 電子發(fā)燒友App
電子發(fā)燒友App


深度殘差網(wǎng)絡(luò)的無人機多目標識別
人工智能技術(shù)與咨詢
來源:《圖學學報》。作者翟進有等
摘要:傳統(tǒng)目標識別算法中,經(jīng)典的區(qū)域建議網(wǎng)絡(luò)(RPN)在提取目標候選區(qū)域時計算量大,時間復雜度較高,因此提出一種級聯(lián)區(qū)域建議網(wǎng)絡(luò)(CRPN)的搜索模式對其進行改善。此外,深層次的卷積神經(jīng)網(wǎng)絡(luò)訓練中易產(chǎn)生退化現(xiàn)象,而引入殘差學習的深度殘差網(wǎng)絡(luò)(ResNet),能夠有效抑制該現(xiàn)象。對多種不同深度以及不同參數(shù)的網(wǎng)絡(luò)模型進行研究,將兩層殘差學習模塊與三層殘差學習模塊結(jié)合使用,設(shè)計出一種占用內(nèi)存更小、時間復雜度更低的新型多捷聯(lián)式殘差網(wǎng)絡(luò)模型(Mu-ResNet)。采用Mu-ResNet與CRPN結(jié)合的網(wǎng)絡(luò)模型在無人機目標數(shù)據(jù)集以及PASCAL VOC數(shù)據(jù)集上進行多目標識別測試,較使用ResNet與RPN結(jié)合的網(wǎng)絡(luò)模型,識別準確率提升了近2個百分點。
關(guān)鍵詞:無人機;殘差網(wǎng)絡(luò);級聯(lián)區(qū)域建議網(wǎng)絡(luò);目標識別
卷積神經(jīng)網(wǎng)絡(luò)屬于人工神經(jīng)網(wǎng)絡(luò)的一個分支,目前國際上有關(guān)卷積神經(jīng)網(wǎng)絡(luò)的學術(shù)研究進行的如火如荼,且該技術(shù)在計算機視覺、模式識別等領(lǐng)域成功得到應用[1-2]。卷積神經(jīng)網(wǎng)絡(luò)的優(yōu)點非常明顯,其是一種多層神經(jīng)網(wǎng)絡(luò),通過卷積運算和降采樣對輸入圖像進行處理,其網(wǎng)絡(luò)權(quán)值共享,可以有效減少權(quán)值數(shù)目,降低模型復雜度,且該網(wǎng)絡(luò)結(jié)構(gòu)具有高度的尺度不變性、旋轉(zhuǎn)不變性等多種仿射不變性。
近兩年的ILSVRC (imagenet large scale visual recognition challenge)競賽中,在目標檢測、分類、定位等項目上前3名的獲獎?wù)呔褂昧松窠?jīng)網(wǎng)絡(luò)的算法,如文獻[3]。在自主目標識別領(lǐng)域,基于機器學習的方法越來越展現(xiàn)出其強大的生命力,學習能力是智能化行為的一個非常重要的特征。隨著人工智能的發(fā)展,機器學習的方法以其強大的泛化能力,不斷在目標識別領(lǐng)域創(chuàng)造突破,也日漸成為計算機視覺各領(lǐng)域的研究主流。
