一個在推上測試Phi-1.5的例子引發了眾多討論。例如,如果你截斷下圖這個問題并輸入給Phi-1.5....

這種“幻覺”現象可能是無意中產生的,它可以由多種因素導致,包括訓練數據集中存在的偏見、模型不能獲取最....
語言模型能夠執行各種任務,包括根據一組圖像創作引人入勝的故事,比較多個圖像中的共同和不同之處,用生動....
使用領域適應技術對預訓練LLM進行微調可以提高在特定領域任務上的性能。但是,進行完全微調可能會很昂貴....
要理解大語言模型(LLM),首先要理解它的本質,無論預訓練、微調還是在推理階段,核心都是next t....
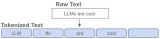
大模型是一個實驗工程,涉及數據清洗、底層框架、算法策略等多個工序,每個環節都有很多坑,因此知道如何避....
ByteDance Research 也在進行 AI for Science 的研究,包括機器學習與....
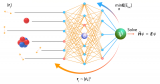
近期,一支來自中國的研究團隊正是針對這些問題提出了解決方案,他們推出了FLM-101B模型及其配套的....

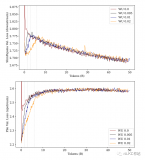
但,這種前提是「充分訓練」,如果只看訓練前期的話,使用更長的預熱步數(黃色的線)。無論是「上游任務」....
目前,單流架構模型在視頻分類、情感分析、圖像生成等多模態領域中得以廣泛應用,單流模型具有結構簡單、容....
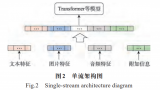
從 GPT-3,Gopher 到 LLaMA,大模型有更好的性能已成為業界的共識。但相比之下,單個 ....

用LLM根據用戶query生成k個“假答案”。(大模型生成答案采用sample模式,保證生成的k個答....
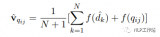
OpenAI 研究科學家 Andrej Karpathy 前段時間在微軟 Build 2023 大會....
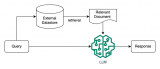
如圖所示,在RLAIF中,首先使用LLM來評估給定的文本和2個候選回復,然后,這些由LLM生成的偏好....
為了解決在插值RoPE嵌入時丟失高頻信息的問題,[4]中開發了"NTK-aware"插值。與同樣乘以....
Transofrmer一個常見的自監督目標是遮罩文本中出現的單詞,將該位置的query, key和v....
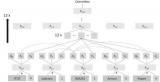
智能代理(AI Agents)長期以來都被視為通往人工通用智能(AGI)的一條希望途徑,預期中其能夠....
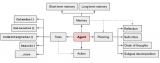
現有的文本嵌入表示方法在應用到新的任務或領域時,通常性能都會受損,甚至應用到相同任務的不同領域也會遇....
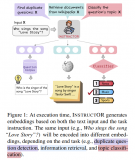
對于位置編碼,常規的做法是在計算 query,key 和 value 向量之前,會計算一個位置編碼向....
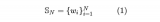
減輕幻覺問題并開發用于衡量幻覺的度量標準是一個蓬勃發展的研究課題。有許多初創公司專注于解決這個問題。....
首先團隊發現,目前已有的長下文外推方法普遍都是通過修改注意力機制中使用的位置編碼系統,指示token....

雖然目前學術界和工業界都在不斷推出自家的各種基座模型,但不可否認的是,完全預訓練一個具有初等推理能力....

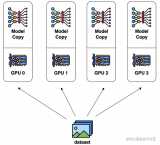
數據并行是最常見的并行形式,因為它很簡單。在數據并行訓練中,數據集被分割成幾個碎片,每個碎片被分配到....
答案是不會。原因是LLM作為語言模型,它的注意力機制是一個單向注意力機制(通過引入 Masked A....
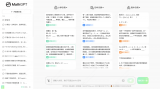
用戶使用MathGPT時,用文字或圖片方式上傳數學題,即可得到對話式的解答反饋,也可以通過“隨機來一....
從結構化數據中自然語言生成(NLG)往往會產生多種錯誤,從而限制了這些模型在面向客戶的應用中的實用性....

這對知識表示領域來說是一個巨大的步驟。長時間以來,人們關注的是明確的知識,例如嵌入在文本中的知識,有....

OpenAI所選擇的路徑就是:「Turn compute into alignment」,通過計算的....
Meta 發布的 Llama 2,是新的 SOTA 開源大型語言模型(LLM)。Llama 2 代表....
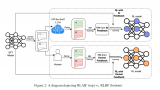
因此,我們認為現在是時候審視個性化服務的挑戰以及用大型語言模型來解決它們的機會了。特別是,我們在這篇....






 工商網監
工商網監
