 MAE再發力,跨模態交互式自編碼器PiMAE席卷3D目標檢測領域
MAE再發力,跨模態交互式自編碼器PiMAE席卷3D目標檢測領域
本文提出了一種基于MAE的跨模態交互式自編碼器PiMAE,PiMAE同時具有強大的3D點云和RGB圖像特征提取能力。作者通過三個方面的獨特設計來促進多模態學習過程中的交互效果。并對提出的PiMAE進行了廣泛的實驗,該框架在多個下游任務上都展示出了非常出色的性能提升效果,這也側面表明MAE模式在基礎視覺感知任務上仍然不過時,具有進一步研究的價值。

論文鏈接: https://arxiv.org/abs/2303.08129 代碼鏈接: https://github.com/BLVLab/PiMAE
從2021年kaiming大佬首次提出MAE(Masked Autoencoders)以來,計算機視覺社區已經出現了很多基于MAE的工作,例如將MAE建模拓展到視頻序列中,或者直接對MAE原始結構進行改進,將MAE嵌入到層次的Transformer結構中等等。截止到現在,MAE原文在谷歌學術的引用量已經達到1613。

MAE以其簡單的實現方式、強大的視覺表示能力,可以在很多基礎視覺任務中展現出良好的性能。但是目前的工作大多是在單一視覺模態中進行,那MAE在多模態數據融合方面表現如何呢?本文為大家介紹一項剛剛被視覺頂會CVPR2023接收的工作,在這項工作中,作者重點探索了點云數據和RGB圖像數據,并且提出了一種基于MAE的自監督擴模態協同感知框架PiMAE。具體來說,PiMAE可以從三個方面來提升模型對3D點云和2D圖像數據的交互性能:
1. PiMAE設計了一個多模態映射模塊來對兩個不同模態的masked和可見的tokens進行對齊,這一設計強調了mask策略在兩個不同模態中的重要性。
2. 隨后,作者為PiMAE設計了兩個MAE支路和一個共享的解碼器來實現masked tokens之間的跨模態交互。
3. 最后PiMAE通過一個新型的跨模態重建模塊來進一步提升兩個模態的表征學習效果。
作者在兩個大規模多模態RGB-D場景理解基準(SUN RGB-D和ScannetV2)上對PiMAE進行了大量評估,PiMAE在3D目標檢測、2D目標檢測以及小樣本圖像分類任務上都展現出了優越的性能。
一、介紹
深度學習技術目前已經成為很多自動化裝備的基礎感知手段,例如工業機器人和自動駕駛。在這些實際場景中,機器可以通過攝像頭和眾多傳感器獲得大量的3D或2D點云數據以及RGB圖像數據。由于成對的2D像素和3D點云可以更全面的呈現同一場景的不同視角,將這些多模態信息高效的結合起來可以提高模型決策的準確性。在本文中,作者旨在探索這樣一個問題:如何設計一個高效的多模態(3D點云和RGB模態)無監督交互學習框架,來實現更好的表征學習?為此,作者選用kaiming提出的MAE作為基礎架構,MAE可以通過一種簡單的自監督任務實現一個強大的ViT預訓練框架。但是MAE在多種模態交互的情況下表現如何,仍然是未知的。
