深度學習在圖像超清化的應用
深度學習的出現使得算法對圖像的語義級操作成為可能。本文即是介紹深度學習技術在圖像超清化問題上的最新研究進展。
深度學習最早興起于圖像,其主要處理圖像的技術是卷積神經網絡,關于卷積神經網絡的起源,業界公認是Alex在2012年的ImageNet比賽中的煌煌表現。雖方五年,卻已是老生常談。因此卷積神經網絡的基礎細節本文不再贅述。在下文中,使用CNN(Convolutional Neural Network)來指代卷積神經網絡。
CNN出現以來,催生了很多研究熱點,其中最令人印象深刻的五個熱點是:
深廣探索:VGG網絡的出現標志著CNN在搜索的深度和廣度上有了初步的突破。
結構探索:Inception及其變種的出現進一步增加了模型的深度。而ResNet的出現則使得深度學習的深度變得“名副其實”起來,可以達到上百層甚至上千層。
內容損失:圖像風格轉換是CNN在應用層面的一個小高峰,涌現了一批以Prisma為首的小型創業公司。但圖像風格轉換在技術上的真正貢獻卻是通過一個預訓練好的模型上的特征圖,在語義層面生成圖像。
對抗神經網絡(GAN):雖然GAN是針對機器學習領域的架構創新,但其最初的應用卻是在CNN上。通過對抗訓練,使得生成模型能夠借用監督學習的東風進行提升,將生成模型的質量提升了一個級別。
Pixel CNN:將依賴關系引入到像素之間,是CNN模型結構方法的一次比較大的創新,用于生成圖像,效果最佳,但有失效率。
這五個熱點,在圖像超清這個問題上都有所體現。下面會一一為大家道來。
CNN的第一次出手
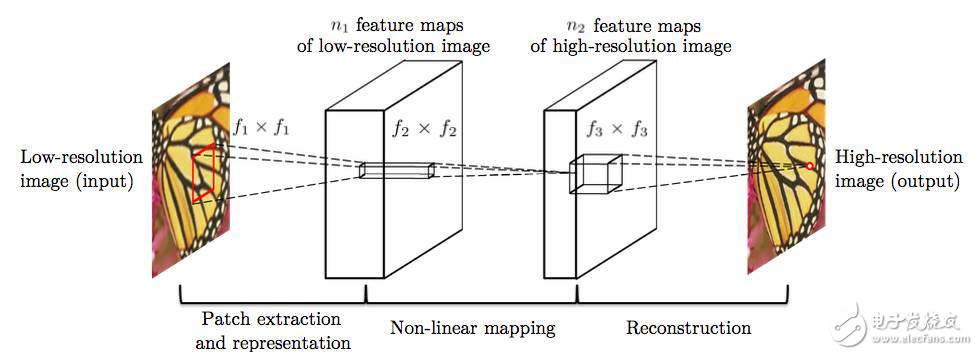
圖2 首個應用于圖像超清問題的CNN網絡結構(輸入為低清圖像,輸出為高清圖像。該結構分為三個步驟:低清圖像的特征抽取、低清特征到高清特征的映射、高清圖像的重建。)
圖像超清問題的特點在于,低清圖像和高清圖像中很大部分的信息是共享的,基于這個前提,在CNN出現之前,業界的解決方案是使用一些特定的方法,如PCA、Sparse Coding等將低分辨率和高分辨率圖像變為特征表示,然后將特征表示做映射。
基于傳統的方法結構,CNN也將模型劃分為三個部分,即特征抽取、非線性映射和特征重建。由于CNN的特性,三個部分的操作均可使用卷積完成。因而,雖然針對模型結構的解釋與傳統方法類似,但CNN卻是可以同時聯合訓練的統一體,在數學上擁有更加簡單的表達。
不僅在模型解釋上可以看到傳統方法的影子,在具體的操作上也可以看到。在上述模型中,需要對數據進行預處理,抽取出很多patch,這些patch可能互有重疊,將這些Patch取合集便是整張圖像。上述的CNN結構是被應用在這些Patch而不是整張圖像上,得到所有圖像的patch后,將這些patch組合起來得到最后的高清圖像,重疊部分取均值。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%