 電子發燒友App
電子發燒友App


引言和數據
歡迎閱讀 Python 機器學習系列教程的回歸部分。這里,你應該已經安裝了 Scikit-Learn。如果沒有,安裝它,以及 Pandas 和 Matplotlib。
pip install numpy
pip install scipy
pip install scikit-learn
pip install matplotlib
pip install pandas
除了這些教程范圍的導入之外,我們還要在這里使用 Quandl:
pip install quandl
首先,對于我們將其用于機器學習而言,什么是回歸呢?它的目標是接受連續數據,尋找最適合數據的方程,并能夠對特定值進行預測。使用簡單的線性回歸,你可以僅僅通過創建最佳擬合直線,來實現它。
?
這里,我們可以使用這條直線的方程,來預測未來的價格,其中日期是 x 軸。
回歸的熱門用法是預測股票價格。由于我們會考慮價格隨時間的流動,并且使用連續的數據集,嘗試預測未來的下一個流動價格,所以可以這樣做。
回歸是監督的機器學習的一種,也就是說,科學家向其展示特征,之后向其展示正確答案來教會機器。一旦教會了機器,科學家就能夠使用一些不可見的數據來測試機器,其中科學家知道正確答案,但是機器不知道。機器的答案會與已知答案對比,并且度量機器的準確率。如果準確率足夠高,科學家就會考慮將其算法用于真實世界。
由于回歸廣泛用于股票價格,我們可以使用一個示例從這里開始。最開始,我們需要數據。有時候數據易于獲取,有時你需要出去并親自收集。我們這里,我們至少能夠以簡單的股票價格和成交量信息開始,它們來自 Quandl。我們會抓取 Google 的股票價格,它的代碼是GOOGL:
import pandas as pd
import quandl
df = quandl.get("WIKI/GOOGL")
print(df.head())
注意:寫這篇文章的時候,Quandl 的模塊使用大寫 Q 引用,但現在是小寫 q,所以import quandl。
到這里,我們擁有:
Open High Low Close Volume Ex-Dividend \
Date
2004-08-19 100.00 104.06 95.96 100.34 44659000 0
2004-08-20 101.01 109.08 100.50 108.31 22834300 0
2004-08-23 110.75 113.48 109.05 109.40 18256100 0
2004-08-24 111.24 111.60 103.57 104.87 15247300 0
2004-08-25 104.96 108.00 103.88 106.00 9188600 0
Split Ratio Adj. Open Adj. High Adj. Low Adj. Close \
Date
2004-08-19 1 50.000 52.03 47.980 50.170
2004-08-20 1 50.505 54.54 50.250 54.155
2004-08-23 1 55.375 56.74 54.525 54.700
2004-08-24 1 55.620 55.80 51.785 52.435
2004-08-25 1 52.480 54.00 51.940 53.000
Adj. Volume
Date
2004-08-19 44659000
2004-08-20 22834300
2004-08-23 18256100
2004-08-24 15247300
2004-08-25 9188600
這是個非常好的開始,我們擁有了數據,但是有點多了。
這里,我們有很多列,許多都是多余的,還有些不怎么變化。我們可以看到,常規和修正(Adj)的列是重復的。修正的列看起來更加理想。常規的列是當天的價格,但是股票有個叫做分拆的東西,其中一股突然就變成了兩股,所以一股的價格要減半,但是公司的價值不變。修正的列為股票分拆而調整,這使得它們對于分析更加可靠。
所以,讓我們繼續,削減原始的 DataFrame。
df = df[['Adj. Open', 'Adj. High', 'Adj. Low', 'Adj. Close', 'Adj. Volume']]
現在我們擁有了修正的列,以及成交量。有一些東西需要注意。許多人談論或者聽說機器學習,就像無中生有的黑魔法。機器學習可以突出已有的數據,但是數據需要先存在。你需要有意義的數據。所以你怎么知道是否有意義呢?我的最佳建議就是,僅僅簡化你的大腦。考慮一下,歷史價格會決定未來價格嗎?有些人這么認為,但是久而久之這被證實是錯誤的。但是歷史規律呢?突出的時候會有意義(機器學習會有所幫助),但是還是太弱了。那么,價格變化和成交量隨時間的關系,再加上歷史規律呢?可能更好一點。所以,你已經能夠看到,并不是數據越多越好,而是我們需要使用有用處的數據。同時,原始數據應該做一些轉換。
考慮每日波動,例如最高價減最低價的百分比差值如何?每日的百分比變化又如何呢?你覺得Open, High, Low, Close這種簡單數據,還是Close, Spread/Volatility, %change daily更好?我覺得后者更好一點。前者都是非常相似的數據點,后者基于前者的統一數據創建,但是帶有更加有價值的信息。
所以,并不是你擁有的所有數據都是有用的,并且有時你需要對你的數據執行進一步的操作,并使其更加有價值,之后才能提供給機器學習算法。讓我們繼續并轉換我們的數據:
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low']) / df['Adj. Close'] * 100.0
這會創建一個新的列,它是基于收盤價的百分比極差,這是我們對于波動的粗糙度量。下面,我們會計算每日百分比變化:
df['PCT_change'] = (df['Adj. Close'] - df['Adj. Open']) / df['Adj. Open'] * 100.0
現在我們會定義一個新的 DataFrame:
df = df[['Adj. Close', 'HL_PCT', 'PCT_change', 'Adj. Volume']]
print(df.head())
Adj. Close HL_PCT PCT_change Adj. Volume
Date
2004-08-19 50.170 8.072553 0.340000 44659000
2004-08-20 54.155 7.921706 7.227007 22834300
2004-08-23 54.700 4.049360 -1.218962 18256100
2004-08-24 52.435 7.657099 -5.726357 15247300
2004-08-25 53.000 3.886792 0.990854 9188600
特征和標簽
基于上一篇機器學習回歸教程,我們將要對我們的股票價格數據執行回歸。目前的代碼:
import quandl
import pandas as pd
df = quandl.get("WIKI/GOOGL")
df = df[['Adj. Open', 'Adj. High', 'Adj. Low', 'Adj. Close', 'Adj. Volume']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low']) / df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj. Open']) / df['Adj. Open'] * 100.0
df = df[['Adj. Close', 'HL_PCT', 'PCT_change', 'Adj. Volume']]
print(df.head())
這里我們已經獲取了數據,判斷出有價值的數據,并通過操作創建了一些。我們現在已經準備好使用回歸開始機器學習的過程。首先,我們需要一些更多的導入。所有的導入是:
import quandl, math
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation, svm
from sklearn.linear_model import LinearRegression
我們會使用numpy模塊來將數據轉換為 NumPy 數組,它是 Sklearn 的預期。我們在用到preprocessing和cross_validation時,會深入談論他們,但是預處理是用于在機器學習之前,對數據清洗和縮放的模塊。交叉驗證在測試階段使用。最后,我們也從 Sklearn 導入了LinearRegression算法,以及svm。它們用作我們的機器學習算法來展示結果。
這里,我們已經獲取了我們認為有用的數據。真實的機器學習如何工作呢?使用監督式學習,你需要特征和標簽。特征就是描述性屬性,標簽就是你嘗試預測的結果。另一個常見的回歸示例就是嘗試為某個人預測保險的保費。保險公司會收集你的年齡、駕駛違規行為、公共犯罪記錄,以及你的信用評分。公司會使用老客戶,獲取數據,并得出應該給客戶的“理想保費”,或者如果他們覺得有利可圖的話,他們會使用實際使用的客戶。
所以,對于訓練機器學習分類器來說,特征是客戶屬性,標簽是和這些屬性相關的保費。
我們這里,什么是特征和標簽呢?我們嘗試預測價格,所以價格就是標簽?如果這樣,什么是特征呢?對于預測我們的價格來說,我們的標簽,就是我們打算預測的東西,實際上是未來價格。這樣,我們的特征實際上是:當前價格、HL 百分比和百分比變化。標簽價格是未來某個點的價格。讓我們繼續添加新的行:
forecast_col = 'Adj. Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.01 * len(df)))
這里,我們定義了預測列,之后我們將任何 NaN 數據填充為 -99999。對于如何處理缺失數據,你有一些選擇,你不能僅僅將 NaN(不是數值)數據點傳給機器學習分類西,你需要處理它。一個主流選項就是將缺失值填充為 -99999。在許多機器學習分類器中,會將其是被為離群點。你也可以僅僅丟棄包含缺失值的所有特征或標簽,但是這樣你可能會丟掉大量的數據。
真實世界中,許多數據集都很混亂。多數股價或成交量數據都很干凈,很少有缺失數據,但是許多數據集會有大量缺失數據。我見過一些數據集,大量的行含有缺失數據。你并不一定想要失去所有不錯的數據,如果你的樣例數據有一些缺失,你可能會猜測真實世界的用例也有一些缺失。你需要訓練、測試并依賴相同數據,以及數據的特征。
