 生成對抗網絡與其他生成模型之間的權衡取舍是什么?
生成對抗網絡與其他生成模型之間的權衡取舍是什么?
根據一些指標顯示,關于生成對抗網絡(GAN)的研究在過去兩年間取得了本質的進步。在圖像合成模型實踐中的進步快到幾乎無法跟上。
但是,根據其他指標來看,實質性的改進還是較少。例如,在應如何評價生成對抗網絡(GAN)仍存在廣泛的分歧。鑒于當前的圖像合成基線標準已經非常高,似乎快達到了飽和,因此我們認為現在思考這一細分領域的研究目標恰逢其時。
在這篇文章中,谷歌大腦團隊的 Augustus Odena 就針對 GAN 的七大開放性問題作出了介紹。
這些問題分別是:
生成對抗網絡與其他生成模型之間的權衡取舍是什么?
生成對抗網絡可以對哪種分布進行建模?
我們如何在圖像合成外擴展生成對抗網絡的應用?
關于生成對抗網絡訓練的全局收斂,我們該作何評價?
我們應如何評估生成對抗網絡,又該在何時使用它們?
生成對抗網絡的訓練是如何調整批量數據的?
對抗生成網絡和對抗樣本的關系是怎樣的?
生成對抗網絡與其他生成模型之間的權衡取舍是什么?
除了對抗生成網絡之外,目前流行的還有另外兩種生成模型:流模型(Flow Models)和自回歸模型(Autoregressive Models)。這個名詞不必深究其字面含義。它們只是用來描述“模型空間”中模糊聚類的有用術語,但是有些模型很難被簡單歸類為這些聚類中的哪一個。我也完全沒有考慮變分自編碼器(VAEs),因為其在目前任何任務中都不是最先進的。
粗略地講,流模型(Flow Models)先將來自先驗的樣本進行一系列可逆變換,以便可以精確計算觀測值的對數似然。另一方面,自回歸模型將觀測值的分布分解為條件分布并每次只處理觀測值的一部分(對于圖像,其每次可能只處理一個像素)。近期的研究表明,這些模型具有不同的性能特征和權衡方法。如何準確地描述這些權衡并確定它們是否為該類模型簇中所固有的,這是一個有趣的開放性問題。
具體來說,先暫時考慮對抗生成網絡和流模型之間計算成本的差異。乍一看,流模型似乎可以使對抗生成網絡變得多余。流模型可以精確得進行對數似然計算和精確推理,因此如果訓練流模型和對抗生成網絡的計算成本相同,則對抗生成網絡可能失去用武之地。而訓練對抗生成網絡需要花費大量精力,因此我們應該關心流模型是否能淘汰對抗生成網絡。即使在這種情況下,可能仍有其他理由支持在圖像到圖像翻譯等環境中使用對抗訓練。將對抗訓練和極大似然訓練相結合可能仍有意義。
然而,訓練對抗生成網絡和流模型所需的計算成本之間似乎存在著較大差距。為了估計這個差距的大小,我們考慮這兩個在人臉數據庫上訓練的模型。GLOW模型(一種基于流模型的生成模型)使用40個GPU、約2億參數值訓練,耗時兩周后生成像素為256x256的名人臉。
相比之下,高效地對抗生成網絡采用類似的人臉數據庫,使用8個GPU、約4600萬個參數訓練,歷時4天后生成了像素為1024x1024圖像。粗略地說,流模型比生成對抗網絡多花費了17倍的GPU天數和4倍的參數來生成圖像,但其像素卻降低了16倍。這一對比并不完美。例如,流模型也可以用更好的技術方法來提高,但是這些方法能讓你有不同的感悟。
