 深度解析HBM內存技術
深度解析HBM內存技術
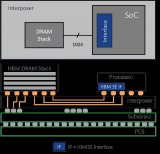
HBM作為基于3D堆棧工藝的高性能DRAM,打破內存帶寬及功耗瓶頸。HBM(High Bandwidth Memory)即高帶寬存儲器,通過使用先進封裝(如TSV硅通孔、微凸塊)將多個DRAM芯片進行堆疊,并與GPU一同進行封裝,形成大容量、高帶寬的DDR組合陣列。
HBM通過與處理器相同的“Interposer”中間介質層與計算芯片實現緊湊連接,一方面既節省了芯片面積,另一方面又顯著減少了數據傳輸時間;此外HBM采用TSV工藝進行3D堆疊,不僅顯著提升了帶寬,同時降低了功耗,實現了更高的集成度。
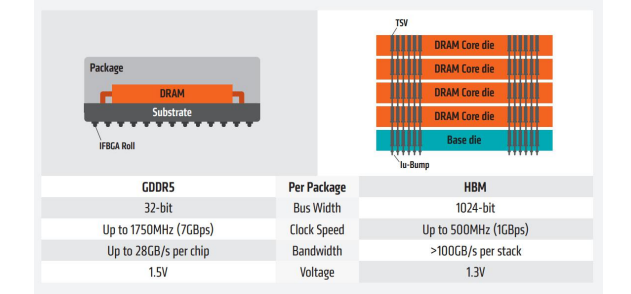
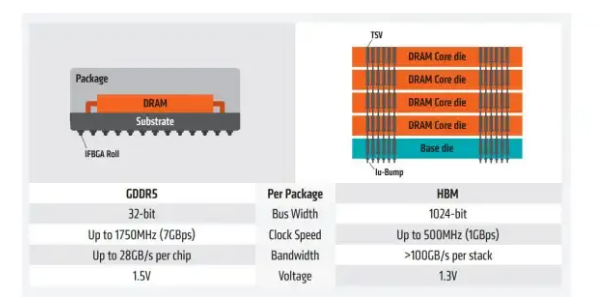
HBM性能遠超GDDR,成為當前GPU存儲單元理想解決方案。GPU顯存一般采用GDDR或者HBM兩種方案,但HBM性能遠超GDDR。
根據AMD數據,從顯存位寬來看,GDDR5為32-bit,HBM為其四倍,達到了1024-bit;從時鐘頻率來看,HBM為500MHz,遠遠小于GDDR5的1750MHz;從顯存帶寬來看,HBM的一個stack大于100GB/s,而GDDR5的一顆芯片才25GB/s,所以HBM的數據傳輸速率遠遠高于GDDR5。
從空間利用角度來看,HBM由于與GPU封裝在一塊,從而大幅度減少了顯卡PCB的空間,而GDDR5芯片面積為HBM芯片三倍,這意味著HBM能夠在更小的空間內,實現更大的容量。因此,HBM可以在實現高帶寬和高容量的同時節約芯片面積和功耗,被視為GPU存儲單元理想解決方案。