深度卷積神經(jīng)網(wǎng)絡(luò)[4-5]為圖像分類帶來了許多突破[6-7]。深層神經(jīng)網(wǎng)絡(luò)以端到端的方式自然地集成了低、中、高級功能和類別[8],功能的“級別”可以通過堆疊層數(shù)(深度)來豐富。近年來,在十分具有挑戰(zhàn)性的ImageNet數(shù)據(jù)集上進行圖像分類取得領(lǐng)先的結(jié)果都是采用了較深的網(wǎng)絡(luò)。當更深的網(wǎng)絡(luò)能夠開始收斂時,就會暴露出退化的問題,隨著網(wǎng)絡(luò)深度的增加,精度達到飽和(這并不奇怪),然后迅速退化[9-11]。這種降級不是由過度設(shè)置引起的,是因在適當深度的模型中添加更多的層而導致了更高的訓練誤差。
1 深度殘差網(wǎng)絡(luò)搭建
1.1 深度卷積神經(jīng)網(wǎng)絡(luò)
在2012年的ILSVRC圖像分類大賽上,KRIZHEVSKY等[4]提出了AlexNet這一經(jīng)典的深度卷積神經(jīng)網(wǎng)絡(luò)模型。AlexNet相較于淺層的卷積神經(jīng)網(wǎng)絡(luò)模型,在性能上有了巨大的提升,而深層的網(wǎng)絡(luò)模型較淺層的網(wǎng)絡(luò)模型具有更大的優(yōu)勢。VGG16網(wǎng)絡(luò)以及GoogleNet網(wǎng)絡(luò)不斷刷新著ILSVRC競賽的準確率。從LeNet,AlexNet至VGG16和GoogleNet,卷積神經(jīng)網(wǎng)絡(luò)的層數(shù)在不斷加深。伴隨著網(wǎng)絡(luò)層數(shù)的加深,數(shù)據(jù)量以及運算量也在劇增。卷積模塊的數(shù)學表達為
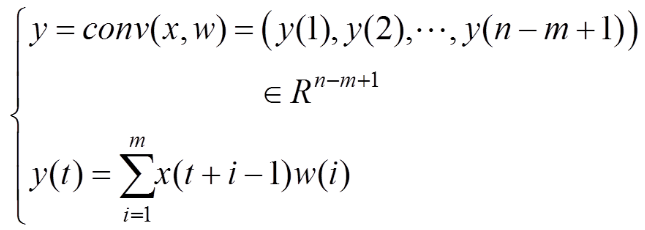
(1)
其中,x為輸入信號;w為卷積核尺寸大小且Rs×k,Rn×m,,且n>m。卷積操作的核心是:可以減少不必要的權(quán)值連接,引入稀疏或局部連接,帶來的權(quán)值共享策略大大地減少參數(shù)量,相對地提升了數(shù)據(jù)量,從而可以避免過擬合現(xiàn)象的出現(xiàn);另外,因為卷積操作具有平移不變性,使得學習到的特征具有拓撲對應性和魯棒性。
1.2 深度殘差學習機制
當卷積神經(jīng)網(wǎng)絡(luò)層數(shù)過深,容易出現(xiàn)準確率下降的現(xiàn)象。通過引入深度殘差學習可以有效解決退化問題。殘差學習并不是每幾個堆疊層直接映射到所需的底層映射,而是明確地讓其映射到殘差層中[12]。訓練深層次的神經(jīng)網(wǎng)絡(luò)是十分困難的,而使用深度殘差模塊搭建網(wǎng)絡(luò)可以很好地減輕深層網(wǎng)絡(luò)訓練的負擔(數(shù)據(jù)量)并且實現(xiàn)對更深層網(wǎng)絡(luò)的訓練[13]。殘差網(wǎng)絡(luò)的學習機制如圖1所示。
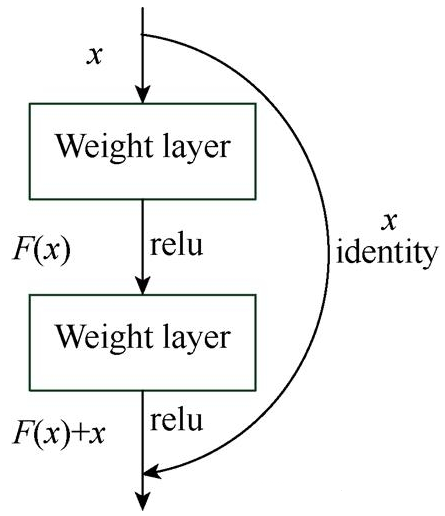
圖1 殘差網(wǎng)絡(luò)學習模塊
