 深度學習在目標檢測中的應用
深度學習在目標檢測中的應用
二階段目標檢測算法(RCNN 家族)是目標檢測中最經典的算法之一,有 R-CNN -> Fast R-CNN -> Faster R-CNN,每一代的變化以及目的性都明確,也是目標檢測領域二階段檢測必會的算法之一。
如果想對目標檢測有粗略的了解請查看這兩篇文章:
目標檢測綜述
目標檢測快速入門(含YOLO V1原理詳解)
深度學習在目標檢測應用
R-CNN 算法在 2014 年提出,可以說是歷史性的算法,將深度學習應用于目標檢測領域,相較于之前的目標檢測方法,提升多達 30% 以上,大大提高了目標檢測效果,改變了目標檢測領域的研究方向。
早在 2010 年,深度學習已經初露鋒芒,為什么在 2014 年目標檢測才可以說正式應用深度學習技術呢?
這要從目標檢測的場景以及目的上來分析。將問題簡化一下,假設現在在做貓和狗的檢測,要從圖片中找到貓和狗的位置并且知道是什么分類。對于人工智能問題,往下細分可以分到 2 個方向,分類問題和回歸問題。識別一張圖片是貓還是狗是比較容易的事情,也可以準確的說是分類問題。
但是尋找到圖片中不確定是否含有以及不確定具體數量的貓和狗的具體位置,這樣的一個問題算作哪個類別呢?分類和回歸問題都不好往上面靠,下面再把問題拆分一下。
目標檢測中的分類與回歸問題
假設,現在已經有框了,如圖 1 所示,根據 4 個檢測框內是否包含狗做分類,包含待檢測目標越完整、背景越少則概率越高,下圖中顯然藍色更加合適。
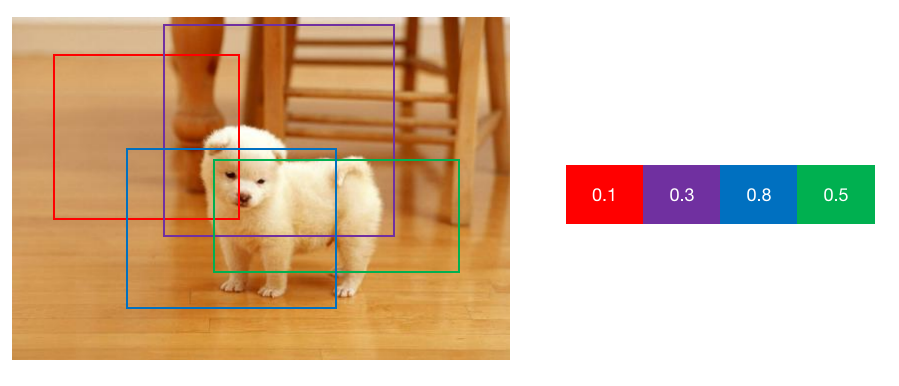
圖1 目標檢測示意
用藍色的檢測框來代表檢測的物體還有個問題,就是這個框還有些許的偏差,離“完美”的檢測框還是有一些距離,下面可以對我們的檢測框進行矯正回歸,如圖 2 所示。白色的框是“完美檢測框”,我們希望藍色的檢測框向白色的檢測框從形狀和位置上靠近,在某些特殊條件下,這種變換滿足線性的變化,將邊框的矯正問題轉變成一個回歸問題。
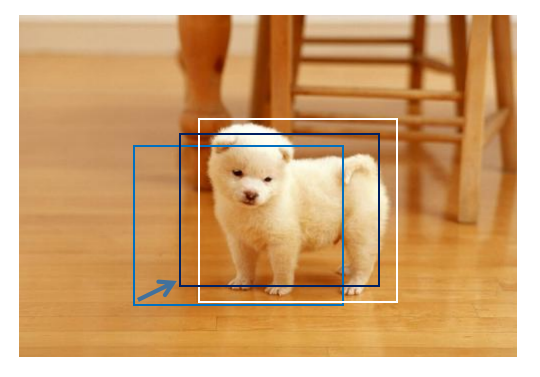
圖2 邊框矯正示意圖
現在目標檢測問題得到了解決,前提是已經存在可能存在待檢測物體的預選框,剩下的問題是如何產生這些預選框。
R-CNN 算法就是采用上面所述的解決思路,采用的是選擇性搜索 (Selective Search) 算法來選擇預選框。
選擇性搜索 (Selective Search) 提取候選區域
選擇性搜索 (Selective Search) 是對上文中的選擇區域過程進行的一個優化。Selective Search 算法在 13 年提出,這個算法其實是借鑒了層次聚類的思想,將層次聚類的思想應用到區域的合并上面。
首先使用 Felzenszwalb 等人在其論文 “Efficient Graph-Based Image Segmentation ” 中描述的方法生成輸入圖像的初始子候選區域。
然后將較小的相似區域遞歸組合為較大的相似區域。這里使用貪婪算法將相似的區域組合成更大的區域。
所謂貪婪算法就是從一組區域中,選擇兩個最相似的區域,將它們合并為一個較大的區域,重復上述步驟進行多次迭代,直至數量為我們想得到的候選區域數量。
