 商湯論文精選:計算機視覺和深度學習技術最新突破
商湯論文精選:計算機視覺和深度學習技術最新突破
作為與ICCV、ECCV并稱為計算機視覺領域三大國際會議之一,本屆CVPR大會共收到5265篇有效投稿,接收論文1300篇,接收率為25.2%。
商湯科技CVPR 2019錄取論文在多個領域實現突破
作為國內CV領域的明星公司,商湯科技及聯合實驗室共有62篇論文被接收,其中口頭報告(Oral)論文18篇,相比2018 CVPR共44篇論文入選,增幅超40%。
商湯科技CVPR 2019錄取論文在多個領域實現突破:高層視覺核心算法——物體檢測與分割、底層視覺核心算法——圖片復原與補全、面向自動駕駛場景的3D視覺、面向AR/VR場景的人體姿態遷移、無監督與自監督深度學習前沿進展等。
值得一提的是,在CVPR 2019 Workshop NTIRE 2019視頻恢復比賽中(包含兩個視頻去模糊和兩個視頻超分辨率),來自商湯科技、香港中文大學、南洋理工大學、中國科學院深圳先進技術研究院組成的聯合研究團隊獲得了全部四個賽道的所有冠軍。
視頻恢復不是圖像恢復的簡單應用,因為其含有大量的時空冗余信息可以利用。目前行業最好的圖像超分辨算法是RCAN恢復,但使用EDVR算法視頻超分辨率的結果能看到更多的細節,效果大幅提升。作者發明了一種新的網絡模塊PCD對齊模塊,使用Deformable卷積進行視頻的對齊,整個過程可以端到端訓練。而且在挖掘時域(視頻前后幀)和空域(同一幀內部)的信息融合時,作者發明了一種時空注意力模型進行信息融合。此次比賽的EDVR算法代碼已開源(開源地址:https://github.com/xinntao/EDVR)。
商湯論文精選:計算機視覺和深度學習技術最新突破
高層視覺核心算法——物體檢測與分割
代表性論文:基于混合任務級聯的實例分割算法
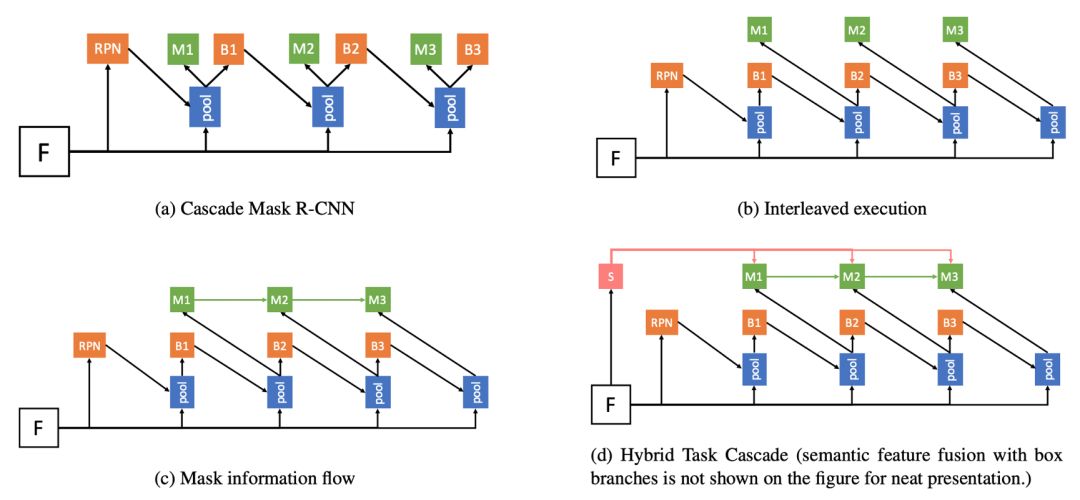
對于很多計算機視覺任務來說,級聯是一種經典有效的結構,可以對性能產生明顯提升。但如何將級聯結構引入實例分割的任務仍然是一個開放性問題。簡單地將物體檢測的級聯結構Cascade R-CNN與經典的實例分割算法Mask R-CNN進行結合,帶來的提升比較有限。
