電子發燒友網報道(文/李彎彎)在深度學習中,經常聽到一個詞“模型訓練”,但是模型是什么?又是怎么訓練的?在人工智能中,面對大量的數據,要在雜亂無章的內容中,準確、容易地識別,輸出需要的圖像/語音
2022-10-23 00:19:00 24277
24277 分布式深度學習框架中,包括數據/模型切分、本地單機優化算法訓練、通信機制、和數據/模型聚合等模塊。現有的算法一般采用隨機置亂切分的數據分配方式,隨機優化算法(例如隨機梯度法)的本地訓練算法,同步或者異步通信機制,以及參數平均的模型聚合方式。
2018-07-09 08:48:2213609 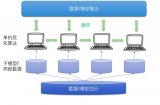
隨著預訓練語言模型(PLMs)的不斷發展,各種NLP任務設置上都取得了不俗的性能。盡管PLMs可以從大量語料庫中學習一定的知識,但仍舊存在很多問題,如知識量有限、受訓練數據長尾分布影響魯棒性不好
2022-04-02 17:21:438765 為什么?一般有 tensor parallelism、pipeline parallelism、data parallelism 幾種并行方式,分別在模型的層內、模型的層間、訓練數據三個維度上對 GPU 進行劃分。三個并行度乘起來,就是這個訓練任務總的 GPU 數量。
2023-09-15 11:16:2112112 
Hello大家好,今天給大家分享一下如何基于YOLOv8姿態評估模型,實現在自定義數據集上,完成自定義姿態評估模型的訓練與推理。
2023-12-25 11:29:01968 
訓練好的ai模型導入cubemx不成功咋辦,試了好幾個模型壓縮了也不行,ram占用過大,有無解決方案?
2023-08-04 09:16:28
就Edge Impulse的三大模型之一的分類模型進行淺析。針對于圖像的分類識別模型,讀者可參考OpenMv或樹莓派等主流圖像識別單片機系統的現有歷程,容易上手,簡單可靠。單擊此處轉到——星瞳科技OpenMv 所以接下來的分析主要是針對數據進行識別的分類模型。...
2021-12-20 06:51:26
),其中y取值1或-1(代表二分類的類別標簽),這也是GBDT可以用來解決分類問題的原因。模型訓練代碼地址 https://github.com/qianshuang/ml-expdef train
2019-01-23 14:38:58
設備的不斷增多,并發模型顯得舉足輕重,本期我們將為大家帶來方舟編譯器對傳統Actor并發模型的輕量級優化。
一、什么是并發模型?在操作系統中,并發是任務在不影響最終執行結果的情況下無序或者按部分順序
2022-07-18 12:00:53
會得到添加了高斯噪聲的新圖像。高斯噪聲也稱為白噪聲,是一種服從正態分布的隨機噪聲。 在深度學習中,訓練時往往會在輸入數據中加入高斯噪聲,以提高模型的魯棒性和泛化能力。 這稱為數據擴充。 通過向輸入數據添加
2023-02-16 14:04:10
及優化器,從而給大家帶來清晰的機器學習結構。通過本教程,希望能夠給大家帶來一個清晰的模型訓練結構。當模型訓練遇到問題時,需要通過可視化工具對數據、模型、損失等內容進行觀察,分析并定位問題出在數據部分
2018-12-21 09:18:02
tf.lite.TFLiteConverter.from_concrete_functions(): # 由具體函數轉化
2 TFLite格式分析
例如我們已經訓練得到了一個tflite模型
2023-08-18 07:01:53
1、YOLOv6中的用Channel-wise Distillation進行的量化感知訓練來自哪里 知識蒸餾 (KD)已被證明是一種用于訓練緊湊密集預測模型的簡單有效的工具。輕量級學生網絡通過
2022-10-09 16:25:51
能否直接調用訓練好的模型文件?
2021-06-22 14:51:03
:這種方法是在預訓練模型的基礎上,修改最后一層或幾層,并且對整個網絡進行微調訓練。這種方法適用于新數據集和原數據集相似度較高,且新數據集規模較大的情況。
特征提取:這種方法是將預訓練模型看作一個
2023-10-16 15:03:16
準備開始為家貓做模型訓練檢測,要去官網https://maix.sipeed.com/home 注冊帳號,文章尾部的視頻是官方的,與目前網站略有出路,說明訓練網站的功能更新得很快。其實整個的過程
2022-06-26 21:19:40
多種形式和任務。這個階段是從語言模型向對話模型轉變的關鍵,其核心難點在于如何構建訓練數據,包括訓練數據內部多個任務之間的關系、訓練數據與預訓練之間的關系及訓練數據的規模。
獎勵建模階段的目標是構建一個文本
2024-03-11 15:16:39
OpenVINO安裝完成后,需要提供項目的模型文件,才能進行參數調優和深度學習推理。所以需要進行數據收集,數據標注,進行模型訓練。訓練的模型很多,有Tensorflow、Caffee等,我選用
2020-07-15 23:29:12
用于訓練模型,如下圖所示:我選擇的方式為上傳本地圖片的方式,選項選擇如下:上傳圖片后,我們需要對圖片進行標記,操作則需要點擊下圖所示的 查看與標注第四步:在創建數據集完成后,就是模型訓練,我們進入模型
2021-03-23 14:32:35
(三)使用YOLOv3訓練BDD100K數據集之開始訓練
2020-05-12 13:38:55
我正在嘗試使用自己的數據集訓練人臉檢測模型。此錯誤發生在訓練開始期間。如何解決這一問題?