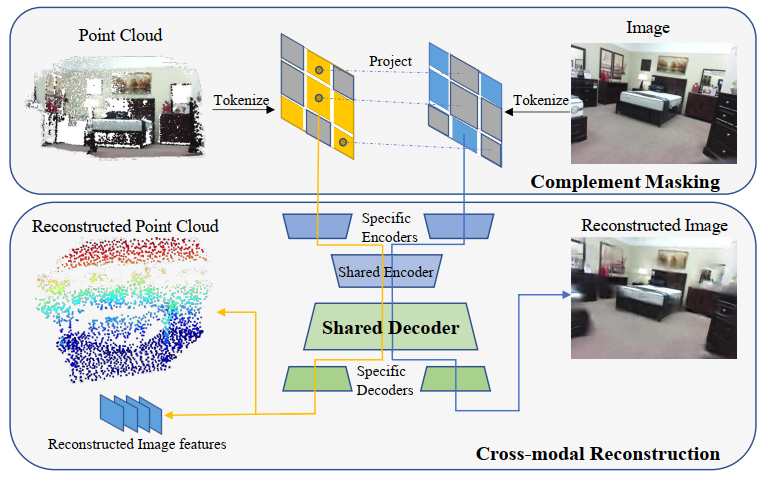
為了探索多模態3D點云和RGB圖像數據交互融合性能,本文提出了PiMAE,這是一種簡單而有效的多模態MAE框架,PiMAE可以通過交互機制來學習更魯棒的3D和2D特征。PiMAE的整體框架如上圖所示,具體來說,PiMAE將成對的3D點云和圖像數據作為輸入,并對兩種輸入做一種互補的mask操作。然后對其進行編碼得到tokens,將3D點云token投影到RGB圖像塊中,明確對齊兩種模態之間的Mask關系。作者認為通過這種mask策略可以幫助點云token從圖像嵌入中獲得互補信息,反之亦然。隨后作者設計了一種對稱的自動編碼器結構來進行模態特征融合,自編碼器由模態特定編碼器(Specific Encoders)的獨立分支和共享編解碼器構成,PiMAE通過多模態重構任務(即點云重構和圖像重構)來完成兩種模態的交互和表征學習。
二、方法介紹
給定3D點云和RGB多模態數據后,PiMAE通過一種聯合嵌入的方式來學習跨模態特征。在具體操作中,作者首先對點云數據進行采樣并執行聚類算法將點云數據嵌入到token中,然后對點云token進行隨機mask。mask后的token隨后被轉換到2D平面中,同時RGB圖像塊以互補mask的形式也嵌入到RGB token中。隨后兩個模態的token數據通過PiMAE的聯合編解碼器進行特征建模和融合。
PiMAE中的編碼器-解碼器架構同時整合了模態獨立分支和模態共享分支,其中前者用來保持模型對特定模態的學習,后者鼓勵模型通過跨模態的特征交互來實現模態之間的高效對齊。
2.1 token投影和對齊
在對點云和RGB圖像進行處理時,作者遵循MAE和Point-M2AE[1]中的做法,對于RGB圖像,作者將圖像先分成不重疊的圖像塊,并且為每個塊添加位置編碼嵌入和模態嵌入,隨后將他們送入到投影層。對于點云數據,先通過最遠點采樣(Farthest Point Sampling,FPS)和KNN算法提取聚類中心token,然后同樣為每個中心token添加編碼嵌入和模態嵌入,并送入到線性投影層。
2.1.1 投影
為了實現多模態token之間的對齊,作者通過將點云token投影到相機的2D圖像平面上來建立 3D點云和RGB圖像像素之間的嵌入聯系。對于3D點云 ,可以使用下面定義的投影函數?Proj?計算出相應的2D坐標:
,可以使用下面定義的投影函數?Proj?計算出相應的2D坐標:
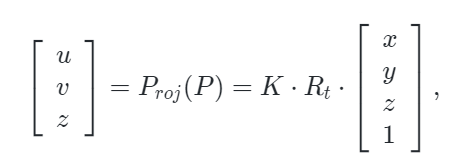
其中 K∈3×4,Rt∈4×4是相機的內在和外置參數矩陣。(x,y,z),(u,v)是點 P 的原始3D坐標和投影得到的2D坐標。
2.1.2 Mask對齊方式
由于點云token是由一系列聚類中心構成,作者隨機從中選擇一部分中心點作為采樣區域。對于可見點云標記Tp,將它們的中心點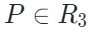 投影到相應的2D相機平面并獲得其2D坐標?
