 電子發燒友App
電子發燒友App


Transformer自誕生以來就席卷了NLP領域,因為它具有對序列中復雜依賴關系進行建模的優越能力。盡管基于Transformer的預訓練語言模型(PLM)在幾乎所有NLP任務中都取得了巨大成功,但它們都有預設的長度限制,因此很難將這種成功擴展到見過數據以外的更長的序列,即長度外推問題。為了增強Transformer的長度外推,人們提出了大量的可外推的位置編碼。
作者:cola

論文:Length Extrapolation of Transformers: A Survey from the Perspective of Position Encoding
地址:https://arxiv.org/abs/2312.17044
介紹
在有限的學習資源下,人類可以通過理解它們的組成部分和結構來理解潛在無限長度的話語。在NLP中,這種能力稱為模型的長度外推,即在較短的上下文窗口上進行訓練,在較長的上下文窗口上進行推理。盡管神經網絡在各種任務上取得了驚人的進展,但長度外推對它們來說仍然是一個重大挑戰。Transformer被用來環節這一問題。
然而,Transformer的優勢容量是以相對于輸入序列長度的二次計算和內存復雜度為代價的,這導致了基于Transformer的模型的預定義上下文長度限制,通常是512或1024個token。因此,利用Transformer處理長序列是極其困難的。此外,人們普遍認為,用更長的上下文窗口對現有模型進行微調要么是有害的,要么是昂貴的。更糟糕的是,由于高質量長文本數據的稀缺和不可負擔的二次成本,通過直接在長序列上訓練Transformer來擴展上下文窗口是不可行的。因此,長度外推似乎是減少訓練開銷、同時放松Transformer上下文長度限制的最合適的方法。
最近,基于Transformer的LLMs,如Llama和GPT-4,在工業界和研究界引起了極大的興趣。但即使這些能力很強的LLMs仍然對上下文長度有強制限制,并且在長度推斷上失敗,這極大地阻礙了它們的廣泛采用。盡管GPT-4的上下文窗口達到了驚人的32k,但實際上,這個上下文長度遠遠不夠。一方面,隨著LLM能力的增長,我們對它們的期望也在增長。另一方面,現有有效利用LLM的技術也對上下文窗口的長度提出了更高的要求。
預備知識
Transformer最初是作為一個編碼器-解碼器架構引入的,其中編碼器和解碼器都由個相同的層組成。每個編碼器層由兩個子層組成,self-attention層和位置全連接前饋網絡。而對于每個解碼器層,還有第三個子層執行交叉注意力,即對編碼器輸出的注意力。我們在這里給出了編碼器層的形式化描述。給定輸入矩陣為個維度為的嵌入序列,的編碼器層定義為:
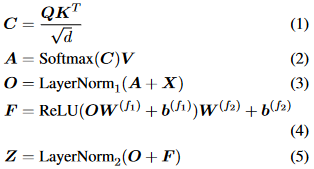
其中,,是所謂的query、key和value,其中,,是投影矩陣。首先,兼容性分數被計算為具有縮放因子的query和key之間的點積。然后,利用逐行softmax函數將兼容性分數轉換為權重,值的加權和正是注意力子層的輸出。全連接的前饋網絡由兩個線性變換組成,中間由ReLU激活。為了提供可伸縮性,在每個子層周圍利用殘差連接,然后進行層歸一化。
為了使模型能夠共同關注來自不同表示子空間不同位置的信息,通常使用多頭注意力。簡而言之,個頭意味著用不同的投影矩陣, ,計算自注意力次,其中。然后將輸出矩陣沿著第二個維度連接起來以獲得最終的。從上面的描述中,不難看出整個編碼器層是置換等價或順序不變的,考慮到注意力子層和前饋子層都是置換等價的。即,給定任意置換矩陣,得到。這種置換等價性質與人類語言的順序性質不一致,可以通過向Transformer中注入位置信息來減少。