2023-04-17 08:04:49
醫療模型人訓練系統是為滿足廣大醫學生的需要而設計的。我國現代醫療模擬技術的發展處于剛剛起步階段,大部分仿真系統產品都源于國外,雖然對于模擬人仿真已經出現一些產品,但那些產品只是就模擬人的某一部分,某一個功能實現的仿真,沒有一個完整的系統綜合其所有功能。
2019-08-19 08:32:45
問題最近在Ubuntu上使用Nvidia GPU訓練模型的時候,沒有問題,過一會再訓練出現非常卡頓,使用nvidia-smi查看發現,顯示GPU的風扇和電源報錯:解決方案自動風扇控制在nvidia
2022-01-03 08:24:09
CV:基于Keras利用訓練好的hdf5模型進行目標檢測實現輸出模型中的臉部表情或性別的gradcam(可視化)
2018-12-27 16:48:28
。
使用TensorFlow對經過訓練的神經網絡模型進行優化,步驟如下:
1.確定圖中輸入和輸出節點的名稱以及輸入數據的維度。
2.使用TensorFlow的transform_graph工具生成優化的32位模型。
3.
2023-08-02 06:43:57
我正在嘗試使用 eIQ 門戶訓練人臉檢測模型。我正在嘗試從 tensorflow 數據集 (tfds) 導入數據集,特別是 coco/2017 數據集。但是,我只想導入 wider_face。但是,當我嘗試這樣做時,會出現導入程序錯誤,如下圖所示。任何幫助都可以。
2023-04-06 08:45:14
個人做數據可視化就算了,但凡上升到部門級的、企業級的,都少不了搭建數據分析模型,但數據分析模型不是那么好搭建的,經驗不足、考慮不周都將影響到后續的數據可視化分析。有些企業用戶就是在搭建分析模型時沒做
2022-05-17 10:03:14
PyTorch Hub 加載預訓練的 YOLOv5s 模型,model并傳遞圖像進行推理。'yolov5s'是最輕最快的 YOLOv5 型號。有關所有可用模型的詳細信息,請參閱自述文件。詳細示例此示例
2022-07-22 16:02:42
怎樣去開發一種Echarts消防訓練成績大數據可視化綜合分析系統?如何去編寫其代碼?
2021-08-31 07:06:59
問題:如何用單個GPU在不到24小時的時間內從零開始訓練ViT模型。作者認為,由于多種原因,這一方向的進展可能會對計算機視覺研究和應用的未來產生重大影響。1 加快模型開發。ML中的新模型通常通過運行和分析
2022-11-24 14:56:31
深度融合模型的特點,背景深度學習模型在訓練完成之后,部署并應用在生產環境的這一步至關重要,畢竟訓練出來的模型不能只接受一些公開數據集和榜單的檢驗,還需要在真正的業務場景下創造價值,不能只是為了PR而
2021-07-16 06:08:20
tensorflow模型部署系列的一部分,用于tflite實現通用模型的部署。本文主要使用pb格式的模型文件,其它格式的模型文件請先進行格式轉換,參考tensorflow模型部署系列————預訓練模型導出。從...
2021-12-22 06:51:18
),其中y取值1或-1(代表二分類的類別標簽),這也是GBDT可以用來解決分類問題的原因。模型訓練代碼地址 https://github.com/qianshuang/ml-expdef train
2019-01-25 15:02:15
目前官方的線上模型訓練只支持K210,請問K510什么時候可以支持
2023-09-13 06:12:13
我在matlab中訓練好了一個神經網絡模型,想在labview中調用,請問應該怎么做呢?或者labview有自己的神經網絡工具包嗎?