選擇性搜索的思想是基于圖像中物體可能具有某些相似性或者連續性,因此采用子區域合并的方法進行提取候選邊界框,合并過程根據子區域之間的顏色、紋理、體積等相似性進行區域合并,最后合并成我們想要的數量,然后再對子區域做外切矩形,得到的矩形就是候選區域。
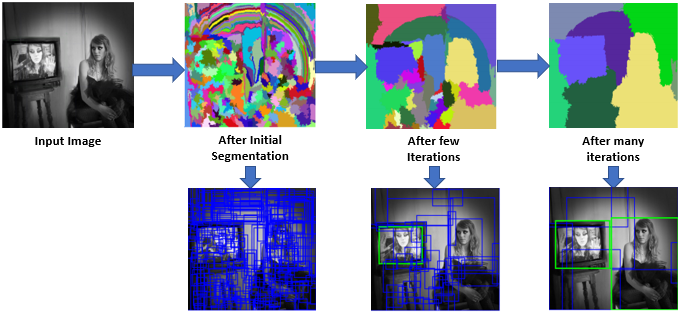
圖3 Selective Search示意圖
R-CNN:Region with CNN feature (Region proposals + CNN)
R-CNN 算法流程可以分為 4 步:
使用選擇性搜索 (Selective Search) 從圖像中提取 1k-2k 個區域,將其稱為候選區域。
將這 2000 個大小可能不同的候選區域處理成固定大小 (227,227),然后輸入到卷積神經網絡中做圖像特征提取,生成 4096 維特征圖作為第二步輸出。
將特征圖輸入到一組 SVM 中,對候選區域是否存在要檢測的目標進行分類,每個 SVM 都是一個二分類器,負責判斷是否是存在某一個類 (yes/no),也就是說有多少個分類就有多少個SVM分類器。
除了預測候選區域內是否包含檢測目標,該算法還預測四個值,這些值是偏移值,以提高邊界框的精度。
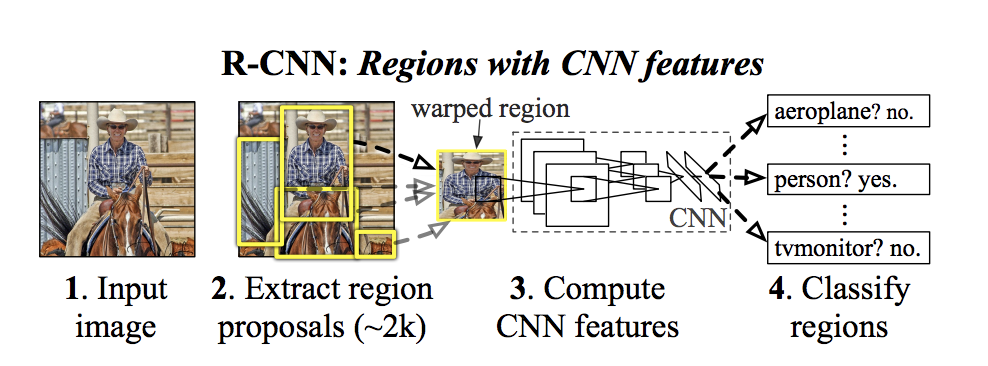
圖4 RCNN示意圖
統一候選區域尺寸
通過前面的內容,可以在圖片中找出想得到的候選區域,這個候選區域不一定都是同樣的大小,如果進行簡單的縮放到同一尺寸,會造成不同的拉扯程度,同一張圖片選出的候選框進行了不同程度的變形會對結果造成影響。
選擇性搜索最終產出的是矩形,論文中對矩形的縮放嘗試了兩種方式:各向同性縮放、各向異性縮放。

圖5 RCNN-圖像尺寸統一處理示意圖
上圖 5 中 B 列,直接在原始圖片中,把邊界擴展延伸成正方形,然后再進行裁剪;如果已經延伸到了原始圖片的外邊界,那么就用候選框中的顏色進行填充;C 列,先沿邊框進行剪裁,然后用固定顏色填充成正方形,這個固定顏色為候選框內顏色均值;D 列方法很簡單,不管候選區域的寬高比,直接進行縮放。
在此基礎上,作者還嘗試了加入 padding 處理,示意圖中第一、三行是使用了padding=0 的效果,第二、四行使用了 padding=16 的效果。經過測試發現,使用各向異性縮放結合 padding=16 的精度最高,使 mAp 提高了 3 到 5 個百分點。
在網絡結構方面,R-CNN 對比現在流行的網絡顯得略微“單薄”。方案選擇上面有 2 個選擇:Alexnet 與 VGG16。從表現來說 VGG16 的表現效果會更好一些,VGG16 有較小的卷積核以及較小的步長,泛化能力更強,但是計算量是 Alexnet 的 7 倍。
Fast R-CNN:Towards Real-Time Object Detection with Region Proposal Networks
站在現在的目標檢測技術角度去看 R-CNN,可能會覺得這個模型表現的并不是很好,設計的也不夠合理,但是在當時 R-CNN 將深度學習引入檢測領域,一舉將 PASCAL VOC 上的檢測率從 35.1% 提升到 53.7%。
