 電子發燒友App
電子發燒友App


機器學習公平性的研究真的走在正確的道路上嗎?
隨著人工智能的發展,機器學習的技術越來越多地被應用在社會的各個領域,來幫助人們進行決策,其潛在的影響力已經變得越來越大,特別是在具有重要影響力的領域,例如刑事判決、福利評估、資源分配等。
因此可以說,從社會影響層面來講,考慮一個機器學習系統在做(有高影響力的)決策時,是否會對弱勢群體造成更加不利的影響,至關重要。
那么如何評估一個機器學習系統的公平性程度呢?目前普遍的方法就是,拿著待評估的系統在一些靜態(特別強調)的數據集上跑,然后看誤差指標。事實上,現在有許多測試機器學習公平性的工具包,例如AIF360、Fairlearn、Fairness-Indicators、Fairness-Comparison等。
雖然這些工具包在一些任務中能夠起到一定的指導作用,但缺點也很明顯:它們所針對的都是靜態的、沒有反饋、短期影響的場景。這一點從評估方法中能夠體現出來,因為數據集是靜態的。
然而現實生活中大多數卻是動態的、有反饋的場景,機器學習算法運行的背景往往對算法的決策具有長期的關鍵性影響。
因此針對機器學習算法公平性的研究,從靜態公平到動態公平,從單線公平到有反饋的公平,從短期公平到長期公平,是重要且必要的一步。
近日,來自谷歌的數位研究人員針對這一問題,在近期于西班牙舉辦的ACM FAT 2020會議(關于計算機技術公平性的國際會議)上發表了一篇論文,并基于這篇論文的研究開發了一組模擬組件ML-fairness-gym,可以輔助探索機器學習系統決策對社會潛在的動態長期影響。

論文及代碼鏈接:https://github.com/google/ml-fairness-gym
一、從案例開始
先從一個案例——借貸問題——開始。
這個問題是機器學習公平性的經典案例,是由加州大學伯克利分校的Lydia T. Liu等人在2018年發表的文章《Delayed Impact of Fair Machine Learning》提出的。

