 NLP數據增強的最新綜述
NLP數據增強的最新綜述
摘要
作為一種有效的策略,數據增強 (data augmentation, DA) 緩解了深度學習技術可能失敗的數據稀缺情況。
它廣泛應用于計算機視覺,然后引入自然語言處理,并在許多任務中取得了改進。DA方法的主要重點之一是提高訓練數據的多樣性,從而幫助模型更好地泛化到看不見的測試數據。
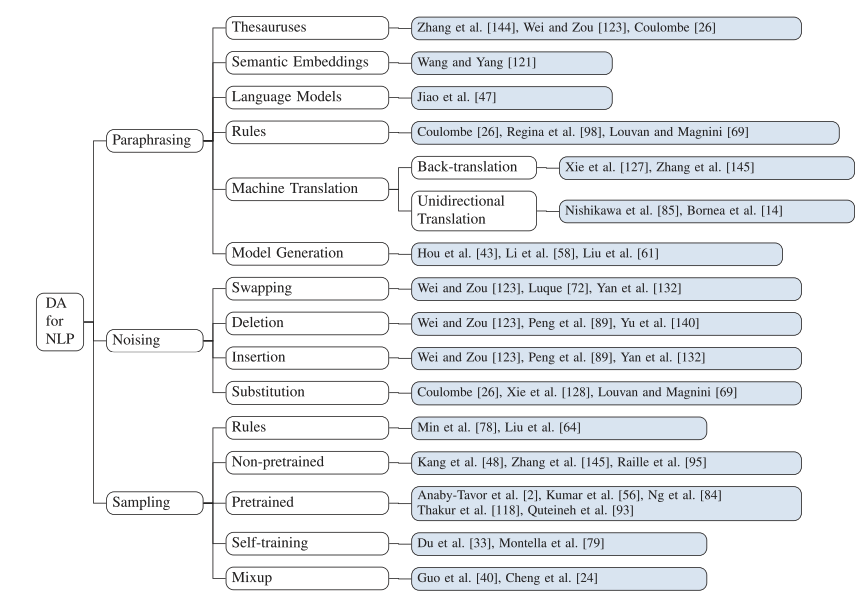
在本次綜述中,我們根據增強數據的多樣性將 DA 方法分為三類,包括改寫(paraphrasing)、噪聲(noising)和采樣(sampling)。我們的論文著手根據上述類別詳細分析 DA 方法。此外,我們還介紹了它們在 NLP 任務中的應用以及面臨的挑戰。
介紹
數據擴充是指通過添加對現有數據稍作修改的副本或從現有數據中新創建的合成數據來增加數據量的方法。這些方法緩解了深度學習技術可能失敗的數據稀缺情況,因此 DA 最近受到了積極的關注和需求。數據增強廣泛應用于計算機視覺領域,例如翻轉和旋轉,然后引入自然語言處理(NLP)。與圖像不同,自然語言是離散的,這使得在 NLP 中采用 DA 方法更加困難且探索不足。
最近提出了大量的 DA 方法,對現有方法的調查有利于研究人員跟上創新的速度。之前的兩項調查都提供了 NLP DA 的鳥瞰圖。他們直接按照方法來劃分類別。因此,這些類別往往過于有限或過于籠統,例如,反向翻譯和基于模型的技術。Baier在 DA 上發布僅用于文本分類的綜述。在本次調研中,我們將全面概述 NLP 中的 DA 方法。我們的主要目標之一是展示 DA 的本質,即為什么數據增強有效。為了促進這一點,我們根據增強數據的多樣性對 DA 方法進行分類,因為提高訓練數據的多樣性是 DA 有效性的主要推動力之一。我們將 DA 方法分為三類,包括改寫、噪聲和采樣。