最后,我們定義我們需要預測的東西。許多情況下,就像嘗試預測客戶的保費的案例中,你僅僅需要一個數字,但是對于預測來說,你需要預測指定數量的數據點。我們假設我們打算預測數據集整個長度的 1%。因此,如果我們的數據是 100 天的股票價格,我們需要能夠預測未來一天的價格。選擇你想要的那個。如果你只是嘗試預測明天的價格,你應該選取一天之后的數據,而且也只能一天之后的數據。如果你打算預測 10 天,我們可以為每一天生成一個預測。
我們這里,我們決定了,特征是一系列當前值,標簽是未來的價格,其中未來是數據集整個長度的 1%。我們假設所有當前列都是我們的特征,所以我們使用一個簡單的 Pnadas 操作添加一個新的列:
df['label'] = df[forecast_col].shift(-forecast_out)
現在我們擁有了數據,包含特征和標簽。下面我們在實際運行任何東西之前,我們需要做一些預處理和最終步驟,我們在下一篇教程會關注。
訓練和測試
歡迎閱讀 python 機器學習系列教程的第四部分。在上一個教程中,我們獲取了初始數據,按照我們的喜好操作和轉換數據,之后我們定義了我們的特征。Scikit 不需要處理 Pandas 和 DataFrame,我出于自己的喜好而處理它,因為它快并且高效。反之,Sklearn 實際上需要 NumPy 數組。Pandas 的 DataFrame 可以輕易轉換為 NumPy 數組,所以事情就是這樣的。
目前為止我們的代碼:
import quandl, math
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation, svm
from sklearn.linear_model import LinearRegression
df = quandl.get("WIKI/GOOGL")
print(df.head())
#print(df.tail())
df = df[['Adj. Open', 'Adj. High', 'Adj. Low', 'Adj. Close', 'Adj. Volume']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low']) / df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj. Open']) / df['Adj. Open'] * 100.0
df = df[['Adj. Close', 'HL_PCT', 'PCT_change', 'Adj. Volume']]
print(df.head())
forecast_col = 'Adj. Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.01 * len(df)))
df['label'] = df[forecast_col].shift(-forecast_out)
我們之后要丟棄所有仍舊是 NaN 的信息。
df.dropna(inplace=True)
對于機器學習來說,通常要定義X(大寫)作為特征,和y(小寫)作為對于特征的標簽。這樣,我們可以定義我們的特征和標簽,像這樣:
X = np.array(df.drop(['label'], 1))
y = np.array(df['label'])
上面,我們所做的就是定義X(特征),是我們整個的 DataFrame,除了label列,并轉換為 NumPy 數組。我們使用drop方法,可以用于 DataFrame,它返回一個新的 DataFrame。下面,我們定義我們的y變量,它是我們的標簽,僅僅是 DataFrame 的標簽列,并轉換為 NumPy 數組。
現在我們就能告一段落,轉向訓練和測試了,但是我們打算做一些預處理。通常,你希望你的特征在 -1 到 1 的范圍內。這可能不起作用,但是通常會加速處理過程,并有助于準確性。因為大家都使用這個范圍,它包含在了 Sklearn 的preprocessing模塊中。為了使用它,你需要對你的X變量調用preprocessing.scale。
X = preprocessing.scale(X)
下面,創建標簽y:
y = np.array(df['label'])
現在就是訓練和測試的時候了。方式就是選取 75% 的數據用于訓練機器學習分類器。之后選取剩下的 25% 的數據用于測試分類器。由于這是你的樣例數據,你應該擁有特征和一直標簽。因此,如果你測試后 25% 的數據,你就會得到一種準確度和可靠性,叫做置信度。有許多方式可以實現它,但是,最好的方式可能就是使用內建的cross_validation,因為它也會為你打亂數據。代碼是這樣:
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
這里的返回值是特征的訓練集、測試集、標簽的訓練集和測試集。現在,我們已經定義好了分類器。Sklearn 提供了許多通用的分類器,有一些可以用于回歸。我們會在這個例子中展示一些,但是現在,讓我們使用svm包中的支持向量回歸。
clf = svm.SVR()
我們這里僅僅使用默認選項來使事情簡單,但是你可以在sklearn.svm.SVR的文檔中了解更多。
一旦你定義了分類器,你就可以訓練它了。在 Sklearn 中,使用fit來訓練。
clf.fit(X_train, y_train)
這里,我們擬合了我們的訓練特征和訓練標簽。
我們的分類器現在訓練完畢。這非常簡單,現在我們可以測試了。
confidence = clf.score(X_test, y_test)
加載測試,之后:
print(confidence)
# 0.960075071072
所以這里,我們可以看到準確率幾乎是 96%。沒有什么可說的,讓我們嘗試另一個分類器,這一次使用LinearRegression:
clf = LinearRegression()
# 0.963311624499
更好一點,但是基本一樣。所以作為科學家,我們如何知道,選擇哪個算法呢?不久,你會熟悉什么在多數情況下都工作,什么不工作。你可以從 Scikit 的站點上查看選擇正確的評估工具。這有助于你瀏覽一些基本的選項。如果你詢問搞機器學習的人,它完全是試驗和出錯。你會嘗試大量的算法并且僅僅選取最好的那個。要注意的另一件事情就是,一些算法必須線性運行,其它的不是。不要把線性回歸和線性運行搞混了。所以這些意味著什么呢?一些機器學習算法會一次處理一步,沒有多線程,其它的使用多線程,并且可以利用你機器上的多核。你可以深入了解每個算法,來弄清楚哪個可以多線程,或者你可以閱讀文檔,并查看n_jobs參數。如果擁有n_jobs,你就可以讓算法通過多線程來獲取更高的性能。如果沒有,就很不走運了。所以,如果你處理大量的數據,或者需要處理中等規模的數據,但是需要很高的速度,你就可能想要線程加速。讓我們看看這兩個算法。
訪問sklearn.svm.SVR的文檔,并查看參數,看到n_jobs了嘛?反正我沒看到,所以它就不能使用線程。你可能會看到,在我們的小型數據集上,差異不大。但是,假設數據集由 20MB,差異就很明顯。然后,我們查看LinearRegression算法,看到n_jobs了嘛?當然,所以這里,你可以指定你希望多少線程。如果你傳入-1,算法會使用所有可用的線程。
這樣:
clf = LinearRegression(n_jobs=-1)
就夠了。雖然我讓你做了很少的事情(查看文檔),讓我給你說個事實吧,僅僅由于機器學習算法使用默認參數工作,不代表你可以忽略它們。例如,讓我們回顧svm.SVR。SVR 是支持向量回歸,在執行機器學習時,它是一種架構。我非常鼓勵那些有興趣學習更多的人,去研究這個主題,以及向比我學歷更高的人學習基礎。我會盡力把東西解釋得更簡單,但是我并不是專家。回到剛才的話題,svm.SVR有一個參數叫做kernel。這個是什么呢?核就相當于你的數據的轉換。這使得處理過程更加迅速。在svm.SVR的例子中,默認值是rbf,這是核的一個類型,你有一些選擇。查看文檔,你可以選擇'linear', 'poly', 'rbf', 'sigmoid', 'precomputed'或者一個可調用對象。同樣,就像嘗試不同的 ML 算法一樣,你可以做你想做的任何事情,嘗試一下不同的核吧。
for k in ['linear','poly','rbf','sigmoid']:
clf = svm.SVR(kernel=k)
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
print(k,confidence)
linear 0.960075071072
poly 0.63712232551
rbf 0.802831714511
sigmoid -0.125347960903
我們可以看到,線性的核表現最好,之后是rbf,之后是poly,sigmoid很顯然是個擺設,并且應該移除。
所以我們訓練并測試了數據集。我們已經有 71% 的滿意度了。下面我們做什么呢?現在我們需要再進一步,做一些預測,下一章會涉及它。
預測
歡迎閱讀機器學習系列教程的第五章,當前涉及到回歸。目前為止,我們收集并修改了數據,訓練并測試了分類器。這一章中,我們打算使用我們的分類器來實際做一些預測。我們目前所使用的代碼為:
import quandl, math
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation, svm
from sklearn.linear_model import LinearRegression
df = quandl.get("WIKI/GOOGL")
df = df[['Adj. Open', 'Adj. High', 'Adj. Low', 'Adj. Close', 'Adj. Volume']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low']) / df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj. Open']) / df['Adj. Open'] * 100.0
df = df[['Adj. Close', 'HL_PCT', 'PCT_change', 'Adj. Volume']]
forecast_col = 'Adj. Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.01 * len(df)))
