

1.程序講解
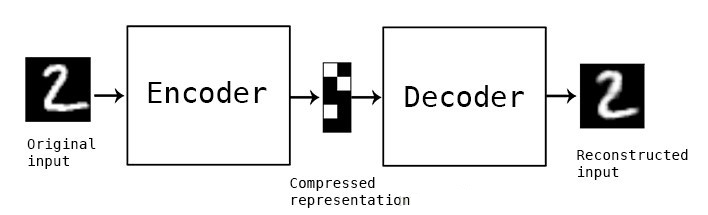
(1)香草編碼器
在這種自編碼器的最簡單結構中,只有三個網絡層,即只有一個隱藏層的神經網絡。它的輸入和輸出是相同的,可通過使用Adam優化器和均方誤差損失函數,來學習如何重構輸入。
在這里,如果 隱含層維數(64)小于輸入維數(784 ),則稱這個編碼器是有損的。通過這個約束,來迫使神經網絡來學習數據的壓縮表征。
input_size = 784
hidden_size = 64
output_size = 784
x = Input(shape=(input_size,))
# Encoder
h = Dense(hidden_size, activation='relu')(x)
# Decoder
r = Dense(output_size, activation='sigmoid')(h)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')
Dense :Keras Dense層,keras.layers.core.Dense( units, activation=None)
units, #代表該層的輸出維度
activation=None, #激活函數.但是默認 liner
Activation :激活層對一個層的輸出施加激活函數
model.compile() :Model模型方法之一:compile
optimizer :優化器,為預定義優化器名或優化器對象,參考優化器
loss :損失函數,為預定義損失函數名或一個目標函數,參考損失函數
adam :adaptive moment estimation,是對RMSProp優化器的更新。利用梯度的一階矩估計和二階矩估計動態調整每個參數的學習率。優點:每一次迭代學習率都有一個明確的范圍,使得參數變化很平穩。
mse :mean_squared_error,均方誤差
(2)多層自編碼器
如果一個隱含層還不夠,顯然可以將自動編碼器的隱含層數目進一步提高。
在這里,實現中使用了3個隱含層,而不是只有一個。 任意一個隱含層都可以作為特征表征 ,但是為了使網絡對稱,我們使用了最中間的網絡層。
input_size = 784
hidden_size = 128
code_size = 64
x = Input(shape=(input_size,))
# Encoder
hidden_1 = Dense(hidden_size, activation='relu')(x)
h = Dense(code_size, activation='relu')(hidden_1)
# Decoder
hidden_2 = Dense(hidden_size, activation='relu')(h)
r = Dense(input_size, activation='sigmoid')(hidden_2)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')
(3)卷積自編碼器
除了全連接層,自編碼器也能應用到卷積層,原理是一樣的,但是 要使用3D矢量(如圖像)而不是展平后的一維矢量 。對輸入圖像進行 下采樣 ,以提供較小維度的潛在表征,來迫使自編碼器從壓縮后的數據進行學習。
x = Input(shape=(28, 28,1))
# Encoder
conv1_1 = Conv2D(16, (3, 3), activation='relu', padding='same')(x)
pool1 = MaxPooling2D((2, 2), padding='same')(conv1_1)
conv1_2 = Conv2D(8, (3, 3), activation='relu', padding='same')(pool1)
pool2 = MaxPooling2D((2, 2), padding='same')(conv1_2)
conv1_3 = Conv2D(8, (3, 3), activation='relu', padding='same')(pool2)
h = MaxPooling2D((2, 2), padding='same')(conv1_3)
# Decoder
conv2_1 = Conv2D(8, (3, 3), activation='relu', padding='same')(h)
up1 = UpSampling2D((2, 2))(conv2_1)
conv2_2 = Conv2D(8, (3, 3), activation='relu', padding='same')(up1)
up2 = UpSampling2D((2, 2))(conv2_2)
conv2_3 = Conv2D(16, (3, 3), activation='relu')(up2)
up3 = UpSampling2D((2, 2))(conv2_3)
r = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(up3)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')
conv2d :Conv2D(filters, kernel_size, strides=(1, 1), padding='valid')
filters:卷積核的數目(即輸出的維度)。
kernel_size:卷積核的寬度和長度,單個整數或由兩個整數構成的list/tuple。如為單個整數,則表示在各個空間維度的相同長度。
strides:卷積的步長,單個整數或由兩個整數構成的list/tuple。如為單個整數,則表示在各個空間維度的相同步長。任何不為1的strides均與任何不為1的dilation_rate均不兼容。
padding:補0策略,有“valid”, “same” 兩種。“valid”代表只進行有效的卷積,即對邊界數據不處理。“same”代表保留邊界處的卷積結果,通常會導致輸出shape與輸入shape相同。
MaxPooling2D :2D輸入的最大池化層。MaxPooling2D(pool_size=(2, 2), strides=None, border_mode='valid')
pool_size:pool_size:長為2的整數tuple,代表在兩個方向(豎直,水平)上的下采樣因子,如取(2,2)將使圖片在兩個維度上均變為原長的一半。
strides:長為2的整數tuple,或者None,步長值。
padding:字符串,“valid”或者”same”。
UpSampling2D :上采樣。UpSampling2D(size=(2, 2))
size:整數tuple,分別為行和列上采樣因子。
(4)正則自編碼器
除了施加一個比輸入維度小的隱含層,一些其他方法也可用來約束自編碼器重構,如正則自編碼器。
