 電子發燒友App
電子發燒友App


寫在前面
今天給大家帶來一篇《多語言SFT可以顯著提高LLM數學推理能力》,來自知乎@promise
Paper:?https://arxiv.org/abs/2310.20246 Github:?https://github.com/microsoft/MathOctopus/tree/main 知乎:https://zhuanlan.zhihu.com/p/664504560
近來,不少研究工作都集中于如何通過instruction tuning的方式來提高大模型(LLMs)的復雜數學推理能力。但是,這些基于的LLMs研究基本都集中于單語言,如何訓練一個多語言數學推理大模型依然丞待解決。
因此,在這篇論文中研究者們基于LLaMA探索并構建了一系列的多語言數學推理大模型:MathOctopus。MathOctopus不僅可以廣泛地提高LLMs在多語言上推理的平均性能,而且與單語訓練的模型相比在其對應的語言測試中依然可以取得更加優越的表現。
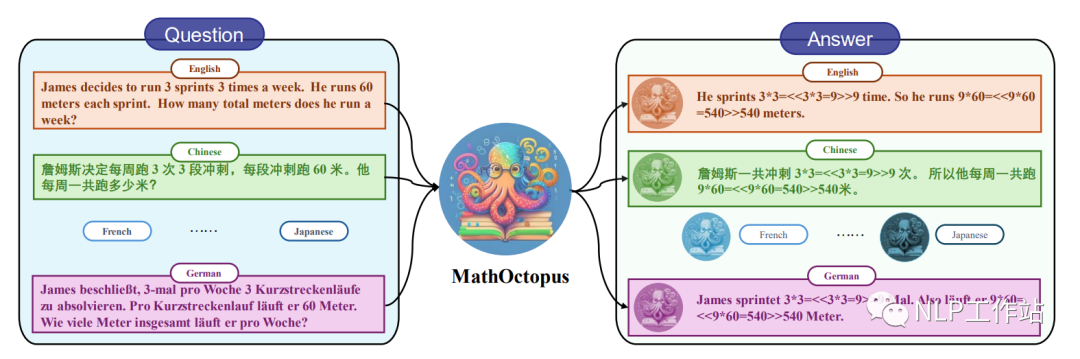
主要貢獻如下:
為了解決當前多語言數學推理任務上訓練數據短缺的問題,本文將英文的GSM8K數據集翻譯成10種不同的語言,并使用了特定的規則來校對翻譯后的語料,以確保數據的質量。最終生成的數據用來構建多語言數學推理訓練數據集:MGSM8KInstruct。
基于MGSM8KInstruct數據集, 并結合不同的SFT策略和多語言拒絕采樣的訓練方法,本文構建了一系列有效地多語言數學推理大模型:MathOctopus。