投影到相應的2D相機平面并獲得其2D坐標?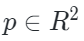 ?它可以自然地落入形狀為?H×W(即圖像形狀)的區域內,可以通過以下方式來獲得其相對應圖像塊的索引
?它可以自然地落入形狀為?H×W(即圖像形狀)的區域內,可以通過以下方式來獲得其相對應圖像塊的索引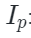
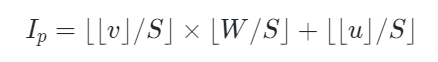
其中 u 和 v表示二維坐標 p 的 x 軸值和 y 軸值,S 是圖像塊大小。
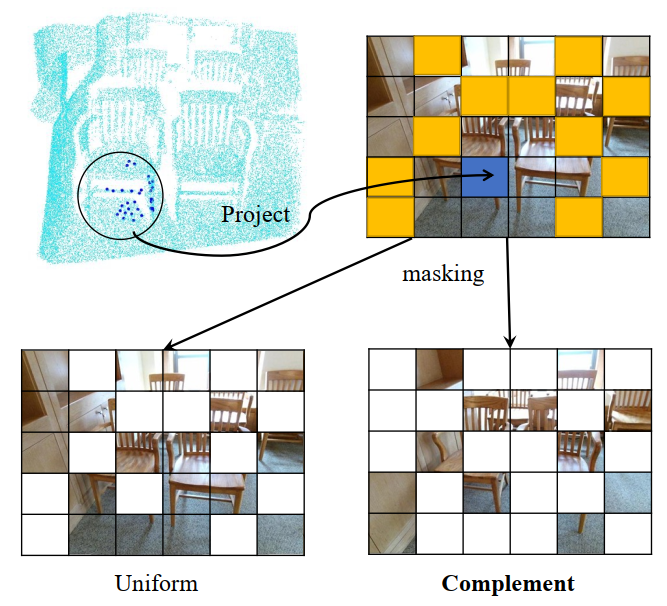
在對每個可見點云token進行投影和索引后,就可以獲得它們對應的圖像塊,如上圖所示。隨后作者使用了一種顯示的mask策略來實現token對齊,具體來說,一個隨機采樣的點云區域(上圖黑色圓圈處)被投影到圖像塊(藍色方塊)上,其他點云區域以類似的方式進行采樣和投影(黃色方塊),來構成正向Mask模式(Uniform)。相反,上圖右下區域是相應的互補Mask模式(Complement)。
2.2 編碼器和解碼器
2.2.1 編碼器
PiMAE的編碼器遵循AIST++[2]的設計,由兩個模塊構成:模態特定編碼器和跨模態編碼器。前者用于更好地提取特定于當前模態的特征,后者用于進行跨模態特征之間的交互。在這一過程中,編碼器側重于保持不同模態特征的完整性,可以形式化表示為:
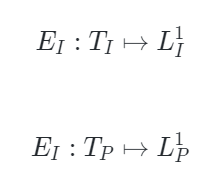
其中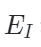 和?
和?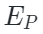 是特定于圖像和特定于點云的編碼器,
是特定于圖像和特定于點云的編碼器,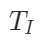 ?和?
?和?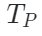 ?是可見圖像和點云token,
?是可見圖像和點云token,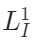 ?和?
?和?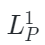 是圖像和點云相應的嵌入空間。
是圖像和點云相應的嵌入空間。
2.2.2 解碼器
原始MAE框架中的解碼器是建立在一個具有統一表征能力的編碼基礎之上,但是本文的設定是編碼器同時捕獲圖像和點云數據的特征表示。由于兩種模態之間的差異,需要使用專門的解碼器將這些特征解碼為各自的模態。形式上,作者將PiMAE的共享解碼器的輸入表示為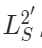 ,其中包括編碼的可見特征和兩種模態的mask tokens。隨后共享解碼器會對這些特征
,其中包括編碼的可見特征和兩種模態的mask tokens。隨后共享解碼器會對這些特征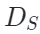 執行跨模態交互:
執行跨模態交互: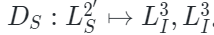 。然后,在單獨模態的解碼器階段,解碼器將特征重構回原始圖像和點云空間?
。然后,在單獨模態的解碼器階段,解碼器將特征重構回原始圖像和點云空間?
。其中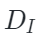 ?和
?和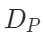 ?是圖像特定和點云特定解碼器,
?是圖像特定和點云特定解碼器,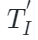 ?和?
?和?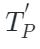
是可見圖像和點云區域,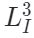 ??和?