正則自編碼器不需要使用淺層的編碼器和解碼器以及小的編碼維數來限制模型容量,而是使用損失函數來鼓勵模型學習其他特性(除了將輸入復制到輸出)。這些特性包括稀疏表征、小導數表征、以及對噪聲或輸入缺失的魯棒性。
即使模型容量大到足以學習一個無意義的恒等函數,非線性且過完備的正則自編碼器仍然能夠從數據中學到一些關于數據分布的有用信息。
在實際應用中,常用到兩種正則自編碼器,分別是稀疏自編碼器和 降噪自編碼器 。
(5)稀疏自編碼器
一般用來學習特征,以便用于像分類這樣的任務。稀疏正則化的自編碼器必須反映訓練數據集的獨特統計特征,而不是簡單地充當恒等函數。以這種方式訓練,執行附帶稀疏懲罰的復現任務可以得到能學習有用特征的模型。
還有一種用來約束自動編碼器重構的方法,是對其損失函數施加約束。比如,可對 損失函數添加一個正則化約束 ,這樣能使自編碼器學習到數據的稀疏表征。
要注意,在隱含層中,我們還加入了 L1正則化,作為優化階段中損失函數的懲罰項 。與香草自編碼器相比,這樣操作后的數據表征更為稀疏。
input_size = 784
hidden_size = 64
output_size = 784
x = Input(shape=(input_size,))
# Encoder
h = Dense(hidden_size, activation='relu', activity_regularizer=regularizers.l1(10e-5))(x)
#施加在輸出上的L1正則項
# Decoder
r = Dense(output_size, activation='sigmoid')(h)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')
activity_regularizer :施加在輸出上的正則項,為ActivityRegularizer對象
l1(l=0.01) :L1正則項,正則項通常用于對模型的訓練施加某種約束,L1正則項即L1范數約束,該約束會使被約束矩陣/向量更稀疏。
(6)降噪自編碼器
這里不是通過對損失函數施加懲罰項,而是 通過改變損失函數的重構誤差項來學習一些有用信息 。
向訓練數據加入噪聲,并使自編碼器學會去除這種噪聲來獲得沒有被噪聲污染過的真實輸入。因此,這就迫使編碼器學習提取最重要的特征并學習輸入數據中更加魯棒的表征,這也是它的泛化能力比一般編碼器強的原因。
這種結構可以通過梯度下降算法來訓練。
x = Input(shape=(28, 28, 1))
# Encoder
conv1_1 = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
pool1 = MaxPooling2D((2, 2), padding='same')(conv1_1)
conv1_2 = Conv2D(32, (3, 3), activation='relu', padding='same')(pool1)
h = MaxPooling2D((2, 2), padding='same')(conv1_2)
# Decoder
conv2_1 = Conv2D(32, (3, 3), activation='relu', padding='same')(h)
up1 = UpSampling2D((2, 2))(conv2_1)
conv2_2 = Conv2D(32, (3, 3), activation='relu', padding='same')(up1)
up2 = UpSampling2D((2, 2))(conv2_2)
r = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(up2)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')
2.程序實例:
(1)單層自編碼器
from keras.layers import Input, Dense
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
print(x_train.shape)
print(x_test.shape)
#單層自編碼器
encoding_dim = 32
input_img = Input(shape=(784,))
encoded = Dense(encoding_dim, activation='relu')(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(inputs=input_img, outputs=decoded)
encoder = Model(inputs=input_img, outputs=encoded)
encoded_input = Input(shape=(encoding_dim,))
decoder_layer = autoencoder.layers[-1]
decoder = Model(inputs=encoded_input, outputs=decoder_layer(encoded_input))
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256,
shuffle=True, validation_data=(x_test, x_test))
encoded_imgs = encoder.predict(x_test)
decoded_imgs = decoder.predict(encoded_imgs)
#輸出圖像
n = 10 # how many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
(2)卷積自編碼器
from keras.layers import Input, Convolution2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
from keras.callbacks import TensorBoard
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
noise_factor = 0.5
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
print(x_train.shape)
print(x_test.shape)
#卷積自編碼器
input_img = Input(shape=(28, 28, 1))
x = Convolution2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Convolution2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(inputs=input_img, outputs=decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
