

本文簡要介紹ICLR 2023錄用論文“StrucTexTv2: Masked Visual-Textual Prediction for Document Image Pre-training”的主要工作。針對當前主流多模態文檔理解預訓練模型需要同時輸入文檔圖像和OCR結果,導致欠缺端到端的表達能力且推理效率偏低等問題,論文提出了一種全新的端到端文檔圖像多模態表征學習預訓練框架StrucTexTv2。該框架設計了一種基于詞粒度圖像區域掩碼、多模態自監督預訓練任務(MIM+MLM),僅需要圖像單模態輸入,使得編碼器網絡能在大規模無標注文檔圖像上充分學習視覺和語言聯合特征表達,并在多個下游任務的公開基準上取得SOTA效果。
一、研究背景
視覺富文檔理解技術例如文檔分類、版式分析、表單理解、OCR以及信息提取,逐漸成為文檔智能領域一個熱門研究課題。為了有效處理這些任務,前沿的方法大多利用視覺和文本線索,將圖像、文本、布局等信息輸入到參數網絡,并基于大規模數據上的自監督預訓練挖掘出文檔的多模態特征。由于視覺和語言之間的模態差異較大,如圖1所示,主流的文檔理解預訓練方法大致可分為兩類:a)掩碼語言建模(Masked Language Modeling)[9],對輸入的掩碼文本Token進行語言建模,運行時文本的獲取依賴于OCR引擎,整個系統的性能提升需要對OCR引擎和文檔理解模型兩個部件進行同步優化;b)掩碼圖像建模(Masked Image Modeling)[10],對輸入的掩碼圖像塊區進行像素重建,此類方法傾向應用于圖像分類和版式分析等任務上,對文檔強語義理解能力欠佳。針對上述兩種預訓練方案呈現的瓶頸,本文提出了StrucTexTv2:c)統一圖像重建與語言建模方式,在大規模文檔圖像上學習視覺和語言聯合特征表達。
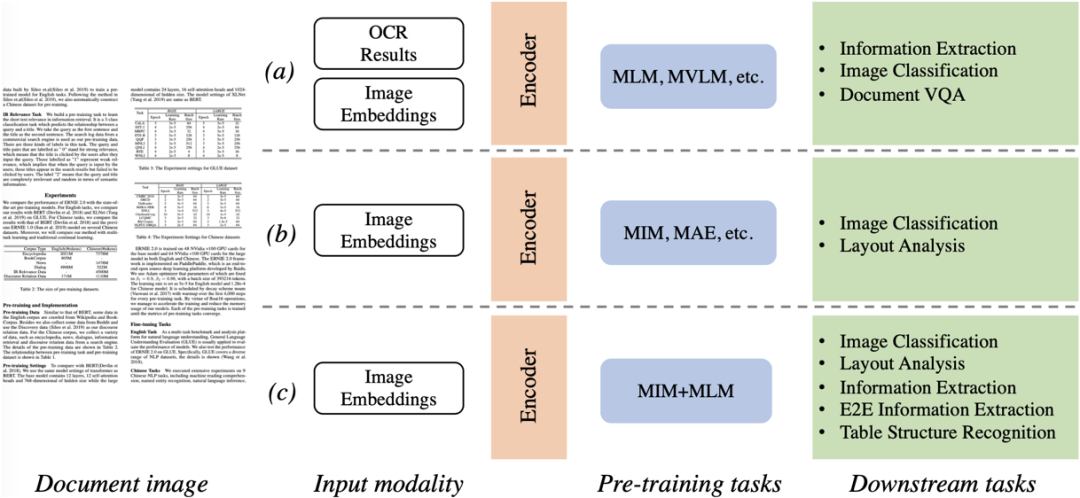
圖1 主流文檔圖像理解預訓練框架比較
二、方法原理簡述
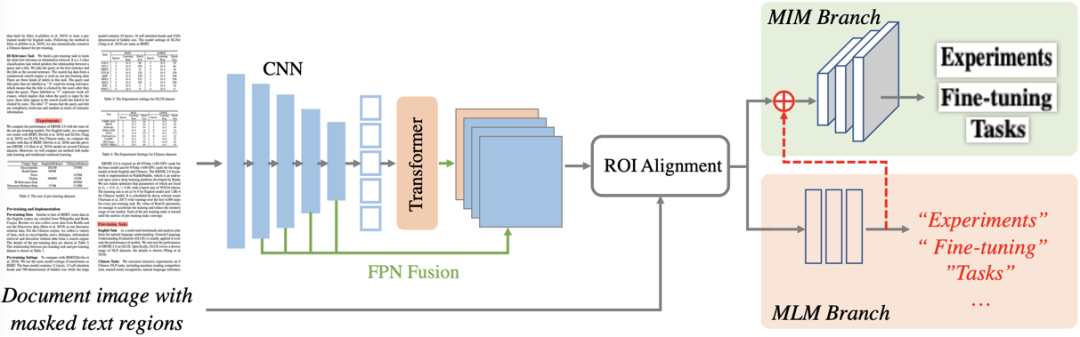
圖2 整體框架圖
圖2描繪了StrucTexTv2的整體框架,主要包含編碼器網絡和預訓練任務分支兩部分。編碼器網絡,主要通過FPN結構串聯CNN組件和Transformer組件構成;預訓練分支則包含了掩碼語言建模(MLM)和掩碼圖像建模(MIM)雙預訓練任務頭。
2.1 編碼器網絡
StrucTexTv2采用CNN和Transformer的串聯編碼器來提取文檔圖像的視覺和語義特征。文檔圖像首先經過ResNet網絡以獲取1/4到1/32的四個不同尺度的特征圖。隨后采用一個標準的Transformer網絡接收最小尺度的特征圖并加上1D位置編碼向量,提取出包含全局上下文的語義特征。該特征被重新轉化為2D形態后,與CNN的其余三個尺度特征圖通過FPN[6]融合成4倍下采樣的特征圖,作為整圖的多模態特征表示。
2.2 預訓練策略