df['label'] = df[forecast_col].shift(-forecast_out)
X = np.array(df.drop(['label'], 1))
X = preprocessing.scale(X)
X = X[:-forecast_out]
df.dropna(inplace=True)
y = np.array(df['label'])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
clf = LinearRegression(n_jobs=-1)
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
print(confidence)
我會強調,準確率大于 95% 的線性模型并不是那么好。我當然不會用它來交易股票。仍然有一些需要考慮的問題,特別是不同公司有不同的價格軌跡。Google 非常線性,向右上角移動,許多公司不是這樣,所以要記住。現在,為了做預測,我們需要一些數據。我們決定預測 1% 的數據,因此我們打算,或者至少能夠預測數據集的后 1%。所以我們什么可以這樣做呢?我們什么時候可以識別這些數據?我們現在就可以,但是要注意我們嘗試預測的數據,并沒有像訓練集那樣縮放。好的,那么做什么呢?是否要對后 1% 調用preprocessing.scale()?縮放方法基于所有給它的已知數據集。理想情況下,你應該一同縮放訓練集、測試集和用于預測的數據。這永遠是可能或合理的嘛?不是,如果你可以這么做,你就應該這么做。但是,我們這里,我們可以這么做。我們的數據足夠小,并且處理時間足夠低,所以我們會一次性預處理并縮放數據。
在許多例子中,你不能這么做。想象如果你使用幾個 GB 的數據來訓練分類器。訓練分類器會花費幾天,不能在每次想要做出預測的時候都這么做。因此,你可能需要不縮放任何東西,或者單獨縮放數據。通常,你可能希望測試這兩個選項,并看看那個對于你的特定案例更好。
要記住它,讓我們在定義X的時候處理所有行:
X = np.array(df.drop(['label'], 1))
X = preprocessing.scale(X)
X_lately = X[-forecast_out:]
X = X[:-forecast_out]
df.dropna(inplace=True)
y = np.array(df['label'])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
clf = LinearRegression(n_jobs=-1)
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
print(confidence)
要注意我們首先獲取所有數據,預處理,之后再分割。我們的X_lately變量包含最近的特征,我們需要對其進行預測。目前你可以看到,定義分類器、訓練、和測試都非常簡單。預測也非常簡單:
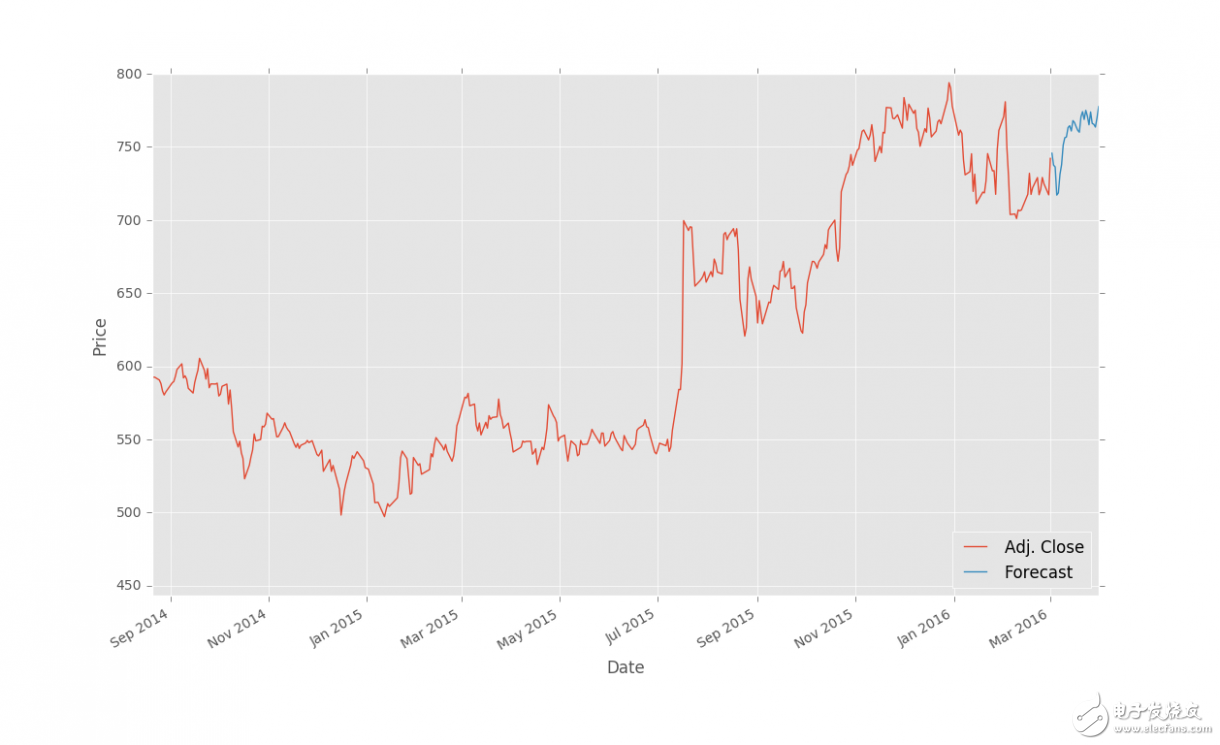
forecast_set = clf.predict(X_lately)
forecast_set是預測值的數組,表明你不僅僅可以做出單個預測,還可以一次性預測多個值。看看我們目前擁有什么:
[ 745.67829395 737.55633261 736.32921413 717.03929303 718.59047951
731.26376715 737.84381394 751.28161162 756.31775293 756.76751056
763.20185946 764.52651181 760.91320031 768.0072636 766.67038016
763.83749414 761.36173409 760.08514166 770.61581391 774.13939706
768.78733341 775.04458624 771.10782342 765.13955723 773.93369548
766.05507556 765.4984563 763.59630529 770.0057166 777.60915879] 0.956987938167 30
所以這些就是我們的預測結果,然后呢?已經基本完成了,但是我們可以將其可視化。股票價格是每一天的,一周 5 天,周末沒有。我知道這個事實,但是我們打算將其簡化,把每個預測值當成每一天的。如果你打算處理周末的間隔(不要忘了假期),就去做吧,但是我這里會將其簡化。最開始,我們添加一些新的導入:
import datetime
import matplotlib.pyplot as plt
from matplotlib import style
我導入了datetime來處理datetime對象,Matplotlib 的pyplot包用于繪圖,以及style來使我們的繪圖更加時髦。讓我們設置一個樣式:
style.use('ggplot')
之后,我們添加一個新的列,forecast列:
df['Forecast'] = np.nan
我們首先將值設置為 NaN,但是我們之后會填充他。
預測集的標簽正好從明天開始。因為我們要預測未來m = 0.1 * len(df)天的數據,相當于把收盤價往前移動m天生成標簽。那么數據集的后m個是不能用作訓練集和測試集的,因為沒有標簽。于是我們將后m個數據用作預測集。預測集的第一個數據,也就是數據集的第n - m個數據,它的標簽應該是n - m + m = n天的收盤價,我們知道今天在df里面是第n - 1天,那么它就是明天。
我們首先需要抓取 DataFrame 的最后一天,將每一個新的預測值賦給新的日期。我們會這樣開始。
last_date = df.iloc[-1].name
last_unix = last_date.timestamp()
one_day = 86400
next_unix = last_unix + one_day
現在我們擁有了預測集的起始日期,并且一天有 86400 秒。現在我們將預測添加到現有的 DataFrame 中。
for i in forecast_set:
next_date = datetime.datetime.fromtimestamp(next_unix)
next_unix += 86400
df.loc[next_date] = [np.nan for _ in range(len(df.columns)-1)]+[i]
我們這里所做的是,迭代預測集的標簽,獲取每個預測值和日期,之后將這些值放入 DataFrame(使預測集的特征為 NaN)。最后一行的代碼創建 DataFrame 中的一行,所有元素置為 NaN,然后將最后一個元素置為i(這里是預測集的標簽)。我選擇了這種單行的for循環,以便在改動 DataFrame 和特征之后,代碼還能正常工作。所有東西都做完了嗎?將其繪制出來。
df['Adj. Close'].plot()
df['Forecast'].plot()
plt.legend(loc=4)
plt.xlabel('Date')
plt.ylabel('Price')
plt.show()
完整的代碼:
import Quandl, math
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation, svm
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from matplotlib import style
import datetime
style.use('ggplot')
df = Quandl.get("WIKI/GOOGL")
df = df[['Adj. Open', 'Adj. High', 'Adj. Low', 'Adj. Close', 'Adj. Volume']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low']) / df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj. Open']) / df['Adj. Open'] * 100.0
df = df[['Adj. Close', 'HL_PCT', 'PCT_change', 'Adj. Volume']]
forecast_col = 'Adj. Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.01 * len(df)))
df['label'] = df[forecast_col].shift(-forecast_out)
X = np.array(df.drop(['label'], 1))
X = preprocessing.scale(X)
X_lately = X[-forecast_out:]
X = X[:-forecast_out]
df.dropna(inplace=True)
y = np.array(df['label'])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
clf = LinearRegression(n_jobs=-1)
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
forecast_set = clf.predict(X_lately)
df['Forecast'] = np.nan
last_date = df.iloc[-1].name
last_unix = last_date.timestamp()
one_day = 86400
next_unix = last_unix + one_day
for i in forecast_set:
next_date = datetime.datetime.fromtimestamp(next_unix)
next_unix += 86400
df.loc[next_date] = [np.nan for _ in range(len(df.columns)-1)]+[i]
df['Adj. Close'].plot()
df['Forecast'].plot()
plt.legend(loc=4)
plt.xlabel('Date')
plt.ylabel('Price')
plt.show()
結果:
?