該論文著手根據上述類別詳細分析 DA 方法。此外,還介紹了它們在 NLP 任務中的應用以及面臨的挑戰。
具體內容
一共分為五大部分。
全面回顧了這三個類別,并分析了這些類別中的每一種方法。還介紹了方法的特征,例如粒度和級別:
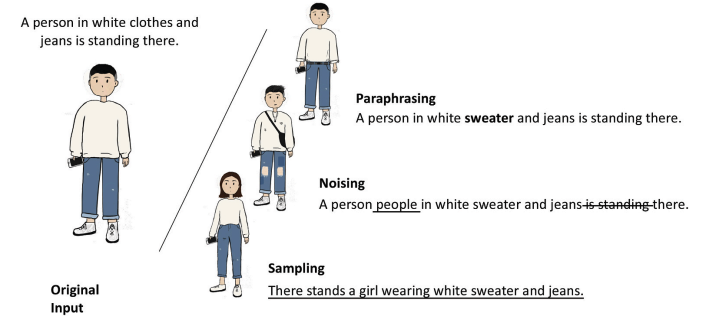
基于改寫(paraphrasing)的方法
基于對句子的適當和有限制的更改,生成與原始數據具有有限語義差異的增強數據。增強數據傳達與原始形式非常相似的信息。
基于噪聲(noising)的方法
在保證有效性的前提下加入離散或連續的噪聲。這些方法的重點是提高模型的魯棒性。
基于抽樣(sampling)的方法
掌握數據分布并對其中的新數據進行抽樣。這些方法輸出更多樣化的數據,滿足基于人工啟發式和訓練模型的下游任務的更多需求。

改寫數據增強技術包括三個層次:詞級、短語級和句子級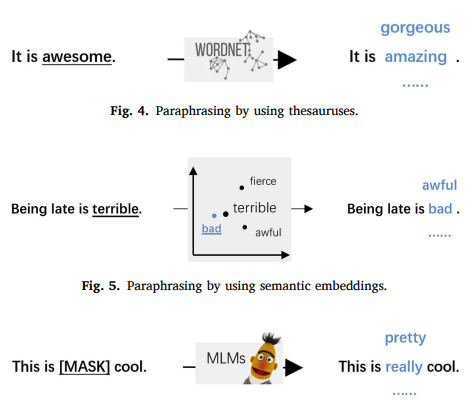
使用語言模型進行改寫
使用規則進行改寫
機器翻譯改寫
通過模型生成進行改寫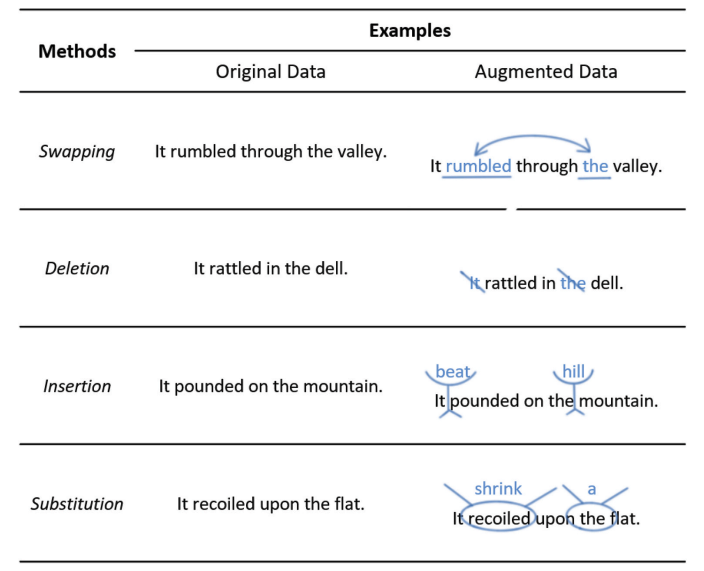
五種基于噪聲的方法的示例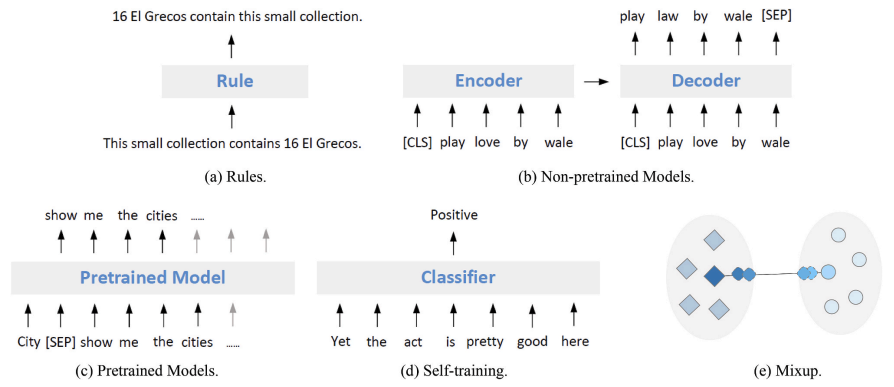
基于采樣的模型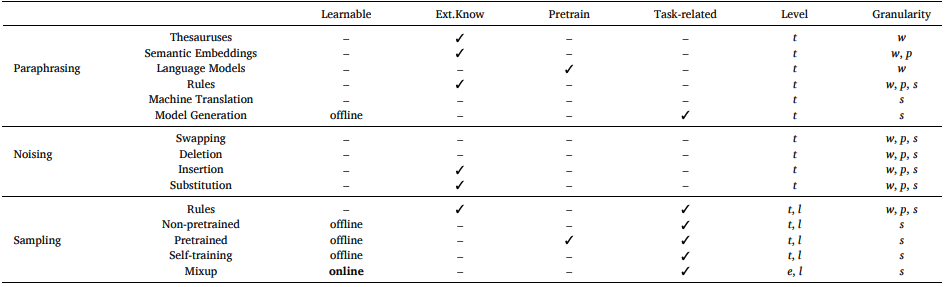
不同DA方法的特點。Learnable表示方法是否涉及模型訓練;online 和 offline 表示 DA 過程是在模型訓練期間還是之后
總結了提高增強數據質量的常用策略和技巧,包括方法堆疊、優化和過濾策略。
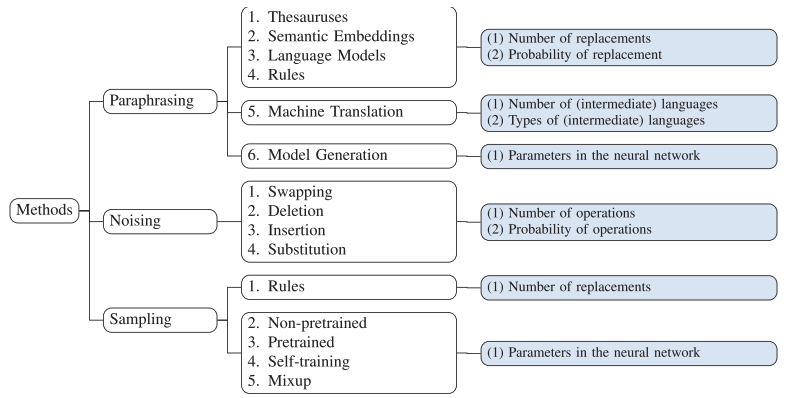
影響每個 DA 方法中增強效果的超參數