為什么流模型的效率較低?我們考慮可能是如下兩個原因:首先,極大似然訓練在計算上比對抗訓練更難。特別當訓練集的一些元素被生成模型指定為零概率,會受到無比嚴厲的懲罰!另一方面,生成對抗網絡的生成器僅在為訓練集元素賦予零概率時而間接受到懲罰,并且這種懲罰不那么嚴厲。其次,標準化流(Normalizing Flow)可能在表示某些函數時較為低效。6.1節做了一些關于其效果的小實驗,但目前我們尚不知道在這個問題是否有深入的分析。
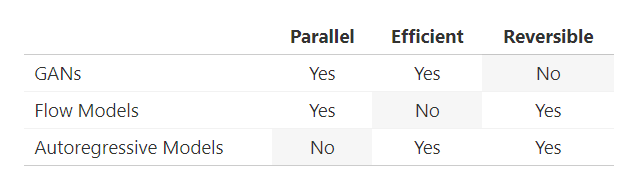
我們已經討論過生成對抗網絡和流模型之間的權衡,那么自回歸模型如何?事實證明,自回歸模型可以表示為不可并行化的流模型(因為它們都是可逆的)。在這種情況下,可并行化的說法有點不精確。我們的意思是流模型的采樣通常必須按順序進行,每次一個觀測值。不過,可能有一些方法可以繞過這個限制。事實證明,自回歸模型比流模型上在時間和參數上效率更高。因此,生成對抗網絡是并行、高效但不可逆的,流模型是可逆、并行但不高效,而自回歸模型是可逆的、高效,但非并行的。
回到第一個開放的問題:

解決這個問題的一種方法是研究更多模型,這些模型將是多類模型的混合。有考慮將生成對抗網絡和流動模型混合,但我們認為這種方法的研究尚不充分。
我們也不確定極大似然訓練是否一定比生成對抗網絡訓練更難。確實,在生成對抗網絡訓練損失下,沒有明確禁止在訓練數據上設置一些零質量的數據,但是如果生成器這么做了,那么強大的鑒別器將能夠做得更好。因此,看起來生成對抗網絡似乎在實踐中會學習低支持的分布。
最后,我們懷疑流模型在每個參數上的表達能力上不如任意解碼器函數,我們還認為這在一些假設條件下是可以被證明的。
生成對抗網絡模型可以對哪種分布進行建模?
大多數生成對抗網絡的研究側重于圖像合成。人們通常使用深度學習社區中幾個標準的圖像數據集上訓練生成對抗網絡:MNIST、CIFAR-10、STL-10、CelebA、和ImageNet。
關于這些數據集中哪一個是“最容易建模”的數據,有一些觀點認為MNIST和CelebA被認為比ImageNet、CIFAR-10或STL-10更容易,因為它們“非常常規”。另有人認為,“大量的類別使生成對抗網絡很難訓練ImageNet圖片”。這些結果是有事實證明的,即CelebA上的最先進圖像合成模型生成的圖像似乎比ImageNet上的最先進圖像合成模型更令人信服。
然而,我們必須通過復雜的實踐來得出這些結論,并試圖在更大,更復雜的數據集上訓練生成對抗網絡。我們特別研究了生成對抗網絡如何對恰好用于物體識別的數據集進行處理。
與任何科學一樣,我們希望能夠有一個簡單的理論來解釋我們的實驗觀察結果。理想情況下,我們可以查看數據集,在不訓練生成模型的情況下進行一些計算,然后說“此數據集對于生成對抗網絡建模比變分自編碼器容易”。我們在此已經取得了一些進展,但我們認為還有可更多的工作需要做。現在的問題是:

我們也可能會問以下相關問題:“給分布建模”是什么意思?我們是否對低支持率表示滿意,還是需要真正的密度模型?是否存在生成對抗網絡永遠無法學習建模的分布?對于某些合理的資源消耗模型,是否存在理論上生成對抗網絡可學習,但是實際上并不能有效學習的分布?對于生成對抗網絡而言,這些問題的答案是否與其他生成模型的有所不同?
