 NLP的介紹和如何利用機器學習進行NLP以及三種NLP技術的詳細介紹
NLP的介紹和如何利用機器學習進行NLP以及三種NLP技術的詳細介紹
本文用簡潔易懂的語言,講述了自然語言處理(NLP)的前世今生。從什么是NLP到為什么要學習NLP,再到如何利用機器學習進行NLP,值得一讀。這是該系列的第一部分,介紹了三種NLP技術:文本嵌入、機器翻譯、Dialogue 和 Conversations。
▌什么是NLP?
自然語言處理(NLP)是計算機科學、人工智能和語言學的交叉領域。目的是讓計算機處理或“理解”自然語言,以執行諸如語言翻譯和問題回答等任務。
隨著語音接口和聊天機器人的興起,NLP成為了信息時代最重要的技術之一,是人工智能的重要組成部分。充分理解和表達語言的含義是一個極其困難的目標。為什么?因為人類的語言很特別。
人類語言有何特別之處?如下所示幾個方面:
人類語言是一種專門用來傳達說話者(或作者)意圖的系統。這不僅是一個環境信號,也是一種深思熟慮的交流。此外,它使用了一種編碼,小孩可以很快學會。同時它也是會改變的。
人類語言大多是離散的/符號的/分類的信號系統,大概是因為這樣信號可靠性更高。
一種語言的分類符號可以以幾種方式編碼為通信信號:聲音,手勢,書寫,圖像等。人類語言可以用其中任何一種信號表示。
人類語言是不明確的(與編程和其他正式語言不同)。因此,對人類語言的表達、學習和使用語言/情境/語境/詞匯/視覺知識具有高度的復雜性。
▌為什么要學習NLP?
從這個研究領域衍生出一批快速增長的有用的應用程序。它們從簡單到復雜。以下是其中幾個:
拼寫檢查,關鍵字搜索,查找同義詞
分類:學校課文的閱讀水平,長文檔的積極/消極情感分析
機器翻譯
口語對話系統
復雜的問答系統
事實上,這些應用程序已經在工業中得到了廣泛應用:從搜索(書面和口頭)到在線廣告匹配; 從自動/輔助翻譯到營銷或財務/交易的情感分析; 從語音識別到聊天機器人/對話代理(自動化客戶支持,控制設備,訂購商品)。
▌深度學習
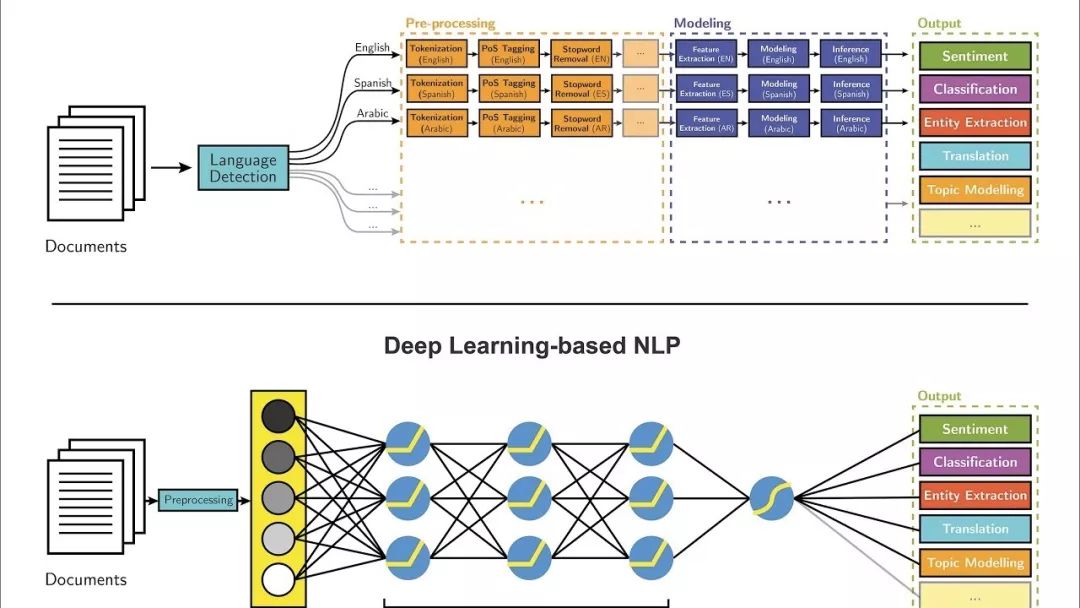
大多數NLP技術都是由深度學習(機器學習的一個子領域)驅動的。在本世紀初,深度學習才開始再次獲得重視,其主要原因如下:
大量的訓練數據。
具有先進功能和改進性能的新模型和算法:更靈活的中間表示學習,更有效的端到端聯合系統學習,更有效的上下文使用和任務之間的轉移學習方法,以及更好的正則化和優化方法。
