 電子發(fā)燒友App
電子發(fā)燒友App


通過(guò)深度學(xué)習(xí)技術(shù),物聯(lián)網(wǎng)(IoT)設(shè)備能夠得以解析非結(jié)構(gòu)化的多媒體數(shù)據(jù),智能地響應(yīng)用戶(hù)和環(huán)境事件,但是卻伴隨著苛刻的性能和功耗要求。本文作者探討了兩種方式以便將深度學(xué)習(xí)和低功耗的物聯(lián)網(wǎng)設(shè)備成功整合。
近年來(lái),越來(lái)越多的物聯(lián)網(wǎng)產(chǎn)品出現(xiàn)在市場(chǎng)上,它們采集周?chē)沫h(huán)境數(shù)據(jù),并使用傳統(tǒng)的機(jī)器學(xué)習(xí)技術(shù)理解這些數(shù)據(jù)。一個(gè)例子是Google的Nest恒溫器,采用結(jié)構(gòu)化的方式記錄溫度數(shù)據(jù),并通過(guò)算法來(lái)掌握用戶(hù)的溫度偏好和時(shí)間表。然而,其對(duì)于非結(jié)構(gòu)化的多媒體數(shù)據(jù),例如音頻信號(hào)和視覺(jué)圖像則顯得無(wú)能為力。
新興的物聯(lián)網(wǎng)設(shè)備采用了更加復(fù)雜的深度學(xué)習(xí)技術(shù),通過(guò)神經(jīng)網(wǎng)絡(luò)來(lái)探索其所處環(huán)境。例如,Amazon Echo可以理解人的語(yǔ)音指令,通過(guò)語(yǔ)音識(shí)別,將音頻信號(hào)轉(zhuǎn)換成單詞串,然后使用這些單詞來(lái)搜索相關(guān)信息。最近,微軟的Windows物聯(lián)網(wǎng)團(tuán)隊(duì)發(fā)布了一個(gè)基于面部識(shí)別的安全系統(tǒng),利用到了深度學(xué)習(xí)技術(shù),當(dāng)識(shí)別到用戶(hù)面部時(shí)能夠自動(dòng)解開(kāi)門(mén)鎖。
物聯(lián)網(wǎng)設(shè)備上的深度學(xué)習(xí)應(yīng)用通常具有苛刻的實(shí)時(shí)性要求。例如,基于物體識(shí)別的安全攝像機(jī)為了能及時(shí)響應(yīng)房屋內(nèi)出現(xiàn)的陌生人,通常需要小于500毫秒的檢測(cè)延遲來(lái)捕獲和處理目標(biāo)事件。消費(fèi)級(jí)的物聯(lián)網(wǎng)設(shè)備通常采用云服務(wù)來(lái)提供某種智能,然而其所依賴(lài)的優(yōu)質(zhì)互聯(lián)網(wǎng)連接,僅僅在部分范圍內(nèi)可用,并且往往需要較高的成本,這對(duì)設(shè)備能否滿(mǎn)足實(shí)時(shí)性要求提出了挑戰(zhàn)。與之相比,直接在物聯(lián)網(wǎng)設(shè)備上實(shí)現(xiàn)深度學(xué)習(xí)或許是一個(gè)更好的選擇,這樣就可以免受連接質(zhì)量的影響。
然而,直接在嵌入式設(shè)備上實(shí)現(xiàn)深度學(xué)習(xí)是困難的。事實(shí)上,低功耗是移動(dòng)物聯(lián)網(wǎng)設(shè)備的主要特征,而這通常意味著計(jì)算能力受限,內(nèi)存容量較小。在軟件方面,為了減少內(nèi)存占用,應(yīng)用程序通常直接運(yùn)行在裸機(jī)上,或者在包含極少量第三方庫(kù)的輕量級(jí)操作系統(tǒng)上。而與之相反,深度學(xué)習(xí)意味著高性能計(jì)算,并伴隨著高功耗。此外,現(xiàn)有的深度學(xué)習(xí)庫(kù)通常需要調(diào)用許多第三方庫(kù),而這些庫(kù)很難遷移到物聯(lián)網(wǎng)設(shè)備。
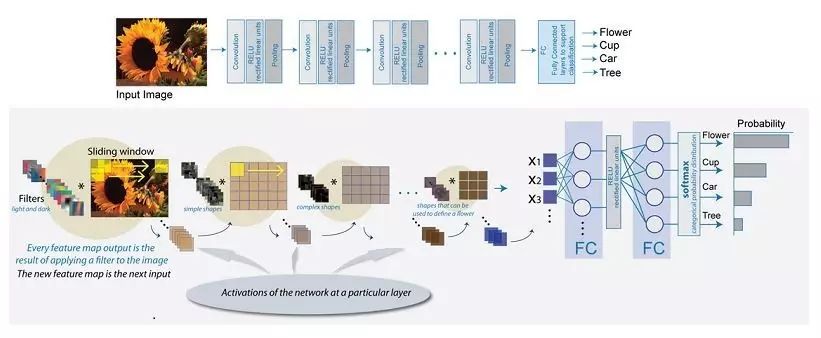