2018-07-05 17:32:32
個領先的 NLP 模型。它通過分析去掉一個單詞的句子(或“屏蔽詞”),并猜測屏蔽詞是什么,來進行推斷。例如,如果你要使用一個預先訓練好的 RoBERTa 模型來猜測一個句子中的下一個單詞,你要使
2022-11-01 15:25:02
一、前言前面結合神經網絡簡要介紹TensorFlow相關概念,并給出了MNIST手寫數字識別的簡單示例,可以得出結論是,構建的神經網絡目的就是利用已有的樣本數據訓練網絡的權重和偏置,使神經網絡最終
2020-11-04 07:49:09
通過一個基于操作規程的虛擬訓練系統研究了系統仿真流程,分析了有限狀態機(FSM)的原理,結合虛擬仿真訓練的特點,設計出了操作過程模型,并通過Windows 消息機制編程實
2009-12-07 14:23:01 14
14 ,需盡可能選擇與目標項目更相似的數據用于模型的訓練。利用PROMISE提供的34個公開數據集,從訓練數據選擇方面,分析了四種典型的相似性度量方法對跨項目預測結果的影響以及各種方法之間的差異。研究結果表明:使用不同的相似性度量
2017-12-09 11:39:530 深度學習模型和數據集的規模增長速度已經讓 GPU 算力也開始捉襟見肘,如果你的 GPU 連一個樣本都容不下,你要如何訓練大批量模型?通過本文介紹的方法,我們可以在訓練批量甚至單個訓練樣本大于 GPU
2018-12-03 17:24:01668 正如我們在本文中所述,ULMFiT使用新穎的NLP技術取得了令人矚目的成果。該方法對預訓練語言模型進行微調,將其在WikiText-103數據集(維基百科的長期依賴語言建模數據集Wikitext之一)上訓練,從而得到新數據集,通過這種方式使其不會忘記之前學過的內容。
2019-04-04 11:26:2623192 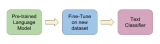
除此模型之外,本研究還嘗試了幾種其他的模型結構,一是移除教師 - 學生模型并使用自訓練模型,二是在進行模型微調時使用推斷出的標簽作為訓練數據。在實驗分析部分,作者討論了幾個影響模型性能的敏感因素
2019-05-08 09:47:453377 自然圖像領域中存在著許多海量數據集,如ImageNet,MSCOCO。基于這些數據集產生的預訓練模型推動了分類、檢測、分割等應用的進步。
2019-08-20 15:03:161871 生成的數據生成準確的預測。這些新數據示例可能是用戶交互、應用處理或其他軟件系統的請求生成的——這取決于模型需要解決的問題。在理想情況下,我們會希望自己的模型在生產環境中進行預測時,能夠像使用訓練過程中使用
2020-04-10 08:00:000 成功訓練計算機視覺任務的深層卷積神經網絡需要大量數據。這是因為這些神經網絡具有多個隱藏的處理層,并且隨著層數的增加,需要學習的樣本數也隨之增加。如果沒有足夠的訓練數據,則該模型往往會很好地學習訓練數據,這稱為過度擬合。如果模型過擬合,則其泛化能力很差,因此對未見的數據的表現很差。