大多數機器學習方法都能很好地工作,因為人工設計的表示和輸入特征,以及權重優化,從而可以最好地進行最終預測。另一方面,在深度學習中,表示學習試圖自動學習來自原始輸入的良好特征或表示。在機器學習中,人工設計的特性常常被過度指定、不完整,并且需要很長時間來設計和驗證。相比之下,深度學習的學習特點是易于調整和快速學習。
深度學習提供了一個非常靈活,通用且可學習的框架,用于呈現視覺和語言信息的世界。最初,它在語音識別和計算機視覺等領域取得了突破性進展。最近,深度學習方法在許多不同的NLP任務中獲得了很高的性能。這些模型通常可以通過一個端到端模型進行訓練,不需要傳統的、特定于任務的特性工程。
最近,我完成了斯坦福大學的CS224n自然語言處理與深度學習的綜合課程。本課程全面介紹應用于NLP的深度學習的前沿研究。在模型方面,它涵蓋了詞向量表示,基于窗口的神經網絡,循環神經網絡,長-短期記憶模型,遞歸神經網絡和卷積神經網絡,以及一些涉及存儲器組件的最新模型。
在編程方面,我學會了實現,訓練,調試,可視化和創建我自己的神經網絡模型。在這個2部分組成的系列中,我想分享我學到的7種主要的NLP技術,以及使用它們的主要深度學習模型和應用。
注意:您可以在這個GitHub Repo上訪問來自CSS 224的課程和編程作業。
https://github.com/khanhnamle1994/natural-language-processing
▌技術1:文本嵌入(Text Embeddings)
在傳統的NLP中, 我們把單詞看成是離散符號, 然后用一個one-hot向量來表示。向量的維數是整個詞庫中單詞的數量。單詞作為離散符號的問題在于, 對于一個one-hot向量來說,沒有自然的相似性概念。因此, 另一種方法是學習在向量本身中的編碼相似性。核心思想是一個詞的意思是由經常出現在其附近的詞給出的。
文本嵌入是字符串的實值向量表示形式。我們為每個單詞構建一個稠密的向量, 這樣做是以便它與出現在相似上下文中的單詞向量相似。對于大多數深度NLP任務而言,詞嵌入被認為是一個很好的起點。它們允許深度學習在較小的數據集上有效,因為它們通常是深度學習體系結構的第一批輸入,也是NLP中最流行的遷移學習方式。詞嵌入中最流行的方法是Google(Mikolov)的Word2vec和Stanford(Pennington,Socher和Manning)的GloVe。讓我們深入研究這些詞匯表達:
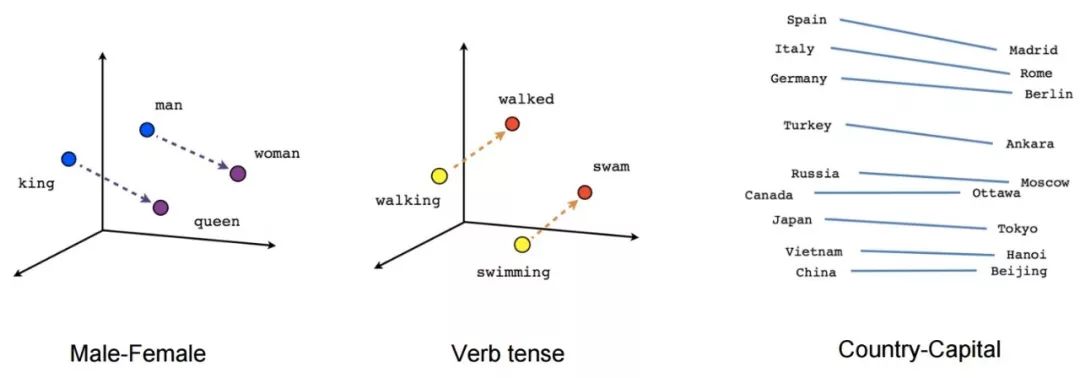
在Word2vec中,我們有一個龐大的文本語料庫,其中固定詞匯表中的每個詞都由一個向量表示。然后我們在文本中遍歷每一個位置t,它有一個中心詞c和上下文詞o。接下來,我們使用c和o的詞向量的相似度來計算給定c的o的概率(反之亦然)。我們不斷地調整詞向量來最大化這個概率。
為了有效地訓練Word2vec,我們可以從數據集中去除無意義(或更高頻率)的單詞(例如a,the,of,then ...)。這有助于提升模型的準確性和減少訓練時間。 此外,我們可以對每個輸入使用negative sampling,即更新所有正確標簽的權重,但只更新少數不正確標簽的權重。
Word2vec有兩個值得注意的模型變體:
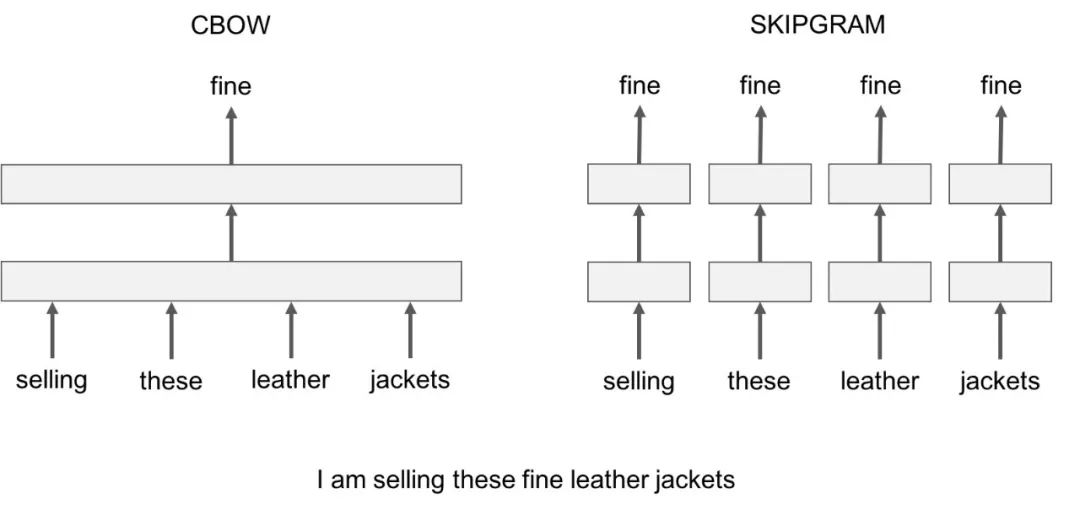
Skip-Gram:我們考慮一個包含k個連續項的上下文窗口。然后我們跳過其中一個詞,嘗試學習一個神經網絡,它獲取除跳過的項之外的所有項并預測跳過的項。因此,如果兩個詞在一個大語料庫中重復地共享相似的上下文,那么這些詞的嵌入向量就是相似的。
Continuous Bag of Words:我們在一個大的語料庫中獲取大量的句子。每當我們看到一個單詞,我們就會聯想到周圍的單詞。然后我們將上下文單詞輸入到一個神經網絡中,并在這個上下文中預測這個中心詞。當我們有數千個這樣的上下文詞和中心詞時,我們就會有一個用于神經網絡的數據集的實例。我們訓練神經網絡,最后編碼的隱藏層輸出表示一個特定的詞嵌入。當我們通過大量的句子進行訓練時,相似上下文中的單詞會得到相似的向量。
Skip-Gram和CBOW的一個不足是它們都是基于窗口的模型,這意味著語料庫的共現(co-occurrence)統計信息沒有得到有效利用,導致次優嵌入(suboptimal embeddings)。GloVe模型試圖通過將一個詞的含義與整個觀察語料庫的結構結合起來,來解決這個問題。
GloVe模型試圖通過捕獲嵌入整個觀察語料庫結構的一個詞的含義來解決這個問題。為了做到這一點,模型對單詞的全局共現數進行訓練,并通過最小化最小二乘誤差來充分利用統計數據,從而產生一個有意義的子結構的詞向量空間。這樣的做法用向量距離來保留了單詞的相似性。