更近一步,為了全面地驗證當前模型在多語言數學推理任務上的魯棒性和通用性,文章基于SVAMP構建了out-of-domain(OOD)的多語言測試數據集MSVAMP。
經過大量的實驗,本文總結出以下結論:
MathOctopus在多語言數學推理任務中,表現出了強大的性能。MathOctopus-7B 可以將LLmMA2-7B在MGSM不同語言上的平均表現從22.6%提升到40.0%。更進一步,MathOctopus-13B也獲得了比ChatGPT更好的性能。
與只在單語言上訓練的LLMs相比,MathOctopus在他們對應的訓練語言測試中也取得了更加卓越的效果。比如,MathOctopus-7B和,在英語GSM8K上訓練的LLaMA2-7B相比,準確率從42.3%提升到了50.8%。
盡管拒絕采樣方法之前在單語數學推理中證明是十分有效的方法,但是在多語言數學推理任務中,使用拒絕采樣進行數據增強,對MathOctopus帶來的增益相對有限。
數據收集
MGSM8KInstruct訓練集
在多語言數學推理任務中,面臨的問題是在low-resource語言中缺乏相應高質量的訓練數據集,為此,本文使用ChatGPT將英文的GSM8K數據集翻譯成多種語言,其中包括孟加拉語(Bn),中文(Zh),法語(Fr),德語(de),日語(Ja),俄語(Ru),西班牙語(Es),斯瓦希里語(Sw)和泰語(Th),并對翻譯后的語料進行校對,確保數據的質量。基于此,構建了MGSM8KInstruct多語言數學推理訓練數據集。