2020-05-04 08:59:002727 在這篇文章中,我會介紹一篇最新的預訓練語言模型的論文,出自MASS的同一作者。這篇文章的亮點是:將兩種經典的預訓練語言模型(MaskedLanguage Model, Permuted
2020-11-02 15:09:362334 訓練方法不僅能夠在BERT上有提高,而且在RoBERTa這種已經預訓練好的模型上也能有所提高,說明對抗訓練的確可以幫助模型糾正易錯點。 方法:ALUM(大型神經語言模型的對抗
2020-11-02 15:26:491802 
導讀:預訓練模型在NLP大放異彩,并開啟了預訓練-微調的NLP范式時代。由于工業領域相關業務的復雜性,以及工業應用對推理性能的要求,大規模預訓練模型往往不能簡單直接地被應用于NLP業務中。本文將為
2020-12-31 10:17:112217 
。這些大模型的出現讓普通研究者越發絕望:沒有「鈔能力」、沒有一大堆 GPU 就做不了 AI 研究了嗎? 在此背景下,部分研究者開始思考:如何讓這些大模型的訓練變得更加接地氣?也就是說,怎么用更少的卡訓練更大的模型? 為了解決這個問題,來自微軟、加州大學默塞德分校的研究
2021-02-11 09:04:002167 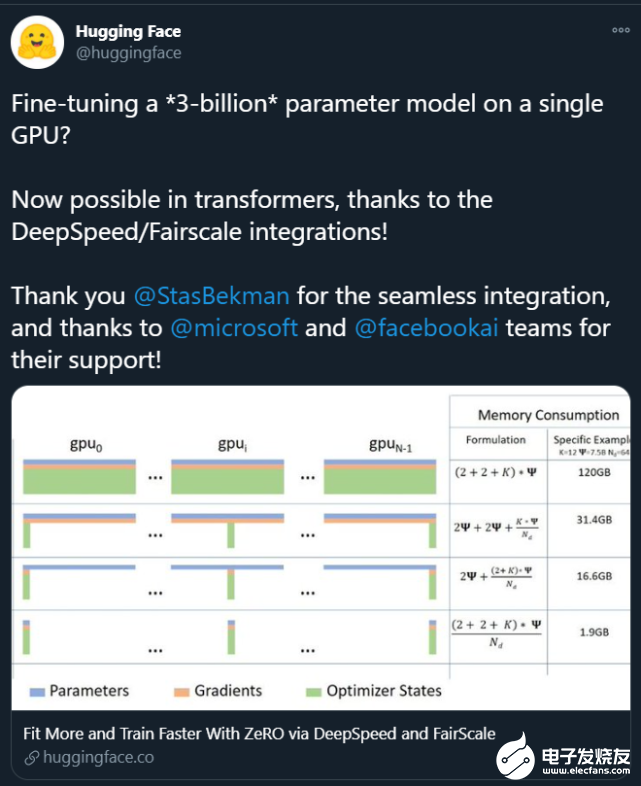
Pre-training of Knowledge Graph and Language Understanding)。該論文提出了知識圖譜和文本的聯合訓練框架,通過將RoBERTa作為語言模型將上下文編碼信息傳遞給知識
2021-03-29 17:06:103778 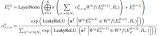
為提高卷積神經網絡目標檢測模型精度并增強檢測器對小目標的檢測能力,提出一種脫離預訓練的多尺度目標檢測網絡模型。采用脫離預訓練檢測網絡使其達到甚至超過預訓練模型的精度,針對小目標特點
2021-04-02 11:35:5026 作為模型的初始化詞向量。但是,隨機詞向量存在不具備語乂和語法信息的缺點;預訓練詞向量存在¨一詞-乂”的缺點,無法為模型提供具備上下文依賴的詞向量。針對該問題,提岀了一種基于預訓練模型BERT和長短期記憶網絡的深度學習
2021-04-20 14:29:0619 本文關注于向大規模預訓練語言模型(如RoBERTa、BERT等)中融入知識。
2021-06-23 15:07:313468 
做企業級數據分析的,沒個分析模型可不行,因此很多企業在做數據分析時都要投入大量的成本去搭建數據分析模型,但由于沒有經驗累積往往要走很多的彎路,付出大量試錯成本。難道就沒有別的辦法降低風險和成本?有,那就是選擇有現成數據分析模型的數據可視化軟件。
2021-09-30 16:57:22378 在某一方面的智能程度。具體來說是,領域專家人工構造標準數據集,然后在其上訓練及評價相關模型及方法。但由于相關技術的限制,要想獲得效果更好、能力更強的模型,往往需要在大量的有標注的數據上進行訓練。 近期預訓練模型的
2021-09-06 10:06:533351 