除了這兩種文本嵌入外,還有許多最近開發的高級模型,包括FastText,Poincare Embeddings,sense2vec,Skip-Thought,Adaptive Skip-Gram。我強烈建議大家去看一看。
▌技術2:機器翻譯
機器翻譯是語言理解的經典測試。它由語言分析和語言生成兩部分組成。大型機器翻譯系統有巨大的商業用途,因為全球語言是一個每年400億美元的產業。給你一些值得注意的例子:
谷歌翻譯每天翻譯1000億字。
Facebook使用機器翻譯自動翻譯帖子和評論中的文字,以打破語言障礙,讓世界各地的人們相互交流。
eBay使用機器翻譯技術來實現跨境貿易,并連接世界各地的買家和賣家。
微軟為Android、iOS和亞馬遜Fire的終端用戶和開發人員提供基于人工智能的翻譯,無論他們是否可以訪問互聯網。
早在2016年,Systran就成為首家推出30多種語言的神經機器翻譯引擎的軟件提供商。
在傳統的機器翻譯系統中,我們必須使用平行語料庫——文本的集合,每個文本都被翻譯成一種或多種不同于原文的其他語言。例如,給定源語言f(例如法語)和目標語言e(例如英語),我們需要構建多個統計模型,包括使用貝葉斯規則的概率公式、在平行語料庫上訓練的翻譯模型p(f|e)和在僅限英語語料庫上訓練的語言模型p(e)。
不用說,這種方法忽略了數百個重要的細節,需要大量的人工特征工程,由許多不同的和獨立的機器學習問題組成,總體而言是一個非常復雜的系統。
神經機器翻譯是通過一個稱為遞歸神經網絡(RNN)的大型人工神經網絡對整個過程進行建模的方法。 RNN是一個有狀態的神經網絡,它和過去通過時間來連接。神經元的信息不僅來自上一層,而且來自更前一層的信息。這意味著,我們輸入和訓練網絡的順序很重要:輸入“Donald”,然后輸入“Trump”,可能會產生與輸入“Trump”和輸入“Donald”不同的結果。
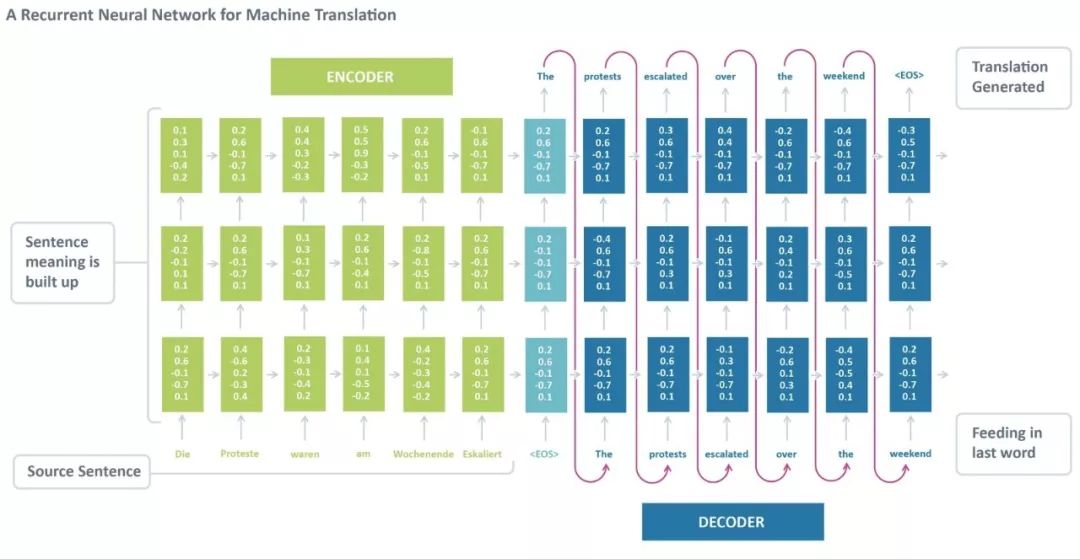
標準的神經機器翻譯是一種端到端神經網絡,源語句由一個稱為編碼器(encoder)的RNN編碼,目標詞使用另一個稱為解碼器(decoder)的RNN進行預測。RNN編碼器逐個讀取一個源語句,然后在最后的隱藏狀態匯總整個源語句。RNN解碼器使用反向傳播學習這個最后的匯總并返回傳播后版本。神經機器翻譯從2014年作為一項邊緣研究活動發展到2016年成為被廣泛采用的機器翻譯的主流方式,這一過程令人驚嘆。那么,使用神經機器翻譯的最大優勢是什么?