在這篇論文中,作者提出了一種新的框架Hybrid Task Cascade (HTC)。該框架是一個多階段多分支的混合級聯結構,對檢測和分割這兩個分支交替地進行級聯預測,除此之外,他們還引入了一個全卷積的語義分割分支來提供更豐富的上下文環境信息。HTC在COCO數據集上相對 Cascade Mask R-CNN獲得了1.5個點的提升。基于提出的框架,他們獲得了COCO 2018比賽實例分割任務的冠軍。
代表性論文:基于特征指導的動態錨點框生成算法
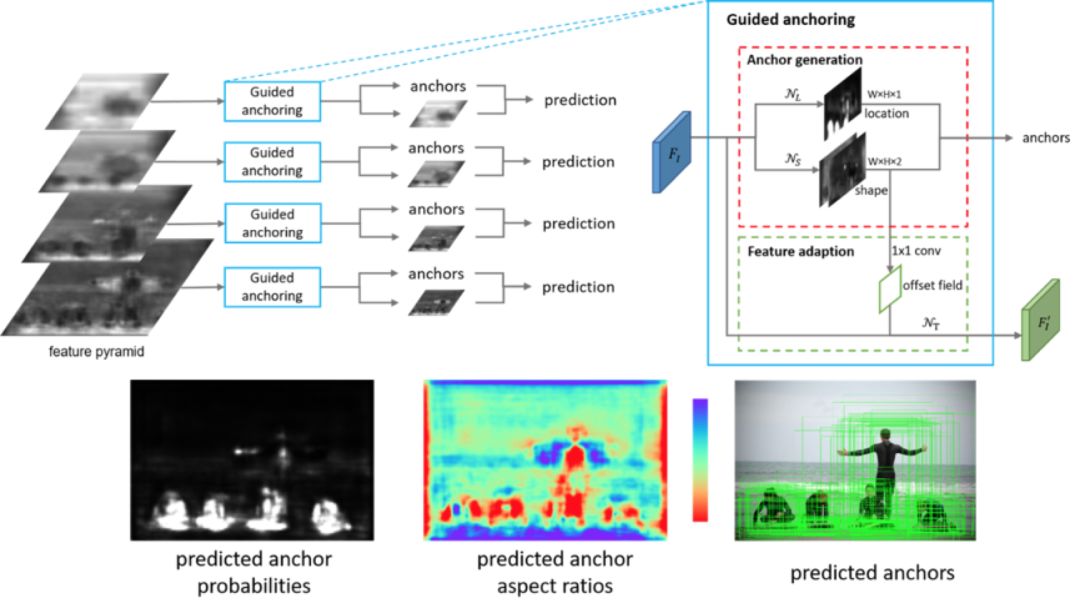
錨點框(Anchor)是現代物體檢測技術的基石。目前主流的物體檢測方法大多依賴于密集產生靜態錨點框的模式。在這種模式下,有著預定義的大小和長寬比的靜態錨點框均勻的分布在平面上。
本文反思了這一關鍵步驟,提出了一種基于特征指導的動態錨點框生成算法,該算法利用語義特征來指導錨點框生成的過程,具有高效率和高質量的特點。本算法可以同時預測目標物體中心區域和該區域應產生的錨點框的大小和長寬比,以及根據錨點框的形狀來調整特征,使特征與錨點框相吻合,從而產生極高質量的動態錨點框。
本方法可以無縫使用在各種基于錨點框的物體檢測器中。實驗表明本方法可以顯著提高三種最主流的物體檢測器(Fast R-CNN, Faster R-CNN, RetinaNet)的性能。
底層視覺核心算法——圖片復原與補全
代表性論文:基于網絡參數插值的圖像效果連續調節

圖像效果的連續調節在實際中有著廣泛的需求和應用, 但是目前基于深度學習的算法往往只能輸出一個固定的結果,缺乏靈活的調節能力來滿足不同的用戶需求。
針對這個問題, 本文提出了一種簡單有效的方式來達到對圖像效果的連續光滑的調節,而不需要進一步繁雜的訓練過程。該方法能夠在許多任務上得到應用, 比如圖像超分辨率,圖像去噪,圖像風格轉換,以及其他許多圖像到圖像的變換。
具體來說,作者對兩個或多個有聯系的網絡的參數進行線性插值,通過調節插值的系數,便可以達到一個連續且光滑的效果調節。他們把這個在神經網絡的參數空間中的操作方法稱為網絡參數插值。本文不僅展示了網絡參數插值在許多任務中的應用,還提供了初步的分析幫助更好地理解網絡參數插值。
代表性論文:基于光流引導的視頻修復

本文關注視頻中的修復問題,雖然近年來圖片修復(Image Inpainting)問題取得了很大的進展,可是在視頻上完成像素級的修復仍熱存在極大的挑戰。其困難主要在于:1)保證時序上的連續型 2)在高分辨率下實現修復 3)降低視頻對于計算的開銷。