殘差學習模塊也是深度卷積神經(jīng)網(wǎng)絡(luò)的一部分[12]。現(xiàn)假設(shè)殘差學習模塊的輸入為x,要擬合的函數(shù)映射即輸出為H(x),那么可以定義另一個殘差映射為F(x),且F(x)=H(x)–x,則原始的函數(shù)映射H(x)=F(x)+x。文獻[12]通過實驗證明,優(yōu)化殘差映射F(x)比優(yōu)化原始函數(shù)映射H(x)容易的多。F(x)+x可以理解為在前饋網(wǎng)絡(luò)中,主網(wǎng)絡(luò)的輸出F(x)與直接映射x的和。直接映射只是將輸入x原封不動地映射到輸出端,并未加入任何其他參數(shù),不影響整體網(wǎng)絡(luò)的復雜度與計算量。殘差學習模塊的卷積層使用2個3×3卷積模塊,進行卷積運算[13-14]。引入了殘差學習機制的網(wǎng)絡(luò)依然可以使用現(xiàn)有的深度學習反饋訓練模式求解。
另一種3層殘差學習模塊,與2層不同的是第一個卷積層采用了1×1的卷積核,對數(shù)據(jù)進行降維,再經(jīng)過一個3×3的卷積核,最后在經(jīng)過一個1×1的卷積核還原。這樣做既保存了精度,又能夠有效地減少計算量,對于越深層次的網(wǎng)絡(luò)效果往往更好。圖2為3層殘差學習模塊,由于其是先降維再卷積再還原,這種計算模式對于越深層次的網(wǎng)絡(luò)訓練效果越好。
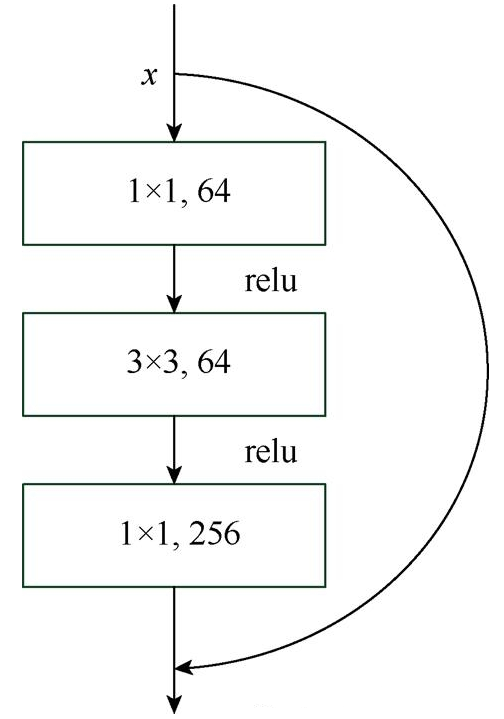
圖2 3層殘差學習模塊
1.3 搭建深度殘差網(wǎng)絡(luò)模型
本文設(shè)計出一種包含多條捷徑通道的多捷聯(lián)式殘差學習模塊,結(jié)合文獻[10]中2種殘差模塊的優(yōu)勢,多捷聯(lián)式殘差模塊使用了5層的堆棧,由1個1×1的卷積層進行降維,再經(jīng)過3個3×3的卷積層,最后經(jīng)過一個1×1的卷積層還原。在第一個1×1的卷積層之前和第二個3×3的卷積層之后使用一條捷徑,第三個3×3的卷積層之前和最后一個1×1的卷積層之后使用一條捷徑,再將第一個1×1的卷積層之前和最后一個1×1的卷積層之后使用一條捷徑。通過設(shè)置多條捷徑減輕網(wǎng)絡(luò)的訓練難度,采用降維以卷積的方式減少訓練的時間復雜度。多捷聯(lián)式殘差模塊如圖3所示。
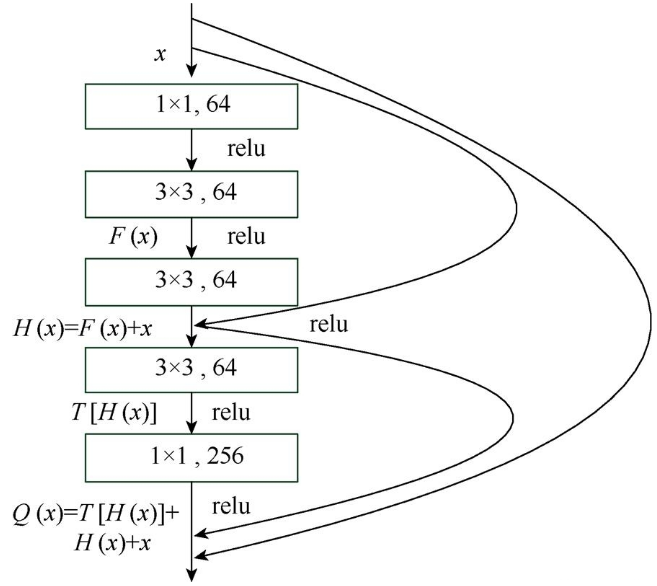
圖3 捷聯(lián)式殘差模塊
前三層卷積層定義為多捷聯(lián)式殘差模塊的第一級,后兩層網(wǎng)絡(luò)定義為第二級。現(xiàn)假設(shè)多捷聯(lián)式殘差模塊的輸入為x,第一級的殘差映射為F(x),要擬合的函數(shù)映射即第一級的輸出為H(x),則
F(x)=H(x)–x?(2)
第二級輸入函數(shù)為H(x)=F(x)+x。第二級殘差映射為T[H(x)],第二級的輸出Q(x),即
Q(x)=T[H(x)]+H(x)+x?(3)
Q(x)為多捷聯(lián)式殘差學習模塊的最終輸出,該模塊設(shè)置了多條捷徑,在深層的網(wǎng)絡(luò)中訓練更易收斂。
針對輸入為任意大小的多類別目標圖像,無人機(unmanned aerial vehicle,UAV)目標識別系統(tǒng)采用卷積神經(jīng)網(wǎng)絡(luò)和殘差學習機制結(jié)合。采用五層殘差學習模塊搭建了多種不同深度的殘差網(wǎng)絡(luò)(multi-strapdown ResNet,Mu-ResNet)。
