 電子發燒友App
電子發燒友App


由于處理器與存儲器的工藝、封裝、需求的不同,從1980年開始至今二者之間的性能差距越來越大。有數據顯示,處理器和存儲器的速度失配以每年50%的速率增加。
存儲器數據訪問速度跟不上處理器的數據處理速度,數據傳輸就像處在一個巨大的漏斗之中,不管處理器灌進去多少,存儲器都只能“細水長流”。兩者之間數據交換通路窄以及由此引發的高能耗兩大難題,在存儲與運算之間筑起了一道“內存墻”。
隨著數據的爆炸勢增長,內存墻對于計算速度的影響愈發顯現。為了減小內存墻的影響,提升內存帶寬一直是存儲芯片聚焦的關鍵問題。
長期以來,內存行業的價值主張在很大程度上始終以系統級需求為導向,已經突破了系統性能的當前極限。很明顯的一點是,內存性能的提升將出現拐點,因為越來越多人開始質疑是否能一直通過內存級的取舍(如功耗、散熱、占板空間等)來提高系統性能。
基于對先進技術和解決方案開展的研究,內存行業在新領域進行了更深入的探索。作為存儲器市場的重要組成部分,DRAM技術不斷地升級衍生。DRAM從2D向3D技術發展,其中HBM是主要代表產品。
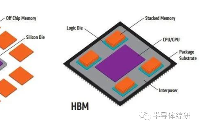
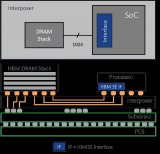
HBM(High Bandwidth Memory,高帶寬內存)是一款新型的CPU/GPU 內存芯片,其實就是將很多個DDR芯片堆疊在一起后和GPU封裝在一起,實現大容量,高位寬的DDR組合陣列。
通過增加帶寬,擴展內存容量,讓更大的模型,更多的參數留在離核心計算更近的地方,從而減少內存和存儲解決方案帶來的延遲。
從技術角度看,HBM使DRAM從傳統2D轉變為立體3D,充分利用空間、縮小面積,契合半導體行業小型化、集成化的發展趨勢。HBM突破了內存容量與帶寬瓶頸,被視為新一代DRAM解決方案,業界認為這是DRAM通過存儲器層次結構的多樣化開辟一條新的道路,革命性提升DRAM的性能。
在內存領域,一場關于HBM的競賽已悄然打響。
