

與城市環境的復雜性和高速公路駕駛的風險相比,停車場景的特點是低速、空間有限和高可控性。這些特點為在車輛中逐步部署端到端自動駕駛能力提供了可行的途徑。最重要的是自動泊車對時間不敏感,而自動駕駛幀率至少要做到15Hz以上。這樣就對存儲和算力需求降低很多。
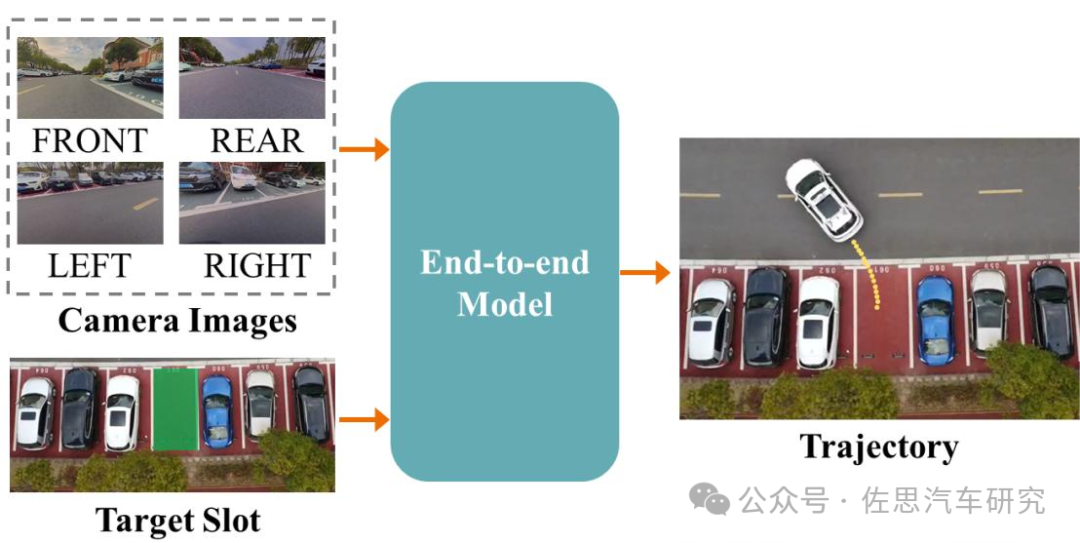
上海交通大學的五位學生發表了一篇端到端自動泊車的論文:《ParkingE2E: Camera-based End-to-end Parking Network from Images to Planning》,比較接近落地,由于是學術研究,這些學生沒有得到汽車產業界的支持,因此他們仍然使用了傳統PC,論文里只是含糊地說用了英特爾的UNC小型臺式機或者叫Mini PC。實際UNC性能千差萬別,一般是英特爾9代或9代以上的CPU,也有用12代筆記本電腦低功耗CPU的,16GB或16GB以上的內存。這樣的電腦CPU算力仍然是英偉達Orin的2-4倍,AI能力自然很低,但有強大的CPU支撐,整體上處理AI任務時,差不多近似或略超英偉達Orin的性能。換句話說,這個可以用英偉達Orin來實現,具備落地的可能性。
流程如下圖。