2 無人機目標識別算法
2.1 級聯(lián)區(qū)域搜素網(wǎng)絡(luò)
在Faster-RCNN算法出現(xiàn)之前,最先進的目標檢測網(wǎng)絡(luò)都需要先用區(qū)域選擇建議算法推測目標位置,例如SPPnet和Fast-RCNN雖然都已經(jīng)做出來相應的改進,減少了網(wǎng)絡(luò)運行的時間,但是計算區(qū)域建議依然需要消耗大量時間。所以,REN 等[15]提出了區(qū)域建議網(wǎng)絡(luò)(region proposal network,RPN)用來提取檢測區(qū)域,其能和整個檢測網(wǎng)絡(luò)共享所有的卷積特征,使得區(qū)域建議的時間大大減少。
簡而言之,F(xiàn)aster-RCNN的核心思想就是RPN,而RPN的核心思想是使用CNN卷積神經(jīng)網(wǎng)絡(luò)直接產(chǎn)生region proposal,使用的方法就是滑動窗口(只在最后的卷積層和最后一層特征圖上滑動),即anchor機制[15]。RPN網(wǎng)絡(luò)需要確定每個滑窗中心對應視野內(nèi)是否存在目標。由于目標的大小和長寬比不一,使得需要多種尺度和大小的滑窗。Anchor給出一個基準窗的大小,按照不同的倍數(shù)和長寬比得到不同大小的窗[15]。例如,文獻[15]給出了3種面積{1282,2562,5122}以及3種比例{1∶1,1∶2,2∶1}共9種尺度的anchor,如圖4所示。
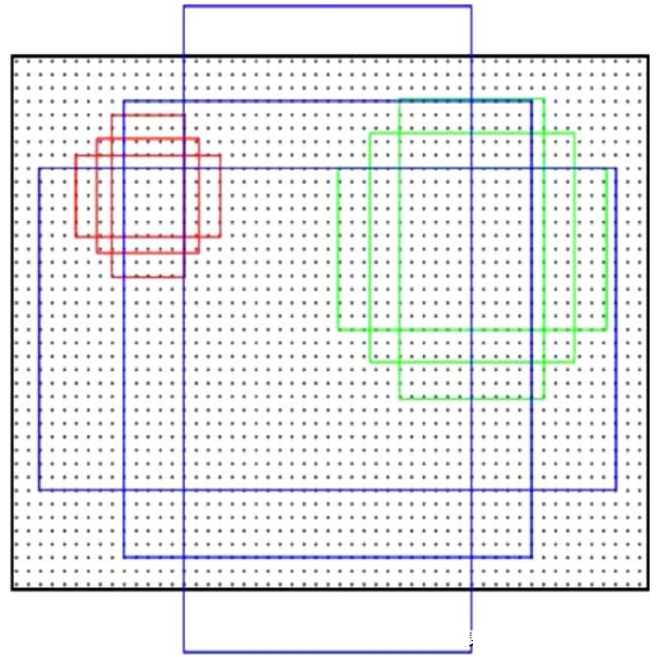
圖4 anchor示意圖
考慮到經(jīng)典的RPN網(wǎng)絡(luò)搜索區(qū)域過多,提取目標候選區(qū)域時計算量大,導致時間復雜度較高。本文提出一種級聯(lián)區(qū)域建議網(wǎng)絡(luò)(cascade region proposal network,CRPN)的搜索模式,第一級CNN采用32×32的卷積核,步長為4,在W×H的特征圖上進行滑窗,得到檢測窗口。由于搜索區(qū)域尺度較小,通過第一級CRPN可以過濾掉90%以上的區(qū)域窗口,最后在采用非極大值抑制(non-maximum suppression,NMS)消除高重合率的候選區(qū)域,可大大減少下級網(wǎng)絡(luò)的計算量以及時間復雜度。
將32×32網(wǎng)絡(luò)最后得到的目標候選區(qū)域調(diào)整為64×64,輸入第二級CRPN,再濾掉90%的候選區(qū)域窗口,留下的窗口再經(jīng)過NMS消除高重合率的候選區(qū)域。
最后將第二級CRPN輸出的候選區(qū)域調(diào)整為128×128,經(jīng)過同樣的操作濾掉背景區(qū)域。最后通過NMS去除高度重合區(qū)域,最終得到300個矩形候選區(qū)域。CRPN模型如圖5所示。
圖5 級聯(lián)區(qū)域搜索網(wǎng)絡(luò)
經(jīng)過級聯(lián)區(qū)域搜索網(wǎng)絡(luò)輸出的每一個位置上對應3種面積{1282,2562,5122}以及3種比例{1∶1,1∶2,2∶1}共9種尺度的anchor屬于目標前景和背景的概率以及每個窗口的候選區(qū)域進行平移縮放的參數(shù)。最后的候選區(qū)域分類層和窗口回歸層可采用尺寸為1×1的卷積層實現(xiàn)。