巨頭領跑,HBM3時代來臨
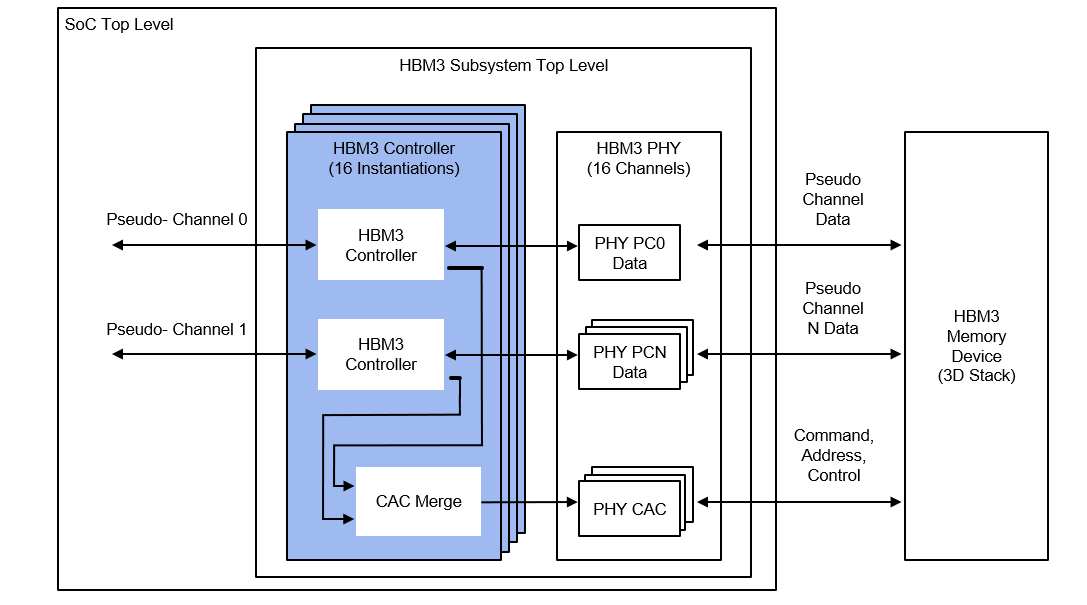
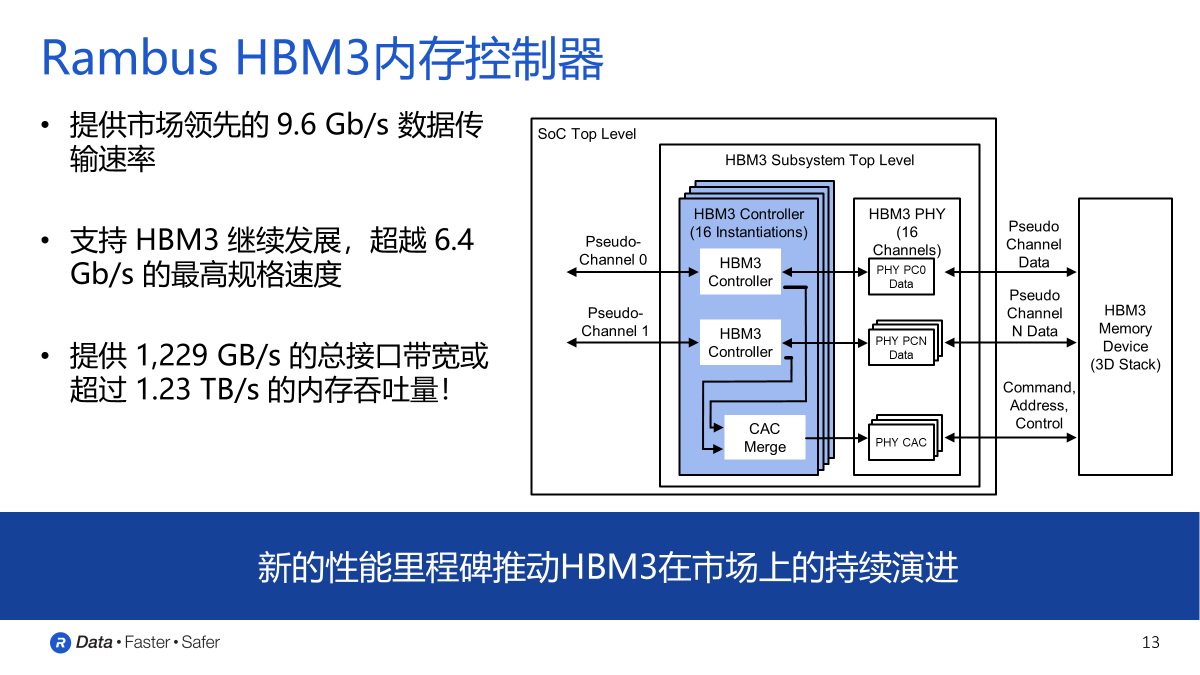
據了解,HBM主要是通過硅通孔(Through Silicon Via, 簡稱“TSV”)技術進行芯片堆疊,以增加吞吐量并克服單一封裝內帶寬的限制,將數個DRAM裸片像樓層一樣垂直堆疊。
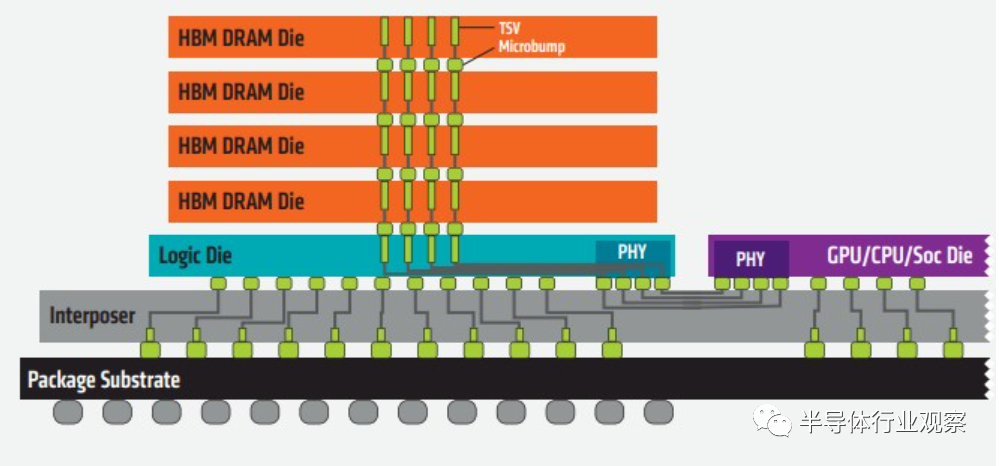
裸片之間用TSV技術連接
SK海力士表示,TSV是在DRAM芯片上搭上數千個細微孔并通過垂直貫通的電極連接上下芯片的技術。該技術在緩沖芯片上將數個DRAM芯片堆疊起來,并通過貫通所有芯片層的柱狀通道傳輸信號、指令、電流。相較傳統封裝方式,該技術能夠縮減30%體積,并降低50%能耗。
憑借TSV方式,HBM大幅提高了容量和數據傳輸速率。與傳統內存技術相比,HBM具有更高帶寬、更多I/O數量、更低功耗、更小尺寸。隨著存儲數據量激增,市場對于HBM的需求將有望大幅提升。
HBM的高帶寬離不開各種基礎技術和先進設計工藝的支持。由于HBM是在3D結構中將一個邏輯die與4-16個DRAM die堆疊在一起,因此開發過程極為復雜。鑒于技術上的復雜性,HBM是公認最能夠展示廠商技術實力的旗艦產品。
2013年,SK海力士將TSV技術應用于DRAM,在業界首次成功研發出HBM。
HBM1的工作頻率約為1600 Mbps,漏極電源電壓為1.2V,芯片密度為2Gb(4-hi)。HBM1的帶寬高于DDR4和GDDR5產品,同時以較小的外形尺寸消耗較低的功率,更能滿足GPU等帶寬需求較高的處理器。
隨后,SK海力士、三星、美光等存儲巨頭在HBM領域展開了升級競賽。
2016年1月,三星宣布開始量產4GB HBM2 DRAM,并在同一年內生產8GB HBM2 DRAM;2017年下半年,被三星趕超的SK海力士開始量產HBM2;2018年1月,三星宣布開始量產第二代8GB HBM2“Aquabolt”。