大模型的預訓練計算。 大模型是大勢所趨 近年來,NLP 模型的發展十分迅速,模型的大小每年以1-2個數量級的速度在提升,背后的推動力當然是大模型可以帶來更強大更精準的語言語義理解和推理能力。 截止到去年,OpenAI發布的GPT-3模型達到了175B的大小,相比2018年94M的ELMo模型,三年的時間整整增大了
2021-10-11 16:46:052226 
NVIDIA Megatron 是一個基于 PyTorch 的框架,用于訓練基于 Transformer 架構的巨型語言模型。本系列文章將詳細介紹Megatron的設計和實踐,探索這一框架如何助力
2021-10-20 09:25:432078 2021 OPPO開發者大會:NLP預訓練大模型 2021 OPPO開發者大會上介紹了融合知識的NLP預訓練大模型。 責任編輯:haq
2021-10-27 14:18:411492 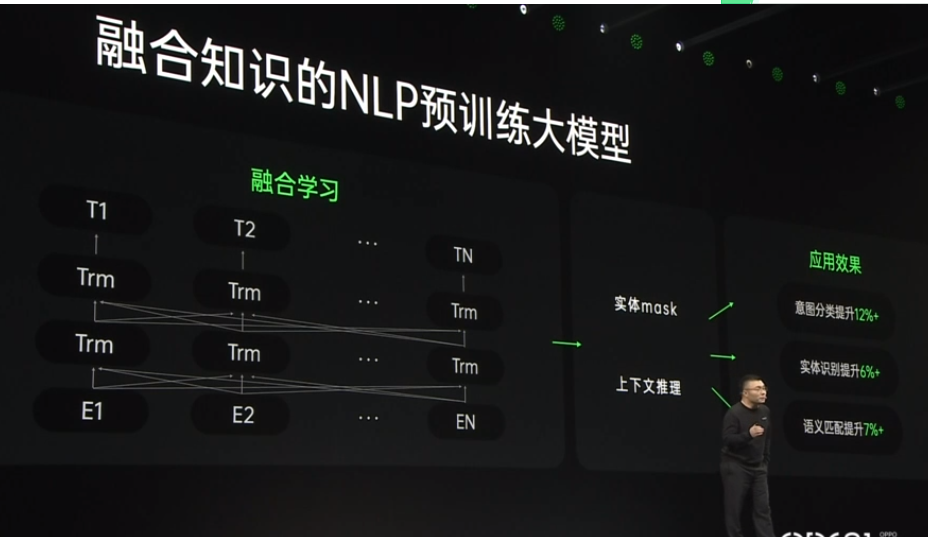
NLP中,預訓練大模型Finetune是一種非常常見的解決問題的范式。利用在海量文本上預訓練得到的Bert、GPT等模型,在下游不同任務上分別進行finetune,得到下游任務的模型。然而,這種方式
2022-03-21 15:33:301843 “強悍的織女模型在京東探索研究院建設的全國首個基于 DGX SuperPOD 架構的超大規模計算集群 “天琴α” 上完成訓練,該集群具有全球領先的大規模分布式并行訓練技術,其近似線性加速比的數據、模型、流水線并行技術持續助力織女模型的高效訓練。”
2022-04-13 15:13:11783 今天給大家介紹的,就是這樣一套不僅擁有上述能力,還直接提供目標檢測、屬性分析、關鍵點檢測、行為識別、ReID等產業級預訓練模型的實時行人分析工具PP-Human,方便開發者靈活取用及更改!
2022-04-20 10:16:481691 由于亂序語言模型不使用[MASK]標記,減輕了預訓練任務與微調任務之間的gap,并由于預測空間大小為輸入序列長度,使得計算效率高于掩碼語言模型。PERT模型結構與BERT模型一致,因此在下游預訓練時,不需要修改原始BERT模型的任何代碼與腳本。
2022-05-10 15:01:271173 為了減輕上述問題,提出了NoisyTune方法,即,在finetune前加入給預訓練模型的參數增加少量噪音,給原始模型增加一些擾動,從而提高預訓練語言模型在下游任務的效果,如下圖所示,
2022-06-07 09:57:321972 本文對任務低維本征子空間的探索是基于 prompt tuning, 而不是fine-tuning。原因是預訓練模型的參數實在是太多了,很難找到這么多參數的低維本征子空間。作者基于之前的工作提出
2022-07-08 11:28:24935 在中國圖象圖形大會的華為昇思MindSpore技術論壇上,中國科學院空天信息創新研究院(以下簡稱“空天院”)發布了首個面向跨模態遙感數據的生成式預訓練大模型“空天.靈眸”(RingMo,Remote Sensing Foundation Model)。