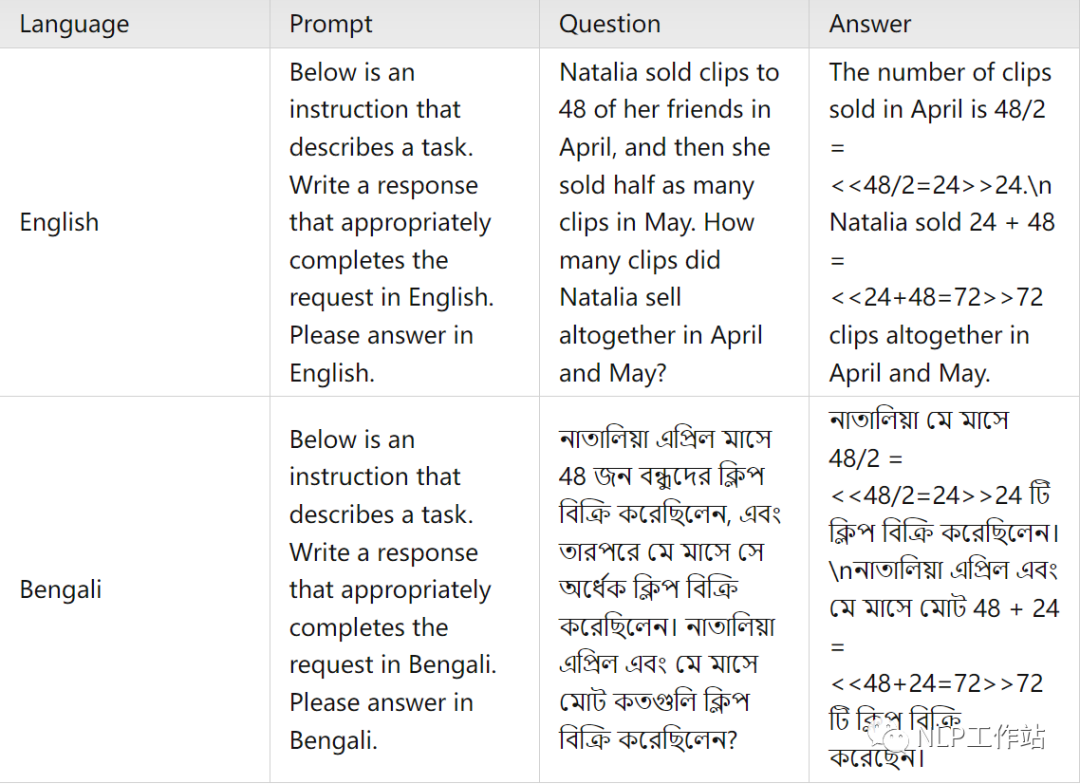
平行訓練語料樣例
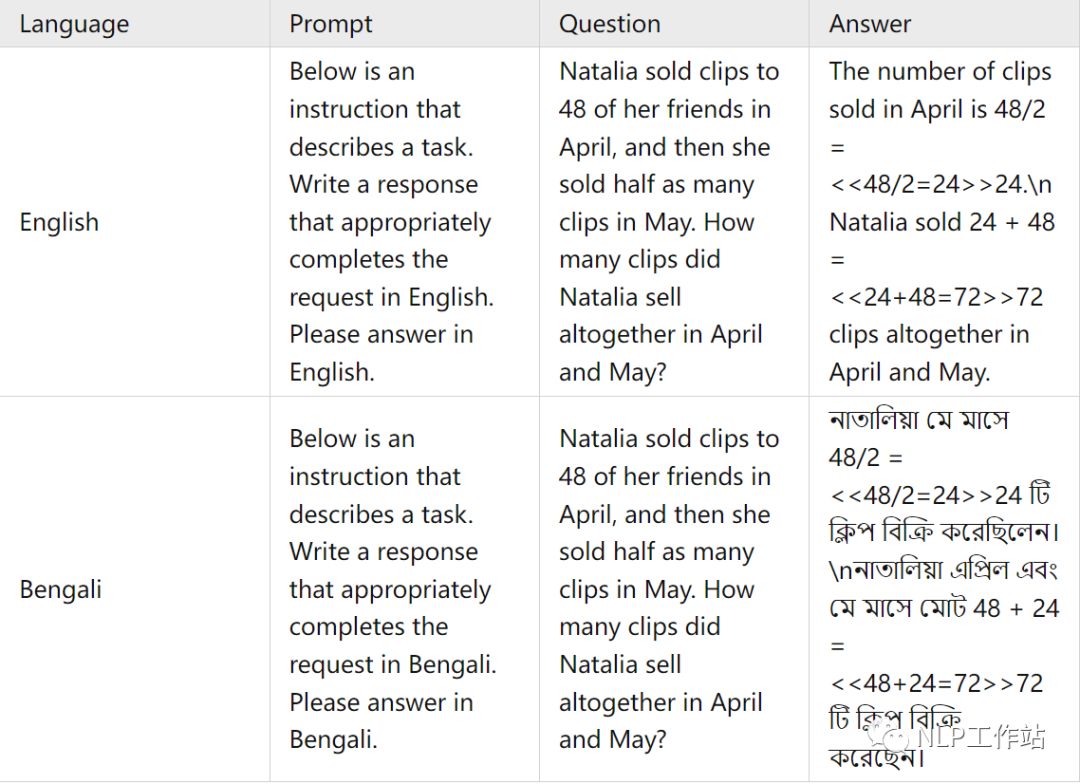
交叉訓練語料樣例
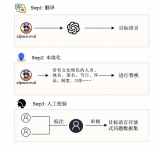
翻譯
在這篇文章中,使用了ChatGPT將英文的GSM8K訓練集和他們對應的 chain-of-thought(COT)回答翻譯成了十種語言。為了保證翻譯的質量,本文在翻譯時使用的提示詞(prompt)中遵循以下規則:
翻譯前后人物和地點的名字保持一致。
翻譯前后數學公式保持不變。
所有的數字都用阿拉伯數字表示。
對于每種語言,在提示詞(prompt)中提供了兩個翻譯的例子。
下面是完整的翻譯提示詞

校對
在翻譯問題與答案后,ChatGPT生成的句子通常沒有語言翻譯錯誤,但存在數學公式在翻譯前后不一致的情況。為了確保翻譯前后的準確性,本文采取了以下做法,首先,提取翻譯后答案中的所有數學公式,然后與原英文數據集中的公式進行比較,如果它們匹配,就認為翻譯是準確的。如果某一數據連續五次出現翻譯錯誤,將刪除該數據。這樣做有助于確保翻譯的準確性。
MSVAMP測試集
為了更近一步測試當前LLMs在多語言數學推理任務上的魯棒性,本文在現有的SVAMP數據集的基礎上構建了out-of-domain(OOD)多語言數學推理測試集MSVAMP。