本文致力于解決這三個問題,同時盡可能保證視頻的清晰度。在研究中發現,保證視頻的時序一致性,對于視頻修復任務來說非常重要,這不僅僅保證了修復后的視頻能夠有良好的觀看體驗,同時還幫助從視頻本身來抽取真實的像素塊來實現更加高效地修復。
所以作者提出的框架主要由兩部分組成,第一部分是通過深度神經網絡實現光流的補全,之后通過補全的光流在整個視頻間做像素的傳導,從而形成一條在時序上保持一致的像素鏈。這樣缺失的區域就可以通過它來實現修復,并且還能夠保證視頻的清晰度。
面向自動駕駛場景的3D視覺
代表性論文:PointRCNN: 基于原始點云的3D物體檢測方法
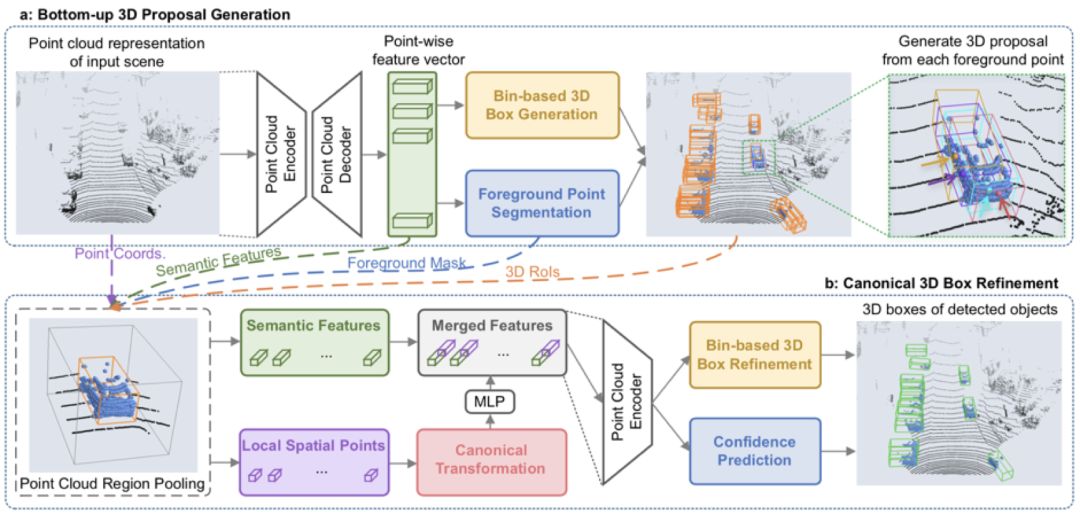
本文首次提出了基于原始點云數據的二階段3D物體檢測框架,PointRCNN。3D物體檢測是自動駕駛和機器人領域的重要研究方向,已有的3D物體檢測方法往往將點云數據投影到鳥瞰圖上再使用2D檢測方法去回歸3D檢測框,或者從2D圖像上產生2D檢測框后再去切割對應的局部點云去回歸3D檢測框。而這些方法中,前者在將點云投影到俯視圖上時丟失了部分原始點云的信息,后者很難處理2D圖像中被嚴重遮擋的物體。
作者觀察到自動駕駛場景中物體在3D空間中是自然分離的,從而可以直接從3D框的標注信息中得到點云的語義分割標注。因此本文提出了以自底向上的方式直接從原始點云數據中同步進行前景點分割和3D初始框生成的網絡結構,即從每個前景點去生成一個對應的3D初始框(階段一),從而避免了在3D空間中放置大量候選框。
在階段二中,前面生成的3D初始框將通過平移和旋轉從而規則化到統一坐標系下,并通過點云池化等操作后得到每個初始框的全局語義特征和局部幾何特征,他們將這兩種特征融合后進行了3D框的修正和置信度的打分,從而獲得最終的3D檢測框。
在提交到KITTI的3D檢測任務上進行官方測試時,作者提出的方法在只使用點云數據的情況下召回率和最終的檢測準確率均超越了已有的方法并達到了先進水平。目前該方法的已將代碼開源GitHub上。
面向AR/VR場景的人體姿態遷移
代表性論文:基于人體本征光流的姿態轉換圖像生成
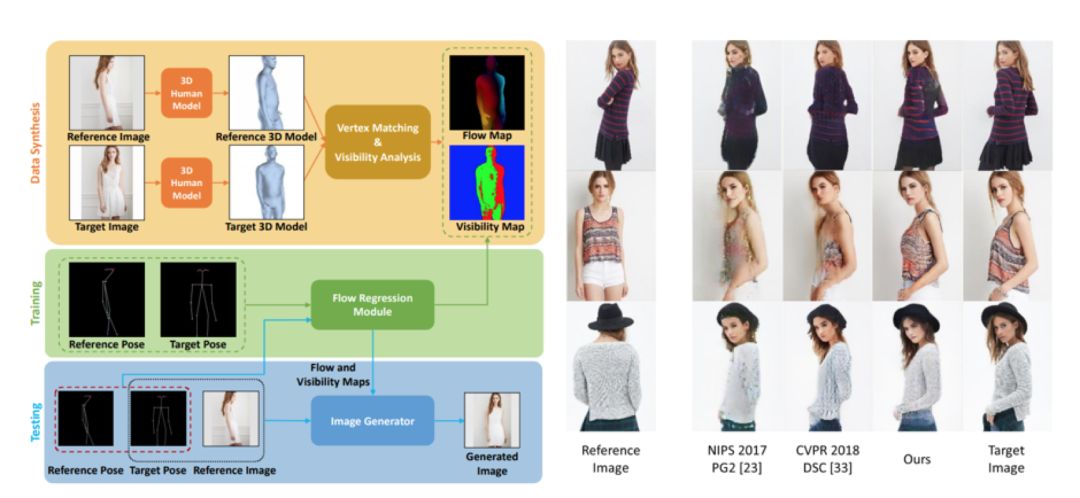
本文主要關注人體姿態轉移問題,即在給定一幅包含一個人的輸入圖像和一個目標姿態的情況下,生成同一個人在目標姿態下的圖像。作者提出利用人體本征光流描述不同姿態間的像素級對應關系。