# 打開一個終端并啟動TensorBoard,終端中輸入 tensorboard --logdir=/autoencoder
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256,
shuffle=True, validation_data=(x_test, x_test),
callbacks=[TensorBoard(log_dir='autoencoder')])
decoded_imgs = autoencoder.predict(x_test)
#輸出圖像
n = 10 # how many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
(3)深度自編碼器
from keras.layers import Input, Dense
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
print(x_train.shape)
print(x_test.shape)
#深度自編碼器
input_img = Input(shape=(784,))
encoded = Dense(128, activation='relu')(input_img)
encoded = Dense(64, activation='relu')(encoded)
decoded_input = Dense(32, activation='relu')(encoded)
decoded = Dense(64, activation='relu')(decoded_input)
decoded = Dense(128, activation='relu')(decoded)
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(inputs=input_img, outputs=decoded)
encoder = Model(inputs=input_img, outputs=decoded_input)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256,
shuffle=True, validation_data=(x_test, x_test))
encoded_imgs = encoder.predict(x_test)
decoded_imgs = autoencoder.predict(x_test)
#輸出圖像
n = 10 # how many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
(4)降噪自編碼器
from keras.layers import Input, Convolution2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
from keras.callbacks import TensorBoard
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
noise_factor = 0.5
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
print(x_train.shape)
print(x_test.shape)
input_img = Input(shape=(28, 28, 1))
x = Convolution2D(32, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(32, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(32, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(32, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
decoded = Convolution2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(inputs=input_img, outputs=decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
# 打開一個終端并啟動TensorBoard,終端中輸入 tensorboard --logdir=/autoencoder
autoencoder.fit(x_train_noisy, x_train, epochs=10, batch_size=256,
shuffle=True, validation_data=(x_test_noisy, x_test),
callbacks=[TensorBoard(log_dir='autoencoder', write_graph=False)])
decoded_imgs = autoencoder.predict(x_test_noisy)
n = 10
plt.figure(figsize=(30, 6))
for i in range(n):
ax = plt.subplot(3, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 1 + n)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 1 + 2*n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
學習更多編程知識,請關注我的公眾號:

-
編碼器
+關注
關注
45文章
3736瀏覽量
136305 -
神經網絡
+關注
關注
42文章
4793瀏覽量
102023 -
編程
+關注
關注
88文章
3669瀏覽量
94581 -
程序
+關注
關注
117文章
3815瀏覽量
81994 -
AutoEncoder
+關注
關注
0文章
2瀏覽量
694
發布評論請先 登錄
相關推薦
基于變分自編碼器的異常小區檢測
是什么讓變分自編碼器成為如此成功的多媒體生成工具呢?

自編碼器介紹
稀疏自編碼器及TensorFlow實現詳解
基于稀疏自編碼器的屬性網絡嵌入算法SAANE
基于變分自編碼器的海面艦船軌跡預測算法
自編碼器基礎理論與實現方法、應用綜述
可實現骨骼運動重定向的通用雙向循環自編碼器

一種基于變分自編碼器的人臉圖像修復方法

自編碼器神經網絡應用及實驗綜述
基于交叉熵損失函欻的深度自編碼器診斷模型
堆疊降噪自動編碼器(SDAE)





 工商網監
工商網監

評論