 深度學習是否會取代傳統的計算機視覺?
深度學習是否會取代傳統的計算機視覺?
當你輾轉于各種論壇時,相信會經常看到這樣的問題:深度學習是否會取代傳統的計算機視覺?或者說,當深度學習看起來如此有效時,是否還有必要研究傳統的計算機視覺技術?
這是一個非常好的問題。
深度學習已經徹底改變了計算機視覺和人工智能這一領域,許多曾經看起來不可能解決的問題,深度學習都能夠解決——尤其是在圖像識別和分類問題上,機器已經超越人類。事實上,深度學習也強化了計算機視覺在行業中的重要地位。
但是,深度學習對計算機視覺來說僅僅是一種工具,它不可能成為解決所有問題的萬能藥。所以,在這篇文章中,我想闡述一下為什么傳統計算機視覺技術仍然很重要,并且值得我們去深入學習和研究。
本文將分為以下三個部分:
深度學習需要大數據
深度學習有時過于深度(殺雞焉用牛刀)
傳統的計算機視覺有助于更好的使用深度學習
首先我需要解釋下什么是傳統的計算機視覺技術,什么是深度學習,以及深度學習為什么如此具有革命性。
▌背景知識
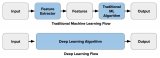
在深度學習出現之前,如果你想對圖像進行分類,首先需要執行一個特征提取(wiki:http://t.cn/RnzvIJ8)的步驟。特征是圖像中比較小的“有趣的”、具有描述性的或包含信息的塊。在這篇文章中你將會了解到傳統的計算機視覺技術,包括邊緣檢測(wiki:http://t.cn/RnzvqtE),角點檢測(wiki:http://t.cn/RnzvSVQ),對象檢測(wiki:http://t.cn/RnzvpqH)等等。
就特征提取和圖像分類而言,使用這些技術的思路是:從統一類別對象的圖像中(椅子、馬等)提取盡可能多的特征,并將這些特征視為對象的一個“定義”(眾所周知的詞袋模型),然后在其他圖像中搜索這些“定義”,如果詞袋模型中有相當一部分的特征都可以在這幅圖像中找到,那么這幅圖像被分類為包含該特定對象的類別(椅子,馬等)。
這種特征提取方法的難點在于,在給定圖像中,必須選擇需要查找哪些特征。當圖像中類別過多時(如10或20個類別),就會變得復雜而難以分類。角點?邊緣?還是紋理特征?只有使用不同的特征才可以更好地描述不同類別的對象。如果你在分類時使用很多特征,就必須對大量的參數進行微調。
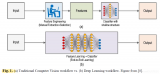
深度學習為我們展示了端到端學習(end-to-endlearning)這一概念,簡而言之,針對每個特定類別的對象,機器會自動學習需要查找什么特征。它為每個對象提供了最具描述性和顯著性的特征。換句話說,神經網絡可以探索圖像類別中的底層模式。
因此,通過端到端的學習,你不再需要自己動手來決定使用哪種傳統計算機視覺技術來描述這些特征,機器將會替你做這些工作。《連線》雜志這樣描述:
“舉個例子來說,如果你想訓練一個[深度]神經網絡來識別一只貓,你不需要告訴它要尋找圖像上的胡須、耳朵、毛發和眼睛。你需要做的就是向它展示成千上萬張貓的照片,這就能解決問題。如果它將狐貍誤認為貓,你也不需要重寫代碼,只需要繼續訓練即可。”
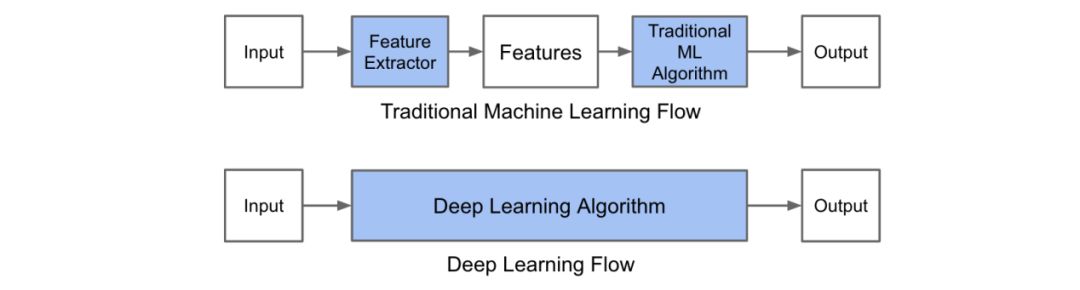
下圖展示了特征提取(使用傳統的計算機視覺技術)和端到端學習二者之間的差異:
下面我們將繼續討論,傳統的計算機視覺為什么仍然有必要且值得我們去學習。
▌深度學習需要大數據
首先,深度學習需要數據,并且是大量的數據!上面提到的那些經典的圖像分類模型都是在大型數據集上進行訓練的。常用于訓練的三種數據集分別是:
ImageNet數據集——包含150萬張圖像,有1000個類別。
MicrosoftCommon Objects in Context(COCO)數據集——包含250萬張圖像,有91個類別。
PASCAL VOC數據集——包含500萬張圖像,有20個類別。
比圖像分類簡單的任務或許并不需要如此多數據,但也少不到哪里去。你必須在你所擁有的數據上進行訓練(有些技巧能夠增強訓練數據,但也都是人為處理的方法)。
