōu)化方案
Hugging Face LLM部署大語言模型到亞馬遜云科技Amazon SageMaker推理示例

怎樣使用Accelerate庫在多GPU上進(jìn)行LLM推理呢?
如何利用OpenVINO加速LangChain中LLM任務(wù)
自然語言處理應(yīng)用LLM推理優(yōu)化綜述

LLM大模型推理加速的關(guān)鍵技術(shù)
基于Arm平臺的服務(wù)器CPU在LLM推理方面的能力





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論