保存和擴展
上一篇教程中,我們使用回歸完成了對股票價格的預測,并使用 Matplotlib 可視化。這個教程中,我們會討論一些接下來的步驟。
我記得我第一次嘗試學習機器學習的時候,多數示例僅僅涉及到訓練和測試的部分,完全跳過了預測部分。對于那些包含訓練、測試和預測部分的教程來說,我沒有找到一篇解釋保存算法的文章。在那些例子中,數據通常非常小,所以訓練、測試和預測過程都很快。在真實世界中,數據都非常大,并且花費更長時間來處理。由于沒有一篇教程真正談論到這一重要的過程,我打算包含一些處理時間和保存算法的信息。
雖然我們的機器學習分類器花費幾秒來訓練,在一些情況下,訓練分類器需要幾個小時甚至是幾天。想象你想要預測價格的每天都需要這么做。這不是必要的,因為我們呢可以使用 Pickle 模塊來保存分類器。首先確保你導入了它:
import pickle
使用 Pickle,你可以保存 Python 對象,就像我們的分類器那樣。在定義、訓練和測試你的分類器之后,添加:
with open('linearregression.pickle','wb') as f:
pickle.dump(clf, f)
現在,再次執行腳本,你應該得到了linearregression.pickle,它是分類器的序列化數據。現在,你需要做的所有事情就是加載pickle文件,將其保存到clf,并照常使用,例如:
pickle_in = open('linearregression.pickle','rb')
clf = pickle.load(pickle_in)
代碼中:
import Quandl, math
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation, svm
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from matplotlib import style
import datetime
import pickle
style.use('ggplot')
df = Quandl.get("WIKI/GOOGL")
df = df[['Adj. Open', 'Adj. High', 'Adj. Low', 'Adj. Close', 'Adj. Volume']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low']) / df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj. Open']) / df['Adj. Open'] * 100.0
df = df[['Adj. Close', 'HL_PCT', 'PCT_change', 'Adj. Volume']]
forecast_col = 'Adj. Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.1 * len(df)))
df['label'] = df[forecast_col].shift(-forecast_out)
X = np.array(df.drop(['label'], 1))
X = preprocessing.scale(X)
X_lately = X[-forecast_out:]
X = X[:-forecast_out]
df.dropna(inplace=True)
y = np.array(df['label'])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
#COMMENTED OUT:
##clf = svm.SVR(kernel='linear')
##clf.fit(X_train, y_train)
##confidence = clf.score(X_test, y_test)
##print(confidence)
pickle_in = open('linearregression.pickle','rb')
clf = pickle.load(pickle_in)
forecast_set = clf.predict(X_lately)
df['Forecast'] = np.nan
last_date = df.iloc[-1].name
last_unix = last_date.timestamp()
one_day = 86400
next_unix = last_unix + one_day
for i in forecast_set:
next_date = datetime.datetime.fromtimestamp(next_unix)
next_unix += 86400
df.loc[next_date] = [np.nan for _ in range(len(df.columns)-1)]+[i]
df['Adj. Close'].plot()
df['Forecast'].plot()
plt.legend(loc=4)
plt.xlabel('Date')
plt.ylabel('Price')
plt.show()
?
?
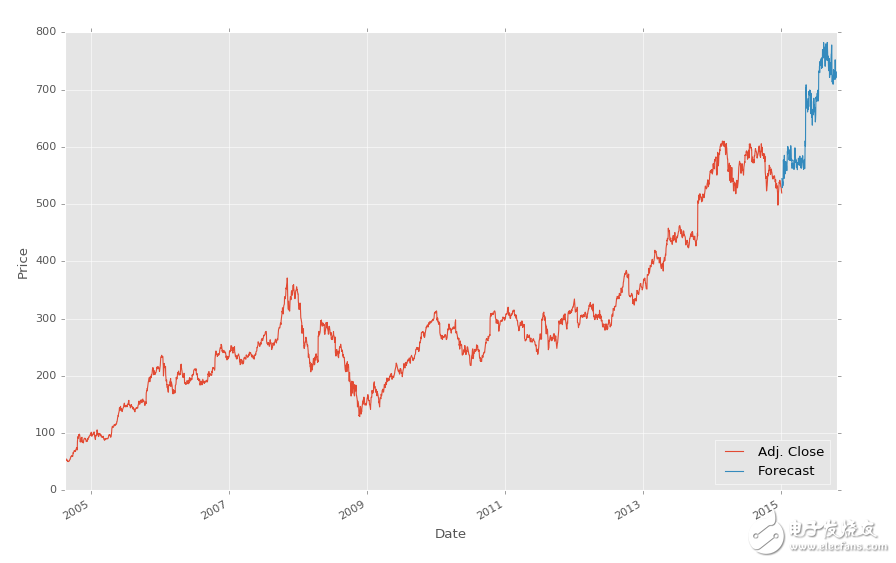
要注意我們注釋掉了分類器的原始定義,并替換為加載我們保存的分類器。就是這么簡單。
最后,我們要討論一下效率和保存時間,前幾天我打算提出一個相對較低的范式,這就是臨時的超級計算機。嚴肅地說,隨著按需主機服務的興起,例如 AWS、DO 和 Linode,你能夠按照小時來購買主機。虛擬服務器可以在 60 秒內建立,所需的模塊可以在 15 分鐘內安裝,所以非常有限。你可以寫一個 shell 腳本或者什么東西來給它加速。考慮你需要大量的處理,并且還沒有一臺頂級計算機,或者你使用筆記本。沒有問題,只需要啟動一臺服務器。
我對這個方式的最后一個注解是,使用任何主機,你通常都可以建立一個非常小型的服務器,加載所需的東西,之后擴展這個服務器。我喜歡以一個小型服務器開始,之后,我準備好的時候,我會改變它的尺寸,給它升級。完成之后,不要忘了注銷或者降級你的服務器。
理論以及工作原理
歡迎閱讀第七篇教程。目前為止,你已經看到了線性回歸的價值,以及如何使用 Sklearn 來應用它。現在我們打算深入了解它如何計算。雖然我覺得不必要深入到每個機器學習算法數學中(你有沒有進入到你最喜歡的模塊的源碼中,看看它是如何實現的?),線性代數是機器學習的本質,并且對于理解機器學習的構建基礎十分實用。
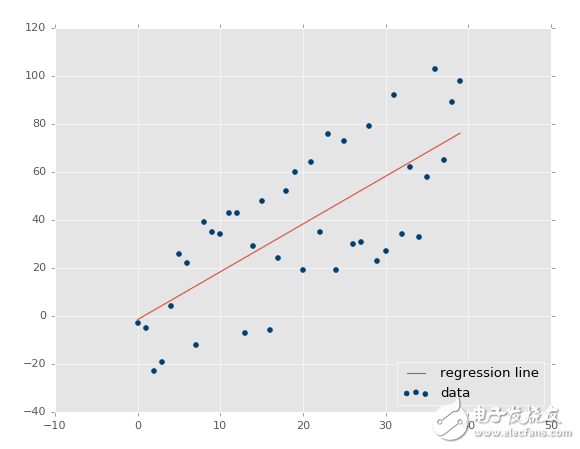
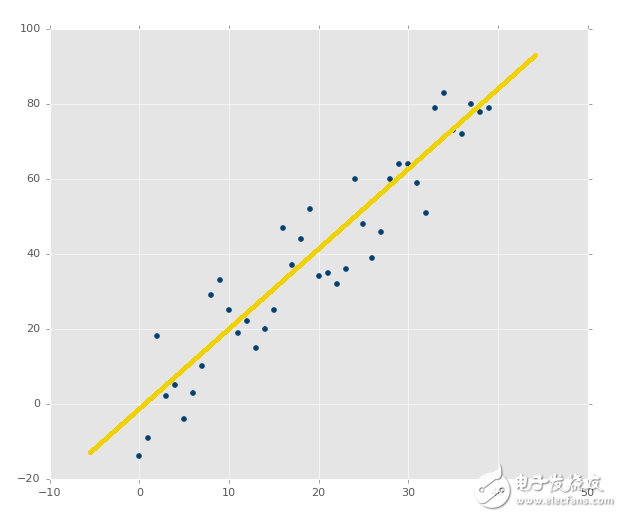
線性代數的目標是計算向量空間中的點的關系。這可以用于很多事情,但是某天,有個人有了個非常狂野的想法,拿他處理數據集的特征。我們也可以。記得之前我們定義數據類型的時候,線性回歸處理連續數據嗎?這并不是因為使用線性回歸的人,而是因為組成它的數學。簡單的線性回歸可用于尋找數據集的最佳擬合直線。如果數據不是連續的,就不是最佳擬合直線。讓我們看看一些示例。
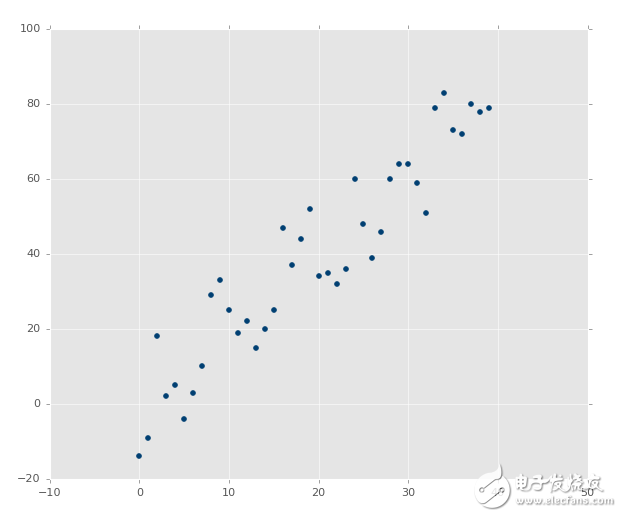
協方差
?