2.2 目標識別網(wǎng)絡(luò)數(shù)學模型
目標識別網(wǎng)絡(luò)的第一部分是以ResNet為模型提取特征圖作為RPN輸入。經(jīng)過ResNet共享卷積層厚的特征為
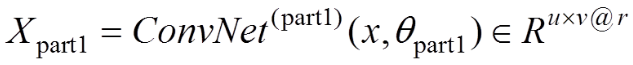
(4)
其中,輸入圖像為,通過殘差網(wǎng)絡(luò)的共享卷積層實現(xiàn)特征提取,提取的特征(輸出)為,即有r個特征圖,其尺寸為u×v;待學習的參數(shù)(權(quán)重和偏置)記為。
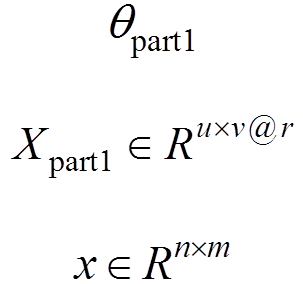
通過共享卷積層提取特征圖之后,利用區(qū)域生成網(wǎng)絡(luò)實現(xiàn)候選目標區(qū)域的提取。對于區(qū)域生成網(wǎng)絡(luò)的訓練,是將一幅任意大小的圖像作為輸入,輸出則是候選目標(矩形)區(qū)域的集合,并且對每個(矩形)區(qū)域給出是否為目標的得分,即
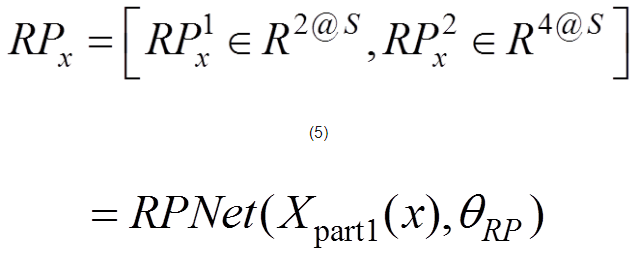
(5)
其中,x為輸入的圖像信息;RPx為輸出;S為候選目標區(qū)域(矩形)個數(shù);為判斷每個目標候選區(qū)域的得分,即
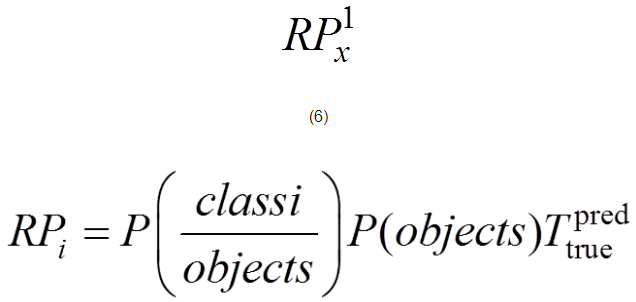
(6)
其中,P(objects)為該矩形框中是否有目標;P(classi/objects)為在有目標的情況下目標屬于第i類的概率;為該預測矩形框與真實目標邊框之間的交集與并集的比值。對于每一幅特征提取圖,選取得分大于0.7的kn個候選區(qū)域(矩形)作為正樣本,小于0.3的作為負樣本,其余的全部舍棄。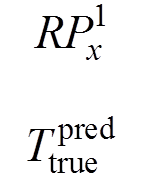
將區(qū)域生成網(wǎng)絡(luò)的輸出結(jié)合特征提取圖作為輸入,得到目標識別網(wǎng)絡(luò)的第二部分,即Fast-RCNN網(wǎng)絡(luò)。在共享卷積層后得到
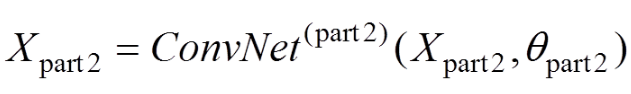
(7)
這一層卷積網(wǎng)絡(luò)是利用特征圖Xpart1來生成更深一層特征Xpart2,其中待學習的網(wǎng)絡(luò)參數(shù)為θpart2。感興趣區(qū)域(region of interest,ROI)的池化層輸出為
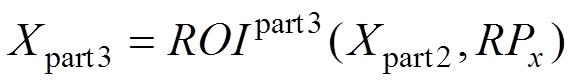
(8)
其中,輸入為區(qū)域生成網(wǎng)絡(luò)得到的候選區(qū)域RPx和式(8)中的Xpart2,但是因為目標候選區(qū)域的尺寸大小不同,為了減少裁剪和縮放對信息造成的損失,引入單層空域塔式池化(spatial pyramid pooling,SPP)來實現(xiàn)對不同尺寸圖像的輸出。最后經(jīng)過全連接層輸出為
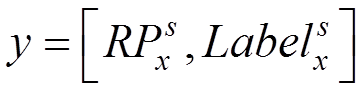
?