端到端訓練:NMT中的所有參數都被同時優化,以最小化網絡輸出上的損失函數。
分布式表示具有優勢:NMT更好地利用單詞和短語的相似性。
更好地探索上下文:NMT可以使用更多的上下文——源文本和部分目標文本——來更準確地翻譯。
更流暢的文本生成:深度學習的文本生成比平行語料庫的生成質量高得多。
RNNs的一個大問題是梯度消失(或爆炸)問題,其中取決于所使用的激活函數,隨著時間的推移信息會迅速丟失。直觀地說,這不會是一個很大的問題。因為這些只是權重而不是神經元狀態,但是時間的權重實際上是存儲過去信息的地方;如果權重達到了0或1,000,000,那么前面的狀態將不會提供很多信息。因此,RNNs在記憶之前的單詞非常困難,并且只能根據最近的單詞做出預測。
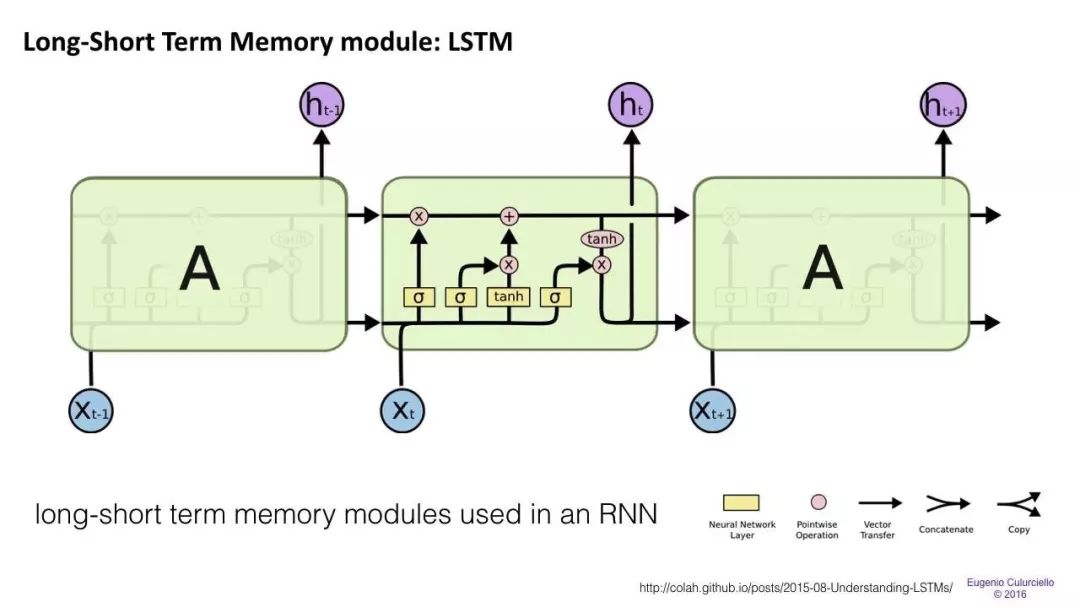
長/短期記憶(LSTM)網絡試圖通過引入門(gate)和明確定義的記憶單元(memory cell)來解決梯度消失/爆炸問題。每個神經元都有一個memory cell和三個gate:input,output和forget。這些門的功能是通過停止或允許信息流來保護信息。
input gate確定來自前一層的信息有多少存儲在單元中。
輸出層接受另一端的任務,并確定下一層有多少人知道這個單元的狀態。
forget gate的作用起初看起來有點奇怪,但有時最好還是忘掉:如果是學習一本書,翻開新的一章,那么網絡可能有必要忘掉前一章中的一些人物。
LSTMs已經被證明能夠學習復雜的序列,比如像莎士比亞一樣進行寫作或創作原始的音樂。請注意,這些門中的每一個都對前一個神經元中的一個單元具有權重,因此它們通常需要更多資源才能運行。LSTM目前非常流行,并且在機器翻譯中被廣泛使用。除此之外,它是大多數序列標簽任務的默認模型,其中有大量的數據。
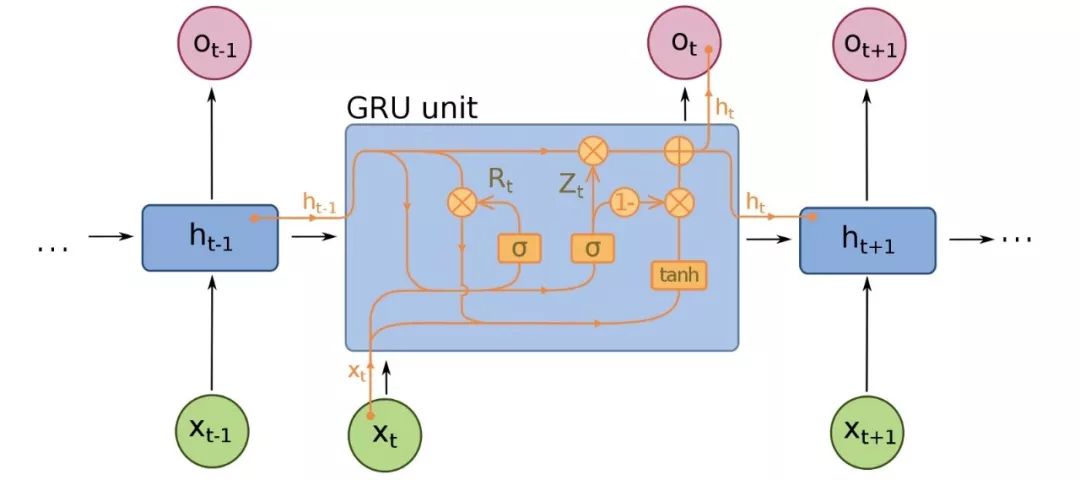
Gated recurrent units(GRU)是LSTMs的一個微小變型,也是神經機器翻譯的擴展。它們少了一個gate,連線方式略有不同:它們沒有一個input、output和一個forget gate,而是一個update gate。這個update gate決定從上一個狀態保存多少信息,以及從上一個層輸入多少信息。
