 在ZTR無配置大規模中實現的縮放零接觸RoCE技術
在ZTR無配置大規模中實現的縮放零接觸RoCE技術
NVIDIA Zero Touch RoCE ( ZTR )使數據中心能夠無縫部署 聚合以太網上的 RDMA ( RoCE ) ,而無需任何特殊交換機配置。直到最近, ZTR 還僅適用于中小型數據中心。同時,大規模部署傳統上依賴于顯式擁塞通知( ECN )來啟用 RoCE 網絡傳輸,這需要交換機配置。
新的 NVIDIA 擁塞控制算法往返時間擁塞控制( RTTCC ) – 允許 ZTR 在不影響性能的情況下擴展到數千臺服務器。通過使用 ZTR 和 RTTCC ,數據中心運營商可以在無需任何交換機配置的情況下,享受部署和操作的便利性,以及大規模遠程直接內存訪問( RDMA )的卓越性能。
這篇文章描述了以前在大規模和小型 RoCE 部署中推薦的 RoCE 擁塞控制。然后介紹了一種新的擁塞控制算法,該算法允許 ZTR 的無配置大規模實現,其性能類似于支持 ECN 的 RoCE 。
具有數據中心量化擁塞通知的 RoCE 部署
在典型的基于 TCP 的環境中,分布式內存請求需要許多步驟和 CPU 周期,這會對應用程序性能產生負面影響。 RDMA 消除了服務器之間內存數據傳輸的所有 CPU 參與,大大加快了對存儲數據的訪問和應用程序性能。
RoCE 在以太網環境中提供 RDMA ,這是數據中心的主要網絡結構。以太網需要高級擁塞控制機制來支持 RDMA 網絡傳輸。數據中心量化擁塞通知( DCQCN )是一種擁塞控制算法,能夠響應擁塞通知并動態調整流量傳輸速率。
DCQCN 的實現需要啟用顯式擁塞通知( ECN ),這需要配置網絡交換機。 ECN 將交換機配置為設置擁塞經歷( CE )位,以指示即將發生的擁塞。
具有無功擁塞控制的零接觸 RoCE
NVIDIA 開發的 ZTR 技術允許 RoCE 部署,無需配置交換機基礎設施。 ZTR 根據 InfiniBand Trade Association ( IBTA ) RDMA 標準構建,完全符合 RoCE specifications ,支持 RoCE 的無縫部署。 ZTR 還擁有與傳統交換機啟用的 RoCE 相當的性能,并且明顯優于傳統的基于 TCP 的內存訪問。此外,通過 ZTR , RoCE 網絡傳輸服務在普通 TCP / IP 環境中與非 RoCE 通信并行運行。
正如 NVIDIA 零接觸 RoCE 技術為 Microsoft Azure Stack HCI 實現了云經濟 文章中所指出的,微軟已經為其 Azure Stack HCI 平臺驗證了 ZTR ,該平臺通常可擴展到幾十個節點。在這樣的環境中, ZTR 依賴于隱式丟包通知,這對于小規模部署來說已經足夠了。通過添加新的基于往返計時器( RTT )的擁塞控制算法, ZTR 變得更加健壯和可擴展,而無需依賴丟包來通知服務器網絡擁塞。
引入往返時間擁塞控制
新的 NVIDIA 擁塞控制算法 RTTCC 主動監控網絡 RTT ,以便在丟棄數據包之前主動檢測并適應擁塞的發生。 RTTCC 使用基于硬件的反饋環路實現動態擁塞控制,與基于軟件的擁塞控制算法相比,該反饋環路提供了顯著優越的性能。 RTTCC 還支持更快的傳輸速率,可以在更大范圍內部署 ZTR 。帶有 RTTCC 的 ZTR 現在作為測試版功能提供, GA 計劃在 2022 年下半年推出。
ZTR-RTTCC 的工作原理
ZTR-RTTCC 通過基于硬件 RTT 的擁塞控制算法擴展了 RoCE 網絡中的 DCQCN 。
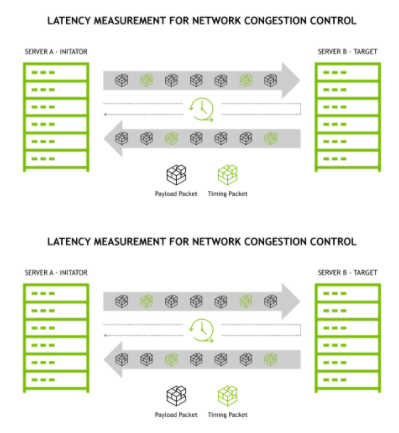
圖 1 服務器之間的往返計時
定時數據包(上圖中的綠色網絡數據包)定期從啟動器發送到目標。立即返回定時數據包,從而能夠測量往返延遲。 RTTCC 測量數據包發送和啟動器接收數據包之間的時間間隔。差異(接收時間–發送時間)衡量往返延遲,這表明路徑擁塞。未壓縮流繼續傳輸數據包,以最佳利用可用網絡路徑帶寬。延遲增加的流意味著路徑擁塞, RTTCC 會對流量進行節流,以避免緩沖區溢出和數據包丟失。
隨著擁塞的減少或增加,網絡流量可以實時地向上或向下調整。主動監控和應對擁塞的能力對于使 ZTR 能夠主動管理擁塞至關重要。這種主動速率控制還可以減少數據包的重新傳輸,提高 RoCE 性能。使用 ZTR-RTTCC ,數據中心節點不會等待數據包丟失的通知;相反,它們主動識別擁塞 prior to 數據包丟失并作出相應反應,通知啟動器調整傳輸速率。