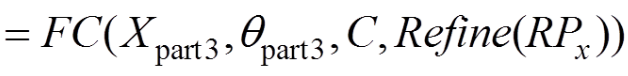
(9)
輸出y包含目標區(qū)域位置和目標區(qū)域類別2部分。其中輸入為式(9)中的Xpart3和目標的總類別個數(shù)C以及對每一類所對應的目標區(qū)域進行精修的參數(shù)Refine(RPx),即目標矩形區(qū)域中左上標與長寬高等滑動窗的位移,其中c=1,2,···,C。對于每一幅輸入圖像,可能存在的目標區(qū)域個數(shù)為s=1,2,···,S。
3 目標檢測實驗
3.1 Cifar10
Cifar10數(shù)據(jù)集共有60 000張彩色圖像,每張圖像大小為32×32,分為10個類,每類6 000張圖。數(shù)據(jù)集中有50 000張圖像用于訓練,構(gòu)成了5個訓練集,每一批包含10 000張圖;另外10 000張用于測試,單獨構(gòu)成一批測試集。數(shù)據(jù)集和訓練集圖像的選取方法是從數(shù)據(jù)集10類圖像中的每一類中隨機取1 000張組成測試集,剩下的圖像就隨機排列組成了訓練集。訓練集中各類圖像數(shù)量可不同,但每一類都有5 000張圖。
本文以文獻[10]中的殘差網(wǎng)絡(luò)形式搭建多種不同深度的經(jīng)典殘差網(wǎng)絡(luò)模型,而后又以本文提出的5層殘差模塊為基礎(chǔ),搭建了22層、37層和57層的殘差網(wǎng)絡(luò)模型,最后將本文的不同ResNet模型網(wǎng)絡(luò)的分類效果與經(jīng)典殘差網(wǎng)絡(luò)模型進行對比。
圖6是文獻[10]與本文設(shè)計的網(wǎng)絡(luò)性能對比圖。圖中ResNet網(wǎng)絡(luò)表示文獻[10]中的網(wǎng)絡(luò),Mu-ResNet表示本文設(shè)計的網(wǎng)絡(luò)。隨著網(wǎng)絡(luò)深度的增加,訓練誤差均不斷減小,網(wǎng)絡(luò)性能變的更優(yōu)。Mu-ResNet在22層時誤差高于ResNet,到37層時誤差低于ResNet,當繼續(xù)加深網(wǎng)絡(luò)至57層式,誤差下降近一個百分點。實驗結(jié)果表明,殘差網(wǎng)絡(luò)的收斂速度在迭代2 k以前較快,隨后減慢,在迭代3 k左右準確率快速下降,當?shù)?2 k時則開始收斂。
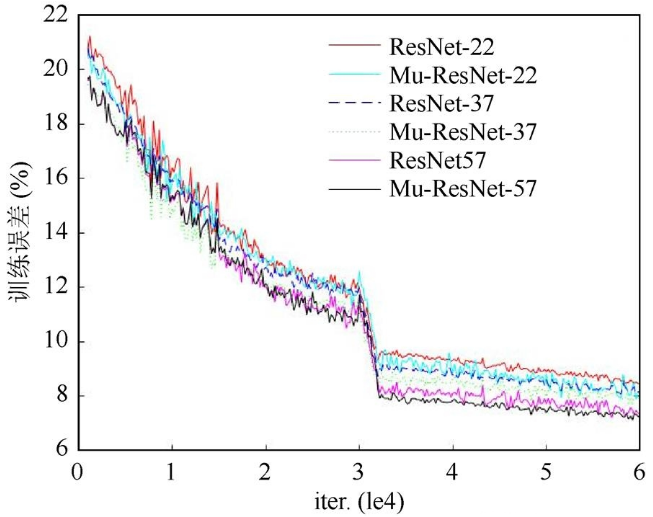
圖6 殘差網(wǎng)絡(luò)性能對比圖
圖7為本文搭建的3種不同深度的殘差網(wǎng)絡(luò)訓練cifar10的準確率,由圖可知深層次的Mu-ResNet-57準確率比Mu-ResNet-22高出了3個百分點。本文設(shè)計的網(wǎng)絡(luò)模型減少了內(nèi)存、時間復雜度和模型大小,使得同樣深度的網(wǎng)絡(luò)具有更好的性能,且網(wǎng)絡(luò)性能在更深層的優(yōu)化越明顯。
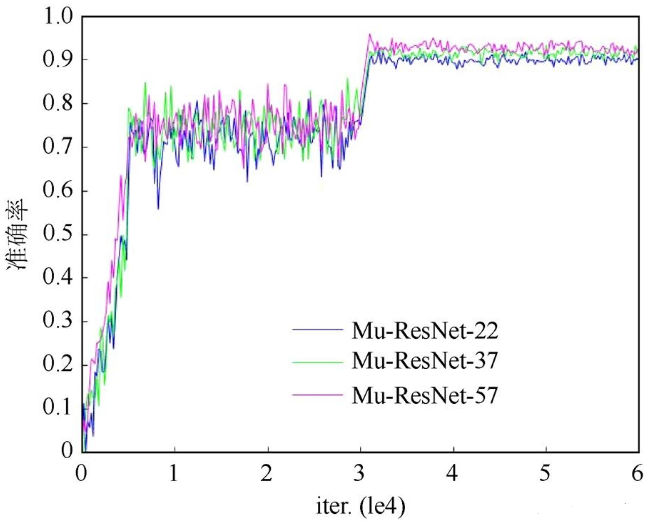

圖7 Mu-ResNet準確率曲線