位置編碼實現長度外推
直觀地說,長度外推與長度和位置有很強的相關性。另一方面,在介紹Transformer時,研究人員也提出了正弦位置嵌入,并聲稱它可以外推到訓練之外的更長的序列。這一說法背后的想法,即只需改變位置表示方法就可以實現長度外推,已得到廣泛支持和證明。因此,開發更好的位置編碼方法已經成為增強Transformer長度外推的主要途徑。
有各種各樣的方法將位置信息集成到Transformer中,統稱為位置編碼(PEs)。表1給出了不同外推PE的特征。我們根據PE是絕對的還是相對的來劃分表格。使用絕對位置編碼(APE),每個位置都被映射到一個唯一的表示,而相對位置編碼(RPE)基于兩個token之間的相對距離來表示位置。
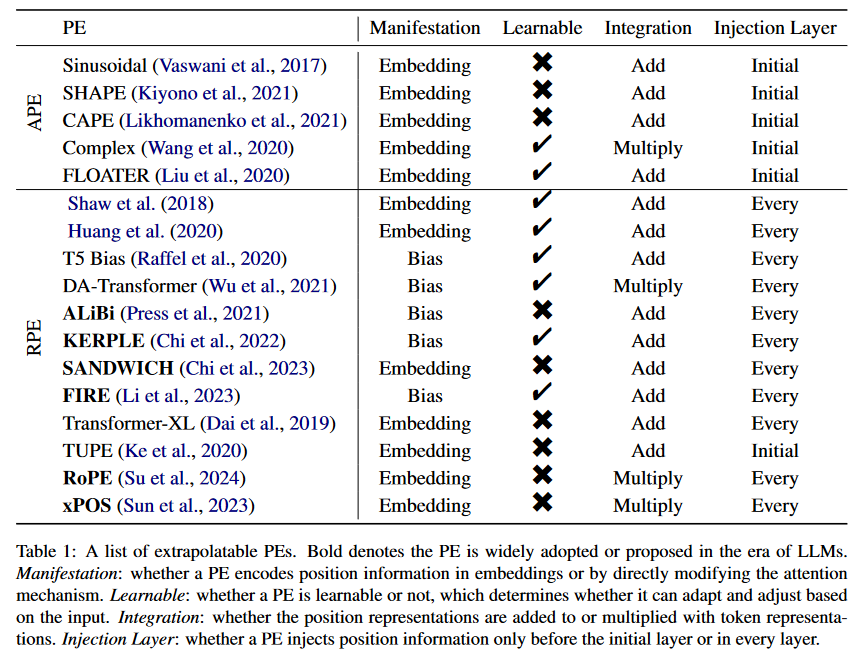
絕對位置編碼
考慮到Transformer的置換等價性質,提出了將位置信息融入其中的APE。具體來說,對于位置為的token,位置嵌入定義為:
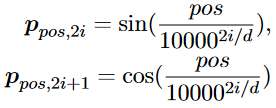
其中是位置嵌入的維數,表示模型維數。然后,將每個位置嵌入與對應的token嵌入相加,并將之和輸入到Transformer中,從而將查詢與鍵之間的兼容性得分形式化為:
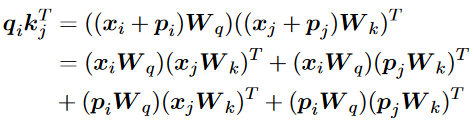
這是許多不同PE的基礎和重點。此外,比較了所提出的正弦APE和完全可學習的位置嵌入的性能,其中位置嵌入是在訓練期間隨機初始化和更新的。盡管具有類似的性能,但研究人員聲稱正弦位置嵌入可能能夠推斷出比所看到的更長的序列。然而,研究人員隨后發現,正弦APE很難外推。因此,人們提出了各種APEs和RPEs,以增強正弦位置編碼,從而增強Transformer的外推。
研究人員推測優異的外推性能來自PE的平移不變性,即即使輸入發生移動,函數也不會改變其輸出的特性。為了結合正弦APE中移位不變性的優點,他們只是對每個序列和訓練期間的每次迭代,通過從離散均勻分布中提取的隨機偏移量移動每個位置索引,其中是最大偏移量。也就是說,他們只是用代替了,這阻止了模型使用絕對位置,而是鼓勵使用相對位置。
遵循類似的想法,進一步利用連續信號來增強正弦APE。除了用相同的隨機偏移量移動APE的每個位置索引(為全局偏移)外,還引入了局部偏移和全局縮放。這三種增廣方法的形式如下:
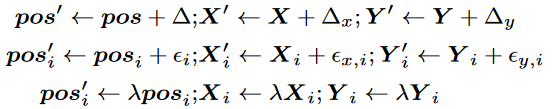
其中為位置索引向量,, 分別為源序列和目標序列的嵌入向量。全局位移將每個嵌入轉換為一個從的全局隨機位移序列。
除了這些基于正弦APE的相對簡單的方法外,還有一些APE采取了完全不同的理論途徑。例如將每個詞嵌入擴展為自變量上的連續函數,即位置,以便詞表示隨著位置的增加而平滑移動。通過數學上合理的推導,將單詞在位置上的一般復數嵌入定義為: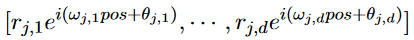 注意,振幅向量,頻率矢量權值和初始相位向量都是可訓練的參數。振幅只取決于單詞wj和向量可以被視為“purely”的位置嵌入。
注意,振幅向量,頻率矢量權值和初始相位向量都是可訓練的參數。振幅只取決于單詞wj和向量可以被視為“purely”的位置嵌入。
研究人員也試圖直接捕捉位置表示之間的依賴關系或動態關系。引入了一個動態系統來對這些位置表示進行建模,其特征可以表示為:
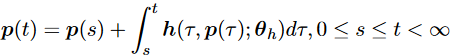