圖片來源:網絡
有一點需要指出,找尋停車位目前最佳或主要傳感器仍然是超聲波,視覺還是不如超聲波雷達,因此論文中省略了車位尋找這一過程,論文應該是使用了AUTOWARE開源無人駕駛系統,這是日本名古屋大學開發的基于ROS2的開源無人駕駛系統,主要用于科研。其中導航和可視化模塊是RVIZ。論文直接用RVIZ模塊選定車位。
使用端到端神經網絡Nθ來模仿專家軌跡進行訓練,定義數據集為:
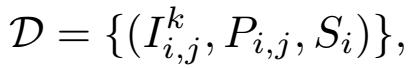
軌跡索引 i∈[1,M],軌跡點索引 j∈[1,Ni],相機索引 k∈[1,R],RGB圖像 I,軌跡點 P 和目標停車位 S。重新組織數據集為:
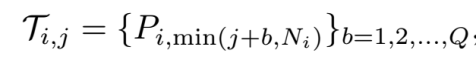
和
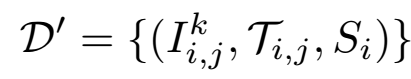
其中 Q 表示預測軌跡點的長度,R 表示 RGB 相機的數量。端到端網絡的優化目標如下:
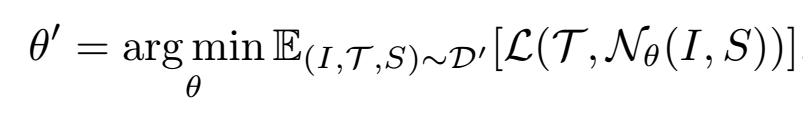
其中 L 表示損失函數。
以 RGB 圖像和目標停車位作為輸入。所提出的神經網絡包括兩個主要部分:輸入編碼器和自回歸軌跡解碼器。通過輸入 RGB 圖像和目標停車位,將 RGB 圖像轉換為 BEV 特征。然后,神經網絡將 BEV 特征與目標停車位融合,并使用 Transformer 解碼器以自回歸方式生成下一個軌跡點。
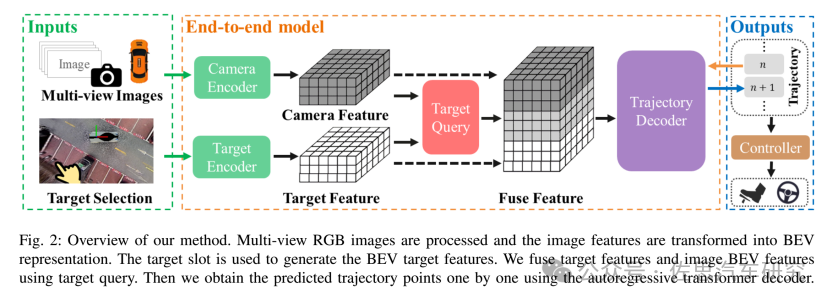
圖片來源:《ParkingE2E: Camera-based End-to-end Parking Network from Images to Planning》
多視角 RGB 圖像被處理,圖像特征被轉換為 BEV(鳥瞰圖)表示形式。使用目標停車位生成 BEV 目標特征,通過目標查詢將目標特征和圖像 BEV 特征融合,然后使用自回歸的 Transformer 解碼器逐個獲得預測的軌跡點。
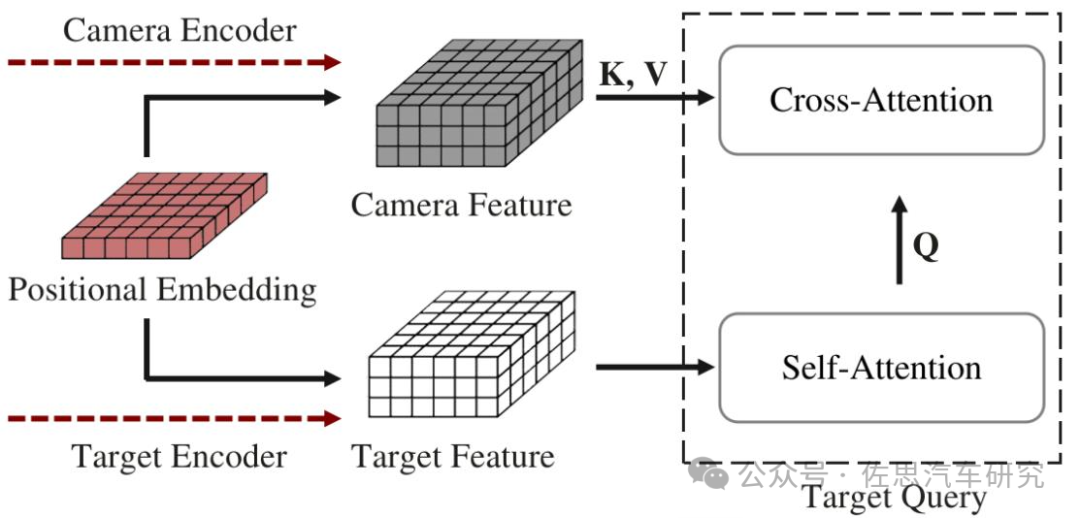
圖片來源:《ParkingE2E: Camera-based End-to-end Parking Network from Images to Planning》
在 BEV 視圖下對輸入進行編碼。BEV 表示提供了車輛周圍環境的俯視圖,允許自車檢測停車位、障礙物和標記。同時,BEV 視圖提供了不同駕駛視角下一致的視點表示,從而簡化了軌跡預測的復雜性。
相機編碼器:在 BEV 生成流程的開始,骨干網使用 EfficientNet 從 RGB 輸入中提取圖像特征
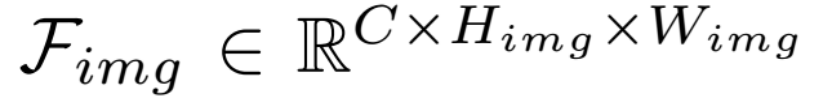
各個尺寸EfficientNet性能對比
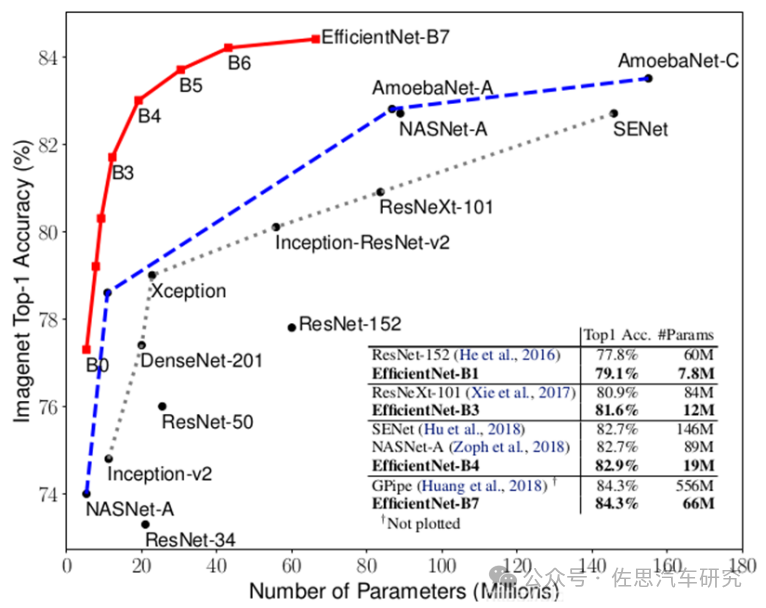
圖片來源:網絡
上圖是各個尺寸EfficientNet性能對比,最高性能是6600萬參數,準確率84.3%,不過1200萬參數也達到了81.6%,這也說明CNN并不適合Scaling Law,此外CNN模型參數少,并不意味著計算量就一定低。