2022-08-23 09:38:141251 電子發燒友網報道(文/李彎彎)在深度學習中,經常聽到一個詞“模型訓練”,但是模型是什么?又是怎么訓練的?在人工智能中,面對大量的數據,要在雜亂無章的內容中,準確、容易地識別,輸出需要的圖像/語音
2022-10-23 00:20:037253 這些模型針對特定數據集進行了訓練,并經過準確性和處理速度的驗證。在部署之前,開發人員需要評估 ML 模型,并確保其滿足特定的閾值并按預期運行。有很多實驗可以提高模型性能,在設計和訓練模型時,可視化
2022-10-24 15:53:14471 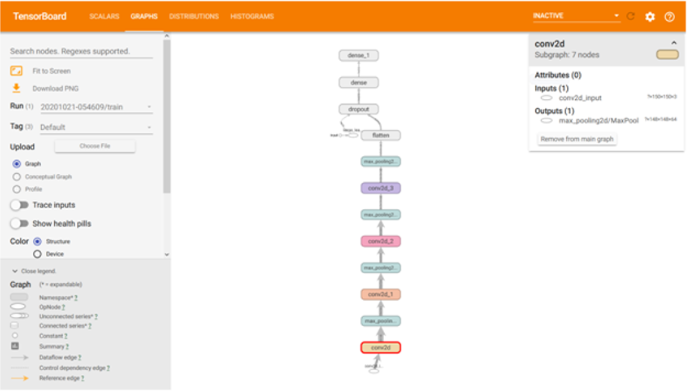
隨著BERT、GPT等預訓練模型取得成功,預訓-微調范式已經被運用在自然語言處理、計算機視覺、多模態語言模型等多種場景,越來越多的預訓練模型取得了優異的效果。
2022-11-08 09:57:193714 這些模型針對特定數據集進行了訓練,并經過了準確性和處理速度的證明。開發人員需要評估 ML 模型,并確保它在部署之前滿足預期的特定閾值和功能。有很多實驗可以提高模型性能,在設計和訓練模型時,可視化
2022-11-22 16:30:51334 可以訪問預訓練模型的完整源代碼和模型權重。 該工具套件能夠高效訓練視覺和對話式 AI 模型。由于簡化了復雜的 AI 模型和深度學習框架,即便是不具備 AI 專業知識的開發者也可以使用該工具套件來構建 AI 模型。通過遷移學習,開發者可以使用自己的數據對 NVIDIA 預訓練模型進行微調,
2022-12-15 19:40:06722 在應用程序開發周期中,第一步是準備和預處理可用數據以創建訓練和驗證/測試數據集。除了通常的數據預處理外,在MAX78000上運行模型還需要考慮幾個硬件限制。
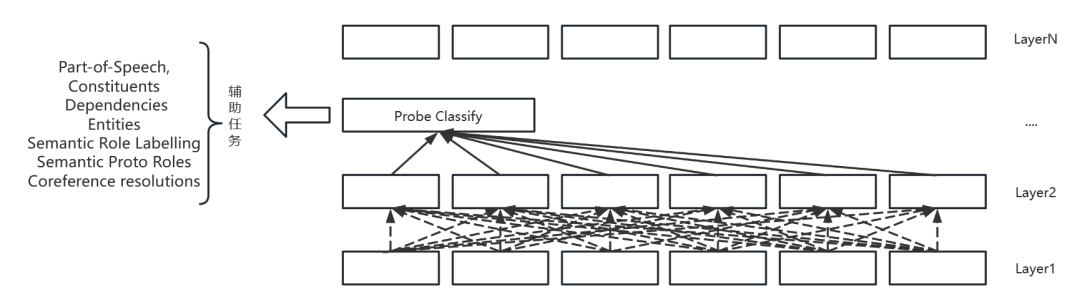
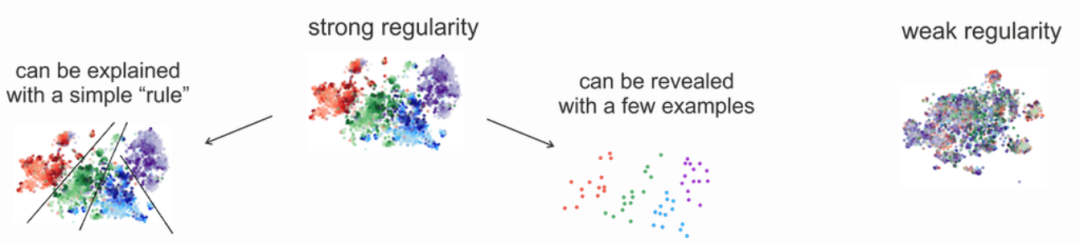
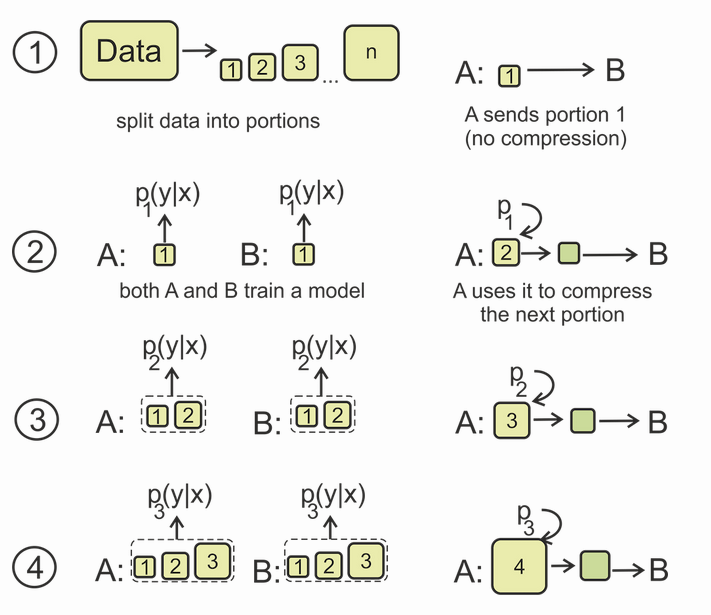
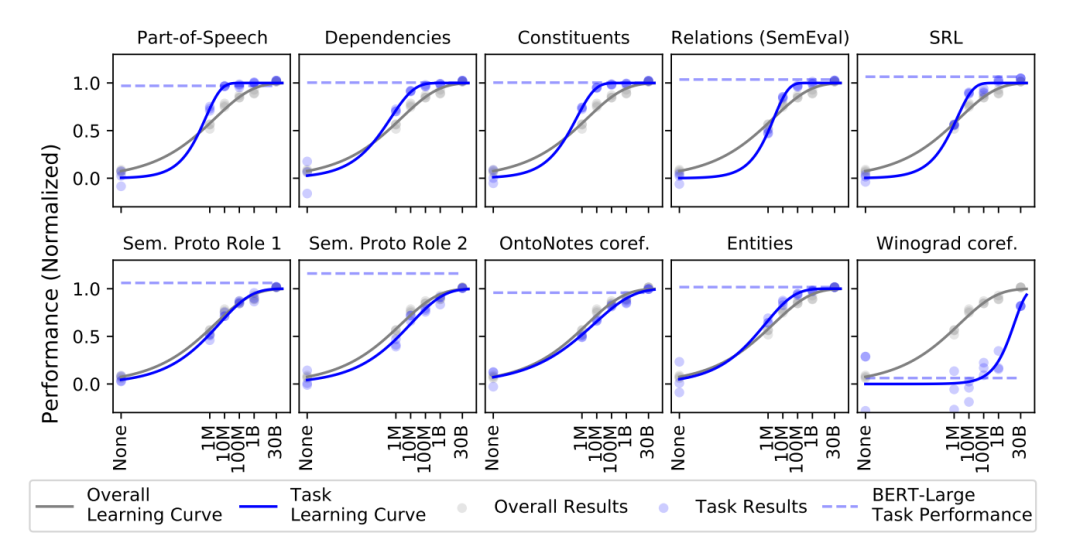
2023-02-21 12:11:44903 BERT類模型的工作模式簡單,但取得的效果也是極佳的,其在各項任務上的良好表現主要得益于其在大量無監督文本上學習到的文本表征能力。那么如何從語言學的特征角度來衡量一個預訓練模型的究竟學習到了什么樣的語言學文本知識呢?
2023-03-03 11:20:00911 你想知道的,都在這里!本文是神策數據「十問十答」科普系列文章的第一期,圍繞數據分析模型展開。 1 Q:常用的數據分析模型有哪些? A:神策數據總結了企業常用的數據分析模型,包括:事件分析、漏斗分析
2023-03-17 11:35:21343 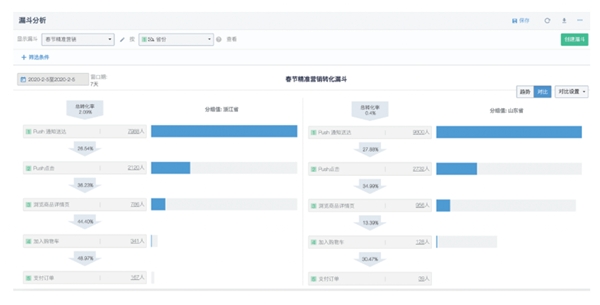
預訓練 AI 模型是為了完成特定任務而在大型數據集上訓練的深度學習模型。這些模型既可以直接使用,也可以根據不同行業的應用需求進行自定義。 如果要教一個剛學會走路的孩子什么是獨角獸,那么我們首先應