他們將借貸過程進行了高度的簡化和程式化,從而能夠讓我們聚焦于單個反饋回路以及其影響。
在這個問題的程式化表示中,個體申請人償還貸款的概率是其信用評分的函數。
每個申請人都會隸屬一個組,每個組具有任意數量的組員。借貸銀行會對每個組組員的借貸和還款能力進行觀察。
每個組一開始有不同的信用評分分布,銀行嘗試確定信用評分的閾值,閾值可以跨組應用并對每個組進行調整,從而讓銀行最好地達到目標。
信用評分高于閾值的申請人可以獲得貸款,低于閾值的申請人則被拒絕貸款。當模擬系統選擇一個申請人時,他們是否償還貸款是根據他們所在組的償還概率隨機決定的。
在該案例中,當前申請貸款的個人,可能會在未來申請更多的貸款,所以他們可以通過償還貸款來提高他們的信用評分以及其所在組的平均信用評分。同樣地,如果申請人沒有償還貸款,那么所在組的平均信用得分則會降低。
最有效的閾值設置取決于銀行的目標。
如果一家銀行追求的是總利潤最大化,那么它可能會根據申請人是否會償還貸款的可能性進行評估,來設置一個能夠最大化預期回報的閾值。
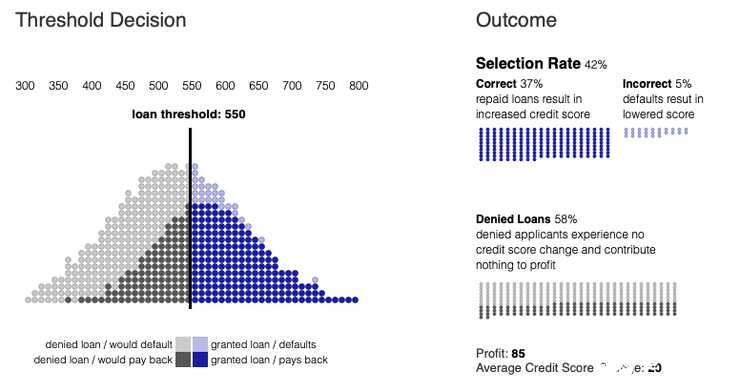
如果不考慮其他因素,銀行將試圖使其總利潤最大化。利潤取決于銀行從償還貸款中獲得的金額與銀行從違約貸款中損失的金額之比。在上圖中,這個損益比是1比-4。隨著損失相對于收益變得越大,銀行將更加保守地發放貸款,并提高貸款門檻。這里把超過這個閾值的部分稱為選擇率。
而有的銀行尋求的可能是能否對所有組做到公平。因此它們會嘗試設置一個能夠平衡總利潤最大化和機會均等的閾值,其中機會均等的目標則是實現平等的 true positive rates(TPR,又稱作靈敏度和召回率,衡量的是償還過貸款的申請人將被給予貸款)。
在這一場景下,銀行應用機器學習技術,基于已經發布的貸款和收入情況,來決定最有效的閾值。然而,由于這些技術往往關注的是短期目標,它們對于不同的組,可能會產生意料之外的和不公正的結果。
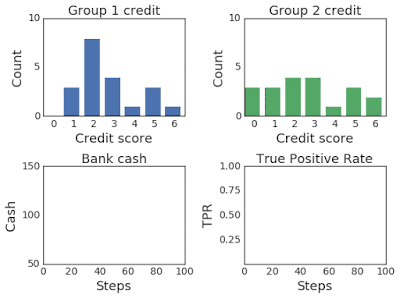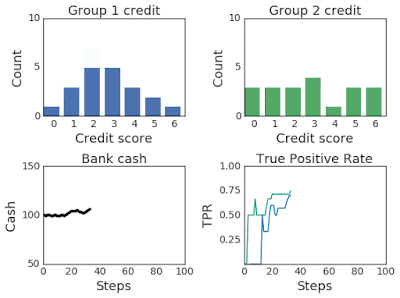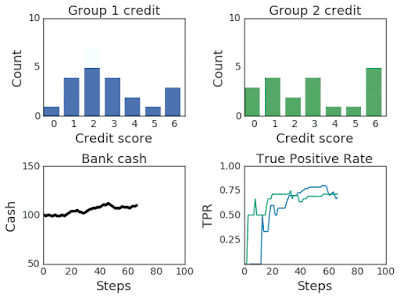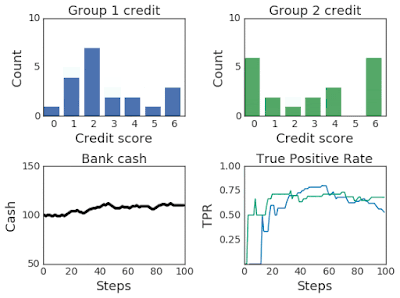
上面兩幅圖:改變兩組超過100個模擬步驟的信用評分分布。第 2 組最初的信用評分較低,因此屬于弱勢群體。下面兩幅圖:左圖為模擬過程中第一組和第二組的銀行現金,右圖為模擬過程中第一組和第二組的TPR。
二、靜態數據集分析的不足之處
在機器學習領域中,評估借貸等場景的影響的標準方法就是將一部分數據作為“測試集”,并使用這個測試集來計算相關的性能指標。然后,通過觀察這些性能指標在顯著組之間的差異,來評估公平性。 然而我們很清楚,在有反饋的系統中使用這樣的測試集存在兩個主要的問題:
第一,如果測試集由現有系統生成,它們可能是不完整的或者會在其他系統中顯示出內在的偏差。在借貸案例中,測試集就可能是不完整的,因為它僅僅只涵蓋曾經被發放過貸款的申請人是否償還貸款的信息。因此,數據集可能并沒有包括那些此前未被批準貸款或者沒有被發放貸款的申請人。
第二,機器學習系統的輸出會對其未來的輸入產生影響。由機器學習系統決定的閾值用來決定是否發放貸款,申請人是否償還這個貸款會影響到它們未來的信用評分,之后也會反饋到機器學習系統中。 這些問題都突出了用靜態數據集來評估公平性的缺陷,并促使研究者需要在部署了算法的動態系統中,分析算法的公平性。
三、可進行長期分析的模擬工具:ML-fairness-gym
基于上述需求,谷歌研究者開發出了ML-fairness-gym 框架,可以幫助機器學習從業者將基于模擬的分析引入到其機器學習系統中。這個組件已在多個領域被證明,在分析那些難以進行封閉形式分析的動態系統上是有效的。