LSS算法
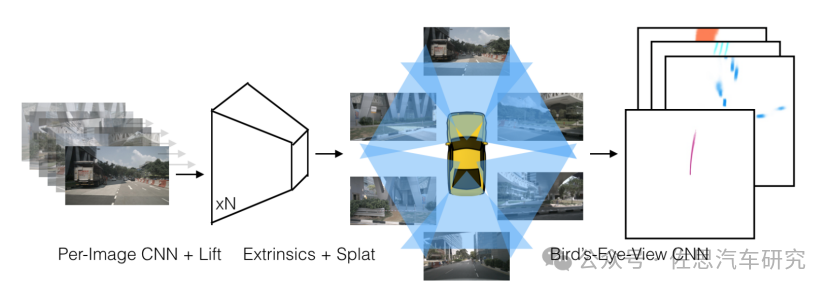
圖片來源:英偉達
受英偉達LSS啟發,學習圖像特征的深度分布,LSS是英偉達2020年提出的一種經典的自下而上的構建BEV特征的3D目標檢測算法,通過將圖像特征反投影到3D空間生成偽視錐點云,通過EfficientNet算法提取云點的深度特征和圖像特征并對深度信息進行估計,最終將點云特征轉換到BEV空間下進行特征融合和后續的語義分割任務。也是國內最常見的BEV算法,典型代表就是地平線。
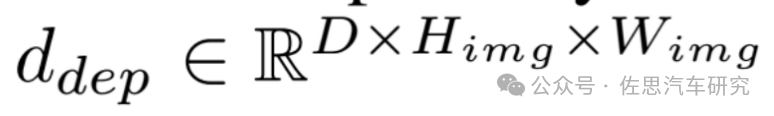
并將每個像素提升到 3D 空間。
然后,將預測的深度分布ddep與圖像特征Fimg相乘,以獲得具有深度信息的圖像特征。通過相機的外部和內部參數,將圖像特征投影到 BEV 體素網格中,生成相機特征。
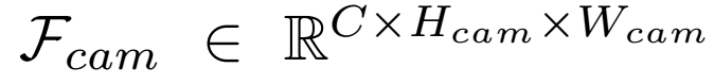
為了將目標停車位與相機特征 Fcam 對齊,根據指定的停車位位置在 BEV 空間生成目標熱圖作為目標編碼器的輸入。隨后,使用深度 CNN 神經網絡提取目標停車位特征 Ftarget 以獲得與 Fcam相同的維度。在訓練期間,目標停車位由人類駕駛軌跡的終點確定。通過在 BEV 空間對齊相機特征 Fcam和目標編碼特征 Ftarget ,并使用目標特征通過交叉注意力機制查詢相機特征,可以有效地融合兩種模態。位置編碼確保了在將特定 BEV 位置的特征關聯時,相機特征和目標特征之間的空間對應關系得以保持。使用 Ftarget 作為查詢,相機特征 Fcam 作為Key和Value,并采用注意力機制,獲得融合特征 Ffuse。
編碼器方面,軌跡序列化將軌跡點表示為離散標記。通過序列化軌跡點,位置回歸可以轉換為標記預測。隨后利用 Transformer 解碼器以自回歸方式預測軌跡。BEV 特征作為Key和Value,而序列化序列作為查詢,使用 Transformer 解碼器以自回歸方式生成軌跡點。在訓練期間,在序列點中添加位置嵌入,并通過掩碼未知信息來實現并行化。在推理過程中,給定 BOS 做開始標記,然后 Transformer 解碼器按順序預測后續點。然后將預測的點追加到序列中,重復此過程直到遇到 EOS終止標記或達到指定的預測點數。
控制過程中,以 t0 表示停車開始時刻,使用端到端神經規劃器基于當前時刻 t0 到當前時刻 t 的相對姿態 egot0→t 來預測路徑 Tt0=Nθ′(It0,S)。目標轉向角 Atar可以通過后輪反饋(RWF)方法獲得,表達式如下:
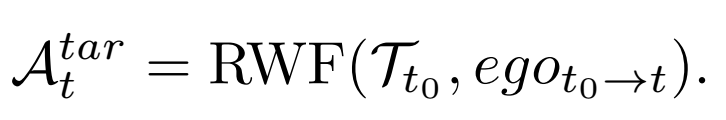
根據來自底盤的速度反饋 Vfeed 和轉向反饋 Afeed,以及設置的目標速度 Vtar 和計算出的目標轉向 Atar,使用級聯 PID 控制器實現橫向和縱向控制。生成新的預測軌跡后,Tt0 和 egot0→t被重置,消除了在整個車輛控制過程中依賴全局定位的必要性。