2023-04-04 01:45:021025 作為深度學習領域的 “github”,HuggingFace 已經共享了超過 100,000 個預訓練模型
2023-05-19 15:57:43494 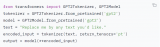
預訓練 AI 模型是為了完成特定任務而在大型數據集上訓練的深度學習模型。這些模型既可以直接使用,也可以根據不同行業的應用需求進行自定義。
2023-05-25 17:10:09595 vivo AI 團隊與 NVIDIA 團隊合作,通過算子優化,提升 vivo 文本預訓練大模型的訓練速度。在實際應用中, 訓練提速 60% ,滿足了下游業務應用對模型訓練速度的要求。通過
2023-05-26 07:15:03422 
實驗室在 SageMaker Studio Lab 中打開筆記本
為了預訓練第 15.8 節中實現的 BERT 模型,我們需要以理想的格式生成數據集,以促進兩項預訓練任務:掩碼語言建模和下一句預測
2023-06-05 15:44:40442 前文說過,用Megatron做分布式訓練的開源大模型有很多,我們選用的是THUDM開源的CodeGeeX(代碼生成式大模型,類比于openAI Codex)。選用它的原因是“完全開源”與“清晰的模型架構和預訓練配置圖”,能幫助我們高效閱讀源碼。我們再來回顧下這兩張圖。
2023-06-07 15:08:242186 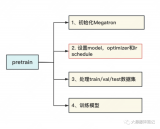
在一些非自然圖像中要比傳統模型表現更好 CoOp 增加一些 prompt 會讓模型能力進一步提升 怎么讓能力更好?可以引入其他知識,即其他的預訓練模型,包括大語言模型、多模態模型 也包括
2023-06-15 16:36:11277 
,一定要經歷以下幾個步驟: 模型選擇(Model Selection) :選擇適合任務和數據的模型結構和類型。 數據收集和準備(Data Collection and Preparation) :收集并準備用于訓練和評估的數據集,確保其適用于所選模型。 無監督預訓練(Pretraining) :
2023-06-21 19:55:02313 
大型語言模型如 ChatGPT 的成功彰顯了海量數據在捕捉語言模式和知識方面的巨大潛力,這也推動了基于大量數據的視覺模型研究。在計算視覺領域,標注數據通常難以獲取,自監督學習成為預訓練的主流方法
2023-07-24 16:55:03272 
模型訓練是將模型結構和模型參數相結合,通過樣本數據的學習訓練模型,使得模型可以對新的樣本數據進行準確的預測和分類。本文將詳細介紹 CNN 模型訓練的步驟。 CNN 模型結構 卷積神經網絡的輸入
2023-08-21 16:42:00885 數據并行是最常見的并行形式,因為它很簡單。在數據并行訓練中,數據集被分割成幾個碎片,每個碎片被分配到一個設備上。這相當于沿批次(Batch)維度對訓練過程進行并行化。每個設備將持有一個完整的模型副本,并在分配的數據集碎片上進行訓練。
2023-08-24 15:17:28537 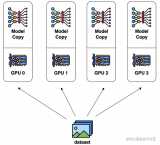