2018年末,JEDEC推出HBM2E規范,以支持增加的帶寬和容量。當傳輸速率上升到每管腳3.6Gbps時,HBM2E可以實現每堆棧461GB/s的內存帶寬。此外,HBM2E支持最多12個DRAM的堆棧,內存容量高達每堆棧24GB。與HBM2相比,HBM2E具有技術更先進、應用范圍更廣泛、速度更快、容量更大等特點。
2019年8月,SK海力士宣布成功研發出新一代“HBM2E”;2020年2月,三星也正式宣布推出其16GB HBM2E產品“Flashbolt”,于2020年上半年開始量產。
據三星介紹,其16GB HBM2E Flashbolt通過垂直堆疊8層10納米級16GB DRAM晶片,能夠提供高達410GB/s的內存帶寬級別和每引腳3.2 GB/s的數據傳輸速度。
SK海力士的HBM2E以每個引腳3.6Gbps的處理速度,每秒能處理超過460GB的數據,包含1024個數據I/O。通過TSV技術垂直堆疊8個16GB芯片,其HBM2E單顆容量16GB。

HBM技術線路圖(圖源:SK海力士)
2020年,另一家存儲巨頭美光宣布加入到這一賽場中來。
美光在當時的財報會議上表示,將開始提供HBM2內存/顯存,用于高性能顯卡,服務器處理器產品,并預計下一代HBMNext將在2022年底面世。但截止目前尚未看到美光相關產品動態。
2022年1月,JEDEC組織正式發布了新一代高帶寬內存HBM3的標準規范,繼續在存儲密度、帶寬、通道、可靠性、能效等各個層面進行擴充升級,具體包括:
主接口使用0.4V低擺幅調制,運行電壓降低至1.1V,進一步提升能效表現。
傳輸數據率在HBM2基礎上再次翻番,每個引腳的傳輸率為6.4Gbps,配合1024-bit位寬,單顆最高帶寬可達819GB/s。
如果使用四顆,總帶寬就是3.2TB/s,六顆則可達4.8TB/s。
獨立通道數從8個翻番到16個,再加上虛擬通道,單顆支持32通道。
支持4層、8層和12層TSV堆棧,并為未來擴展至16層TSV堆棧做好準備。