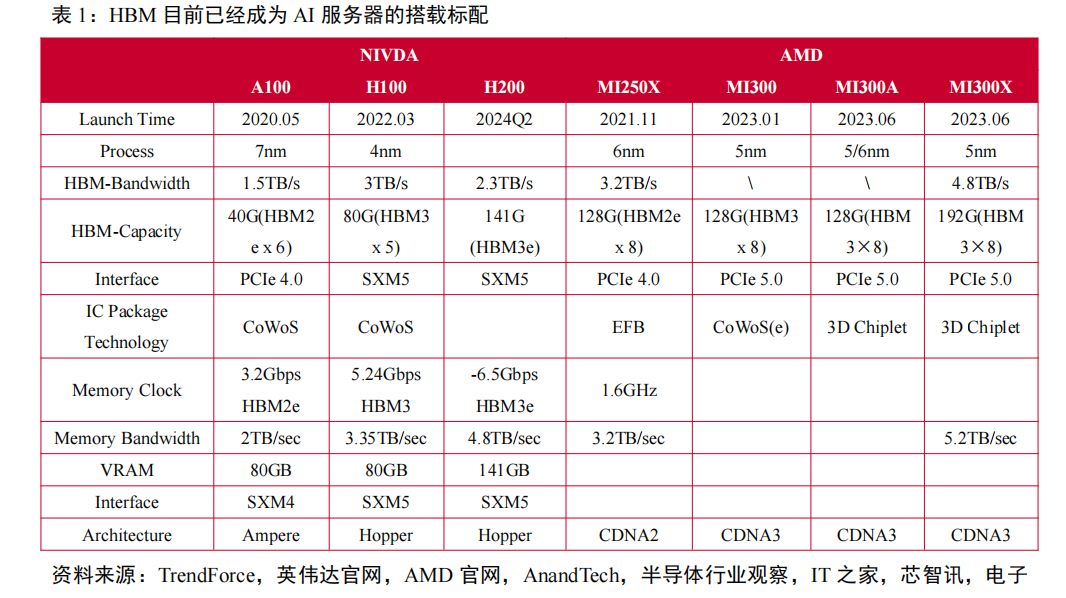
在高性能GPU需求推動下,HBM目前已經成為AI服務器的搭載標配。AI大模型的興起催生了海量算力需求,而數據處理量和傳輸速率大幅提升使得AI服務器對芯片內存容量和傳輸帶寬提出更高要求。
HBM具備高帶寬、高容量、低延時和低功耗優勢,目前已逐步成為AI服務器中GPU的搭載標配。英偉達推出的多款用于AI訓練的芯片A100、H100和H200,都采用了HBM顯存。
其中,A100和H100芯片搭載了40GB的HBM2e和80GB的HBM3顯存,最新的H200芯片搭載了速率更快、容量更高的HBM3e。AMD的MI300系列也都采用了HBM3技術,MI300A的容量與前一代相同為128GB,而更高端的MI300X則將容量提升至192GB,增長了50%,相當于H100容量的2.4倍。
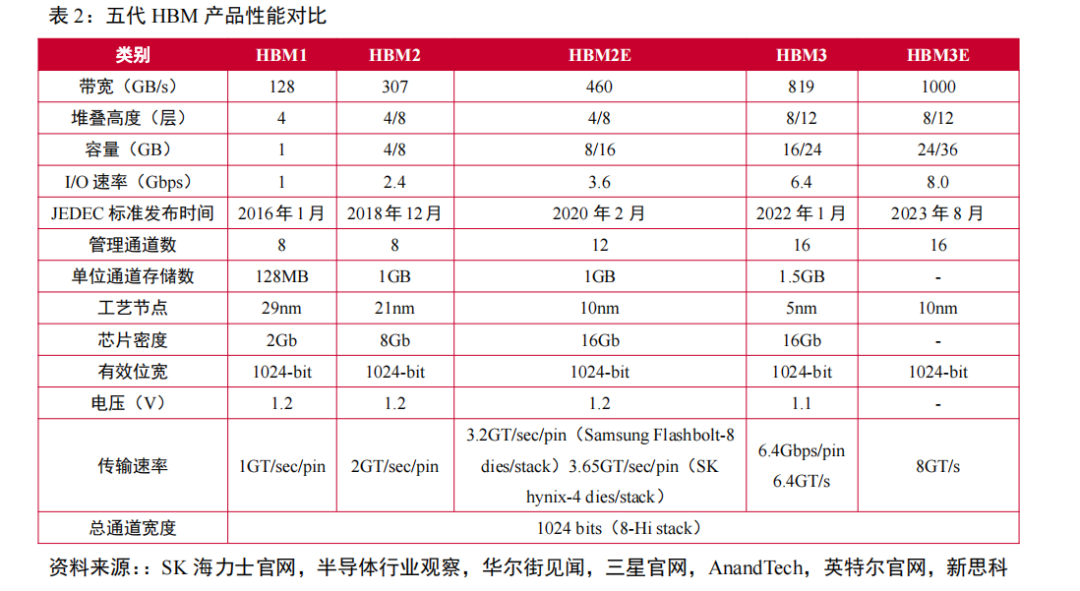
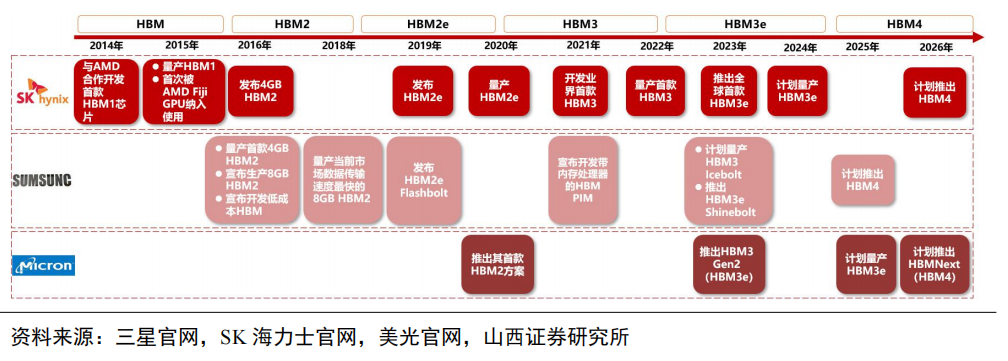
HBM市場競爭激烈,HBM產品向低能耗、高帶寬、高容量加速迭代。從2016年第一代HBM1發布開始,HBM目前已經迭代到第五代產品——HBM3e,縱觀五代HBM產品性能變化,可以發現HBM在帶寬、I/O速率、容量、工藝節點等方面取得較大突破,其中帶寬由初代的128GB/s迭代至HBM3e的1TB/s,I/O速率由1Gbps迭代至8Gbps,容量從1GB增至最高36GB,制造工藝則取得進一步突破,達到5nm級別。
最新一代HBM3e數據處理速度最高可達到1.15TB/s,HBM系列產品的更新迭代將在低能耗、高帶寬、高容量上持續發力,以高性能牽引AI技術進一步革新。