如前所述, ZTR 的一個關鍵優勢是能夠提供 RoCE 功能,同時在普通 TCP / IP 流量中與非 RoCE 通信同時運行。 ZTR 提供 RoCE 網絡功能的無縫部署。通過添加 RTTCC 主動監控擁塞, ZTR 提供數據中心范圍內的操作,無需交換機配置。請繼續閱讀,看看它的性能如何。
具有 RTTCC 性能的 ZTR
如圖 2 所示,當通過網絡結構配置 ECN 和 PFC 時,帶有 RTTCC 的 ZTR 提供了與 RoCE 相當的應用程序性能。這些測試是在最壞的多對一( in-cast )情況下進行的,以模擬擁擠條件下的吞吐量。
結果表明,具有 RTTCC 的 ZTR 不僅可以擴展到數千個節點,而且其性能與目前可用的最快 RoCE 解決方案相當。
在小規模( 256 個連接及以下)下,具有 RTTCC 的 ZTR 在啟用 ECN 擁塞控制(傳統 RoCE )的 RoCE 的 99% 范圍內執行。
通過 16000 多個連接,具有 RTTCC 吞吐量的 ZTR 是傳統 RoCE 吞吐量的 98% 。
帶有 RTTCC 的 ZTR 在不需要任何開關配置的情況下,提供了與傳統 RoCE 幾乎相同的性能。
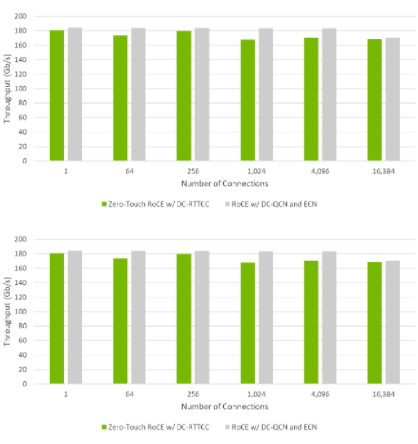
圖 2 連接不斷增加的應用程序帶寬
配置 ZTR
要使用新的 RTTCC 算法配置 ZTR , 下載 并為 NVIDIA 網絡接口卡安裝最新固件和工具,請執行以下步驟。
配置 ZTR
要使用新的 RTTCC 算法配置 ZTR , 下載 并為 NVIDIA 網絡接口卡安裝最新固件和工具,請執行以下步驟。
使用mlxconfig(持續配置)啟用可編程擁塞控制:
mlxconfig -d /dev/mst/mt4125_pciconf0 -y s ROCE_CC_LEGACY_DCQCN=0
使用mlxfwreset重置設備或重新啟動主機:
mlxfwreset -d /dev/mst/mt4125_pciconf0 -l 3 -y r
完成這些步驟后,當 RDMA-CM 用于增強連接建立( ECE , MLNX _ OFED 版本 5.1 支持)時,將使用 ZTR-RTTCC 。
如果出現錯誤,無論 RDMA-CM 同步狀態如何,都可以強制使用 ZTR-RTTCC :
mlxreg -d /dev/mst/mt4125_pciconf0 --reg_id 0x506e --reg_len 0x40 --set "0x0.0:8=2,0x4.0:4=15" -y
總結
NVIDIA RTTCC 是 ZTR 的新擁塞控制算法,在數據中心范圍內提供卓越的 RoCE 性能,無需對交換機基礎設施進行任何特殊配置。此增強功能使數據中心能夠在現有和新的數據中心基礎架構中無縫實現 RoCE ,并從即時的應用程序性能改進中獲益。
關于作者
Aviv Barnea 是 NVIDIA 網絡軟件工程的高級主管。他監督網絡適配器 RDMA 軟件和擁塞控制機制的開發,實現高速、低延遲的數據中心連接。 Aviv 是 RDMA 和 RoCE 通信協議方面的專家,擁有該領域的多項專利,在推動 RDMA / RoCE 在業界的發展方面發揮了重要作用,在客戶和合作伙伴大規模部署加速網絡解決方案時與他們密切合作,并實現了無與倫比的性能和易用性。 Aviv 擁有特拉維夫大學工商管理碩士學位和理工學院物理與電氣工程學士學位。
Itay Ozery 是 NVIDIA 網絡產品營銷總監。他為 Mellanox 的云網絡解決方案推動戰略性產品營銷和產品管理計劃。 Itay 在網絡安全領域領導了大規模的業務和項目,并與數據中心和電信服務提供商在 IT 系統和網絡工程領域擔任過多個職位。
審核編輯:郭婷
-
接口
+關注
關注
33文章
8685瀏覽量
151642 -
NVIDIA
+關注
關注
14文章
5071瀏覽量
103488
發布評論請先 登錄
相關推薦
小米澄清年底大規模裁員傳聞
RoCE與IB對比分析(二):功能應用篇
RoCE與IB對比分析(一):協議棧層級篇
FPGA仿真黑科技\"EasyGo Vs Addon \",助力大規模電力電子系統仿真
云平臺在大規模設備管理和數據分析中的作用


【大規模語言模型:從理論到實踐】- 每日進步一點點
摩爾線程與無問芯穹在國產GPU上首次實現大模型實訓
深度解讀RoCE v2的核心技術原理





 工商網監
工商網監
評論