分析了上述方法在 NLP 任務中的應用,還通過時間線展示了 DA 方法的發展。



介紹了數據增強的一些相關主題,包括預訓練語言模型、對比學習、相似數據操作方法、生成對抗網絡和對抗攻擊。目標是將數據增強與其他主題聯系起來,同時展示它們的不同之處。
列出了在 NLP 數據增強中觀察到的一些挑戰,包括理論敘述和通用方法,揭示了數據增強未來的發展方向。
公開資源
一些有用的api:
除了英語,也有其他語種的工具資源:
總結
在本文中,作者對自然語言處理的數據增強進行了全面和結構化的調研。為了檢驗 DA 的性質,根據增強數據的多樣性將 DA 方法分為三類,包括改寫、噪聲和采樣。這些類別有助于理解和開發 DA 方法。
還介紹了 DA 方法的特點及其在 NLP 任務中的應用,然后通過時間線對其進行了分析。
此外,還介紹了一些技巧和策略,以便研究人員和從業者可以參考以獲得更好的模型性能。最后,我們將 DA 與一些相關主題區分開來,并概述了當前的挑戰以及未來研究的機遇。
審核編輯:劉清
-
計算機視覺
+關注
關注
8文章
1700瀏覽量
46075 -
自然語言處理
+關注
關注
1文章
619瀏覽量
13616 -
nlp
+關注
關注
1文章
489瀏覽量
22069
原文標題:NLP中關于數據增強的最新綜述
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
MOS管驅動電路綜述
數據融合技術綜述
NLP的介紹和如何利用機器學習進行NLP以及三種NLP技術的詳細介紹

NLP-Progress庫NLP的最新數據集、論文和代碼
NLP 2019 Highlights 給NLP從業者的一個參考
一種單獨適配于NER的數據增強方法
NLP事件抽取綜述之挑戰與展望
基于圖像的數據增強方法發展現狀綜述






 工商網監
工商網監
評論