 幾種常用的NLP數據增強方法
幾種常用的NLP數據增強方法
當訓練數據量不充分,或者分布單一的情況下,數據增強可以快速擴充語料以避免過擬合的問題。同時,數據增強也可以提升模型的魯棒性,避免微弱的變化使得模型無法泛化到相似的語境中。
機器學習和深度學習在包括文本分類等自然語言任務達到不錯的效果,但他們 需要依賴于大規模的標注數據 ,除了直接使用小樣本學習外,顯式數據增強格外有效;
數據增強在計算機視覺中得以應用,其可以在數據量很少的情況下提升模型的魯棒性;而在NLP中,通用的文本類型的數據增強 還沒有完全被挖掘出來 ;
本文介紹幾種比較簡單但常用的NLP數據增強方法,包括顯式和隱式兩個方面,在實驗或比賽中可以提升效果。可使用nlpaug[1]工具快速實現這些技術。
顯式數據增強
給定一個輸入文本,在盡可能不改變原是文本語義的情況下,微調或修改部分字符或詞可以實現快速的增強,主要包括如下幾種類型:
同義詞替換 (SR) :隨機挑選n個 非停用詞 ,分別根據其 同義詞表 隨機替換一個同義詞;
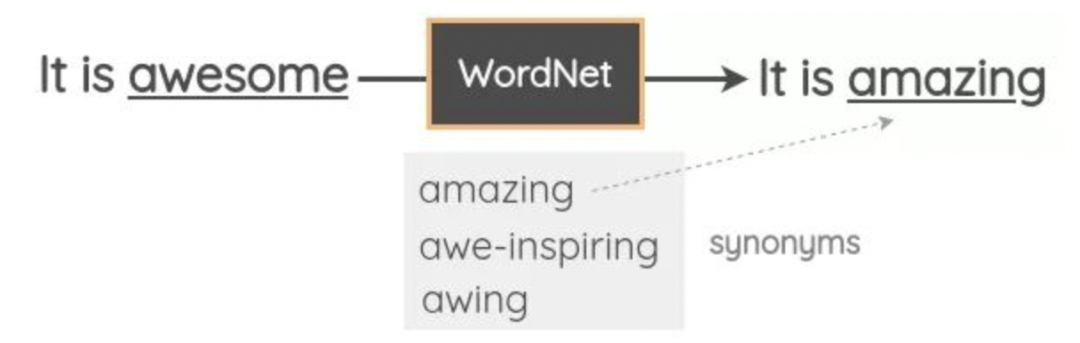
對于分類、回歸等任務,可以使用反義詞表替換所有原始詞性的詞,實現負采樣,也是一種數據增強方法。但使用同義詞或反義詞表進行替換時,很難保證文本的語義是否符合預期。
隨機插入 (RI) :在句子中隨機找到一個 非停用詞 ,并隨機選擇其對應的一個同義詞,將該同義詞插入句子中的 隨機位置 。重復執行 n n n 次;
隨機交換 (RS) :在句子中隨機挑選兩個詞,并 交換位置 ,重復執行 n n n 次;
隨機刪除 (RD) :對每個詞,有一定概率 p p p 進行 刪除 ;
標點插入 (PI) :隨機挑選若干位置,并分別隨機插入 標點符號 ;
由于輸入的文本長度長短不一,直覺上希望較長的句子 n 較大,因此通過一個參數 α 控制,即 ,對于 RD ,概率 。
本文對標點插入 PI 進行了實現,以中文為例,如下所示:
借助Spacy分詞工具,需要安裝Spacy,使用Spacy進行分詞、分析詞性,根據分詞和詞性選擇需要插入的標點。
標點符號可以選擇 ,。?!;“ ” 等。
importnumpyasnp importspacy importrandom fromtypingimportDict fromtqdmimporttqdm classDataAugmentation: def__init__(self): self.nlp=spacy.load('zh_core_web_sm') deffit(self,examples:Dict[str,list]): self.examples=examples#{'text':[],'label':[],'id':[]} #簡單的數據增強:增加標點符號 text_list=self.examples['text'] label_list=self.examples['label'] id_list=self.examples['id'] aug_text_list,aug_label_list,aug_id_list=[],[],[] pun=[',','。','?','!',';','"'] foreiintqdm(range(len(text_list))): text=text_list[ei] label=label_list[ei] id=label_list[ei] doc=self.nlp(text)#spacy分詞 