ML-fairness-gym 使用了 Open AI 的 Gym 框架來模擬序列決策。在該框架中,智能體以循環的方式與模擬環境交互。在每一步,智能體都選擇一個能夠隨后影響到環境狀態的動作。然后,該環境會顯示出一個觀察結果,智能體用它來指導接下來的動作。
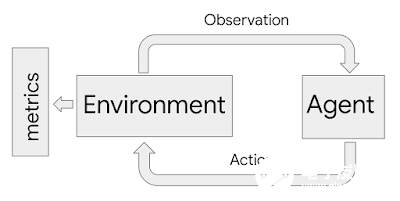
在該框架中,環境對系統和問題的動態性進行建模,而觀察結果則作為數據輸入給智能體,而其中智能體可以視為機器學習系統。
在借貸案例中,銀行充當的角色是智能體。它以從環境中進行觀察,從而接收貸款申請人以及他們的信用評分和組成員的信息,并以接受貸款或拒絕貸款的二分決策來執行動作。然后,環境對申請人是否成功償還貸款進行建模,并且據此來調整申請人的信用評分。ML-fairness-gym 可以通過模擬這些結果,從而來評估銀行政策對于所有申請人的公平性的長期影響。
四、公平性并不是靜態的:將分析擴展到長期影響
由于Liu 等人對借貸問題提出的原始公式,僅僅考量了銀行政策的短期影響結果,包括短期利潤最大化策略(即最大化獎勵智能體)和受機會均等(EO)約束的策略。而研究者使用 ML-fairness-gym ,則能通過模擬將分析擴展到長期影響。
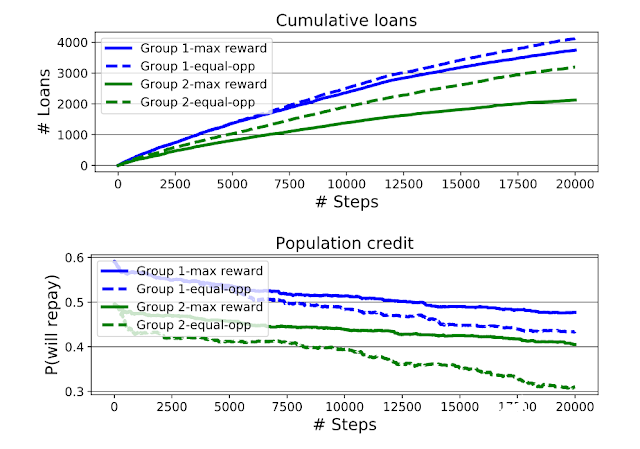
上圖:最大化獎勵智能體和機會均等智能體的累計放貸額,按申請人所隸屬的組劃分,藍色代表第 1 組,綠色代表第2組。下圖:模擬過程中的組平均信用評分(由各組有條件的償還概率量化而得出)。機會均等智能體增加了第2組的貸款通過率,但是加大了第2 組與第1 組合的信用評分差距。
谷歌研究者基于對上述借貸問題的長期分析得到了兩個發現:
第一,正如Liu等人所發現的,機會均等智能體(EO 智能體)有時會對弱勢群體(第2組,最初的信用評分更低)設置比最大化獎勵智能體更低的閾值,從而會給他們發放超出原本應該給他們發放的貸款。 這導致第2組的信用評分比第 1 組下降的更多,最終造成機會均等智能體模擬的兩組組之間的信用評分差距比最大化獎勵智能體模擬的更大。
同時,他們在分析中還發現,雖然機會均等智能體讓第2 組的情況似乎變得更糟,但是從累計貸款圖來看,弱勢的第2 組從機會均等智能體那里獲得了明顯更多的貸款。
因此,如果福利指標是收到的貸款總額,顯然機會均等智能體對弱勢群體(第 2組)會更有利; 然而如果福利指標是信用評分,那么顯然機會均等智能體將會讓弱勢群體的信用變得越來越差。
第二,在模擬過程中,機會均等約束(在每一步都在每組間強制實施均等的 TPR)并不能使TRP在總體上均等。這個可能違反直覺的結果可以看作是辛普森悖論的案例之一。
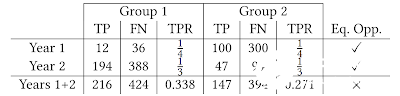
辛普森悖論的案例之一。TP 為真陽性分類,FN 對應假陰性分類,而TPR則是真陽性率。在第1、2年中,借貸者實施能夠在兩組間實現均等TPR的政策。但兩年的TPR總和并沒有實現均等TPR。
如上表所示,每兩年的均等TPR并不意味著TPR總體均等。這也顯示了當潛在人群不斷演變時,機會均等指標解釋起來會很難,同時也表明非常有必要用更多詳細的分析來確保機器學習能產生預期的效果。
上述內容,只討論了借貸問題,不過據谷歌研究人員表示,ML-fairness-gym 可以用來解決更廣泛的公平性問題。在論文中,作者還介紹了其他一些應用場景,感興趣者可以去閱讀論文原文。
ML-fairness-gym 框架在模擬和探索未研究過“公平性”的問題上,也足夠靈活。在他們另外的一篇論文《Fair treatment allocations in social networks》(社交網絡中的公平待遇分配)中,作者還研究了社交網絡中精準疾病控制問題的公平性問題。







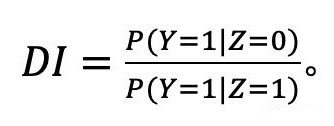









 工商網監
工商網監
評論