在深度學(xué)習(xí)任務(wù)中,最廣泛使用的神經(jīng)網(wǎng)絡(luò)是卷積神經(jīng)網(wǎng)絡(luò)(CNNs),它能夠?qū)⒎墙Y(jié)構(gòu)化的圖像數(shù)據(jù)轉(zhuǎn)換成結(jié)構(gòu)化的對(duì)象標(biāo)簽數(shù)據(jù)。一般來(lái)說(shuō),CNNs的工作流程如下:首先,卷積層掃描輸入圖像以生成特征向量;第二步,激活層確定在圖像推理過(guò)程中哪些特征向量應(yīng)該被激活使用;第三步,使用池化層降低特征向量的大小;最后,使用全連接層將池化層的所有輸出和輸出層相連。
在本文中,我們將討論如何使用CNN推理機(jī)在物聯(lián)網(wǎng)設(shè)備上實(shí)現(xiàn)深度學(xué)習(xí)。
將服務(wù)遷移到云端
對(duì)于低功耗的物聯(lián)網(wǎng)設(shè)備,問(wèn)題在于是否存在一個(gè)可靠的解決方案,能夠?qū)⑸疃葘W(xué)習(xí)部署在云端,同時(shí)滿(mǎn)足功耗和性能的要求。為了回答這個(gè)問(wèn)題,我們?cè)谝粔KNvidia Jetson TX1設(shè)備上實(shí)現(xiàn)了基于CNN的物體推理,并將其性能、功耗與將這些服務(wù)遷移到云端后的情況進(jìn)行對(duì)比。
為了確定將服務(wù)遷移到云端后,是否可以降低功耗并滿(mǎn)足對(duì)物體識(shí)別任務(wù)的實(shí)時(shí)性要求,我們將圖像發(fā)送到云端,然后等待云端將結(jié)果返回。研究表明,對(duì)于物體識(shí)別任務(wù),本地執(zhí)行的功耗為7 W,而遷移到云端后功耗降低為2W。這說(shuō)明將服務(wù)遷移到云端確實(shí)是降低功耗的有效途徑。
然而,遷移到云端會(huì)導(dǎo)致至少2秒的延遲,甚至可能高達(dá)5秒,這不能滿(mǎn)足我們500ms的實(shí)時(shí)性要求。此外,延遲的劇烈抖動(dòng)使得服務(wù)非常不可靠(作為對(duì)比,我們?cè)诿绹?guó)和中國(guó)分別運(yùn)行這些實(shí)驗(yàn)進(jìn)行觀(guān)察)。通過(guò)這些實(shí)驗(yàn)我們得出結(jié)論,在當(dāng)前的網(wǎng)絡(luò)環(huán)境下,將實(shí)時(shí)性深度學(xué)習(xí)任務(wù)遷移到云端是一個(gè)尚未可行的解決方案。
移植深度學(xué)習(xí)平臺(tái)到嵌入式設(shè)備
相比遷移到云端的不切實(shí)際,一個(gè)選擇是將現(xiàn)有的深度學(xué)習(xí)平臺(tái)移植到物聯(lián)網(wǎng)設(shè)備。為此,我們選擇移植由Google開(kāi)發(fā)并開(kāi)源的深度學(xué)習(xí)平臺(tái)TesnsorFlow來(lái)建立具有物體推理能力的物聯(lián)網(wǎng)設(shè)備Zuluko——PerceptIn的裸機(jī)ARM片上系統(tǒng)。Zuluko由四個(gè)運(yùn)行在1 GHz的ARM v7內(nèi)核和512 MB RAM組成,峰值功耗約為3W。根據(jù)我們的研究,在基于ARM-Linux的片上系統(tǒng)上,TensorFlow能夠提供最佳性能,這也是我們選擇它的原因。
我們預(yù)計(jì)能夠在幾天內(nèi)完成移植工作,然而,移植TensorFlow并不容易,它依賴(lài)于許多第三方庫(kù)(見(jiàn)圖1)。為了減少資源消耗,大多數(shù)物聯(lián)網(wǎng)設(shè)備都運(yùn)行在裸機(jī)上,因此移植所有依賴(lài)項(xiàng)可以說(shuō)是一項(xiàng)艱巨的任務(wù)。我們花了一個(gè)星期的精力才使得TensorFlow得以在Zuluko上運(yùn)行。此次經(jīng)驗(yàn)也使我們重新思考,相比移植一個(gè)現(xiàn)有的平臺(tái),是否從頭開(kāi)始構(gòu)建一個(gè)新平臺(tái)更值得。然而缺乏諸如卷積算子等基本的構(gòu)建塊,從頭開(kāi)始構(gòu)建并不容易。此外,從頭開(kāi)始構(gòu)建的推理機(jī)也很難比一個(gè)久經(jīng)測(cè)試的深度學(xué)習(xí)框架表現(xiàn)更優(yōu)。