為了統一建模MLM和MIM兩種模態預訓練方式,論文提出了一種基于詞粒度圖像區域掩碼預測方式來學習視覺和語言聯合特征表達。首先,隨機篩選30%的詞粒度OCR預測結果(僅在預訓練階段使用),根據OCR的位置信息直接在原圖對應位置像素進行掩碼操作(比如填充0值)。接著,掩碼后的文檔圖像直接送入編碼器網絡去獲得整圖的多模態特征表示。最后,再次根據選中的OCR位置信息,采用ROIAlign[11]操作去獲得每個掩碼區域的多模態ROI特征。
掩碼語言建模:借鑒于BERT[9]構建的掩碼語言模型思路,語言建模分支使用一個2層的MLP將詞區域的ROI特征映射到預定義的詞表類別上,使用Cross Entropy Loss監督。同時為了避免使用詞表對文本序列進行標記化時單個詞組被拆分成多個子詞導致的一對多匹配問題,論文使用分詞后每個單詞的首個子詞作為分類標簽。此設計帶來的優勢是:StrucTexTv2的語言建模無需文本作為輸入。
掩碼圖像建模:考慮到基于圖像Patch的掩碼重建在文檔預訓練中展現出一定的潛力,但Patch粒度的特征表示難以恢復文本細節。因此,論文將詞粒度掩碼同時用作圖像重建,即預測被掩碼區域的原始像素值。詞區域的ROI特征首先通過一個全局池化操作被壓縮成特征向量。其次,為了提升圖像重建的視覺效果,論文將通過語言建模后的概率特征與池化特征進行拼接,為圖像建模引入“Content”信息,使得圖像預訓練專注于復原文本區域的“Style”部分。圖像建模分支由3個全卷積 Block構成。每個Block包含一個Kernel=2×2,Stride=4的反卷積層,一個Kernel=1×1,以及兩個Kernel=3×1卷積層。最后,每個單詞的池化向量被映射成一個大小為64×64×3的圖像,并逐像素與原本的圖像區域做MSE Loss。
論文提供了Small和Large兩種參數規格的模型,并在IIT-CDIP數據集上使用百度通用高精OCR的文字識別結果預訓練編碼網絡。
三、實驗結果
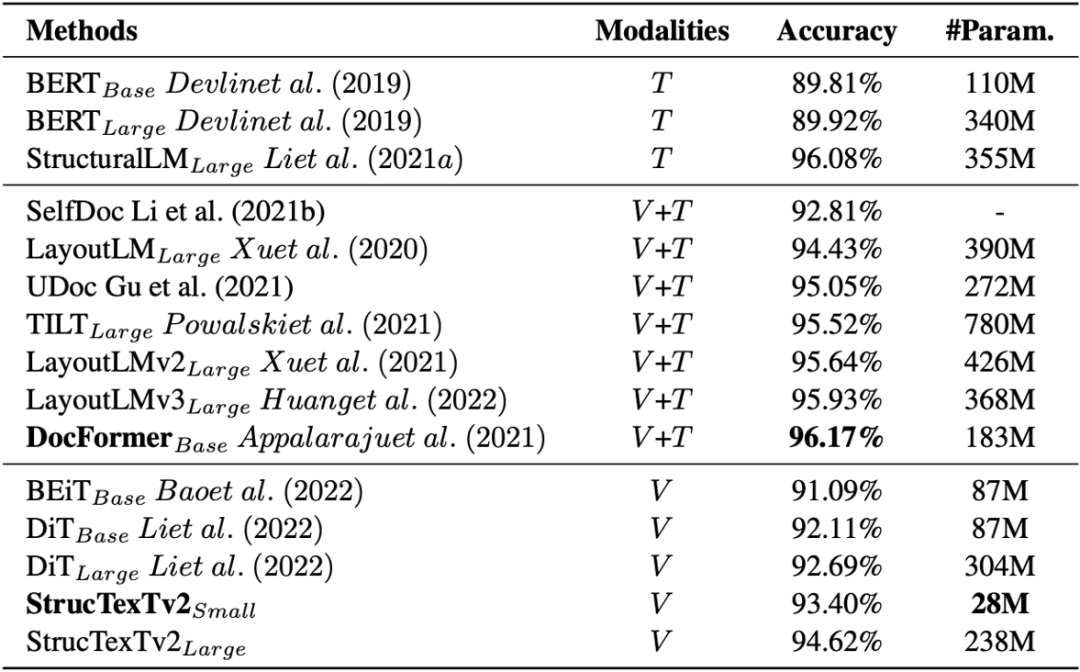
論文在四個基準數據集上測試模型對文檔理解的能力,在五個下游任務上使用不同的Head進行Fine-tune并給出實驗結論。表1給出模型在RVL-CDIP[13]驗證文檔圖像分類的效果。同比基于圖像單模態輸入的方法DiT[4],StrucTexTv2以更少的參數量取得了更優的分類精度。
表1 RVL-CDIP數據集上文檔圖像分類的實驗結果
如表2和表3所示,論文結合預訓練模型和Cascade R-CNN[1]框架fine-tune去檢測文檔中的版式元素以及表格結構,在PubLaynet[8]以及WWW[12]數據集上取得了當前的最好性能。
表2 PubLaynet數據集上版式分析的檢測結果
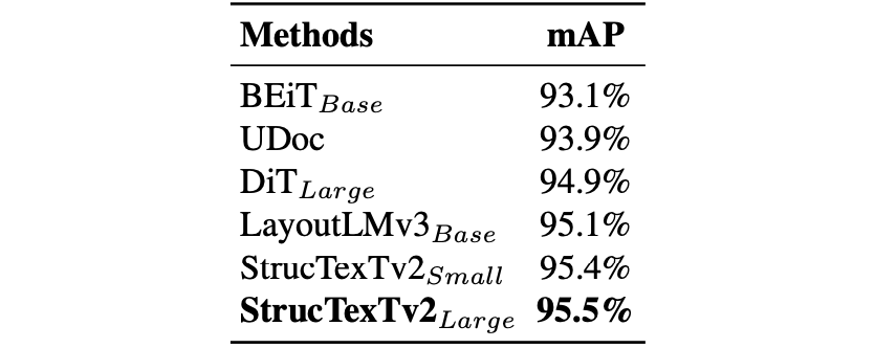
表3 WWW數據集上表格結構識別的性能對比