正弦APE作為Transformer的第一個PE,對以后的PE有重要影響。然而,發現它的外推性很差。為了增強Transformer的外推性,研究人員要么利用隨機移位將移位不變性納入正弦APE中,要么生成隨位置平滑變化的位置嵌入。這些方法確實比正弦APE具有更好的外推性能,但只能勉強趕上RPEs的外推能力。
相對位置編碼
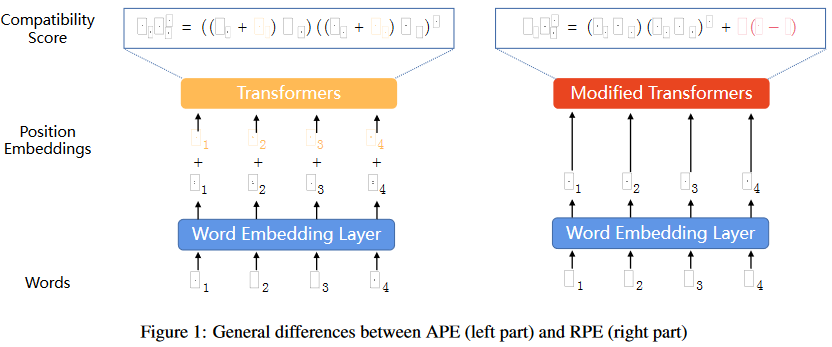
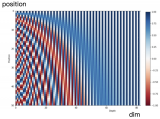
已經提出了許多新的RPE加強Transformer的外推。在我們深入討論之前,我們重新制定兼容性得分,如下所示,以幫助闡明RPEs的視角: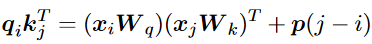 其中是編碼相對位置信息的術語。RPEs傾向于直接修改注意力機制來融合相對位置信息。因此,這種位置信息通常在每一層都重復出現,而不是像APE那樣只在第一層之前出現。此外,這種修改獨立于值向量,使它們不與位置信息糾纏。這些差異如圖1所示。
其中是編碼相對位置信息的術語。RPEs傾向于直接修改注意力機制來融合相對位置信息。因此,這種位置信息通常在每一層都重復出現,而不是像APE那樣只在第一層之前出現。此外,這種修改獨立于值向量,使它們不與位置信息糾纏。這些差異如圖1所示。
研究人員在此公式的基礎上引入了RPE的思想。具體來說,他們將公式具體化為: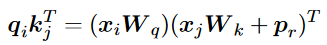 其中是可訓練的相對位置嵌入,表示關系位置關系。通過在確定的范圍內裁剪相對位置,減少了要學習的位置嵌入數量,增強了長度外推。同樣,在計算值時,他們還引入了,將其添加到詞嵌入中。再此基礎上,研究人員又增加了一個項來同時建模鍵嵌入和相對位置嵌入的交互:
其中是可訓練的相對位置嵌入,表示關系位置關系。通過在確定的范圍內裁剪相對位置,減少了要學習的位置嵌入數量,增強了長度外推。同樣,在計算值時,他們還引入了,將其添加到詞嵌入中。再此基礎上,研究人員又增加了一個項來同時建模鍵嵌入和相對位置嵌入的交互:
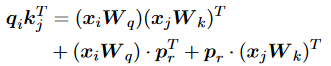
然而,一些研究人員采取了完全相反的方法,將其簡化為極其簡單的形式。利用可學習的標量來表示相對位置信息: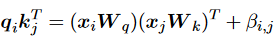 為了使Transformer能夠有效利用真實的token距離信息,研究人員提出了一種更復雜的方法:
為了使Transformer能夠有效利用真實的token距離信息,研究人員提出了一種更復雜的方法: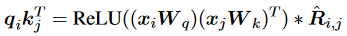 其中ReLU被用于確保兼容性分數的非負性,是通過可學習的sigmoid函數從加權相對距離映射而來的重新縮放系數:
其中ReLU被用于確保兼容性分數的非負性,是通過可學習的sigmoid函數從加權相對距離映射而來的重新縮放系數: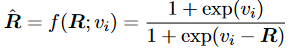 同樣為了利用真實距離信息來增強上下文建模,另一種更簡單的方法來表示相對位置信息:
同樣為了利用真實距離信息來增強上下文建模,另一種更簡單的方法來表示相對位置信息: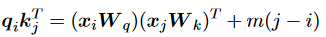 其中標量是訓練前固定的特定頭部斜率。值得注意的是,該方法不需要額外的可學習參數,因此效率更高,也有助于更好地推斷不在場證明。另一種方法建議按照以下方式計算兼容性:
其中標量是訓練前固定的特定頭部斜率。值得注意的是,該方法不需要額外的可學習參數,因此效率更高,也有助于更好地推斷不在場證明。另一種方法建議按照以下方式計算兼容性:
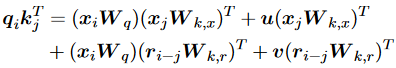
類似地,研究人員認為位置嵌入和詞嵌入對不同的概念進行編碼,因此應該對不同的信息應用不同的投影。因此,他們建議用: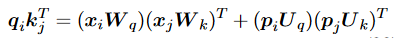 其中為正弦位置嵌入。他們發現他們的方法結合T5偏差可以有效地降低預訓練成本,并提高GLUE基準上的性能。
其中為正弦位置嵌入。他們發現他們的方法結合T5偏差可以有效地降低預訓練成本,并提高GLUE基準上的性能。
同樣受到正弦APE的啟發,研究人員提出通過正弦嵌入將鍵和查詢相乘,而不是將它們相加。他們將相容性分數重新表述為:
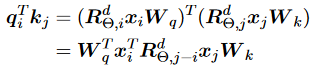
這種方法稱為旋轉位置嵌入(RoPE),因為直觀地說,它根據位置索引旋轉鍵和值嵌入,該索引形式化為。值得注意的是,盡管這是一個絕對的旋轉過程,但兼容性分數以及注意力機制僅依賴于查詢與鍵之間的相對距離,這有助于長度外推。
盡管之前提出了大量的PEs,但在最近的LLMs中,只有ALiBi和RoPE被廣泛采用。因此,LLM時代提出的PEs大多衍生自這兩種方法,試圖使ALiBi更具表現力或使RoPE更具外推性。
研究人員意識到正弦APE的過擬合問題,提出通過將正弦APE簡化為一種新的RPE Sandwich來克服它。具體來說,他們刪除了交叉項,但保留了兩個位置嵌入的內積: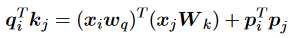 值得注意的是,在這種形式化中,成為與ALiBi具有相同衰減與距離模式的時間偏差項。此外,由于這里的位置嵌入只需要與自己交互,作者將它們的維度作為超參數,以進一步改善推斷。
值得注意的是,在這種形式化中,成為與ALiBi具有相同衰減與距離模式的時間偏差項。此外,由于這里的位置嵌入只需要與自己交互,作者將它們的維度作為超參數,以進一步改善推斷。
FIRE采用與T5 bias完全相同的形式,將位置信息與Transformer集成: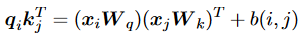 其中,它們的偏差使用可學習的連續函數,例如MLP。為了避免輸入在函數訓練域之外時的泛化問題,提出了通過查詢位置索引對距離進行歸一化的漸進式插值方法。請注意,在因果注意中,相對距離總是在[0,1]之間有界,對于任何序列長度,這將使推理域與訓練域對齊,從而帶來更好的長度泛化。
其中,它們的偏差使用可學習的連續函數,例如MLP。為了避免輸入在函數訓練域之外時的泛化問題,提出了通過查詢位置索引對距離進行歸一化的漸進式插值方法。請注意,在因果注意中,相對距離總是在[0,1]之間有界,對于任何序列長度,這將使推理域與訓練域對齊,從而帶來更好的長度泛化。
由于RoPE在流行的LLM中被廣泛使用,也有人提出一些變體來改進它。研究人員首先定義了兩個特定距離上的token之間的注意力得分期望和進一步的注意力分辨率,作為Transformer編碼位置能力的指標。他們將繩子外推性能較差的原因歸結為注意期望的劇烈振蕩,并提出引入平衡項來懲罰不穩定維度的振蕩,保持穩定維度的分布。他們的方法可以簡化為: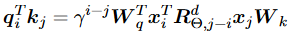
LLMs時代的長度外推