R-CNN 也存在著非常大的問題,首先三個模型在訓練的方面會是個比較大的挑戰,其次也是最主要的就是效率問題,計算 Region Proposals 和 features 平均所花時間:13s/image on a GPU;53s/image on a CPU。最后 2000 個左右的候選區域都需要經過網絡處理,這就加大了計算代價。
已經定位了 R-CNN 的計算瓶頸,那么解決方法也就應運而生,R-CNN 的同一作者解決了R-CNN 的一些缺點并提出了新的算法,該算法稱為 Fast R-CNN。
Fast R-CNN 算法發表于 2015 年,在同樣使用 VGG16 網絡作為 Backbone 的情況下,與 R-CNN 相比訓練速度快 9 倍,推理時間快了 200 多倍,在 Pascal VOC 數據集上準確率也從 62% 提升到了66%。
整體思路類似于 R-CNN 算法,與之不同的是,不再用候選區域選出來再傳入網絡中,Fast R-CNN 將輸入圖像直接提供給 CNN 結構來生成卷積特征圖,在原圖中使用 SS(Selective Search) 算法提取候選區域,映射到特征圖上形成特征矩陣,這樣看似簡單的調整順序,從需要對 1k-2k 張圖像提取特征轉變成只需要對一張圖像提取特征,極大的減少了執行時間。
但是新的問題也出來了,對特征圖進行預選區域選擇后產出的“小特征圖”大小不一,無法一下放入網絡中進行處理與預測。Fast R-CNN 借鑒了 SPP Net 的設計來解決這個問題。
SPP:Spatial Pyramid Pooling(空間金字塔池化)
SPP-Net 是出自 2015 年發表在 IEEE 上的論文:《Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition》,SPP 是其中核心的設計。
CNN 一般都有卷積部分和全連接部分,其中,卷積層不需要固定尺寸的圖像,而全連接層是需要固定大小的輸入。
所以當全連接層面對各種尺寸的輸入數據時,就需要對輸入數據進行 crop(crop 就是從一個大圖摳出網絡輸入大小的 patch,比如 227×227),或 warp(把一個邊界框 bounding box 的內容 resize 成 227×227)等一系列操作以統一圖片的尺寸大小,比如 224×224(ImageNet)、32×32(LenNet)等。
在 R-CNN 中,因為取出的區域大小各自不同,所以需要將每個 Region Proposal 縮放(warp)成統一的 227x227 的大小并輸入到 CNN。但 warp/crop 這種預處理,導致的問題要么被拉伸變形、要么物體不全,限制了識別精確度。如圖 6 所示,原本“瘦高”的燈塔,warp 之后體型“發福”了。

圖6 圖像伸縮示意圖
SPP Net 開拓了新的思路,原來的思路是在進入 CNN 中之前,將圖像統一尺寸,而 CNN 本身可以適應任何尺寸,那么何不嘗試在 CNN 結構之后再加入某種結構使后面的全連接層可以接收到固定的輸出呢?