每個存儲層容量8/16/32Gb,單顆容量起步4GB(8Gb 4-high)、最大容量64GB(32Gb 16-high)。
支持平臺級RAS可靠性,集成ECC校驗糾錯,支持實時錯誤報告與透明度。
JEDEC表示,HBM3是一種創新的方法,是更高帶寬、更低功耗和單位面積容量的解決方案,對于高數據處理速率要求的應用場景來說至關重要,比如圖形處理和高性能計算的服務器。

HBM性能演進(圖源:Rambus)
SK海力士早在2021年10月就開發出全球首款HBM3,2022年6月量產了HBM3 DRAM芯片,并將供貨英偉達,持續鞏固其市場領先地位。隨著英偉達使用HBM3 DRAM,數據中心或將迎來新一輪的性能革命。
根據此前的資料介紹,SK海力士提供了兩種容量產品,一個是12層硅通孔技術垂直堆疊的24GB(196Gb),另一個則是8層堆疊的16GB(128Gb),均提供819 GB/s的帶寬,前者的芯片高度也僅為30微米。相比上一代HBM2E的460 GB/s帶寬,HBM3的帶寬提高了78%。此外,HBM3內存還內置了片上糾錯技術,提高了產品的可靠性。
SK海力士對于HBM的研發一直非常積極,為了滿足客戶不斷增加的期望,打破現有框架進行新技術開發勢在必行。SK海力士還在與HBM生態系統中的參與者(客戶、代工廠和IP公司等)通力合作,以提升生態系統等級。商業模式的轉變同樣是大勢所趨。作為HBM領軍企業,SK海力士將致力于在計算技術領域不斷取得進步,全力實現HBM的長期發展。
三星也在積極跟進,在2022年技術發布會上發布的內存技術發展路線圖中,三星展示了涵蓋不同領域的內存接口演進的速度。首先,在云端高性能服務器領域,HBM已經成為了高端GPU的標配,這也是三星在重點投資的領域之一。HBM的特點是使用高級封裝技術,使用多層堆疊實現超高IO接口寬度,同時配合較高速的接口傳輸速率,從而實現高能效比的超高帶寬。
在三星發布的路線圖中,2022年HBM3技術已經量產,其單芯片接口寬度可達1024bit,接口傳輸速率可達6.4Gbps,相比上一代提升1.8倍,從而實現單芯片接口帶寬819GB/s,如果使用6層堆疊可以實現4.8TB/s的總帶寬。