通過cifar10實驗結(jié)果表明,本文提出的Mu-ResNet在目標分類上具有較好的效果。相比于經(jīng)典殘差網(wǎng)絡(luò)不僅減少了內(nèi)存、時間復雜度,在準確率上也有了一定的提升。從22、37、57層的Mu-ResNet準確率在不斷提升(圖6),且在訓練的過程中未觀察到退化現(xiàn)象,因此可從增加深度上顯著提高準確度。所有評估指標都體現(xiàn)了深度的好處。更深層的網(wǎng)絡(luò)能夠更好地提升Mu-ResNet的性能。
3.2 無人機目標識別
UAV執(zhí)行目標識別任務(wù)主要包含飛機、行人、小汽車、大型公交車、船以及飛行的鳥等10類常見目標。數(shù)據(jù)源主要來源于ImageNet,各大開源數(shù)據(jù)庫以及通過UAV航拍的圖像共100 000張。其中將70 000張圖像作為訓練集,30 000張作為測試集。
為了研究不同性能參數(shù)的特征提取網(wǎng)絡(luò)對識別效果的影響,共搭建了3種不同深度的網(wǎng)絡(luò)進行性能測試。22、37、57層的ResNet分別為Mu-ResNet-22,Mu-ResNet-37以及Mu-ResNet-57。
為了進行橫向?qū)Ρ龋瑢⒁陨暇W(wǎng)絡(luò)與VGG16,ZF和經(jīng)典殘差網(wǎng)絡(luò)結(jié)合經(jīng)典區(qū)域搜索網(wǎng)絡(luò)進行性能比較。通過在UAV目標數(shù)據(jù)集上進行訓練,測試得到各網(wǎng)絡(luò)模型在測試集上的識別準確率以及檢測每張圖片的時間。
Mu-ResNet-57的識別準確率略高于ResNet-57,但檢測時間更少;Mu-ResNet-22和Mu-ResNet-37的整體性能也優(yōu)于VGG16和ZF網(wǎng)絡(luò)。采用本文提出的5層殘差學習模塊搭建網(wǎng)絡(luò)模型能夠更有效地提高算法的性能,在計算時間和識別精度上都有所提升。
將ZF,VGG16,ResNet-57和Mu-ResNet-57結(jié)合CRPN,得到在UAV目標數(shù)據(jù)集上的召回率曲線。
當目標候選區(qū)域更少時,IOU更大,ResNet-57和Mu-ResNet-57的召回率較慢,當IOU在0.70~0.75區(qū)間內(nèi)Mu-ResNet-57效果最好。在IOU過小(<0.60)時,提取候選區(qū)域過多,嚴重影響網(wǎng)絡(luò)的速度,在IOU過大(>0.80)時,提取候選區(qū)域過少,導致召回率較低。
在十萬張圖像的UAV數(shù)據(jù)集上,VGG16,ResNet-57和Mu-ResNet-57與經(jīng)典區(qū)域搜索網(wǎng)絡(luò)和級聯(lián)區(qū)域搜素網(wǎng)絡(luò)相結(jié)合,對每一類目標的檢測準確率。RPN的proposal參數(shù)采用文獻[15]中效果最好的2 000。本文提出的CRPN中proposal參數(shù)取1 000。由表2可知,Mu-ResNet對airplane,human,automobile,truck的分類效果要優(yōu)于VGG16和ResNet,對ship,bird,horse的分類效果要差于ResNet。而采用CRPN的性能整體要優(yōu)于RPN。