為此,他們設計了一個前饋神經網絡模塊,以原始姿態和目標姿態作為輸入,迅速對光流場進行估計。考慮到真實光流數據難以獲取,他們利用3D人體模型擬合圖像中的人體姿態,生成對應姿態變化的光流場數據,用于模型訓練。
在該光流預測模塊的基礎上,他們設計了一個圖像生成模型,利用本征光流對人體的外觀特征進行空間變換,從而生成目標姿態下的人體圖像。他們的模型在DeepFashion和Market-1501等數據集上取得了良好的效果。
無監督與自監督深度學習前沿進展
代表性論文:基于條件運動傳播的自監督學習
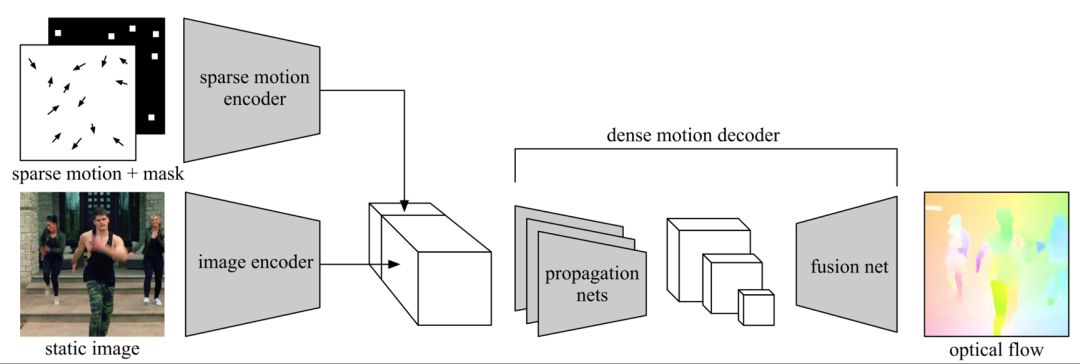
本文提出一種從運動中學習圖像特征的自監督學習范式。(1)在自然場景中,物體的運動具有高度的復雜性,例如人體和常見動物都具有較高的運動自由度。(2)同時,從單張圖片中推測物體的運動具有歧義性。現有基于運動的自監督學習方法由于沒有很好地解決這兩個問題,因而未能高效地從運動中學習到較好的圖像特征。
為此,作者提出了條件運動傳播這個自監督學習任務。訓練時,他們將單張圖像作為輸入,將目標運動場中抽樣出來的稀疏運動場作為條件,訓練神經網絡去恢復目標運動場。這樣訓練完的圖像編碼器可以用來作為其他高級任務的初始化。他們在語意分割、實例分割和人體解析等任務中相比以往自監督學習方法獲得了較大提升。
經過分析,作者發現條件運動傳播任務從運動中學習到了物體的剛體性、運動學屬性和一部分現實世界中的物理規律。利用這些特性,他們將它應用到交互式視頻生成和半自動實例標注,獲得了令人滿意的效果;而整個過程,沒有用到任何人工的標注。
Open-MMLab計劃,推動學術生態建設
現代AI系統日趨復雜,涉及很多的關鍵細節,這些細節的優化和調節需要長時間的專注和積累。因此,AI研究的未來推進,也將需要越來越多不同研究背景的團隊共同參與,讓每個團隊專注于某一個方面的開拓與探索。
所以商湯科技啟動Open-MMLab計劃,希望在一個統一的代碼架構上,逐步開放實驗室積累的算法和模型。目前,商湯科技和香港中文大學多媒體實驗室(MMLab)聯合開源了兩個重要的純學術代碼庫MMDetection和MMAction。
MMDetection