我們提出了回答這些問題的兩種策略:
合成數據集-我們可以研究合成數據集,以探討哪些特征會影響其可學習性。例如,作者創建了合成三角形數據集。我們認為這方面尚未被探索。合成數據集甚至可以根據關注的數量(例如連通性或平滑性)進行參數化,以便進行系統研究。這種數據集也可用于研究其他類型的生成模型。
修改現有理論結果-我們可以采用現有的理論結果并嘗試修改假設,以考慮數據集的不同屬性。例如,我們可以獲得適用于給定單峰數據分布的生成對抗網絡的結果,并查看當數據分布變為多峰時會發生什么情況。
我們如何在圖像合成外擴展生成對抗網絡的應用?
除了圖像翻譯和遷移學習等應用,大多數生成對抗網絡的成功都是在圖像合成中取得的。嘗試在圖像領域外使用生成對抗網絡,主要集中于以下三個領域:
文本-文本的離散性使得我們難以應用生成對抗網絡。這是因為生成對抗網絡依賴將鑒別器中的信號通過生成的文本反向傳播到發生器。解決這一困難有兩種方法。第一種是僅對離散數據的連續表示進行生成對抗網絡行為。第二種是使用實際離散模型,并嘗試使用梯度估計訓練生成對抗網絡。還有其它更復雜的改進方法,但據我們所知,沒有一種方法的結果能與基于似然的語言模型相比較。
結構化數據-那么其他非歐幾里得的結構化數據,如圖的應用會怎樣?這類數據的研究稱為幾何深度學習。生成對抗網絡在這里取得的成果有限,但其他深度學習技術也是如此,因此很難判斷生成對抗網絡在這里能發揮多大作用。我們嘗試在這個領域中使用生成對抗網絡,使發生器(和鑒別器)隨機游走(隨機行走等是指基于過去的表現,無法預測將來的發展步驟和方向。),目的是盡量類似于從源圖取樣的隨機游走。
音頻-音頻是生成對抗網絡最可能像圖像應用那樣大獲成功的領域。首次將生成對抗網絡應用于無監督音頻合成的重大嘗試是,作者在處理音頻數據時做了各種特殊寬松設置。最近的研究表明,生成對抗網絡在某些感知指標上甚至能優于自回歸模型。
盡管進行了這些嘗試,圖像顯然是生成對抗網絡應用最容易的領域。這使得我們思考以下問題:

擴展到其他領域是需要新的訓練技術,還是僅僅需要在每個領域更好的隱式先驗信息?
我們期望生成對抗網絡最終在其他連續數據上能實現類似圖像合成水平的成功,但它需要更好的隱式先驗信息。要找到這些先驗信息,就需要認真思考什么是合理的、并在特定領域計算上是可行的。
對于結構化數據或不連續數據,我們尚不能確定。一種方法是使發生器和鑒別器都成為經過強化學習訓練的代理。但要使這種方法起作用可能需要大規模的計算資源。最后,這個問題可能只需要基礎研究的進展就能解決。
關于生成對抗網絡訓練的全局收斂,我們該作何評價?
訓練生成對抗網絡與訓練其他神經網絡不同,因為我們同時優化發生器和辨別器以達到相反的目的。在某些假設下,該同步優化是局部漸近穩定的。
不幸的是,我們很難證明一般情況下的令人感興趣的信息。這是因為鑒別器/發生器的損失是其參數的非凸函數。但所有神經網絡模型都存在此問題!我們希望能以某種方式來解決同步優化產生的問題。這促使我們開始思考以下問題:

我們在這個問題上得到了突出進展。廣義而言,現有3種技術,所有這些技術均呈現出了有前景的成果,但均未研究完成:
簡化假設-第一種策略是簡化關于發生器和鑒別器的假設。例如,如果采用特殊技術和一些額外假設進行優化,則可以證明簡化的LGQ GAN(線性發生器、高斯數據和二次判別器)能夠全局收斂。如果逐漸放寬這些假設,結果可能會很可觀。例如,我們可以遠離單峰分布。這是很自然的就能想到的研究方式,因為“模式塌陷”是標準GAN的常見問題。
使用常規神經網絡技術-第二種策略是應用用于分析常規神經網絡(也是非凸型)的技術來回答有關生成對抗網絡收斂的問題。例如,有人認為深度神經網絡的非凸性不是問題,因為隨著網絡越來越大,損失函數的較差局部極小值會在指數變化中漸漸被忽略。該分析能否“引入生成對抗網絡中?事實上,對用作分類器的深部神經網絡進行分析,并觀察其是否適用于生成對抗網絡,似乎是一種具有普適性的啟發方法。
博弈論-最終策略是使用博弈論的概念對生成對抗網絡訓練建模。這些技術產生了可證明收斂到某種近似納什均衡的訓練過程,但卻使用了不合理的大資源約束。在這種情況下,下一步的工作是嘗試減少這些資源限制。
我們應如何評估生成對抗網絡,又該在何時使用它們?