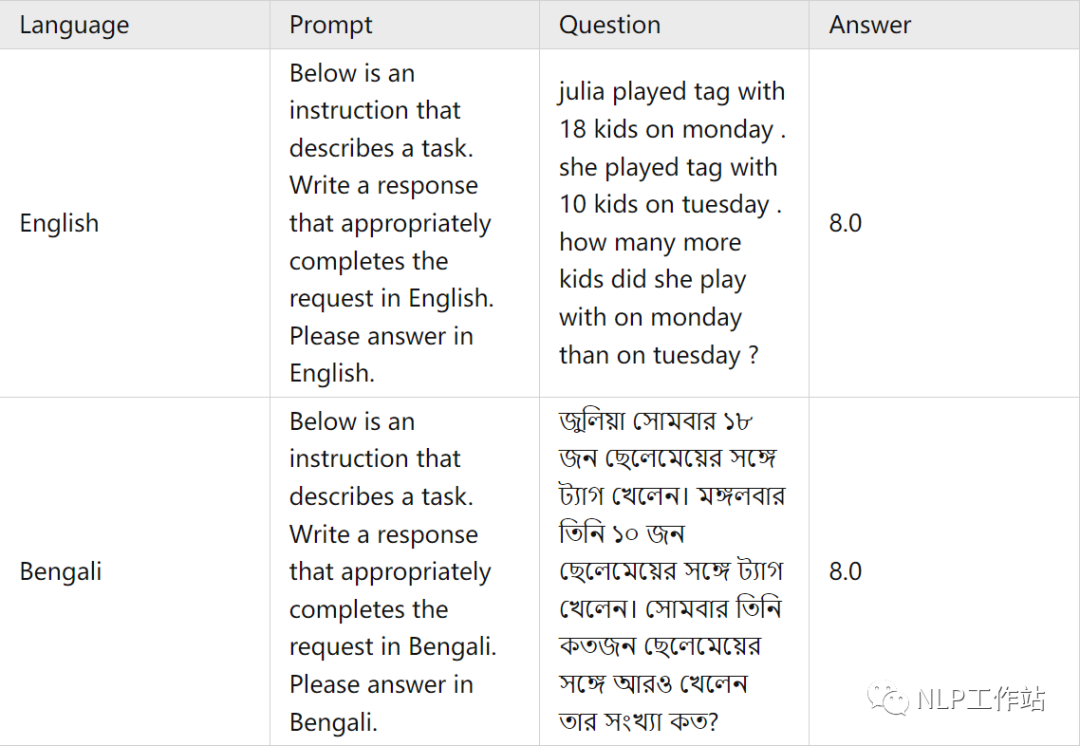
測試集語料樣例
翻譯
由于這個數據集的答案只包含最終的數字答案而不包括chain-of-thought(COT)過程,所以我們使用google翻譯系統僅對問題進行翻譯,本文將SVAMP測試集中1000條數據翻譯成和訓練集中對應的語言。
校對
為了確保翻譯的質量:首先,翻譯后的句子再次被翻譯回英文,以檢查是否存在翻譯上的差異。此外,還有三名專業的人員對翻譯前后的意思是否一致進行了審查,進一步確保翻譯的準確性。
MathOctopus
本文基于MGSM8KInstruct,為了讓模型擁有更多樣化的能力,本文提出了兩種不同的訓練方式。
為了使模型更好地理解問題與答案,本文提出的第一種方法是parallel-training,即問題與回答是相同的語言。
為了幫助模型融匯貫通不同的語言,本文提出的第二種方法是cross-training,即問題是英語,回答是別的語言,這可以使模型更好地解決多語言問題。
實驗結果與分析
下圖是模型在MGSM測試集上的表現,MathOctopusP 和 MathOctopusC 指的是模型訓練方式分別為parallel-training和cross-training,xRFT 指的是多語言數學推理的拒絕采樣,LLaMA 指的是只在英語GSM8K上訓練,RFT 指的是在英語GSM8K上訓練后,進行拒絕采樣。
下圖是模型在MGSM測試集上的表現
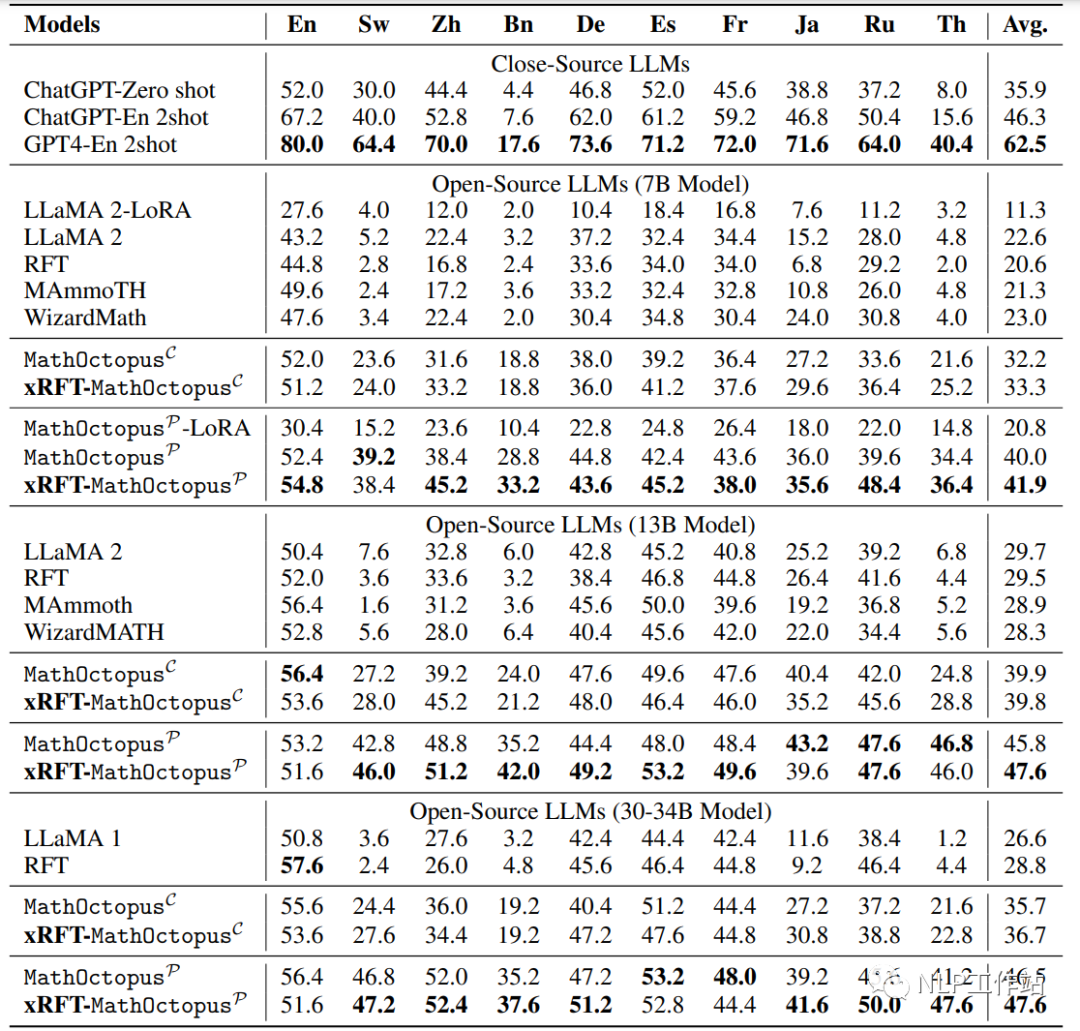