reset gate的功能與LSTM的forget gate非常相似,但位置稍有不同。它們總是發送它們的全部狀態——它們沒有輸出門。在大多數情況下,它們的功能與LSTMs非常相似,最大的區別是GRUs稍微快一些,更容易運行(但也更不容易表達)。在實踐中,這些往往會互相抵消,因為你需要一個更大的網絡來重新獲得一些表示能力,這反過來又抵消了性能優勢。在一些不需要額外表示的情況下,GRU可以勝過LSTM。
除了這三種主要體系結構之外,近年來神經機器翻譯系統也有了進一步的改進。以下是最顯著的發展:
Sequence to Sequence Learning with Neural Networks【1】證明了LSTM在神經機器翻譯中的有效性。它提出了序列學習的一種通用的端到端方法,對序列結構進行了最少的假設。該方法使用多層Long Short Term Memory(LSTM)將輸入序列映射為固定維度的向量,然后再通過另一個深度LSTM對目標序列進行解碼。
Neural Machine Translation by Jointly Learning to Align and Translate【2】引入了NLP中的注意力機制(將在下一篇文章中介紹)。認識到使用固定長度的向量是提高NMT性能的瓶頸,作者建議通過允許模型自動(軟)搜索與預測目標相關的源句子來進行擴展,而不必將這些部分明確地形成為一個固定的長度。
Convolutional over Recurrent Encoder for Neural Machine Translation【3】在NMT標準RNN編碼器中增加了卷積層,以便在編碼器輸出中捕獲更廣泛的上下文。
谷歌建立了自己的NMT系統,稱為Google’s Neural Machine Translation【4】,它解決了準確性和部署方便性方面的許多問題。該模型由一個深度LSTM網絡組成,該網絡包含8個編碼器和8個解碼器層,使用殘差連接以及從解碼器網絡到編碼器的注意力連接。
Facebook AI研究人員不使用遞歸神經網絡,而是使用卷積神經網絡【5】序列對NMT中的學習任務進行排序。
▌技術3:Dialogue 和 Conversations
關于會話AI的文章很多,其中大部分集中在垂直聊天機器人、messenger平臺、商業趨勢和創業機會(比如亞馬遜Alexa、蘋果Siri、Facebook M、谷歌助理、微軟Cortana)。人工智能理解自然語言的能力仍然有限。因此,創建完全自動化的開放域會話助理仍然是一個開放的挑戰。盡管如此,以下所示的工作對于那些想要尋求對話人工智能下一個突破的人來說是一個很好的起點。