2024年預計將實現接口速度高達7.2Gbps的HBM3p,從而將數據傳輸率相比這一代進一步提升10%,從而將堆疊的總帶寬提升到5TB/s以上。另外,這里的計算還沒有考慮到高級封裝技術帶來的高多層堆疊和內存寬度提升,預計2024年HBM3p單芯片和堆疊芯片都將實現更多的總帶寬提升。而這也將會成為人工智能應用的重要推動力,預計在2025年之后的新一代云端旗艦GPU中看到HBM3p的使用,從而進一步加強云端人工智能的算力。
從HBM1到HBM3,SK海力士和三星一直是HBM行業的領軍企業。
HBM未來潛力與演進方向
對于接下來的規劃策略和技術進步,業界旨在突破目前HBM在速度、密度、功耗、占板空間等方面的極限。
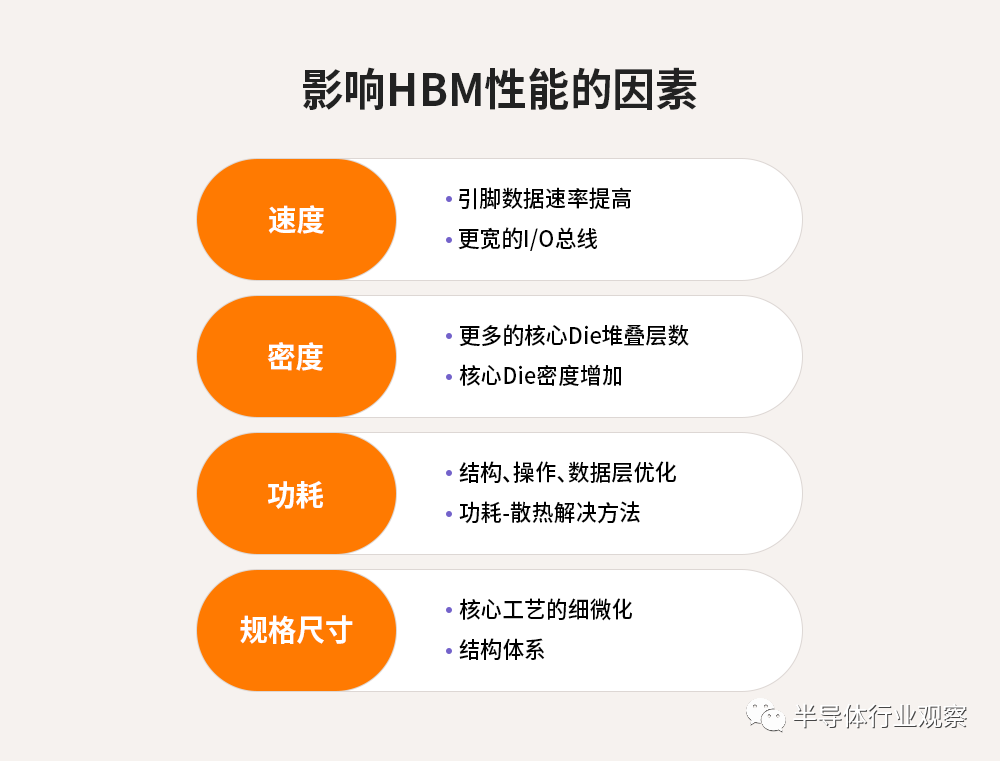
影響HBM性能的因素
首先,為了打破速度極限,SK海力士正在評估提高引腳數據速率的傳統方法的利弊,以及超過1024個數據的I/O總線位寬,以實現更好的數據并行性和向后設計兼容性。簡單來講,即用最少的取舍獲得更高的帶寬性能。
針對更大數據集、訓練工作負載所需的更高內存密度要求,存儲廠商開始著手研究擴展Die堆疊層數和物理堆疊高度,以及增加核心Die密度以優化堆疊密度。
另一方面也在致力于提高功耗效率,通過評估從最低微結構級別到最高Die堆疊概念的內存結構和操作方案,最大限度地降低每帶寬擴展的絕對功耗。由于現有中介層光罩尺寸的物理限制以及支持處理單元和HBM Cube的其他相關技術,實現總內存Die尺寸最小化尤為重要。因此,行業廠商需要在不擴大現有物理尺寸的情況下增加存儲單元數量和功能,從而實現整體性能的飛躍。
但從產業發展歷程來看,完成上述任務的前提是:存儲廠商要與上下游生態系統合作伙伴攜手合作和開放協同,將HBM的使用范圍從現有系統擴展到潛在的下一代應用。
此外,新型HBM-PIM(存內計算)芯片將AI引擎引入每個存儲庫,從而將處理操作轉移到HBM。