下圖是模型在MSVAMP測試集上的表現
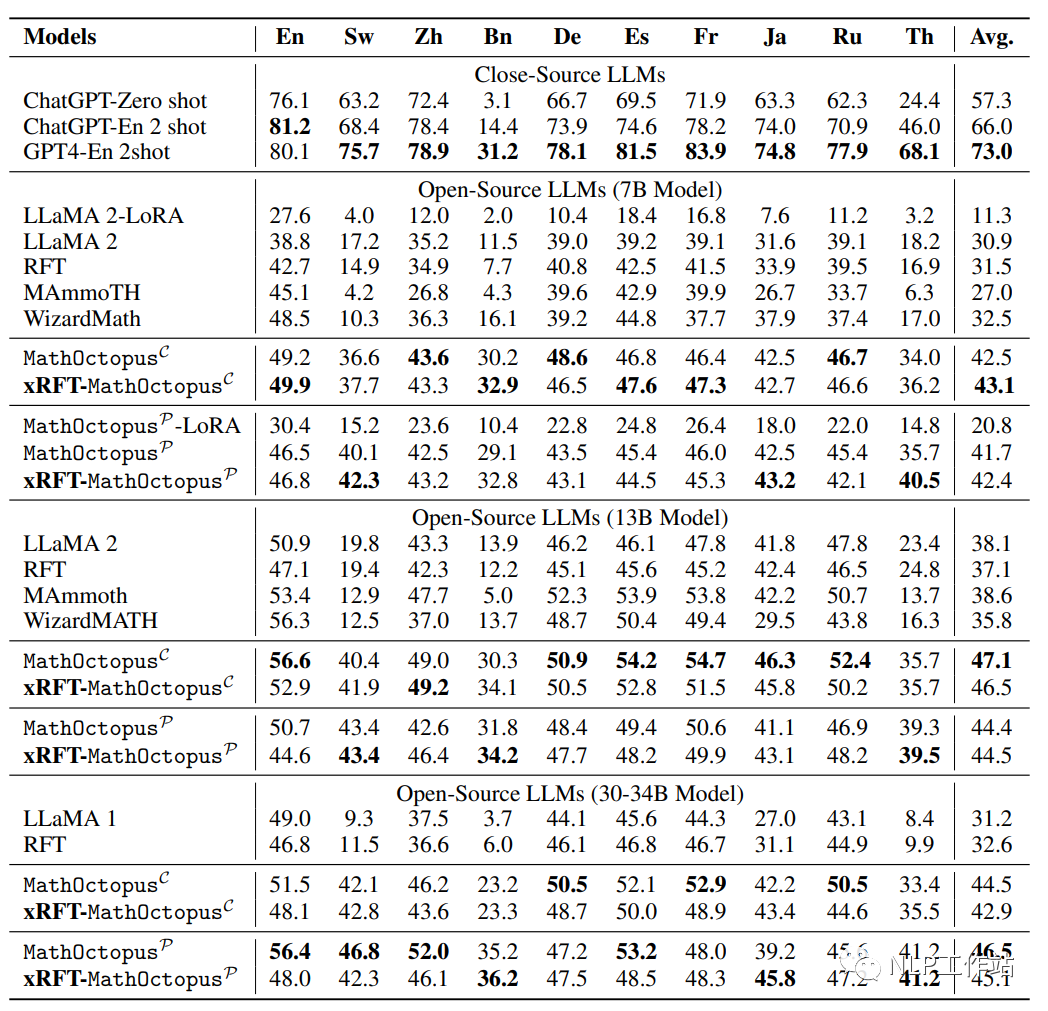
根據實驗結果,本文有以下發現:
MathOctopus不論是在平行訓練語料還是交叉訓練語料上訓練的結果都遠超于其他開源的LLMs。例如,在7B模型上,MathOctopus在MGSM上的準確率從22.6%提升到41.9%,MathOctopusP-13B在MGSM上的準確率超過了ChatGPT。
MathOctopusP在in-domain測試集MGSM中表現效果更好,相反MathOctopusC在out-of-domain測試集MSVAMP中體現了更強的泛化能力。
多語言拒絕采樣在多語言數學推理任務中,對MathOctopus帶來的提升有限。
下圖展示了在GSM8K訓練集上訓練的LLaMA2和用MGSM8KInstruct訓練的MathOctopus在GSM8K測試集和SVAMP上的表現
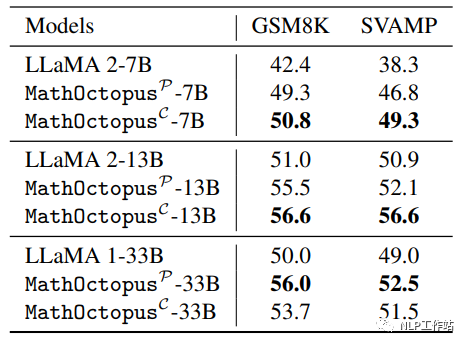
本文發現,和只在單語言上訓練的LLMs相比,MathOctopus在英語數據測試中也取得了更好的效果。為了進一步探索在其他語言上是否有相同的現象,本文進行了以下實驗:
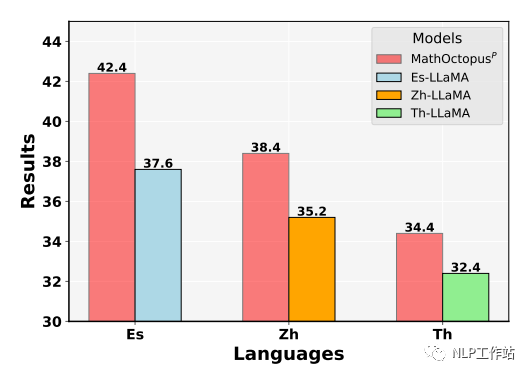
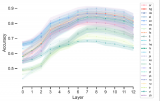