作者設置了四種不同類型的停車場作為測試和訓練,有室內,有全開放,有兩側和單側。
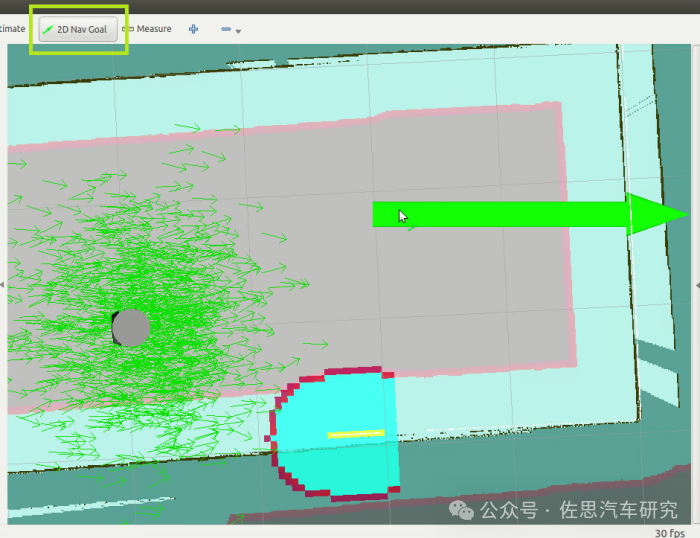
圖片來源:網絡
通過在RViz界面軟件中使用“2D-Nav-Goal”來選擇目標停車位,如上圖,每次只能選一個。靠IMU獲取起始位姿,將以起始點為原點的世界坐標轉化為車輛坐標。模型接收來自環視攝像頭的當前圖像和目標停車位,以自回歸方式預測后續n個軌跡點的位置。將預測的軌跡序列發布到 RViz 進行可視化顯示,讓用戶更直觀看到泊車過程,為用戶增加信心。控制器根據路徑規劃結果、自車姿態和反饋信號來操控車輛,將車輛停放到指定的停車位中。值得注意的是,目標點和預測軌跡點的坐標在車輛坐標系中表示,確保軌跡序列和BEV特征在一致的坐標基礎上表達。這種設計還使整個系統獨立于全局坐標系。
關于神經網絡的細節,BEV特征的大小為200×200,對應實際空間范圍x∈[?10m, 10m], y∈[?10m, 10m],分辨率為0.1米。在Transformer解碼器中,軌跡序列化的最大值Nt為1200。軌跡解碼器生成長度為30的預測序列,實現了推理精度和速度的最佳平衡。使用PyTorch框架,神經網絡在NVIDIA GeForce RTX 4090 GPU上訓練,batch size為16,總共訓練時間約為8小時,使用了40,000幀數據。測試數據包括大約5,000幀。