上面的圖像顯然擁有良好的協方差。如果你通過估計畫一條最佳擬合直線,你應該能夠輕易畫出來:
?
如果圖像是這樣呢?
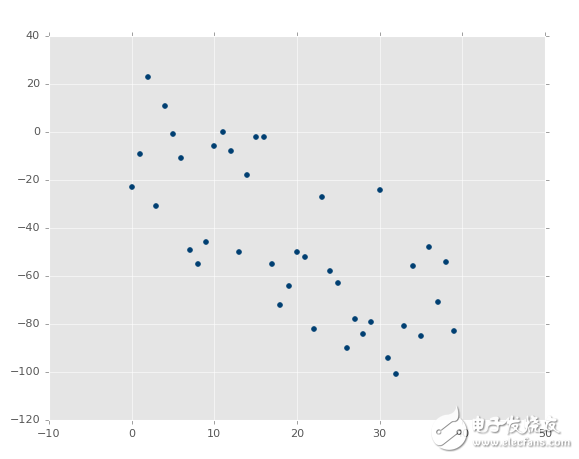
?
并不和之前一樣,但是是清楚的負相關。你可能能夠畫出最佳擬合直線,但是更可能畫不出來。
最后,這個呢?
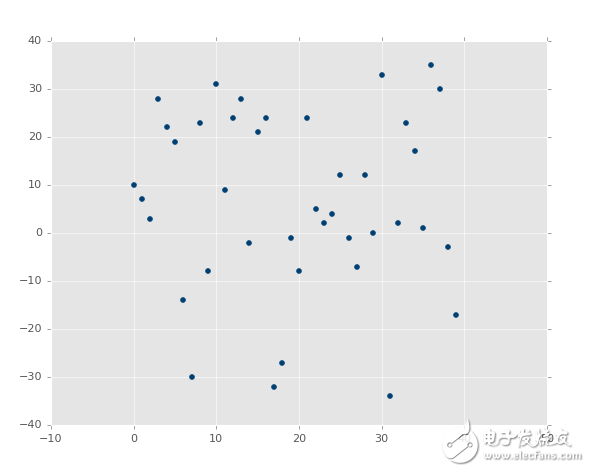
?
啥?的確有最佳擬合直線,但是需要運氣將其畫出來。
將上面的圖像看做特征的圖像,所以 X 坐標是特征,Y 坐標是相關的標簽。X 和 Y 是否有任何形式的結構化關系呢?雖然我們可以準確計算關系,未來我們就不太可能擁有這么多值了。
在其它圖像的案例中,X 和 Y 之間顯然存在關系。我們實際上可以探索這種關系,之后沿著我們希望的任何點繪圖。我們可以拿 Y 來預測 X,或者拿 X 來預測 Y,對于任何我們可以想到的點。我們也可以預測我們的模型有多少的誤差,即使模型只有一個點。我們如何實現這個魔法呢?當然是線性代數。
首先,讓我們回到中學,我們在那里復習直線的定義:y = mx + b,其中m是斜率,b是縱截距。這可以是用于求解y的方程,我們可以將其變形來求解x,使用基本的代數原則:x = (y-b)/m。
好的,所以,我們的目標是尋找最佳擬合直線。不是僅僅是擬合良好的直線,而是最好的那條。這條直線的定義就是y = mx + b。y就是答案(我們其他的坐標,或者甚至是我們的特征),所以我們仍然需要m(斜率)和b(縱截距),由于x可能為沿 x 軸的任一點,所以它是已知的。
最佳擬合直線的斜率m定義為:
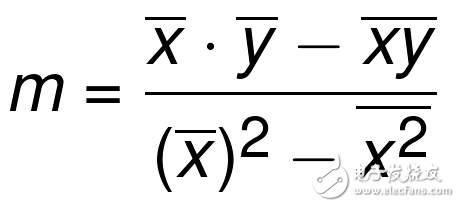
?
注:可簡寫為m = cov(x, y) / var(x)。
符號上面的橫杠代表均值。如果兩個符號挨著,就將其相乘。xs 和 ys 是所有已知坐標。所以我們現在求出了y=mx+b最佳擬合直線定義的m(斜率),現在我們僅僅需要b(縱截距)。這里是公式:
好的。整個部分不是個數學教程,而是個編程教程。下一個教程中,我們打算這樣做,并且解釋為什么我要編程實現它,而不是直接用模塊。
編程計算斜率
歡迎閱讀第八篇教程,我們剛剛意識到,我們需要使用 Python 重復編寫一些比較重要的算法,來嘗試給定數據集的計算最佳擬合直線。
在我們開始之前,為什么我們會有一些小麻煩呢?線性回歸是機器學習的構建基礎。它幾乎用于每個單獨的主流機器學習算法之中,所以對它的理解有助于你掌握多數主流機器學習算法。出于我們的熱情,理解線性回歸和線性代數,是編寫你自己的機器學習算法,以及跨入機器學習前沿,使用當前最佳的處理過程的第一步。由于處理過程的優化和硬件架構的改變。用于機器學習的方法論也會改變。最近出現的神經網絡,使用大量 GPU 來完成工作。你想知道什么是神經網絡的核心嗎?你猜對了,線性代數。
如果你能記得,最佳擬合直線的斜率m:
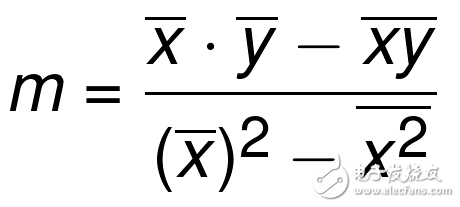
?
是的,我們會將其拆成片段。首先,進行一些導入:
from statistics import mean
import numpy as np
我們從statistics導入mean,所以我們可以輕易獲取列表的均值。下面,我們使numpy as np,所以我們可以其創建 NumPy 數組。我們可以對列表做很多事情,但是我們需要能夠做一些簡單的矩陣運算,它并不對簡單列表提供,所以我們使用 NumPy。我們在這個階段不會使用太復雜的 NumPy,但是之后 NumPy 就會成為你的最佳伙伴。下面,讓我們定義一些起始點吧。
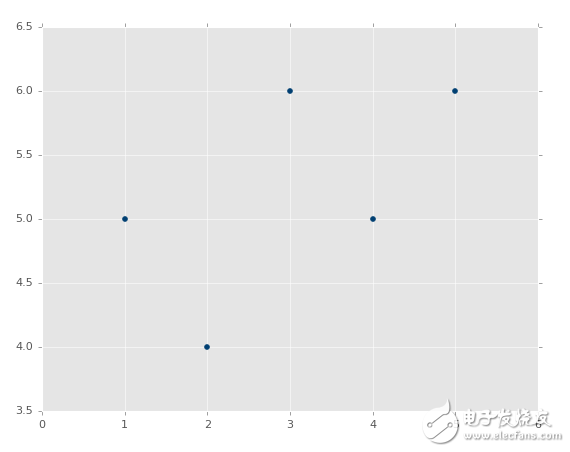
xs = [1,2,3,4,5]
ys = [5,4,6,5,6]
所以這里有一些我們要使用的數據點,xs和ys。你可以認為xs就是特征,ys就是標簽,或者他們都是特征,我們想要建立他們的聯系。之前提到過,我們實際上把它們變成 NumPy 數組,以便執行矩陣運算。所以讓我們修改這兩行:
xs = np.array([1,2,3,4,5], dtype=np.float64)
ys = np.array([5,4,6,5,6], dtype=np.float64)
現在他們都是 NumPy 數組了。我們也顯式聲明了數據類型。簡單講一下,數據類型有特性是屬性,這些屬性決定了數據本身如何儲存和操作。現在它不是什么問題,但是如果我們執行大量運算,并希望他們跑在 GPU 而不是 CPU 上就是了。
將其畫出來,他們是:
?