下圖便是 R-CNN 與 SPP Net 檢測流程的對比:

圖7 R-CNN與SPP Net流程對比
在卷積結構與 FC 層之間介入金字塔池化層,保證下一層全連接層的輸入固定。換句話說,在普通的 CNN 結構中,輸入圖像的尺寸往往是固定的(比如 224×224 像素),輸出則是一個固定維數的向量。SPP Net 在普通的 CNN 結構中加入了 ROI 池化層(ROI Pooling),使得網絡的輸入圖像可以是任意尺寸的,輸出則不變,同樣是一個固定維數的向量。
Fast R-CNN 中的 ROI Pooling
Fast R-CNN 使用 ROI Pooling 結構將 CNN 結構輸出統一成 7×7 的結構,這個過程并不復雜,如圖 8 所示,左面假設是特征圖(為了可視化使用圖像代替),將特征圖劃分成 7×7 的網格 ,對每一個網格用 Max Pooling 得到 7×7的 結構,圖中使用一個 channel 數據示例,實際計算中對每個 channel 做如下處理。

圖8 ROI Pooling示意圖
在訓練過程中,并不是所有 SS 算法獲取的候選框都被使用,相對于選擇的 1k-2k 個候選框,只需要其中的一小部分, 從中選擇正樣本和負樣本,正樣本指包含需要檢測的目標,而負樣本不包含需要檢測的目標,也就是背景。
為什么要分正樣本與負樣本,對于選擇出的 1k-2k 個候選區域,絕大部分只會有很小的一部分里面包含需要檢測的物體,大部分都是背景,如果全部使用包含圖像的樣本進行訓練,會對網絡產生不好的影響。區分正負樣本的條件是與 GT 的 IOU 大于 0.5 的為正樣本,反之為負樣本。
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Faster R-CNN 的設計思路