圖1 TensorFlow對(duì)第三方庫(kù)的依賴(lài)。因?yàn)橐蕾?lài)于許多第三方庫(kù),將現(xiàn)有的深度學(xué)習(xí)平臺(tái)(如TensorFlow)移植到物聯(lián)網(wǎng)設(shè)備并不是一個(gè)簡(jiǎn)單的過(guò)程。
從頭開(kāi)始構(gòu)建推理機(jī)
ARM最近宣布推出其計(jì)算庫(kù)(ACL,developer.arm.com/technologies/compute-library),為ARM Cortex-A系列CPU處理器和ARM Mali系列GPU實(shí)現(xiàn)了軟件功能的綜合集成。具體而言,ACL為CNNs提供了基本的構(gòu)建模塊,包括激活、卷積、全連接和局部連接、規(guī)范化、池化和softmax功能。這些功能正是我們建立推理機(jī)所需要的。
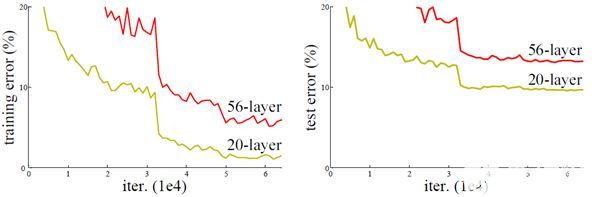
我們使用ACL構(gòu)建塊構(gòu)建了一個(gè)具有SqueezeNet架構(gòu)的CNN推理機(jī),其內(nèi)存占用空間小,適合于嵌入式設(shè)備。SqueezeNet在保持相似的推理精度的同時(shí),使用1×1卷積核來(lái)減少3×3卷積層的輸入大小。然后,我們將SqueezeNet推理機(jī)的性能與Zuluko上的TensorFlow進(jìn)行比較。為了確保比較的公平性,我們啟用了TensorFlow中的ARM NEON向量計(jì)算優(yōu)化,并在創(chuàng)建SqueezeNet引擎時(shí)使用了支持NEON的構(gòu)建塊。確保兩個(gè)引擎都使用了NEON向量計(jì)算,這樣任何性能差異將僅由平臺(tái)本身引起。如圖2所示,平均來(lái)言,TensorFlow處理227×227像素的RGB圖像需要420 ms,而SqueezeNet將處理相同圖像的時(shí)間縮短到320ms,加速了25%。
圖2 在TensorFlow上運(yùn)行的SqueezeNet推理機(jī)與使用ARM Compute Library(ACL)構(gòu)建的SqueezeNet推理機(jī)的性能。從頭開(kāi)始構(gòu)建簡(jiǎn)單的推理引擎不僅需要較少的開(kāi)發(fā)時(shí)間,而且相比現(xiàn)有的深度學(xué)習(xí)引擎,如TensorFlow,表現(xiàn)更加優(yōu)秀。
為了更好地了解性能增益的來(lái)源,我們將執(zhí)行過(guò)程分為兩部分:第一部分包括卷積、ReLU(線(xiàn)性整流函數(shù))激活和級(jí)聯(lián);第二部分包括池化和softmax功能。圖2所示的分析表明,SqueezeNet在第一部分中的性能相比TensorFlow提高23%,在第二部分中提高110%。考慮資源利用率,當(dāng)在TensorFlow上運(yùn)行時(shí),平均CPU使用率為75%,平均內(nèi)存使用量為9MB;當(dāng)在SqueezeNet上運(yùn)行時(shí),平均CPU使用率為90%,平均內(nèi)存使用量約為10MB。兩個(gè)原因帶來(lái)了性能的提升:首先,SqueezeNet提供了更好的NEON優(yōu)化,所有ACL運(yùn)算符都是使用NEON提供的運(yùn)算符直接開(kāi)發(fā)的,而TensorFlow則依靠ARM編譯器來(lái)提供NEON優(yōu)化。其次,TensorFlow平臺(tái)本身可能會(huì)引起一些額外的性能開(kāi)銷(xiāo)。