隨機從訓練集中挑選三種語言,分別是西班牙語,中文,泰語。使用它們對應的訓練語料分別訓練三個模型,分別命名為 ES-LLaMA,CN-LLaMA,Th-LLaMA。下圖展示了這幾個模型在他們對應訓練語言下的測試結果。由圖可見,在單一語言上,MathOctopus的表現仍然超過了單語SFT模型的結果。這表明,在數學推理任務中,多語言訓練比單語言訓練有更好的效果。
多語言拒絕采樣
《Scaling relationship on learning mathematical reasoning with large language models》表明,拒絕采樣rejection sampling(RFT)可以大幅提升模型的表現。為了探究在多語言訓練的場景下拒絕采樣對模型的提升效果,本文在得到多語言SFT模型后,采樣模型在MGSM8KInstruct數據集上的推理結果,對采樣到的推理過程進行驗證,如果符合要求則將其并入到原本的數據集。具體做法如下:
為了采樣到多樣化的推理答案,本文從MathOctopus-7B和MathOctopus-13B中分別采樣25條推理路徑,即每種語言總共采樣50次。
為了確保推理路徑的準確性,本文提取推理路徑中的所有公式并對公式進行驗算,如果答案正確那么就認為推理路徑是正確的。
為了確保推理路徑的多樣化,本文采用的策略是,只有當前推理路徑和先前的路徑中沒有相同的公式時,才將此路徑放入數據集中。
下圖展示了不同的采樣次數下,每種語言生成的不同推理路徑的個數
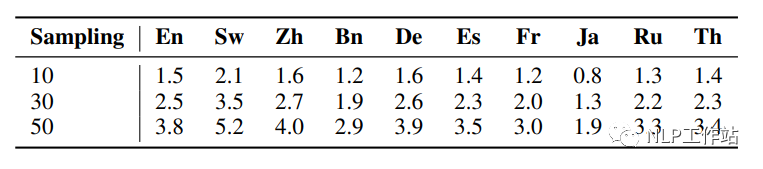