經過前面兩個網絡的積累 (Fast R-CNN 與 R-CNN),Ross B.Girshick 在 2016 年提出了新的改進版算法 Faster R-CNN,盡管 Fast R-CNN 已經對 R-CNN 的速度進行了大幅度的優化,但是在其結構中還是有明顯的瓶頸,Fast R-CNN 的整體結構并不緊湊,先使用卷積神經網絡結構進行特征提取,篩選候選區域再進行預測。
在 Faster R-CNN 中,引入了 Region Proposal Network(RPN),RPN 網絡與檢測網絡共享完整的圖像卷積特征,從而大大降低了 region proposal 的代價。RPN 是一個 FCN 結構的網絡,可以同時預測每個位置上的對象范圍和對象得分。RPN 網絡不是單獨的網絡而是融合在整個網絡之中,這樣更容易訓練出好的效果。
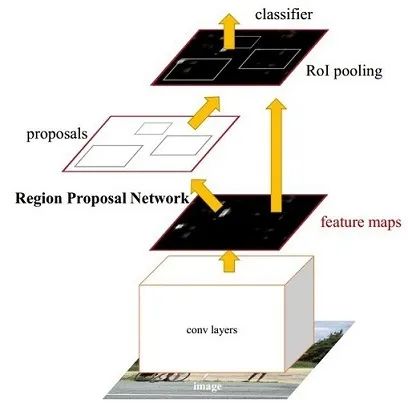
圖9 Faster R-CNN結構圖
代碼結構
除了 RPN 結構,Faster R-CNN 與 Fast R-CNN 結構一致,這里不再過多的介紹基礎,在前期對 Faster R-CNN 有初步的認識即可,下面給出 Faster R-CNN 實現的代碼結構圖。
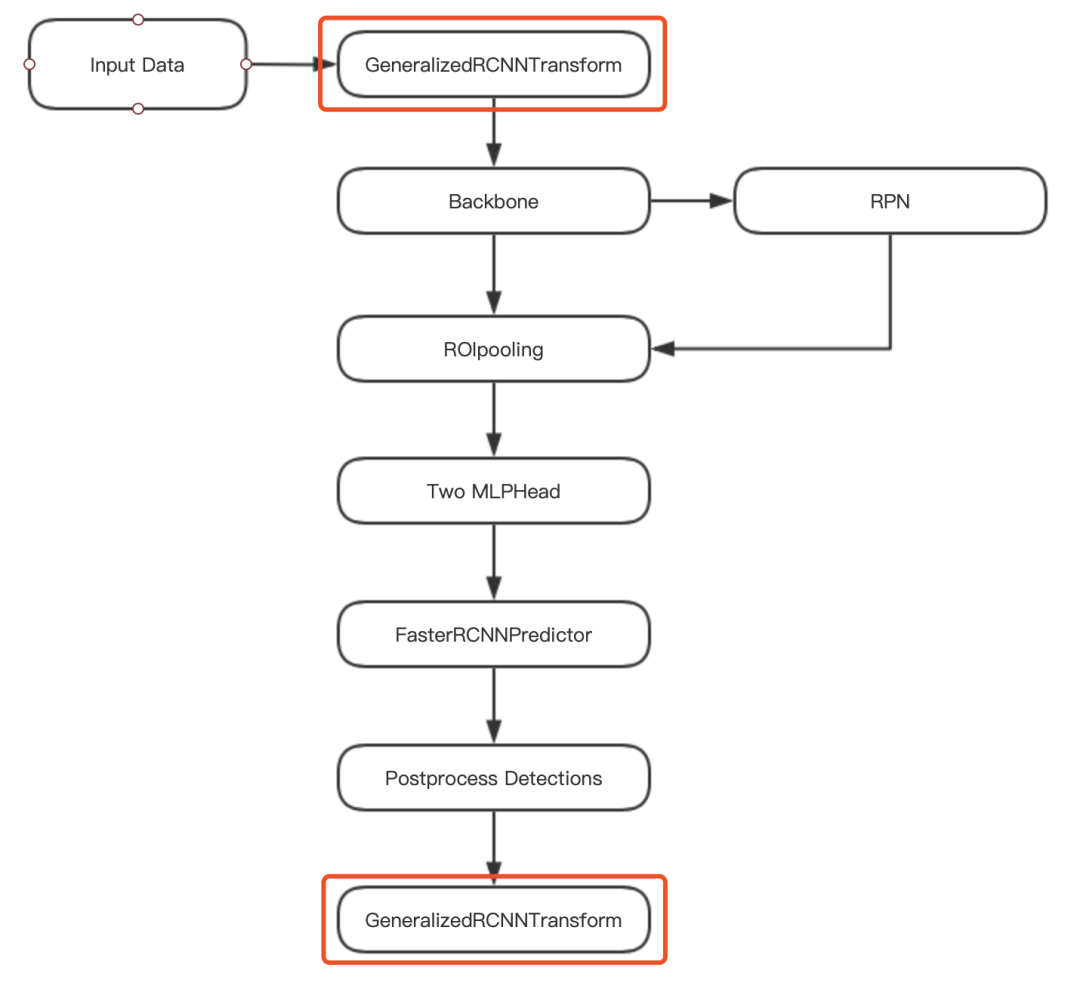
圖10 Faster R-CNN代碼結構
審核編輯:劉清
-
SVM
+關注
關注
0文章
154瀏覽量
32493 -
分類器
+關注
關注
0文章
152瀏覽量
13200 -
voc
+關注
關注
0文章
105瀏覽量
15695
原文標題:通俗易懂詳解二階段目標檢測
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
GPU在深度學習中的應用 GPUs在圖形設計中的作用
NPU在深度學習中的應用
慧視小目標識別算法 解決目標檢測中的老大難問題

基于AI深度學習的缺陷檢測系統
深度學習在視覺檢測中的應用
深度學習在自動駕駛中的關鍵技術
深度解析深度學習下的語義SLAM


在ELF 1 開發板上實現讀取攝像頭視頻進行目標檢測






 工商網監
工商網監
評論