在表4中,論文同時在FUNSD[3]數據集上進行了端到端OCR和信息提取兩項實驗,在基準測試中都取得了同期最優的效果。對比如StrucTexTv1[5]和LayoutLMv3[2]等OCR+文檔理解的兩階段方法,證明了提出方法端到端優化的優越性。
表4 FUNSD數據集上端到端OCR以及信息抽取實驗

接下來,論文對比了SwinTransformer[7]、ViT[10]以及StrucTexTv2的編碼網絡。從表5對比結果來看,論文提出CNN+Transformer的串聯結構更有效地支持預訓練任務。同時,論文給出了不同預訓練配置的模型在文檔圖像分類和版式分析的性能增益,對兩種模態預訓練進行了有效性驗證。
表5 預訓練任務以及編碼器結構的消融實驗
同時,論文中評估了模型在預測時的耗時和顯存開銷。表6中給出了兩種OCR引擎帶來的開銷以及并與現階段最優的多模態方法LayoutLMv3進行了比較。
表6 與兩階段的方法LayoutLMv3的資源開銷對比
最后,論文評估了表7所示在圖像重建預訓練中使用不同的掩碼方式對下游任務的影響。在RVL-CDIP和PubLaynet兩個數據集上,基于詞粒度掩碼的策略可以獲取到更有效的視覺語義特征,確保更好的性能。
表7 預訓練任務以及編碼器結構的消融實驗

總結及討論
論文出的StructTexTv2模型用于端到端學習文檔圖像的視覺和語言聯合特征表達,圖像單模態輸入條件下即可實現高效的文檔理解。論文提出的預訓練方法基于詞粒度的圖像掩碼,能同時預測相應的視覺和文本內容,此外,所提出的編碼器網絡能夠更有效地挖掘大規模文檔圖像信息。實驗表明,StructTexTv2在模型大小和推理效率方面對比之前的方法都有顯著提高。更多的方法原理介紹和實驗細節請參考論文原文。
審核編輯 :李倩
-
圖像
+關注
關注
2文章
1091瀏覽量
40893 -
OCR
+關注
關注
0文章
155瀏覽量
16635
原文標題:ICLR 2023 | StrucTexTv2:端到端文檔圖像理解預訓練框架
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
動量感知規劃的端到端自動駕駛框架MomAD解析
詳解RAD端到端強化學習后訓練范式

端到端自動駕駛技術研究與分析
端到端在自動泊車的應用
爆火的端到端如何加速智駕落地?
連接視覺語言大模型與端到端自動駕駛

端到端讓智駕強者愈強時代來臨?
端到端InfiniBand網絡解決LLM訓練瓶頸







 工商網監
工商網監

評論