本文發現,通過多語言拒絕采樣(xRFT)增加的數據對模型的提升效果有限,主要表現在以下幾點:
在MGSM測試集上,多語言拒絕采樣只能提升MathOctopusP模型1%-2%的效果。
在MSVAMP測試集上,多語言拒絕采樣的提升效果不到1%。
多語言拒絕采樣對MathOctopusC的提升效果更小,在MGSM數據集上的表現反而有所下降。
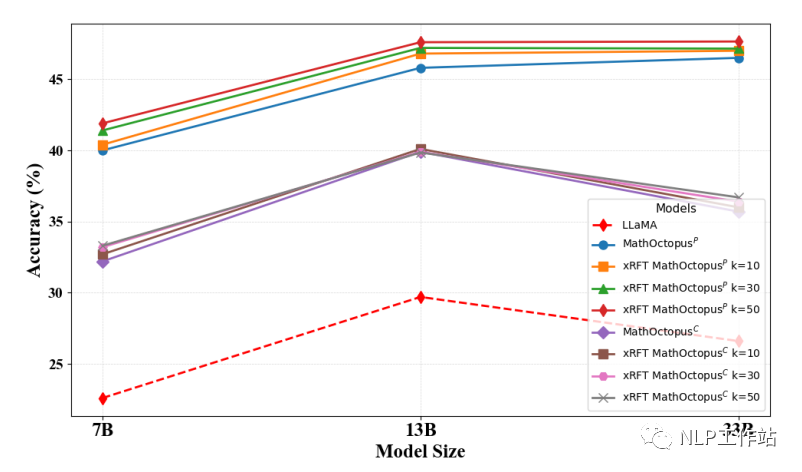
為了探究xRFT生成的數據量對模型的影響,本文在三個不同的采樣次數(10,30,50)下分別探究對應的模型在測試集上的表現。
下圖是不同采樣次數下模型在MGSM數據集上的表現
下圖是不同采樣次數下模型在MSVAMP數據集上的表現
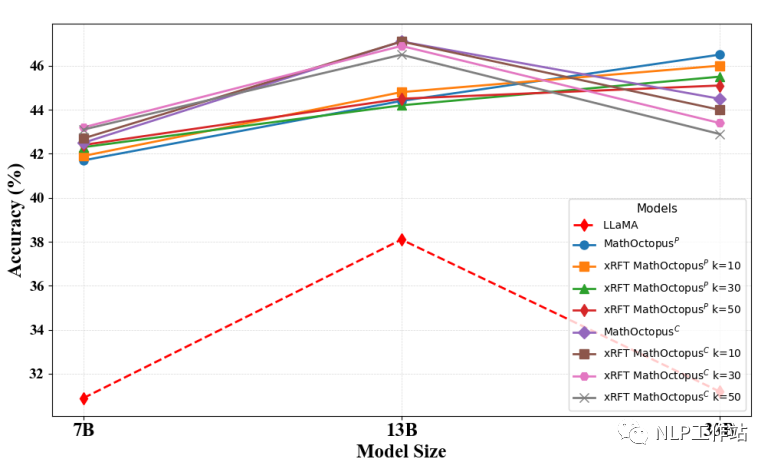
可以發現,在MGSM測試集上,當拒絕采樣的次數越多,訓練語料越多時,MathOctopusP的表現也略微變好。與之相反,在MSVAMP數據集上,當拒絕采樣的次數越多,訓練語料越多時,MathOctopusC的表現反而有所下降。
總結
目前僅研究到33B模型,將來還可以在LLaMA2-70B的基礎上探索更大的MathOctopus模型,除此之外,在這些更大的模型上使用多語言拒絕采樣也是將來的研究點之一。由于MathOctopus只有十種訓練語言,更多的訓練語言是否會給模型帶來更好的效果仍然有待研究。
編輯:黃飛
?




























 工商網監
工商網監
評論