HBM產品迭代助力AI芯片性能升級。當地時間2023年11月13日,英偉達發布了首款搭載最先進存儲技術HBM3e的GPU芯片H200。H200作為首款搭載最先進存儲技術HBM3e的GPU,擁有141GB顯存容量和4.8TB/s顯存帶寬,與H100的80GB和3.35TB/s相比,顯存容量增加76%,顯存帶寬增加43%。
盡管GPU核心未升級,但H200憑借更大容量、更高帶寬的顯存,依舊在人工智能大模型計算方面實現顯著提升。根據英偉達官方數據,在單卡性能方面,H200相比H100,在Llama2的130億參數訓練中速度提升40%,在GPT-3的1750億參數訓練中提升60%,在Llama2的700億參數訓練中提升90%;在降低能耗、減少成本方面,H200的TCO(總擁有成本)達到了新水平,最高可降低一半的能耗。
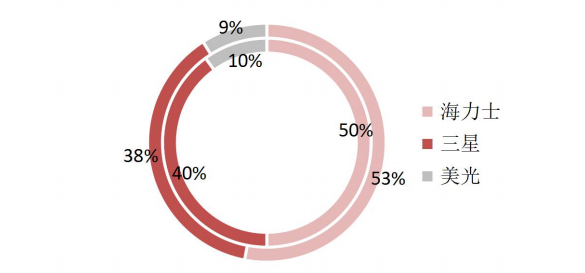
HBM市場目前被三大原廠占據,其中海力士份額領先,占據HBM市場主導地位。據TrendForce數據,三大原廠海力士、三星、美光2022年HBM市占率分別為50%、40%、10%。2023年年初至今,生成式AI市場呈爆發式增長,大模型參數量、預訓練數據量攀升,驅動AI服務器對高帶寬、高容量的HBM需求迅速增加。
作為最先開發出HBM芯片的海力士,在AIGC行業迅速發展背景下得以搶占先機,率先實現HBM3量產,搶占市場份額。2023年下半年英偉達高性能GPUH100與AMD MI300將搭載海力士生產的HBM3,海力士市占率將進一步提升,預計2023年海力士、三星、美光市占率分別為53%、38%、9%。