測試結果如上,L2距離(L2 Dis.)指的是預測軌跡和真實軌跡航點之間的平均歐幾里得距離。這個指標評估模型推理的精確度和準確性。Hausdorff距離(Haus. Dis.)指的是兩個點集之間的最小距離的最大值。這個指標從點集的角度評估預測軌跡與真實軌跡的匹配程度。傅里葉描述符差異(Four. Diff.)可以用來測量軌跡之間的差異,值越低表示軌跡之間的差異越小。這個指標使用一定數量的傅里葉描述符將實際和預測軌跡表示為向量。
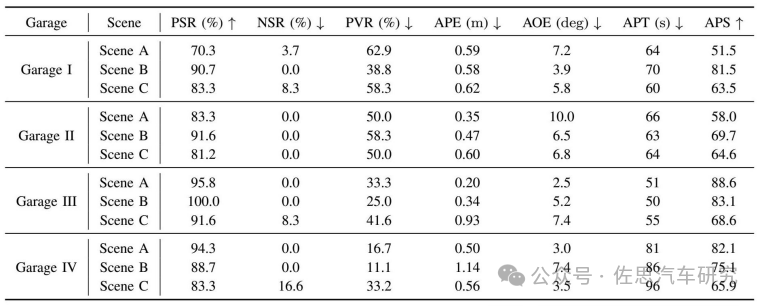
停車成功率(PSR)描述的是自車成功停放在目標停車位的概率。
無車位率(NSR)未能在指定停車位停放的失敗率。
停車違規率(PVR)指的是車輛輕微超出指定停車位但沒有阻礙或妨礙相鄰停車位的情況。
平均位置誤差(APE)是自車成功停放時目標停車位置與自車停止位置之間的平均距離。
平均方向誤差(AOE)是自車成功停放時目標停車方向與自車停止方向之間的平均差異。
平均停車得分(APS)是通過綜合評估停車過程中的位置誤差、方向誤差和成功率來計算的。得分在0到100之間分布。
這個試驗有個缺點,那就是停車位的尋找可能會影響自動泊車。在RViz上,停車位只是一個坐標點。但在真實場景中,停車位可能不是一個清晰的坐標點,超聲波雷達或視覺找到停車位,需要確定幾何中心為關鍵坐標點,這個需要全局定位。而這種端到端自動泊車似乎很難做全局定位,特別是地下停車場。
端到端和傳統算法比,地下停車場和雙側停車場仍然是難點,違規率超過了50%,這完全無法接受,這也表明純粹端到端很難應用,必須添加人工規則,單側停車場表現還不錯。純粹從算力和存儲帶寬看,自動泊車領域用端到端沒有難度。
-
自動泊車
+關注
關注
0文章
104瀏覽量
13843 -
自動駕駛
+關注
關注
788文章
14055瀏覽量
168215
原文標題:端到端在自動泊車的應用
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
特斯拉帶火“端到端”智駕,國內車企加速上車

東風汽車推出端到端自動駕駛開源數據集
小米汽車端到端智駕技術介紹

端到端自動駕駛技術研究與分析
爆火的端到端如何加速智駕落地?
連接視覺語言大模型與端到端自動駕駛

智己汽車“端到端”智駕方案推出,老司機真的會被取代嗎?
Mobileye端到端自動駕駛解決方案的深度解析


理想汽車加速自動駕駛布局,成立“端到端”實體組織
小鵬汽車發布端到端大模型
智行者聯合清華完成國內首套全棧式端到端自動駕駛系統的開放道路測試
佐思汽研發布《2024年端到端自動駕駛研究報告》

理想汽車自動駕駛端到端模型實現






 工商網監
工商網監

評論