生成式AI和大語言模型(LLM)正在以難以置信的方式吸引全世界的目光,本文簡要介紹了大語言模型,訓練這些模型帶來的硬件挑戰,以及GPU和網絡行業如何針對訓練的工作負載不斷優化硬件。
2023-09-01 17:14:561046 
model 訓練完成后,使用 instruction 以及其他高質量的私域數據集來提升 LLM 在特定領域的性能;而 rlhf 是 openAI 用來讓model 對齊人類價值觀的一種強大技術;pre-training dataset 是大模型在訓練時真正喂給 model 的數據,從很多 paper 能看到一些觀
2023-09-19 10:00:06506 
NVIDIA Megatron 是一個基于 PyTorch 的分布式訓練框架,用來訓練超大Transformer語言模型,其通過綜合應用了數據并行,Tensor并行和Pipeline并行來復現 GPT3,值得我們深入分析其背后機理。
2023-10-23 11:01:33826 
如果我們使用的 數據集較大 ,且 網絡較深 ,則會造成 訓練較慢 ,此時我們要 想加速訓練 可以使用 Pytorch的AMP ( autocast與Gradscaler );本文便是依據此寫出
2023-11-03 10:00:191054 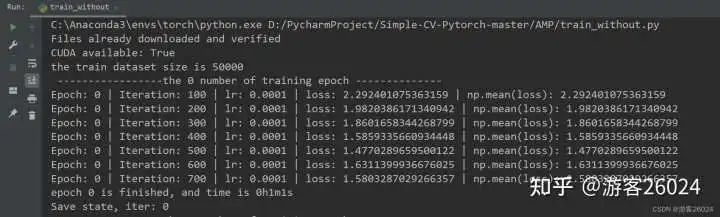
算法工程、數據派THU深度學習在近年來得到了廣泛的應用,從圖像識別、語音識別到自然語言處理等領域都有了卓越的表現。但是,要訓練出一個高效準確的深度學習模型并不容易。不僅需要有高質量的數據、合適的模型
2023-12-07 12:38:24547 
Hello大家好,今天給大家分享一下如何基于深度學習模型訓練實現圓檢測與圓心位置預測,主要是通過對YOLOv8姿態評估模型在自定義的數據集上訓練,生成一個自定義的圓檢測與圓心定位預測模型
2023-12-21 10:50:05529 
Hello大家好,今天給大家分享一下如何基于深度學習模型訓練實現工件切割點位置預測,主要是通過對YOLOv8姿態評估模型在自定義的數據集上訓練,生成一個工件切割分離點預測模型
2023-12-22 11:07:46259 
谷歌模型訓練軟件主要是指ELECTRA,這是一種新的預訓練方法,源自谷歌AI。ELECTRA不僅擁有BERT的優勢,而且在效率上更勝一籌。
2024-02-29 17:37:39337 谷歌在模型訓練方面提供了一些強大的軟件工具和平臺。以下是幾個常用的谷歌模型訓練軟件及其特點。
2024-03-01 16:24:01184 在近日舉辦的百度智能云千帆產品發布會上,三款全新的輕量級大模型——ERNIE Speed、ERNIE Lite以及ERNIE Tiny,引起了業界的廣泛關注。相較于傳統的千億級別參數大模型,這些輕量級大模型在參數量上有了顯著減少,為客戶提供了更加靈活和經濟高效的解決方案。
2024-03-22 10:28:3497
 電子發燒友App
電子發燒友App









 工商網監
工商網監
評論