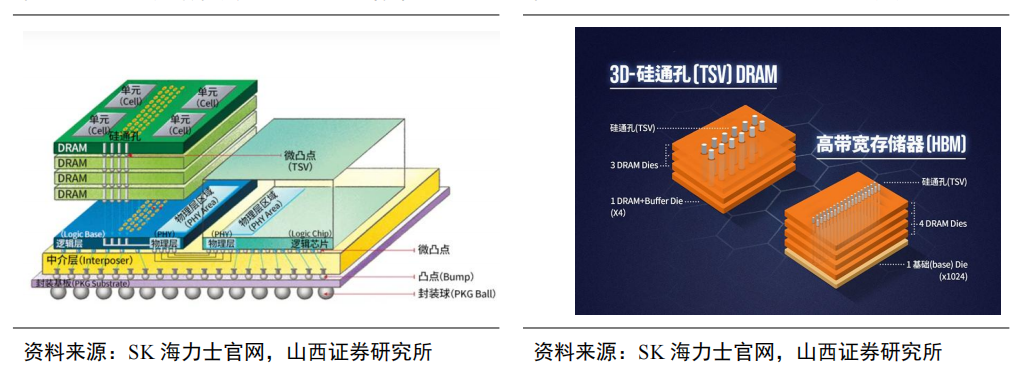
TSV技術通過垂直堆疊多個DRAM,能顯著提升存儲容量、帶寬并降低功耗。TSV(硅通孔)技術通過在芯片與芯片之間、晶圓和晶圓之間制作垂直導通,并通過銅、鎢、多晶硅等導電物質的填充,實現硅通孔的垂直電氣互聯。
作為實現3D先進封裝的關鍵技術之一,對比wire bond疊層封裝,TSV可以提供更高的互連密度和更短的數據傳輸路徑,因此具有更高的性能和傳輸速度。隨著摩爾定律放緩,芯片特征尺寸接近物理極限,半導體器件的微型化也越來越依賴于集成TSV的先進封裝。目前DRAM行業中,3D-TSVDRAM和HBM已經成功生產TSV,克服了容量和帶寬的限制。
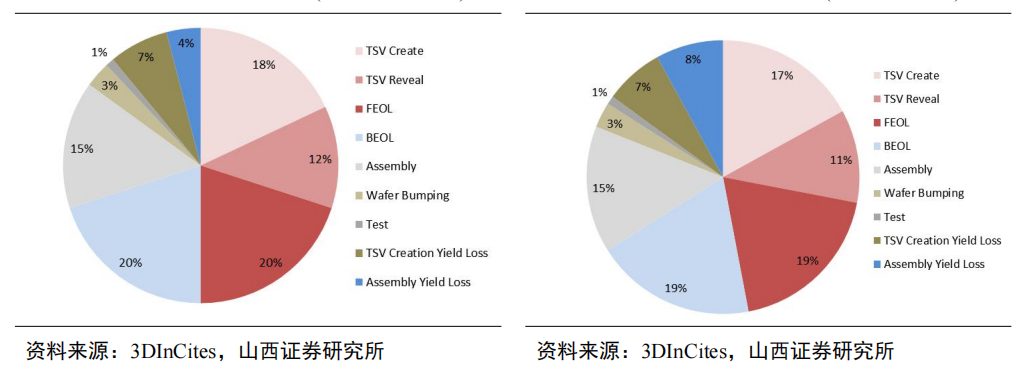
TSV為HBM核心工藝,在HBM3D封裝成本中占比約30%。根據SAMSUNG,3D TSV工藝較傳統POP封裝形式節省了35%的封裝尺寸,降低了50%的功耗,并且對比帶來了8倍的帶寬提升。對4層存儲芯片和一層邏輯裸芯進行3D堆疊的成本進行分析,TSV形成和顯露的成本合計占比,對應99.5%和99%兩種鍵合良率的情形分別為30%和28%,超過了前/后道工藝的成本占比,是HBM3D封裝中成本占比最高的部分。
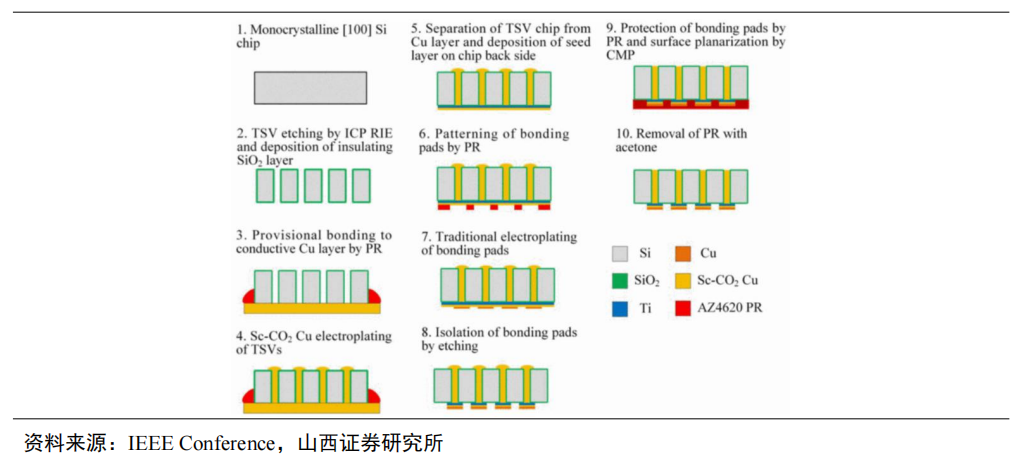
TSV技術主要涉及深孔刻蝕、沉積、減薄拋光等關鍵工藝。TSV首先利用深反應離子刻蝕(DRIE)法制作通孔;然后使用化學氣相沉積(PECVD)的方法沉積制作介電層、使用物理氣相沉積(PVD)的方法沉積制作阻擋層和種子層;再選擇電鍍銅(Cu)進行填孔;最后使用化學和機械拋光(CMP)法去除多余的銅。另外,由于芯片堆疊集成的需要,在完成銅填充后,還需要晶圓減薄和鍵合。