接下來(lái),我們希望能夠從TensorFlow中榨出更多的性能,看看它是否能勝過(guò)我們構(gòu)建的SqueezeNet推理機(jī)。一種常用的技術(shù)是使用矢量量化,使用8位權(quán)重以精度來(lái)?yè)Q取性能。8位權(quán)重的使用,使得我們可以通過(guò)向量操作,只需一個(gè)指令便可計(jì)算多個(gè)數(shù)據(jù)單元。然而,這種優(yōu)化是有代價(jià)的:它引入了重新量化和去量化操作。我們?cè)赥ensorFlow中實(shí)現(xiàn)了這個(gè)優(yōu)化,圖3比較了有無(wú)優(yōu)化的性能。使用矢量量化將卷積性能提高了25%,但由于去量化和重新量化操作,也顯著地增加了開(kāi)銷(xiāo)。總體而言,它將整個(gè)推理過(guò)程減慢了超過(guò)100毫秒。
圖3 有無(wú)矢量量化的TensorFlow性能。手動(dòng)優(yōu)化現(xiàn)有的深度學(xué)習(xí)平臺(tái)(如TensorFlow)很困難,可能不會(huì)帶來(lái)顯著的性能提升。
網(wǎng)絡(luò)連接是易失的,因此我們想要確保能夠在本地設(shè)備上實(shí)現(xiàn)某種形式的智能,使其能夠在ISP或網(wǎng)絡(luò)故障的情況下繼續(xù)運(yùn)行。然而要想實(shí)現(xiàn)它,需要較高的計(jì)算性能和功耗。
盡管將服務(wù)遷移到云端能夠減少物聯(lián)網(wǎng)設(shè)備的功耗,但很難滿(mǎn)足實(shí)時(shí)性要求。而且現(xiàn)有的深度學(xué)習(xí)平臺(tái)是為了通用性任務(wù)而設(shè)計(jì)開(kāi)發(fā)的,同時(shí)適用于訓(xùn)練和推理任務(wù),這意味著這些引擎未針對(duì)嵌入式推理任務(wù)進(jìn)行優(yōu)化。并且它們還依賴(lài)于裸機(jī)嵌入式系統(tǒng)上不易獲得的其他第三方庫(kù),這些都使其非常難以移植。
通過(guò)使用ACL構(gòu)建塊來(lái)建立嵌入式CNN推理引擎,我們可以充分利用SoC的異構(gòu)計(jì)算資源獲得高性能。因此,問(wèn)題變?yōu)槭沁x擇移植現(xiàn)有引擎,還是從零開(kāi)始構(gòu)建它們更容易。我們的經(jīng)驗(yàn)表明,如果模型很簡(jiǎn)單,相比之下從頭開(kāi)始構(gòu)建它們?nèi)菀椎枚唷6S著模型越來(lái)越復(fù)雜,在某些情況下,可能我們遷移現(xiàn)有引擎相對(duì)更加高效。然而,考慮到嵌入式設(shè)備實(shí)際運(yùn)行的任務(wù),不大可能會(huì)需要用到復(fù)雜的模型。因此我們得出結(jié)論,從頭開(kāi)始構(gòu)建一個(gè)嵌入式推理引擎或許是向物聯(lián)網(wǎng)設(shè)備提供深度學(xué)習(xí)能力的可行方法。
更進(jìn)一步
相比從頭開(kāi)始手動(dòng)構(gòu)建模型,我們需要一種更方便的方式來(lái)在物聯(lián)網(wǎng)設(shè)備上提供深度學(xué)習(xí)能力。一個(gè)解決方案是實(shí)現(xiàn)一個(gè)深度學(xué)習(xí)的模型編譯器,可以將給定的模型經(jīng)過(guò)優(yōu)化,編譯為目標(biāo)平臺(tái)上的可執(zhí)行代碼。如圖4中間的圖所示,這種編譯器的前端可以從主要的深度學(xué)習(xí)平臺(tái)(包括MXNet、Caffe、TensorFlow等)解析模型。然后,優(yōu)化器可以執(zhí)行額外的優(yōu)化,包括模型修剪,量化和異構(gòu)執(zhí)行。優(yōu)化后,由代碼生成器生成目標(biāo)平臺(tái)上可執(zhí)行代碼,可以是ACL(用于ARM設(shè)備),TensorRT(用于Nvidia GPU)或其他ASIC設(shè)備。