現在我們準備好構建函數來計算m,也就是我們的直線斜率:
def best_fit_slope(xs,ys):
return m
m = best_fit_slope(xs,ys)
好了。開個玩笑,所以這是我們的框架,現在我們要填充了。
我們的第一個邏輯就是計算xs的均值,再乘上ys的均值。繼續填充我們的框架:
def best_fit_slope(xs,ys):
m = (mean(xs) * mean(ys))
return m
目前為止還很簡單。你可以對列表、元組或者數組使用mean函數。要注意我這里使用了括號。Python 的遵循運算符的數學優先級。所以如果你打算保證順序,要顯式使用括號。要記住你的運算規則。
下面我們需要將其減去x*y的均值。這既是我們的矩陣運算mean(xs*ys)。現在的代碼是:
def best_fit_slope(xs,ys):
m = ( (mean(xs)*mean(ys)) - mean(xs*ys) )
return m
我們完成了公式的分子部分,現在我們繼續處理的分母,以x的均值平方開始:(mean(xs)*mean(xs))。Python 支持** 2,能夠處理我們的 NumPy 數組的float64類型。添加這些東西:
def best_fit_slope(xs,ys):
m = ( ((mean(xs)*mean(ys)) - mean(xs*ys)) /
(mean(xs)**2))
return m
雖然根據運算符優先級,向整個表達式添加括號是不必要的。我這里這樣做,所以我可以在除法后面添加一行,使整個式子更加易讀和易理解。不這樣的話,我們會在新的一行得到語法錯誤。我們幾乎完成了,現在我們只需要將x的均值平方和x的平方均值(mean(xs*xs))相減。全部代碼為:
def best_fit_slope(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)**2) - mean(xs*xs)))
return m
好的,現在我們的完整腳本為:
from statistics import mean
import numpy as np
xs = np.array([1,2,3,4,5], dtype=np.float64)
ys = np.array([5,4,6,5,6], dtype=np.float64)
def best_fit_slope(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)**2) - mean(xs**2)))
return m
m = best_fit_slope(xs,ys)
print(m)
# 0.3
下面干什么?我們需要計算縱截距b。我們會在下一個教程中處理它,并完成完整的最佳擬合直線計算。它比斜率更佳易于計算,嘗試編寫你自己的函數來計算它。如果你做到了,也不要跳過下一個教程,我們會做一些別的事情。
計算縱截距
歡迎閱讀第九篇教程。我們當前正在為給定的數據集,使用 Python 計算回歸或者最佳擬合直線。之前,我們編寫了一個函數來計算斜率,現在我們需要計算縱截距。我們目前的代碼是:
from statistics import mean
import numpy as np
xs = np.array([1,2,3,4,5], dtype=np.float64)
ys = np.array([5,4,6,5,6], dtype=np.float64)
def best_fit_slope(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)*mean(xs)) - mean(xs*xs)))
return m
m = best_fit_slope(xs,ys)
print(m)
請回憶,最佳擬合直線的縱截距是:
這個比斜率簡單多了。我們可以將其寫到同一個函數來節省幾行代碼。我們將函數重命名為best_fit_slope_and_intercept。
下面,我們可以填充b = mean(ys) - (m*mean(xs)),并返回m, b:
def best_fit_slope_and_intercept(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)*mean(xs)) - mean(xs*xs)))
b = mean(ys) - m*mean(xs)
return m, b
現在我們可以調用它:
best_fit_slope_and_intercept(xs,ys)
我們目前為止的代碼:
from statistics import mean
import numpy as np
xs = np.array([1,2,3,4,5], dtype=np.float64)
ys = np.array([5,4,6,5,6], dtype=np.float64)
def best_fit_slope_and_intercept(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)*mean(xs)) - mean(xs*xs)))
b = mean(ys) - m*mean(xs)
return m, b
m, b = best_fit_slope_and_intercept(xs,ys)
print(m,b)
# 0.3, 4.3
現在我們僅僅需要為數據創建一條直線:
?
要記住y=mx+b,我們能夠為此編寫一個函數,或者僅僅使用一行的for循環。
regression_line = [(m*x)+b for x in xs]
上面的一行for循環和這個相同:
regression_line = []
for x in xs:
regression_line.append((m*x)+b)
好的,讓我們收取我們的勞動果實吧。添加下面的導入:
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
我們可以繪制圖像,并且不會特備難看。現在:
plt.scatter(xs,ys,color='#003F72')
plt.plot(xs, regression_line)
plt.show()
首先我們繪制了現有數據的散點圖,之后我們繪制了我們的回歸直線,之后展示它。如果你不熟悉,可以查看 Matplotlib 教程集。
輸出:
?
所以,如何基礎這個模型來做一些實際的預測呢?很簡單,你擁有了模型,只要填充x就行了。例如,讓我們預測一些點:
predict_x = 7
我們輸入了數據,也就是我們的特征。那么標簽呢?
predict_y = (m*predict_x)+b
print(predict_y)
# 6.4
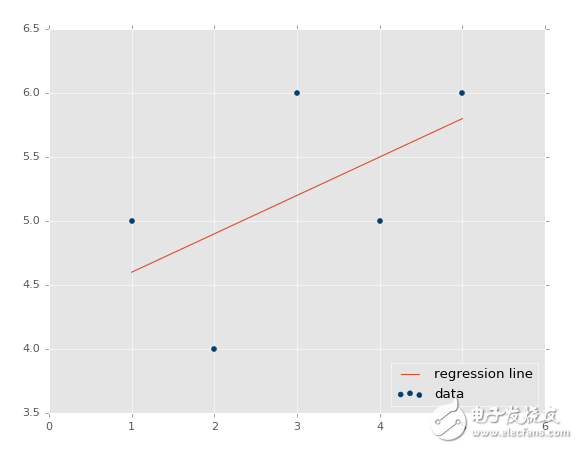
我們也可以繪制它:
predict_x = 7
predict_y = (m*predict_x)+b
plt.scatter(xs,ys,color='#003F72',label='data')
plt.plot(xs, regression_line, label='regression line')
plt.legend(loc=4)
plt.show()
輸出:
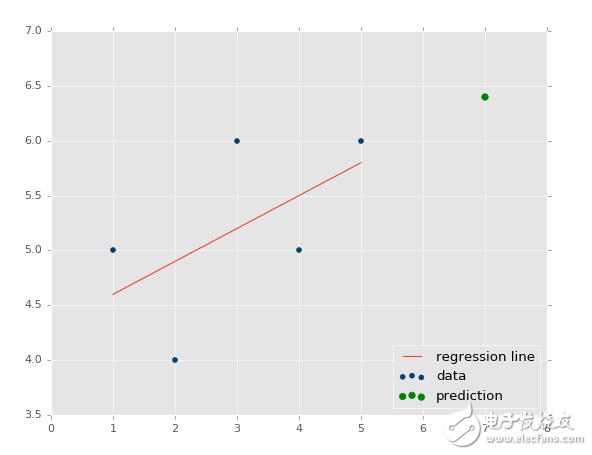
?
我們現在知道了如何創建自己的模型,這很好,但是我們仍舊缺少了一些東西,我們的模型有多精確?這就是下一個教程的話題了。
R 平方和判定系數原理
歡迎閱讀第十篇教程。我們剛剛完成了線性模型的創建和處理,現在我們好奇接下來要干什么。現在,我們可以輕易觀察數,并決定線性回歸模型有多么準確。但是,如果你的線性回歸模型是拿神經網絡的 20 個層級做出來的呢?不僅僅是這樣,你的模型以步驟或者窗口工作,也就是一共 5 百萬個數據點,一次只顯示 100 個,會怎么樣?你需要一些自動化的方式來判斷你的最佳擬合直線有多好。
回憶之前,我們展示幾個繪圖的時候,你已經看到,最佳擬合直線好還是不好。像這樣:
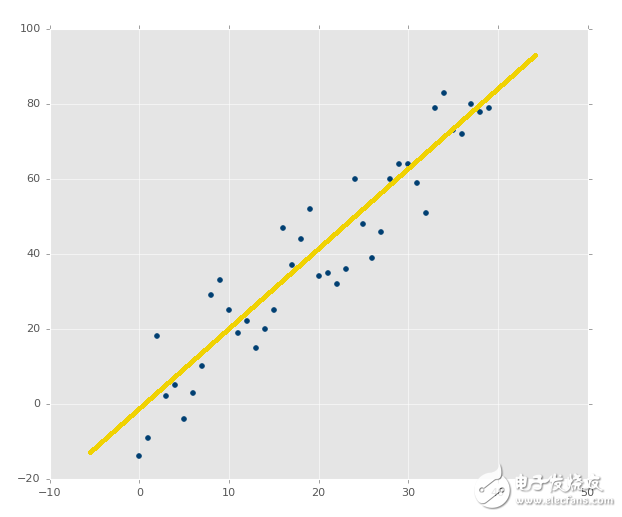
?
與這個相比:
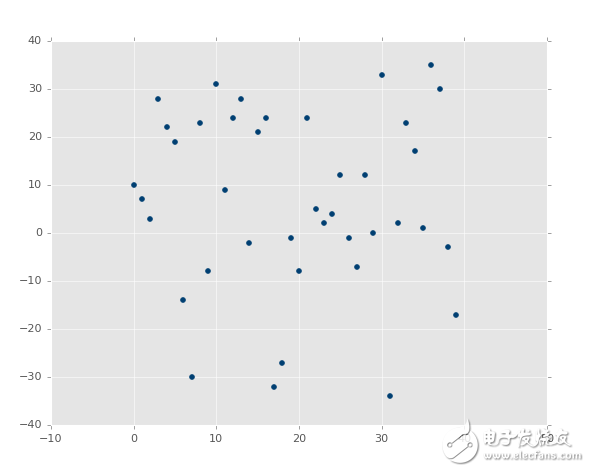
?
第二張圖片中,的確有最佳擬合直線,但是沒有人在意。即使是最佳擬合直線也是沒有用的。并且,我們想在花費大量計算能力之前就知道它。
檢查誤差的標準方式就是使用平方誤差。你可能之前聽說過,這個方法叫做 R 平方或者判定系數。什么叫平方誤差呢?