HBM多層堆疊結構提升工序步驟,帶動封裝設備需求持續提升。(1)前道環節:HBM需要通過TSV進行垂直方向連接,增加了TSV刻蝕設備需求,同時HBM中TSV、微凸點、硅中介層等工藝大量增加了前道工序,給前道檢、量測設備帶來增量;(2)后道環節:HBM堆疊結構增多,要求晶圓厚度不斷降低,這意味著對減薄、鍵合等設備的需求提升;HBM多層堆疊結構依靠超薄晶圓和銅銅混合鍵合工藝增加了對臨時鍵合/解鍵合等設備的需求;(3)各層DRAM Die的保護材料也非常關鍵,對注塑或壓塑設備提出了較高要求。
審核編輯:湯梓紅
-
存儲器
+關注
關注
38文章
7493瀏覽量
163873 -
gpu
+關注
關注
28文章
4742瀏覽量
128968 -
內存
+關注
關注
8文章
3028瀏覽量
74074 -
內存技術
+關注
關注
0文章
28瀏覽量
9847 -
HBM
+關注
關注
0文章
380瀏覽量
14765
原文標題:HBM內存技術全面對比分析
文章出處:【微信號:架構師技術聯盟,微信公眾號:架構師技術聯盟】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
簡述HBM技術的重要性
追求性能提升 使用8GB HBM2顯存
AUTOSAR架構深度解析 精選資料分享
全面解構FuzionSC如何高速組裝HBM內存
HBM內存:韓國人的游戲
深度解析三星內存處理技術(PIM)

一文解析HBM技術原理及優勢
英偉達斥資預購HBM3內存,為H200及超級芯片儲備產能
什么是HBM3E內存?Rambus HBM3E/3內存控制器內核






 工商網監
工商網監
評論