token_list,pos_list=[],[] fortokenindoc: token_list.append(token.text) pos_list.append(token.pos_) iflen(token_list)-1>=1: num=0 state=False whilenum
演示效果:
除了前述的幾種方法,也可以采用如下幾種新的策略:
單詞縮寫、全寫:例如可以建立一個詞表,對所有存在簡寫的詞進行替換,例如 It is可以替換為 It’s,England可替換為UK.等;
錯誤拼寫 (WS) :有時候為了提高魯棒性,會故意將文本中的單詞或字符使用錯誤拼寫的單詞或字符進行替換,在不影響語義的條件下 引入少量噪聲 。例如 I like this book可以替換為 I like thes book。對于中文,也可以構建confusion set,替換字形或字音相似的詞,例如“上海是經濟中心”可以替換為“上海時經濟中心”。但注意需要保證原始語義。
統計特征 (SF) :通常很多詞在大規模語料中具有一定的統計特征,例如TF-IDF、互信息量等。在使用TF-IDF和互信息量時,可選擇值較小的進行隨機替換。
隱式數據增強
因為直接對原是文本進行數據增強,很難保證維持原始的文本語義,因此可以通過在語義空間上進行隱式數據增強,簡單列出幾種方法:
詞向量替換 :通過word2vec或GloVe預訓練的詞向量獲得相似的詞,對于給定某個詞,則可以直接隨機選擇相似的詞的詞向量進行替換;
詞向量的原型向量: 通過word2vec或GloVe預訓練的詞向量,可以通過對所有相似的詞或token的embedding進行平均池化。一般認為語義相似的詞在語義空間內會聚集在一起,因此其平均的詞向量可以認為是這些相似語義詞的 原型向量(prototype embedding) ,原型向量可以作為隱式增強表征;
Dropout: 在對文本使用RNN、CNN或BERT等進行表征后,得到融合上下文信息的embedding,可以采用 隨機dropout法 。具體地說,假設一個embedding是 [0.1, 0.4, 0.2, -0.5], 隨機dropout旨在隨機挑選一個元素替換為0,例如挑選第2個位置的元素替換為0,變為 [0.1, 0.0, 0.2, -0.5]。隨機dropout參考了計算機視覺領域內對圖像表征后的feature map進行mask的操作(在語義特征上添加噪點)以實現增強;
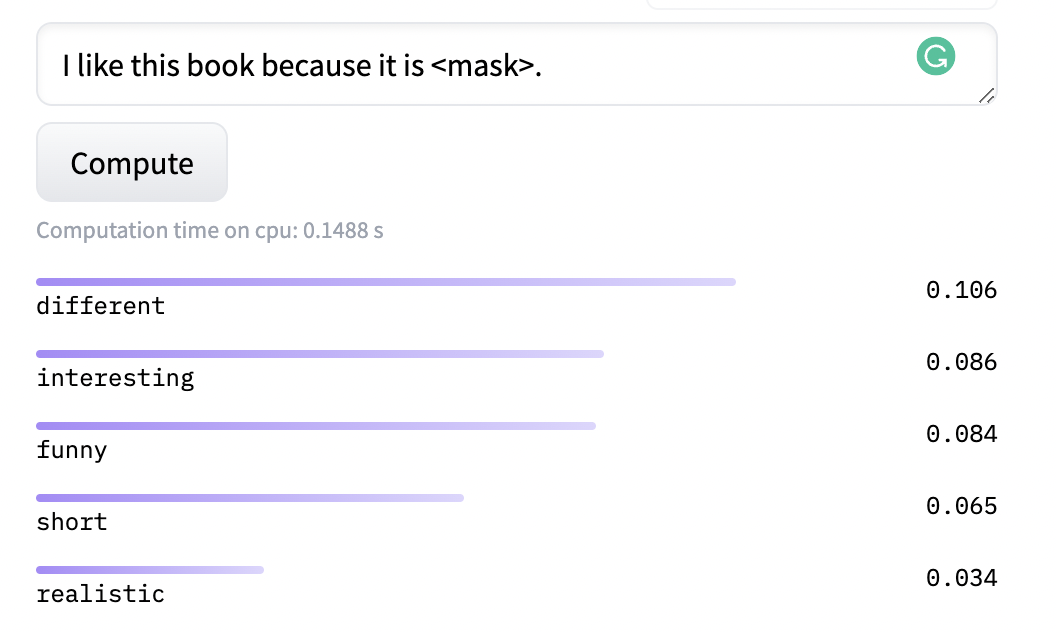
語言模型 Masked Language Modeling(MLM): MLM是BERT等預訓練語言模型在大規模語料上自監督訓練目標,其旨在隨機挖掉一個文本中的token并讓模型預測該詞。由于大規模訓練,使得模型可以預測出許多相似的結果,例如“I like this book because it is funny.”,我們可以讓MLM生成與“funny”具有同等語義的詞:
機器翻譯: 基于機器翻譯的方法,將原始文本翻譯為另一種語言,并再次進行回譯。該方法比較類似計算機視覺中的自編碼器。但該方法需要率先在領域數據上進行訓練,且依賴于大量的平行語料,較為繁瑣;
文本生成: 基于生成的方法可以在不改變原始語義的前提下生成出上述無法顯式構造的新文本。但基于生成的方法依然依賴于所屬領域的訓練數據。
如果需要增強的文本所屬一個新的領域(例如醫療、生物),基于翻譯和生成的方法則需要先在該領域的相關語料上進行訓練,得到較為魯棒的翻譯或生成模型。但數據增強又是為了增強數據量,沒有充分又無法訓練翻譯或生成模型,產生矛盾。因此通常對新的領域或任務上不會首選這兩種方法。
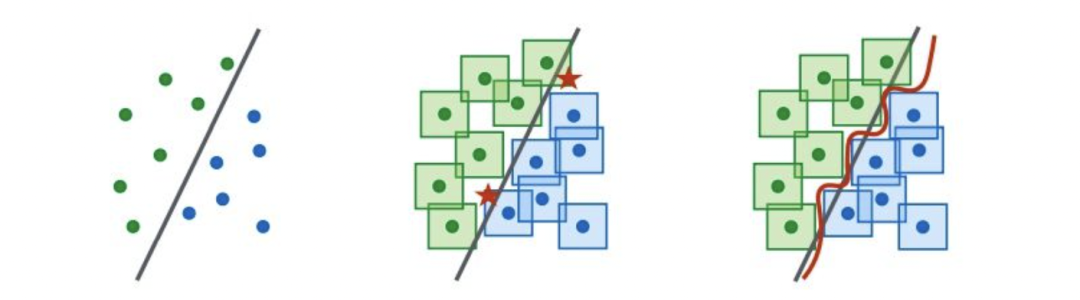
對抗訓練: 引入對抗樣本實現數據增強,例如下圖(左)是少量樣本時學習的決策邊界,對每個樣本在一定范圍內進行擾動攻擊,使得在直觀上無法辨別,但在語義空間內則會影響樣本的決策,例如下圖(中),五角星則代表對抗樣本。因此圖(右)引入對抗訓練目標以修改決策邊界。通常對抗訓練目標可以是對增強的樣本偽造其標簽以增強魯棒性。
對比學習: 如果樣本少,那就盡可能學習這些樣本之間的差異。對比學習旨在構建樣本對來解決訓練困難問題,因為構建了樣本對,所以間接地增加了數據量。雖然對比學習最初目標不是為了數據增強,但可以通過添加對比學習loss來隱式地提升魯棒性;
自監督輔助任務: 如果目標NLP數據量少,那么可以直接引入大規模無監督語料(例如Wikipedia),并在具體任務訓練時添加輔助學習目標,通過語義層面上實現增強;
例如在進行文本分類任務上時,除了文本分類損失函數外,還可以添加類似MLM的輔助任務,或者添加額外的多任務信息
知識圖譜增強(遠程監督法): 遠程監督可以快速地啟發式構建大規模標注數據,目前在信息抽取任務上使用廣泛,其旨在通過一個已有的知識圖譜或規則來直接對無監督的語料進行標注,但遠程監督方法容易引入大量噪聲。
在關系抽取任務中,通過知識庫中已有的三元組(例如<喬布斯,創始人,蘋果>),來標注一批新的實體對語料。但對于文本“喬布斯吃了一個蘋果”而言,遠程監督法依然會標注為“創始人”,但顯然這是噪聲。對于噪聲,則可以通過一些規則,或Attention的方法解決。
半監督方法: 半監督法旨在對少量有標簽數據上進行訓練,然后在無標簽數據上進行推理,并獲得高置信度的偽標簽數據后,再進行訓練。因此偽標簽數據可以作為數據增強部分語料,但依然容易引入噪聲。
對于噪聲部分,則可以采用幾種策略:(1)提高置信度閾值,(2)多個不同的模型共同預測偽標簽,取全部預測正確的作為可信樣本;(3)偽標簽數據回測評估:如果加入偽標簽的數據后效果變差,則需要剔除或更改標簽。
審核編輯:彭靜

-
數據
+關注
關注
8文章
7048瀏覽量
89068 -
語言模型
+關注
關注
0文章
526瀏覽量
10277 -
nlp
+關注
關注
1文章
488瀏覽量
22039
原文標題:NLP中的數據增強方法!
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論