LLM徹底改變了NLP領域,并對長度外推提出了很大的要求,以更好地理解長文檔,利用更多的演示,處理多輪對話,增強智能體的長期記憶等。因此,在LLM的長度推斷方面付出了大量努力,導致了許多新的和新穎的PE的出現。除了這些方法,也有一些研究嘗試分析LLM的外推,并試圖揭示PE對長度外推的影響。
位置插值
盡管有大量具有更好外推性的PE,但RoPE由于其優越的分布性能,在最近的LLM中得到了最廣泛的采用。因此,人們提出了許多方法來增強現有的用RoPE進行預訓練的LLM的外推,其中最流行的是位置插值方法。基于將LLM外推到更長的序列的簡單想法,引入了RoPE的位置插值,這是將線性縮放降低該位置索引的比例,以便在預訓練期間最大位置索引匹配之前的長度限制。形式上,這個方法將RoPE替換為,定義如下: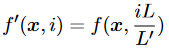 其中是預訓練期間的長度限制,是推理時較長的上下文窗口。注意,這里的比例是,將位置轉換為位置。該方法將絕對位置索引從減少到以匹配原始范圍,這也減少了從到的最大相對距離。因此,位置插值通過對齊位置索引的范圍和擴展前后的相對距離,減輕了由于上下文窗口擴展對注意力分數計算的影響。
其中是預訓練期間的長度限制,是推理時較長的上下文窗口。注意,這里的比例是,將位置轉換為位置。該方法將絕對位置索引從減少到以匹配原始范圍,這也減少了從到的最大相對距離。因此,位置插值通過對齊位置索引的范圍和擴展前后的相對距離,減輕了由于上下文窗口擴展對注意力分數計算的影響。
然而,從神經切線核(Neural Tangent Kernel, NTK)理論的角度來看,簡單地線性插值RoPE的傅里葉空間會造成高頻信息的丟失,會阻止模型區分附近的位置。為了解決這個問題,提出了NTK-Aware Scaling RoPE算法,通過修改基底來代替RoPE的尺度: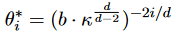 其中是原始基底,κ仍然是比例,兩者都可以看作是超參數。這里的核心思想是減少高頻的縮放,增加低頻的縮放,以減少高頻的信息損失。由于NTK-Aware插值不直接對傅里葉特征進行縮放,因此所有位置都是可以區分的。此外,該方法不需要對上下文窗口進行任何微調。
其中是原始基底,κ仍然是比例,兩者都可以看作是超參數。這里的核心思想是減少高頻的縮放,增加低頻的縮放,以減少高頻的信息損失。由于NTK-Aware插值不直接對傅里葉特征進行縮放,因此所有位置都是可以區分的。此外,該方法不需要對上下文窗口進行任何微調。
已經提出了幾種改進NTK-Aware插值的變體。Dynamic-NTK插值在預訓練的上下文窗口中為token使用精確的位置值,以防止性能下降,并隨著當前序列長度的增加動態增加縮放比,以適應預訓練的上下文窗口以外的位置:
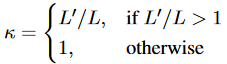
其中是當前序列的長度,每一步都會增加。
無論是縮放位置索引還是修改基地,所有token都變得彼此更接近,這將損害LLM區分相近token的位置順序的能力。結合他們對RoPE的波長的觀察,存在一些波長比預訓練的上下文窗口長的維度,NTK-by-parts插值的作者建議完全不插值較高的頻率維度,而總是插值較低的頻率維度。除了這種方法之外,在Softmax之前引入一個兼容性分數的溫度可以持續降低困惑度,他們將其稱為注意力縮放。具體來說: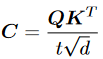 請注意,該方法與上面的插值方法是正交的,這促使作者將YaRN作為注意力擴展和NTK-by-parts插值的組合,以進一步提高性能,并在微調和非微調場景中超越所有基于NTK-Aware插值的方法。