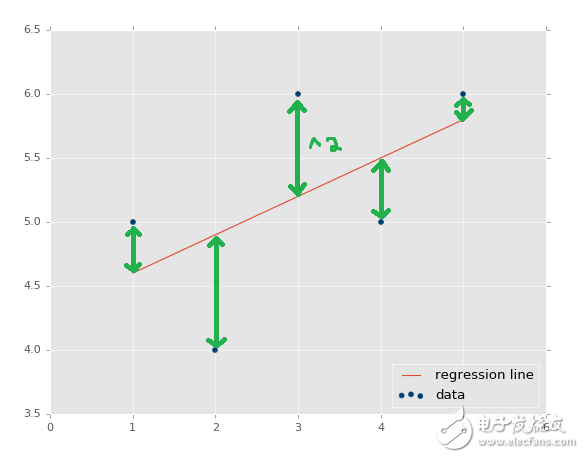
?
回歸直線和數據的y值的距離,就叫做誤差,我們將其平方。直線的平方誤差是它們的平均或者和。我們簡單求和吧。
我們實際上已經解除了平方誤差假設。我們的最佳擬合直線方程,用于計算最佳擬合回歸直線,就是證明結果。其中回歸直線就是擁有最小平方誤差的直線(所以它才叫做最小二乘法)。你可以搜索“回歸證明”,或者“最佳擬合直線證明”來理解它。它很抑郁理解,但是需要代數變形能力來得出結果。
為啥是平方誤差?為什么不僅僅將其加起來?首先,我們想要一種方式,將誤差規范化為距離,所以誤差可能是 -5,但是,平方之后,它就是正數了。另一個原因是要進一步懲罰離群點。進一步的意思是,它影響誤差的程度更大。這就是人們所使用的標準方式。你也可以使用4, 6, 8的冪,或者其他。你也可以僅僅使用誤差的絕對值。如果你只有一個挑戰,也許就是存在一些離群點,但是你并不打算管它們,你就可以考慮使用絕對值。如果你比較在意離群點,你就可以使用更高階的指數。我們會使用平方,因為這是大多數人所使用的。
好的,所以我們計算回歸直線的平方誤差,什么計算呢?這是什么意思?平方誤差完全和數據集相關,所以我們不再需要別的東西了。這就是 R 平方引入的時候了,也叫作判定系數。方程是:
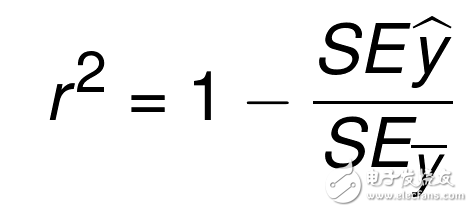
?
y_hat = x * m + b
r_sq = 1 - np.sum((y - y_hat) ** 2) / np.sum((y - y.mean()) ** 2)
這個方程的的本質就是,1 減去回歸直線的平方誤差,比上 y 平均直線的平方誤差。 y 平均直線就是數據集中所有 y 值的均值,如果你將其畫出來,它是一個水平的直線。所以,我們計算 y 平均直線,和回歸直線的平方誤差。這里的目標是識別,與欠擬合的直線相比,數據特征的變化產生了多少誤差。
所以判定系數就是上面那個方程,如何判定它是好是壞?我們看到了它是 1 減去一些東西。通常,在數學中,你看到他的時候,它返回了一個百分比,它是 0 ~ 1 之間的數值。你認為什么是好的 R 平方或者判定系數呢?讓我們假設這里的 R 平方是 0.8,它是好是壞呢?它比 0.3 是好還是壞?對于 0.8 的 R 平方,這就意味著回歸直線的平方誤差,比上 y 均值的平方誤差是 2 比 10。這就是說回歸直線的誤差非常小于 y 均值的誤差。聽起來不錯。所以 0.8 非常好。
那么與判定系數的值 0.3 相比呢?這里,它意味著回歸直線的平方誤差,比上 y 均值的平方誤差是 7 比 10。其中 7 比 10 要壞于 2 比 10,7 和 2 都是回歸直線的平方誤差。因此,目標是計算 R 平方值,或者叫做判定系數,使其盡量接近 1。
編程計算 R 平方
歡迎閱讀第十一篇教程。既然我們知道了我們尋找的東西,讓我們實際在 Python 中計算它吧。第一步就是計算平方誤差。函數可能是這樣:
def squared_error(ys_orig,ys_line):
return sum((ys_line - ys_orig) * (ys_line - ys_orig))
使用上面的函數,我們可以計算出任何實現到數據點的平方誤差。所以我們可以將這個語法用于回歸直線和 y 均值直線。也就是說,平方誤差只是判定系數的一部分,所以讓我們構建那個函數吧。由于平方誤差函數只有一行,你可以選擇將其嵌入到判定系數函數中,但是平方誤差是你在這個函數之外計算的東西,所以我選擇將其單獨寫成一個函數。對于 R 平方:
def coefficient_of_determination(ys_orig,ys_line):
y_mean_line = [mean(ys_orig) for y in ys_orig]
squared_error_regr = squared_error(ys_orig, ys_line)
squared_error_y_mean = squared_error(ys_orig, y_mean_line)
return 1 - (squared_error_regr/squared_error_y_mean)
我們所做的是,計算 y 均值直線,使用單行的for循環(其實是不必要的)。之后我們計算了 y 均值的平方誤差,以及回歸直線的平方誤差,使用上面的函數。現在,我們需要做的就是計算出 R 平方之,它僅僅是 1 減去回歸直線的平方誤差,除以 y 均值直線的平方誤差。我們返回該值,然后就完成了。組合起來并跳過繪圖部分,代碼為:
from statistics import mean
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
xs = np.array([1,2,3,4,5], dtype=np.float64)
ys = np.array([5,4,6,5,6], dtype=np.float64)
def best_fit_slope_and_intercept(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)*mean(xs)) - mean(xs*xs)))
b = mean(ys) - m*mean(xs)
return m, b
def squared_error(ys_orig,ys_line):
return sum((ys_line - ys_orig) * (ys_line - ys_orig))
def coefficient_of_determination(ys_orig,ys_line):
y_mean_line = [mean(ys_orig) for y in ys_orig]
squared_error_regr = squared_error(ys_orig, ys_line)
squared_error_y_mean = squared_error(ys_orig, y_mean_line)
return 1 - (squared_error_regr/squared_error_y_mean)
m, b = best_fit_slope_and_intercept(xs,ys)
regression_line = [(m*x)+b for x in xs]
r_squared = coefficient_of_determination(ys,regression_line)
print(r_squared)
# 0.321428571429
##plt.scatter(xs,ys,color='#003F72',label='data')
##plt.plot(xs, regression_line, label='regression line')
##plt.legend(loc=4)
##plt.show()
這是個很低的值,所以根據這個度量,我們的最佳擬合直線并不是很好。這里的 R 平方是個很好的度量手段嗎?可能取決于我們的目標。多數情況下,如果我們關心準確預測未來的值,R 平方的確很有用。如果你對預測動機或者趨勢感興趣,我們的最佳擬合直線實際上已經很好了。R 平方不應該如此重要。看一看我們實際的數據集,我們被一個較低的數值卡住了。值與值之間的變化在某些點上是 20% ~ 50%,這已經非常高了。我們完全不應該感到意外,使用這個簡單的數據集,我們的最佳擬合直線并不能描述真實數據。
但是,我們剛才說的是一個假設。雖然我們邏輯上統一這個假設,我們需要提出一個新的方法,來驗證假設。到目前為止的算法非常基礎,我們現在只能做很少的事情,所以沒有什么空間來改進誤差了,但是之后,你會在空間之上發現空間。不僅僅要考慮算法本身的層次空間,還有由很多算法層次組合而成的算法。其中,我們需要測試它們來確保我們的假設,關于算法是干什么用的,是正確的。考慮把操作組成成函數由多么簡單,之后,從這里開始,將整個驗證分解成數千行代碼。
我們在下一篇教程所做的是,構建一個相對簡單的數據集生成器,根據我們的參數來生成數據。我們可以使用它來按照意愿操作數據,之后對這些數據集測試我們的算法,根據我們的假設修改參數,應該會產生一些影響。我們之后可以將我們的假設和真實情況比較,并希望他們匹配。這里的例子中,假設是我們正確編寫這些算法,并且判定系數低的原因是,y 值的方差太大了。我們會在下一個教程中驗證這個假設。
為測試創建樣例數據集
歡迎閱讀第十二篇教程。我們已經了解了回歸,甚至編寫了我們自己的簡單線性回歸算法。并且,我們也構建了判定系數算法來檢查最佳擬合直線的準確度和可靠性。我們之前討論和展示過,最佳擬合直線可能不是最好的擬合,也解釋了為什么我們的示例方向上是正確的,即使并不準確。但是現在,我們使用兩個頂級算法,它們由一些小型算法組成。隨著我們繼續構造這種算法層次,如果它們之中有個小錯誤,我們就會遇到麻煩,所以我們打算驗證我們的假設。
在編程的世界中,系統化的程序測試通常叫做“單元測試”。這就是大型程序構建的方式,每個小型的子系統都不斷檢查。隨著大型程序的升級和更新,可以輕易移除一些和之前系統沖突的工具。使用機器學習,這也是個問題,但是我們的主要關注點僅僅是測試我們的假設。最后,你應該足夠聰明,可以為你的整個機器學習系統創建單元測試,但是目前為止,我們需要盡可能簡單。
我們的假設是,我們創建了最賤he直線,之后使用判定系數法來測量。我們知道(數學上),R 平方的值越低,最佳擬合直線就越不好,并且越高(接近 1)就越好。我們的假設是,我們構建了一個這樣工作的系統,我們的系統有許多部分,即使是一個小的操作錯誤都會產生很大的麻煩。我們如何測試算法的行為,保證任何東西都預期工作呢?