通過以上實驗,綜合考慮檢測每幅圖像的時間以及檢測的準確率,采用5層殘差學習模塊搭建的57層Mu-ResNet結(jié)合CRPN在數(shù)據(jù)集上能達到90.40%的識別率且檢測每張圖像只需要0.093 s,故該網(wǎng)絡(luò)模型較適合用于UAV目標識別。
3.3 PASCAL VOC
PASCAL VOC 2007數(shù)據(jù)集作為經(jīng)典的開源數(shù)據(jù)集,包含5 k訓練集樣本圖像和5 k測試機樣本圖像,共有21個不同對象類別。PASCAL VOC 2012數(shù)據(jù)集包含16 k訓練樣本和10 k測試樣本。本文使用VOC 2007的5 k和VOC 2012的16 k作為網(wǎng)絡(luò)的訓練集,使用VOC 2007的5 k和VOC 2012的10 k作為網(wǎng)絡(luò)的測試集。采用ZF,VGG16,文獻[10]中提出的ResNet和本文中搭建的Mu-ResNet-57模型分別與文獻[15]中的RPN和本文提出的CRPN結(jié)合,來評估網(wǎng)絡(luò)的平均檢測精度,在VOC 2007+2012數(shù)據(jù)集上檢測結(jié)果見表3。
將Mu-ResNet-57與CRPN結(jié)合在VOC2007+2012數(shù)據(jù)集上測試,準確率達到76.20%。采用較深層網(wǎng)絡(luò)ResNet-57和Mu-ResNet-57模型提取特征時,CRPN效果較RPN有所提升。而采用淺層網(wǎng)絡(luò)ZF和VGG16模型時,CRPN與RPN對結(jié)果影響基本無區(qū)別。
以New-ResNet-57結(jié)合CRPN進行測試的結(jié)果圖。對于飛機、汽車、行人、鳥類等目標的識別具有良好的效果,該網(wǎng)絡(luò)模型對大小不同的物體識別效果均較好,具有良好的適應性。
4 結(jié)束語
針對UAV目標識別的實時性與準確性要求,以卷積神經(jīng)網(wǎng)絡(luò)為基礎(chǔ),搭建了多種框架的ResNet模型進行訓練,并且通過比較各網(wǎng)絡(luò)的性能優(yōu)劣,最終找到最適用于UAV目標識別的網(wǎng)絡(luò)。基于ResNet的目標識別算法,相較于傳統(tǒng)的目標識別算法可以避免人為提取目標特征而帶來的誤差,在識別精度上有了巨大的提升。對于復雜背景下的目標,ResNet的捷徑反饋機制能夠有效地降低網(wǎng)絡(luò)訓練的難度,使得更深層次的網(wǎng)絡(luò)依然能夠有效地訓練使用。使用ResNet的目標檢測應用于UAV目標識別中,通過準確率與檢測時間的綜合性能考慮要更優(yōu)于傳統(tǒng)的深度卷積神經(jīng)網(wǎng)絡(luò)。
然而本文所研究的目標數(shù)據(jù)集依然較少,在以后的研究中需要獲取更大、更多的UAV目標數(shù)據(jù)集,并且搭建更深層次、性能更優(yōu)的網(wǎng)絡(luò)以及更高效的特征提取來提高目標檢測的準確率與檢測時間。
關(guān)注微信公眾號:人工智能技術(shù)與咨詢。了解更多咨詢!
編輯:fqj



























 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論