MMDetection是一個基于PyTorch的開源物體檢測工具包。該工具包采用模塊化設計,支持多種流行的物體檢測和實例分割算法,并且可以靈活地進行拓展,在速度和顯存消耗上也具有優勢。(https://github.com/open-mmlab/mmdetection)
目前已經支持單階段檢測器如SSD/RetinaNet/FCOS/FSAF,兩階段檢測器如Faster R-CNN/Mask R-CNN,多階段檢測器如Cascade R-CNN/Hybrid Task Cascade等,另外支持許多相關模塊如DCN/Soft-NMS/OHEM等,也支持混合精度訓練。有很多最新的工作也在MMDetection上開源。
商湯團隊還提供了完整的訓練和測試框架,以及超過200個訓練好的模型及其測試結果,希望能為社區提供統一的開發平臺和測試基準,助力物體檢測的相關研究。
MMAction
MMAction是一個基于Pytorch的開源視頻動作理解工具包,囊括了視頻動作分類、時域動作檢測(定位)、時空動作檢測等視頻理解的基礎任務。(https://github.com/open-mmlab/mmaction)
目前已經支持雙流、TSN、SSN等動作分類和動作檢測框架和基于Fast R-CNN的時空動作檢測基線模型,支持Plain 2D/Inflated 3D/Non-local等流行的網絡結構,支持UCF-101、Something-Something、Kinetics、THUMOS14、ActivityNet、AVA等視頻數據集,并提供相關的預訓練模型。
作為Open-MMLab系統開源項目的一部分,團隊希望MMAction可以成為視頻研究人員的測試平臺,促進視頻動作理解領域更上新臺階。
-
論文
+關注
關注
1文章
103瀏覽量
14972 -
深度學習
+關注
關注
73文章
5512瀏覽量
121408 -
商湯科技
+關注
關注
8文章
518瀏覽量
36129
原文標題:商湯62篇論文入選CVPR 2019,一覽五大方向最新研究進展
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
讓機器“看見”—計算機視覺入門及實戰 第二期基礎技術篇
深度學習在計算機視覺領域圖像應用總結 精選資料下載
介紹了計算機視覺領域內比較成功的10個深度學習架構

基于深度學習的計算機視覺技術在醫療領域中的現狀與應用
計算機視覺中的九種深度學習技術






 工商網監
工商網監
評論