請注意,該方法與上面的插值方法是正交的,這促使作者將YaRN作為注意力擴展和NTK-by-parts插值的組合,以進一步提高性能,并在微調和非微調場景中超越所有基于NTK-Aware插值的方法。
研究人員在此基礎上提出了一種更簡單的方法。不難看出,在訓練過程中,模型已經看到了全范圍的高頻分量,而低頻分量則沒有。這種不平衡使得模型對低頻進行外推是一項特別困難的任務。因此,他們建議使用apply給出的截斷基:
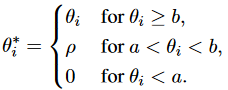
其中ρ是一個相對較小的固定值,和是選定的截斷值。這樣,模型將通過選擇適當的截斷值,在微調期間使用的上下文長度中體驗所有基值,并被認為在推理過程中進行更好的推斷。
隨機化位置編碼
對于沒有clipping機制的APE和RPE,長度外推意味著位置表示超出了訓練期間觀察到的位置表示,導致分布外位置表示,從而性能下降。為了解決這個問題,最直觀的方法之一是使模型在訓練期間觀察所有可能的位置表示,這正是隨機PEs背后的核心思想。
作為這一想法的具體化,研究人員提出模擬更長的序列的位置,并隨機選擇一個有序子集來適應訓練上下文窗口。具體來說,的長度遠大于訓練和評估過程中的最大長度。對于每個訓練步驟,長度為的序列的隨機位置是較大范圍位置的升序子樣本,該范圍大小為,且不包含重復。因此,通過充分的訓練,可以確保模型遇到足夠的唯一位置,并且在推理之前已經充分訓練了從1到的所有位置,從而在token中的任何序列上實現一致的性能。
基于相同的想法,PoSE也試圖通過在固定的預訓練上下文窗口內操縱位置索引來模擬更長的輸入。然而,PoSE是將原始序列劃分為幾個塊,并通過添加不同的skip偏差項來調整每個塊的位置索引。這樣,PoSE保持了每個塊中的連續位置,這與預訓練非常相似,同時允許模型適應更長的上下文窗口中的所有位置。
本質上,隨機PE只是通過在訓練過程中引入隨機位置,將預訓練的上下文窗口與較長的推理長度解耦,從而提高了較長的上下文窗口中所有位置的暴露。
討論
評估和基準
在早期階段,研究人員通過有意在具有長度限制的序列上訓練模型并在稍長的序列上測試來評估長度外推。在此期間,訓練和測試的長度限制都只有幾十個token和樣本,指標通常來自各種不同的下游任務,如機器翻譯,文本分類和問答。然后,由于PLM已經被證明是通用的,并且其他NLP任務可以很容易地轉換為語言建模,語言建模和困惑度成為測試和評估長度外推的標準做法。然而,人們越來越認識到,作為唯一的指標,復雜度不能說明下游任務的性能,而且非常不充分。
理論基礎
早期的方法大多是經驗的,并聲稱通過下游性能進行外推。最近,有一種量化外推能力的趨勢,如累積歸一化梯度和注意力分辨率。對數衰減時間偏差模式被認為是成功的長度外推的秘密,而沒有PE的僅解碼器模型在小規模合成任務中有更好的長度外推。盡管取得了這些進展,但仍然需要建立一個堅實的理論基礎,什么真正導致更好的長度外推仍然是一個開放的問題。
其他方法
除了上述方法外,還有幾種采取不同思維方式的方法來提高長度外推性能,如暫存器或思維鏈,Λ-shaped注意力掩碼和streamingLLM。此外,長度外推還適用于更大的任務,即上下文窗口擴展或長上下文LLM。
總結
本文對從Transformer誕生到LLM時代關于Transformer長度外推的研究工作進行了全面和有組織的概述,重點是外推PE和相關方法,包括位置插值和隨機PE。
審核編輯:黃飛
?


















 工商網監
工商網監
評論