??和?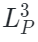 是圖像和點云嵌入空間,重構過程的損失函數如下:
是圖像和點云嵌入空間,重構過程的損失函數如下:
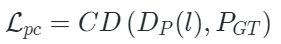
其中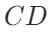 ?是
?是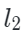 Chamfer Distance函數(倒角距離),
Chamfer Distance函數(倒角距離),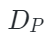 表示解碼器重構函數,
表示解碼器重構函數,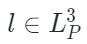 ?是點云嵌入表示,
?是點云嵌入表示,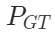 ?是點云ground-truth(即點云輸入)。
?是點云ground-truth(即點云輸入)。
2.3 跨模態重構
本文使用三種不同的損失聯合訓練PiMAE:點云重建損失、圖像重建損失和跨模式重建損失。在最后的重建階段,作者利用先前對齊的關系來獲得mask點云區域相應的二維坐標。然后,對重建的圖像特征進行上采樣,這樣每個具有2D坐標的mask點云都可以與重建的圖像特征相關聯。最后,mask點云token通過一個跨模態預測頭來恢復相應的可見圖像特征。形式上,跨模式重建損失定義為:
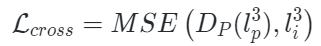
其中 ?表示均方誤差損失函數,
?表示均方誤差損失函數,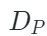 ?是解碼器的跨模態重建函數,
?是解碼器的跨模態重建函數,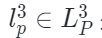 是點云表示,
是點云表示,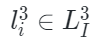 ?是圖像表示。PiMAE通過聯合以上損失來進行訓練,通過這樣的設計,PiMAE可以分別學習3D和2D特征,同時保持兩種模態之間的強交互性。
?是圖像表示。PiMAE通過聯合以上損失來進行訓練,通過這樣的設計,PiMAE可以分別學習3D和2D特征,同時保持兩種模態之間的強交互性。
三、實驗效果
本文的實驗在兩個大規模多模態RGB-D場景理解基準(SUN RGB-D和ScannetV2)上進行,作者先在SUN RGB-D訓練集對PiMAE進行預訓練,并在多個下游任務上對PiMAE進行評估,包括3D目標檢測、3D單目目標檢測、2D目標檢測和小樣本圖像分類。
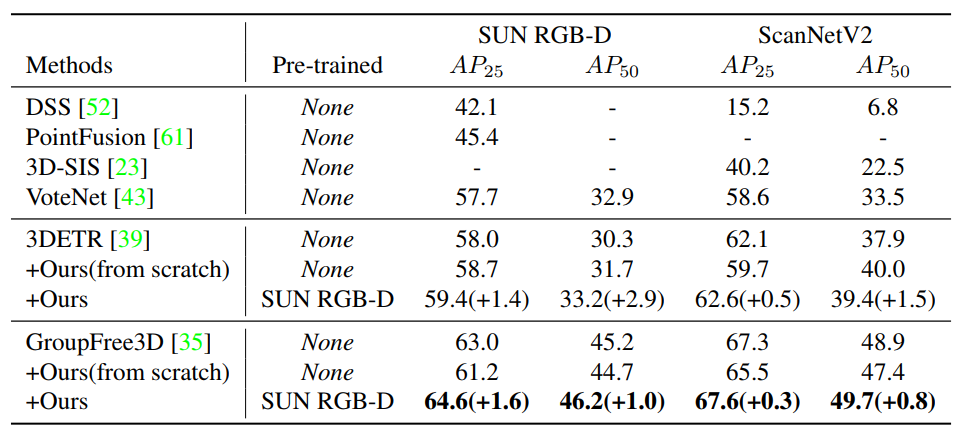
3.1 室內3D目標檢測
對于室內的3D目標檢測任務,作者將PiMAE的3D特征編碼器加入到不同的backbone網絡中來提高特征提取的能力,從而實現3D目標檢測的能力。作者以兩個SOTA模型3DETR和GroupFree3D來作為baseline模型,如下表所示,本文的PiMAE為兩個模型都帶來了顯著的性能提升,在所有數據集上都超過了之前的基線方法。