圖4 物聯(lián)網(wǎng)設(shè)備服務(wù)架構(gòu)。我們需要一個(gè)新的系統(tǒng)架構(gòu)來(lái)實(shí)現(xiàn)物聯(lián)網(wǎng)設(shè)備上的深度學(xué)習(xí):首先,我們需要直接編譯和優(yōu)化深度學(xué)習(xí)模型生成目標(biāo)設(shè)備上的可執(zhí)行代碼; 其次,我們需要一個(gè)非常輕量級(jí)的操作系統(tǒng),以實(shí)現(xiàn)多任務(wù)及其間的高效通信。IMU:慣性測(cè)量單元。
NNVM項(xiàng)目(github.com/dmlc/nnvm)是邁向這一目標(biāo)的第一步。我們已經(jīng)成功地?cái)U(kuò)展了NNVM來(lái)生成代碼,以便我們可以使用ACL來(lái)加速ARM設(shè)備上的深度學(xué)習(xí)操作。這種方法的另一個(gè)好處是,即使模型變得更加復(fù)雜,我們?nèi)匀豢梢暂p松地在物聯(lián)網(wǎng)設(shè)備上實(shí)現(xiàn)它們。
當(dāng)前的物聯(lián)網(wǎng)設(shè)備通常由于計(jì)算資源的限制而執(zhí)行單個(gè)任務(wù)。然而,我們預(yù)計(jì)很快將有能夠執(zhí)行多個(gè)任務(wù)的低功耗物聯(lián)網(wǎng)設(shè)備(例如,我們的Zuluko設(shè)備就包含了四個(gè)內(nèi)核)。為了使用這些設(shè)備,我們需要一個(gè)非常輕量級(jí)的消息傳遞協(xié)議來(lái)連接不同的服務(wù)。
如圖4所示,物聯(lián)網(wǎng)設(shè)備的基本服務(wù)包括傳感,感知和決策。傳感節(jié)點(diǎn)涉及處理來(lái)自例如攝像機(jī),慣性測(cè)量單元和車(chē)輪測(cè)距的原始傳感器數(shù)據(jù)。感知節(jié)點(diǎn)使用已處理的傳感器數(shù)據(jù),并對(duì)所捕獲的信息進(jìn)行解釋?zhuān)鐚?duì)象標(biāo)簽和設(shè)備位置。動(dòng)作節(jié)點(diǎn)包含一組規(guī)則,用于確定在檢測(cè)到特定事件時(shí)如何響應(yīng),例如在檢測(cè)到所有者的臉部時(shí)解鎖門(mén),或者當(dāng)檢測(cè)到障礙物時(shí)調(diào)整機(jī)器人的運(yùn)動(dòng)路徑。Nanomsg(nanomsg.org)是一個(gè)非常輕量級(jí)的消息傳遞框架,非常適合類(lèi)似的任務(wù)。另一個(gè)選擇是機(jī)器人操作系統(tǒng),盡管我們發(fā)現(xiàn)對(duì)于物聯(lián)網(wǎng)設(shè)備來(lái)說(shuō),其在內(nèi)存占用和計(jì)算資源需求方面顯得太重了。
為了有效地將深度學(xué)習(xí)與物聯(lián)網(wǎng)設(shè)備集成,我們開(kāi)發(fā)了自己的操作系統(tǒng),包括用于消費(fèi)級(jí)傳感器輸入的傳感器接口,基于NNVM的編譯器,將現(xiàn)有的深度學(xué)習(xí)模型編譯并優(yōu)化為可執(zhí)行代碼,以及基于Nanomsg的消息傳輸框架來(lái)連接所有的節(jié)點(diǎn)。
筆者希望本文將激勵(lì)研究人員和開(kāi)發(fā)人員,在比以往更小的嵌入式設(shè)備中設(shè)計(jì)更加智能的物聯(lián)網(wǎng)系統(tǒng)。


















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論