在傳統架構下,數據從內存單元傳輸到計算單元需要的功耗是計算本身的約200倍,數據的搬運耗費的功耗遠大于計算,因此真正用于計算的能耗和時間占比很低,數據在存儲器與處理器之間的頻繁遷移帶來嚴重的傳輸功耗問題,稱為“功耗墻”。新型的內存旨在減輕在內存和處理器之間搬運數據的負擔。
寫在最后
過去幾年來,HBM產品帶寬增加了數倍,目前已接近或達到1TB/秒的里程碑節點。相較于同期內其他產品僅增加兩三倍的帶寬增速,HBM的快速發展歸功于存儲器制造商之間的競爭和比拼。
存儲器帶寬指單位時間內可以傳輸的數據量,要想增加帶寬,最簡單的方法是增加數據傳輸線路的數量。事實上,每個HBM由多達1024個數據引腳組成,HBM內部的數據傳輸路徑隨著每一代產品的發展而顯著增長。
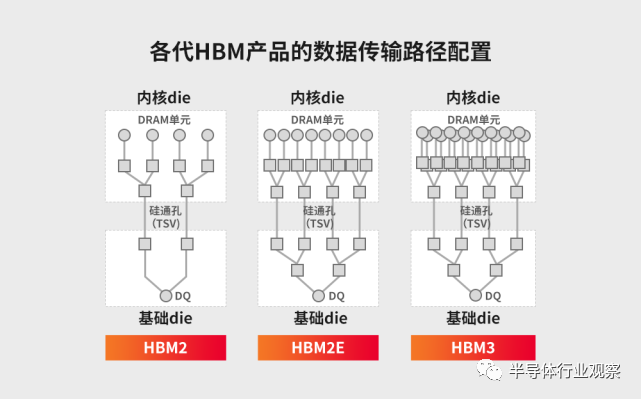
各代HBM產品的數據傳輸路徑配置
回顧HBM的演進歷程,第一代HBM數據傳輸速率大概可達1Gbps;2016年推出的第二代產品HBM2,最高數據傳輸速率可達2Gbps;2018年,第三代產品HBM2E的最高數據傳輸速率已經可達3.6Gbps。如今,SK海力士和三星已研發出第四代產品HBM3,此后HBM3預計仍將持續發力,在數據傳輸速率上有更大的提升。
從性能來看,HBM無疑是出色的,其在數據傳輸的速率、帶寬以及密度上都有著巨大的優勢。不過,目前HBM仍主要應用于服務器、數據中心等應用領域,其最大的限制條件在于成本,對成本比較敏感的消費領域而言,HBM的使用門檻仍較高。
盡管HBM已更迭到了第四代,但HBM現在依舊處于相對早期的階段,其未來還有很長的一段路要走。
而可預見的是,隨著人工智能、機器學習、高性能計算、數據中心等應用市場的興起,內存產品設計的復雜性正在快速上升,并對帶寬提出了更高的要求,不斷上升的寬帶需求持續驅動HBM發展。市場調研機構Omdia預測,2025年HBM市場的總收入將達到25億美元。
在這個過程中,存儲巨頭持續發力、上下游廠商相繼入局,HBM將受到越來越多的關注與青睞。
編輯:黃飛
?





















 工商網監
工商網監
評論