3.2 室外單目3D目標檢測
除了室內環境,作者也展示了更具挑戰性的室外場景效果。與室內預訓練數據相比,室外場景的數據具有很大的數據分布差距。如下圖所示,本文方法對MonoDETR方法實現了實質性的改進,這證明,PiMAE預訓練對室內和室外場景都具有很強的泛化能力。

3.3 2D目標檢測
對于2D目標檢測任務,作者直接將PiMAE中的2D分支特征提取器部署在DETR上,并在ScanNetV2 2D檢測數據集上進行評估。效果如下表所示,PiMAE預訓練可以顯著提高DETR的檢測性能。

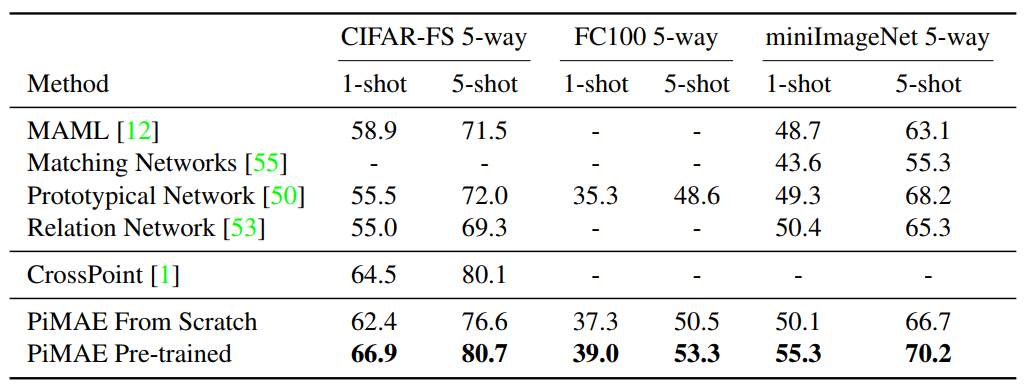
3.4 小樣本圖像分類
對于few-shot圖像分類任務,作者選取了三個不同的基準來探索PiMAE圖像編碼器的特征提取能力。為了驗證PiMAE的有效性,作者沒有改動原有模型的分類器,僅在特征編碼器中添加一個線性層,并基于[CLS] token作為輸入來預測類別。下表展示了PiMAE在小樣本圖像分類任務上的結果。與從頭開始訓練的模型相比,經過PiMAE預訓練的模型具有顯著的性能提升。
此外,為了驗證PiMAE跨模態交互設計的有效性,作者在下圖中可視化了共享編碼器中的注意力圖。可以看到,PiMAE更專注于具有更高注意力值的更多前景目標,顯示出較強的跨模態理解能力。

四、總結
本文提出了一種基于MAE的跨模態交互式自編碼器PiMAE,PiMAE同時具有強大的3D點云和RGB圖像特征提取能力。作者通過三個方面的獨特設計來促進多模態學習過程中的交互效果。首先,通過一種顯示的點云圖像對齊mask策略可以實現更好的特征融合。接下來,設計了一個共享解碼器來同時對兩種模態中的token進行處理。最后,跨模態重建機制可以高效的對整體框架進行優化。作者對提出的PiMAE進行了廣泛的實驗,PiMAE在多個下游任務上都展示出了非常出色的性能提升效果,這也側面表明MAE模式在基礎視覺感知任務上仍然不過時,具有進一步研究的價值。
審核編輯 :李倩
-
解碼器
+關注
關注
9文章
1147瀏覽量
40885 -
編碼器
+關注
關注
45文章
3664瀏覽量
135097 -
目標檢測
+關注
關注
0文章
211瀏覽量
15655
原文標題:CVPR 2023 | MAE再發力,跨模態交互式自編碼器PiMAE席卷3D目標檢測領域
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于變分自編碼器的異常小區檢測
基于深度自編碼網絡的慢速移動目標檢測
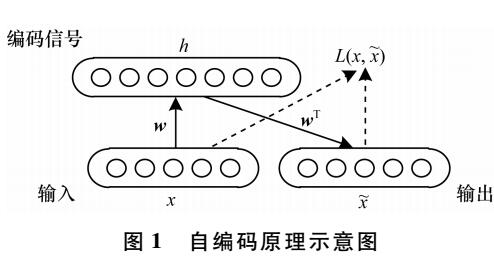
是什么讓變分自編碼器成為如此成功的多媒體生成工具呢?

Torch 3D通過AR工具來開拓3D設計領域
英偉達再出新研究成果 可以渲染合成交互式3D環境的AI技術
自編碼器介紹
自編碼器基礎理論與實現方法、應用綜述
自編碼器神經網絡應用及實驗綜述
華南理工開源VISTA:雙跨視角空間注意力機制實現3D目標檢測SOTA
自編碼器 AE(AutoEncoder)程序

工業儀器3D交互式產品展示的亮點
如何搞定自動駕駛3D目標檢測!






 工商網監
工商網監
評論