來自蒙特利爾、佐治亞理工學院、微軟和Facebook的研究人員建立了一個神經網絡,能夠產生上下文敏感的對話反應。這種新型的響應生成系統可以在大量非結構化的Twitter對話中進行端到端訓練。當將上下文信息集成到經典的統計模型中時,使用一個遞歸的神經網絡架構來解決稀疏性問題,使系統能夠考慮到以前的對話。該模型顯示了對上下文敏感和非上下文敏感的機器翻譯和信息檢索baseline的一致好處。
神經應答機(NRM)是在香港開發的一種基于神經網絡的短文本對話響應發生器。它采用通用的編碼-解碼框架。首先,它將響應的生成形式化為基于輸入文本潛在表示的解碼過程,而編碼和解碼都是通過遞歸神經網絡實現的。NRM通過從微博服務收集的大量一輪談話數據進行訓練。實證研究表明,NRM能夠對超過75%的輸入文本產生語法正確和內容恰當的響應,在相同的環境下表現優于現有技術。
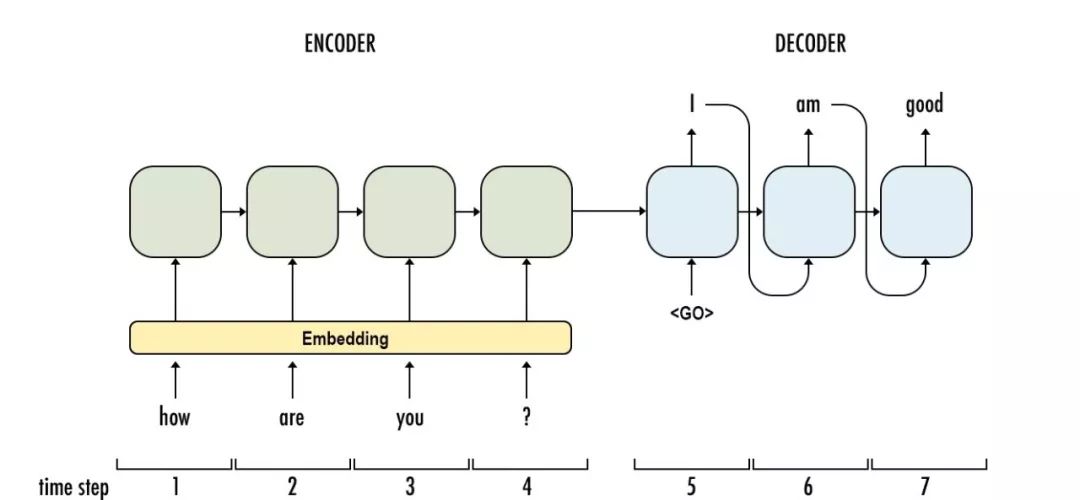
最后,谷歌的神經會話模型(Neural Conversational Model)是會話建模的一種簡單方法。它使用序列到序列(sequence-to-sequence)的框架。該模型通過預測會話中給定前一句的下一句進行對話。該模型的優點在于可以進行端到端的訓練,因此需要更少的手工規則。
給出一個大型的會話訓練數據集,該模型可以生成簡單的會話。它可以從特定領域的數據集以及電影字幕的大的、有噪聲的、通用的領域數據集中提取知識。在特定于域的IT help-desk數據集上,該模型可以通過對話找到技術問題的解決方案。在嘈雜的開放域電影副本數據集上,該模型可以執行簡單形式的常識推理。
-
機器學習
+關注
關注
66文章
8438瀏覽量
132918 -
機器翻譯
+關注
關注
0文章
139瀏覽量
14922 -
nlp
+關注
關注
1文章
489瀏覽量
22068
原文標題:這7種NLP黑科技讓你更好交流!來看一看是什么(Part1)
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ChatGPT爆火背后,NLP呈爆發式增長!
對2017年NLP領域中深度學習技術應用的總結
NLP中的深度學習技術概述






 工商網監
工商網監
評論