在訓練數據范圍之外的數據上,已訓練模型的表現就會很差,這是因為機器并沒有理解這個問題,所以不能在沒有訓練過的數據上進行泛化。
我們很難看到訓練過的模型的內在機制,手動調參也相當困難,因為深度學習模型里面有數百萬個參數——每個參數在訓練過程中都需要調整。從某種意義上來說,深度學習模型就是一個黑匣子。
傳統的計算機視覺具有充分的透明度,這能夠使你對解決方案能否在訓練環境之外運行做一個更好的評估和判斷。你可以更容易地了解算法中存在的問題,弄清楚什么地方需要調整。
▌殺雞焉用牛刀
這也許是我支持繼續研究傳統計算機視覺技術的最佳理由。
訓練一個深度神經網絡需要很長時間。如果使用專用硬件(例如高性能GPU)訓練最先進的圖像分類模型,也得需要將近一天的時間;如果使用標準筆記本電腦進行訓練,甚至需要一周或者更長的時間。
此外,如果你的訓練模型表現不佳應該怎么辦?你必須重來一遍,使用不同的訓練參數重新進行訓練,而且這個過程有時候還得重復數百次。
并不是所有問題需要使用深度學習。在某些問題上,傳統的計算機視覺技術的表現比深度學習更好,而且需要的代碼更少。
例如,我曾經參與過一個項目——檢測每個通過傳送帶的錫罐中是否有紅色的勺子。你可以訓練一個深度神經網絡來檢測勺子并完成上述過程,但這比較耗費時間;或者你也可以編寫一個簡單的關于紅色的顏色閾值算法(在紅色范圍內的任何像素都標記成白色,其他像素則都是黑色),然后計算有多少白色像素,這樣就可以快速檢測勺子。第二個方法很簡單,并且能在一個小時以內完成!
了解傳統的計算機視覺技術會為你節省大量時間以及減少不必要的麻煩。
▌理解傳統的計算機視覺方法可以提升你的深度學習技巧
理解傳統的計算機視覺實際上真的有助于你更好的使用深度學習。例如,計算機視覺中最常見的神經網絡是卷積神經網絡。但是什么是卷積?它實際上是一種廣泛使用的圖像處理技術(例如Sobel邊緣檢測)。了解卷積有助于了解神經網絡的內在機制,在解決問題時,它可以幫助你設計和調整模型。
其次是預處理,這通常是針對訓練數據而言。預處理這一步驟用到的主要是傳統的計算機視覺技術。例如,如果你沒有足夠多的訓練數據,則可以采用數據增強的方法來處理:通過對原來的圖像進行隨機旋轉、移位、剪切的方式來創建“新”的圖像。這些操作可以大大增加訓練數據的數量。
▌結論
在這篇文章中,我解釋了為什么深度學習仍然沒有取代傳統的計算機視覺技術,以及傳統的計算機視覺技術為何值得我們去學習和研究。
首先,深度學習通常需要大量的數據才能達到較好的性能,但是有時候這是不可能實現的。在這些情況下,傳統的計算機視覺技術就可以成為替代方案。
其次,對于某些特定的任務來說,有時候深度學習過于深度。在這種情況下,標準的計算機視覺技術可以更有效地解決問題,并且使用較少的代碼。
第三,了解傳統的計算機視覺技術實際上可以讓你更好地使用深度學習。這是因為通過傳統的計算機視覺,你可以更好地了解深度學習的內在機制,并且可以執行某些預處理步驟來提升深度學習的性能。
簡而言之,深度學習只是計算機視覺的一種工具,并不是萬能藥。不要因為深度學習現在較為流行就只使用深度學習。傳統的計算機視覺技術仍然非常重要,它可以為你節省很多時間,并減少許多不必要的麻煩。
-
視覺技術
+關注
關注
0文章
87瀏覽量
13526 -
大數據
+關注
關注
64文章
8897瀏覽量
137526 -
深度學習
+關注
關注
73文章
5507瀏覽量
121291
原文標題:為什么深度學習不能取代傳統的計算機視覺技術?
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深度學習在計算機視覺領域圖像應用總結 精選資料下載
深度學習崛起后,傳統計算機視覺方法被淘汰了嗎?

DL和傳統計算機視覺的比較
剖析深度學習與傳統計算機視覺之間的關系
傳統CV和深度學習方法的比較
計算機視覺中的九種深度學習技術

反思深度學習與傳統計算機視覺的關系






 工商網監
工商網監
評論