這里的理念是創建一個樣例數據集,由我們定義,如果我們有一個正相關的數據集,相關性非常強,如果相關性很弱的話,點也不是很緊密。我們用眼睛很容易評測這個直線,但是機器應該做得更好。讓我們構建一個系統,生成示例數據,我們可以調整這些參數。
最開始,我們構建一個框架函數,模擬我們的最終目標:
def create_dataset(hm,variance,step=2,correlation=False):
return np.array(xs, dtype=np.float64),np.array(ys,dtype=np.float64)
我們查看函數的開頭,它接受下列參數:
hm(how much):這是生成多少個數據點。例如我們可以選擇 10,或者一千萬。
variance:決定每個數據點和之前的數據點相比,有多大變化。變化越大,就越不緊密。
step:每個點距離均值有多遠,默認為 2。
correlation:可以為False、pos或者neg,決定不相關、正相關和負相關。
要注意,我們也導入了random,這會幫助我們生成(偽)隨機數據集。
現在我們要開始填充函數了。
def create_dataset(hm,variance,step=2,correlation=False):
val = 1
ys = []
for i in range(hm):
y = val + random.randrange(-variance,variance)
ys.append(y)
非常簡單,我們僅僅使用hm變量,迭代我們所選的范圍,將當前值加上一個負差值到證差值的隨機范圍。這會產生數據,但是如果我們想要的話,它沒有相關性。讓我們這樣:
def create_dataset(hm,variance,step=2,correlation=False):
val = 1
ys = []
for i in range(hm):
y = val + random.randrange(-variance,variance)
ys.append(y)
if correlation and correlation == 'pos':
val+=step
elif correlation and correlation == 'neg':
val-=step
非常棒了,現在我們定義好了 y 值。下面,讓我們創建 x,它更簡單,只是返回所有東西。
def create_dataset(hm,variance,step=2,correlation=False):
val = 1
ys = []
for i in range(hm):
y = val + random.randrange(-variance,variance)
ys.append(y)
if correlation and correlation == 'pos':
val+=step
elif correlation and correlation == 'neg':
val-=step
xs = [i for i in range(len(ys))]
return np.array(xs, dtype=np.float64),np.array(ys,dtype=np.float64)
我們準備好了。為了創建樣例數據集,我們所需的就是:
xs, ys = create_dataset(40,40,2,correlation='pos')
讓我們將之前線性回歸教程的代碼放到一起:
from statistics import mean
import numpy as np
import random
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
def create_dataset(hm,variance,step=2,correlation=False):
val = 1
ys = []
for i in range(hm):
y = val + random.randrange(-variance,variance)
ys.append(y)
if correlation and correlation == 'pos':
val+=step
elif correlation and correlation == 'neg':
val-=step
xs = [i for i in range(len(ys))]
return np.array(xs, dtype=np.float64),np.array(ys,dtype=np.float64)
def best_fit_slope_and_intercept(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)*mean(xs)) - mean(xs*xs)))
b = mean(ys) - m*mean(xs)
return m, b
def coefficient_of_determination(ys_orig,ys_line):
y_mean_line = [mean(ys_orig) for y in ys_orig]
squared_error_regr = sum((ys_line - ys_orig) * (ys_line - ys_orig))
squared_error_y_mean = sum((y_mean_line - ys_orig) * (y_mean_line - ys_orig))
print(squared_error_regr)
print(squared_error_y_mean)
r_squared = 1 - (squared_error_regr/squared_error_y_mean)
return r_squared
xs, ys = create_dataset(40,40,2,correlation='pos')
m, b = best_fit_slope_and_intercept(xs,ys)
regression_line = [(m*x)+b for x in xs]
r_squared = coefficient_of_determination(ys,regression_line)
print(r_squared)
plt.scatter(xs,ys,color='#003F72', label = 'data')
plt.plot(xs, regression_line, label = 'regression line')
plt.legend(loc=4)
plt.show()
執行代碼,你會看到:
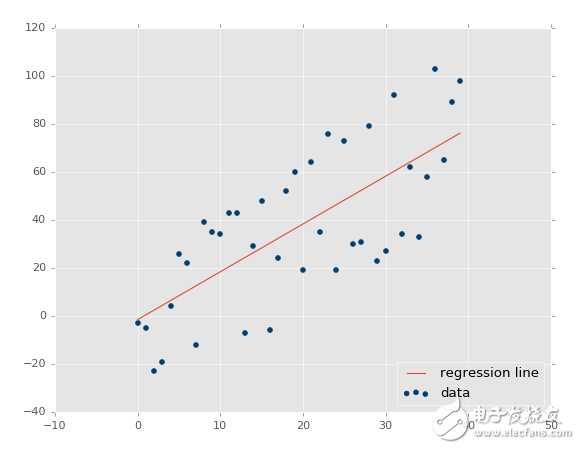
?
判定系數是 0.516508576011(要注意你的結果不會相同,因為我們使用了隨機數范圍)。
不錯,所以我們的假設是,如果我們生成一個更加緊密相關的數據集,我們的 R 平方或判定系數應該更好。如何實現它呢?很簡單,把范圍調低。
xs, ys = create_dataset(40,10,2,correlation='pos')
?
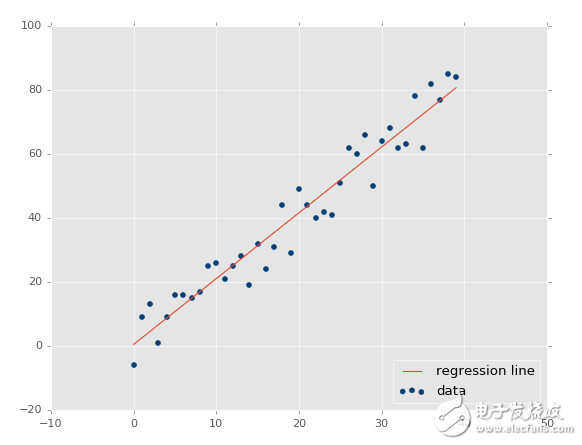
?
現在我們的 R 平方值為 0.939865240568,非常不錯,就像預期一樣。讓我們測試負相關:
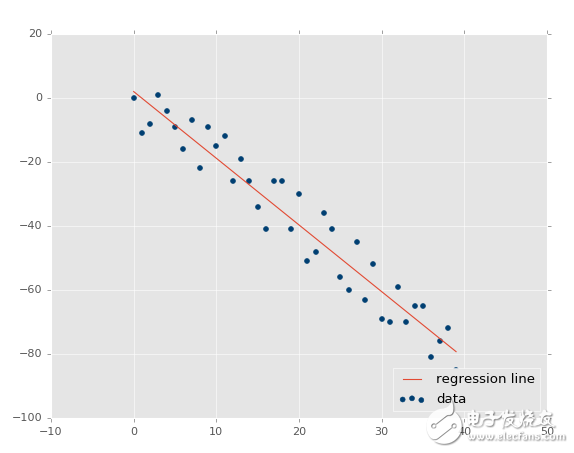
xs, ys = create_dataset(40,10,2,correlation='neg')
?
R 平方值是 0.930242442156,跟之前一樣好,由于它們參數相同,只是方向不同。
這里,我們的假設證實了:變化越小 R 值和判定系數越高,變化越大 R 值越低。如果是不相關呢?應該很低,接近于 0,除非我們的隨機數排列實際上有相關性。讓我們測試:
xs, ys = create_dataset(40,10,2,correlation=False)
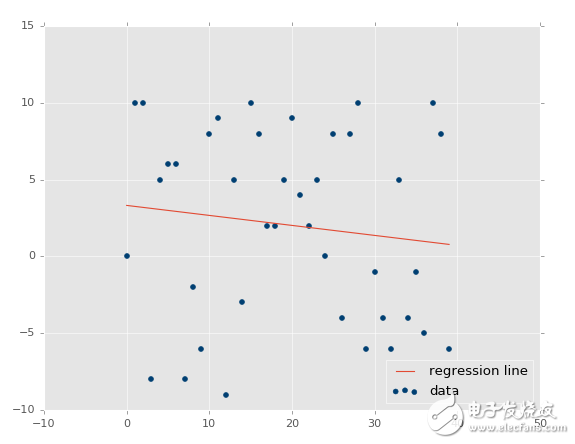
?
判定系數為 0.0152650900427。
現在為止,我覺得我們應該感到自信,因為事情都符合我們的預期。
既然我們已經對簡單的線性回歸很熟悉了,下個教程中我們開始講解分類。













 工商網監
工商網監
評論