在評估生成對抗網絡方面目前有很多方案,但幾乎沒有共識。建議包括:
Inception Score and FID——這兩個因素都使用預訓練的圖像分類器,并且都有已知的問題。常見批評是,這些因素衡量的是“樣本質量”,而不是“樣本多樣性”。
MS-SSIM——使用MS-SSIM來單獨評估多樣性,但這種技術存在一些問題,而且還沒有真正廣泛使用。
AIS——在生成對抗網絡輸出上建立高斯觀測模型,并使用退火算法重要性采樣來預估該模型下的對數似然,但如果生成對抗網絡發生器也是流模型的話,以這種方式計算的估計就是不準確的了。
幾何評分——計算生成的數據流形的幾何特性,并將這些特性與實際數據進行比較。
精確性和召回——嘗試測量生成對抗網絡的“精確性”和“召回率”。
技能等級——表明訓練過的生成對抗網絡鑒別器可以包含有用的信息,以便進行評估。
這些只是大家提議的生成對抗網絡評估方案的一小部分。雖然IS和FID相對比較流行,但是生成對抗網絡評估問題顯然還未解決。最后,我們認為“如何評價生成對抗網絡”這一問題源于“何時使用生成對抗網絡”這一問題。因此,我們將這兩個問題合并為一個問題:

我們應該用生成對抗網絡做什么?如果你想要的是一個真實的密度模型,生成對抗網絡可能不是最好的選擇。現在有很好的實驗證據表明,生成對抗網絡只能學習目標數據集的“低支持度”表示,這意味著生成對抗網絡測試集的絕大部分(隱含地)被指定為零概率。
與其擔心太多這個方面的事情,我們認為把生成對抗網絡的研究重點放在那些好的甚至有用的任務上更有意義。生成對抗網絡很可能非常適合感知任務,圖像合成、圖像轉換、圖像填充和屬性操作等圖形應用程序都均屬于這一概念。
我們應該如何評價這些感知任務上的生成對抗網絡?理想情況下,我們只需要一個測試評判員,但這非常昂貴。一個便宜的測試評論員只需要看分類器是否可以區分樣本中的真實和虛假。這叫做分類器雙樣本測試(C2STs)。雙樣本測試的主要問題是,哪怕發生器有一個小小的缺陷(比如說是樣本的系統性),它都會嚴重影響評估。
理想情況下,我們會有一個不受單一因素決定的整體評估。一種方法可能讓判別器對其顯性缺陷視而不見,但是一旦我們這樣做了,其他一些缺陷就有可能占主導地位,我們就又需要一個新的判別器,等等。如果我們反復這樣做,我們可以得到一種“格蘭姆-施密特步驟”,該步驟創建一個寫有最重要的缺陷和忽略它們的判別器的有序列表。也許這可以通過在判別器激活值上進行PCA(主成分分析),以及逐步剔除高方差成份來實現。
最后,我們可以在不考慮費用的情況下人為評估。這能夠驗證我們真正關心的事情。另外,我們可以通過預測人類的答案、只在預測不確定時與真人互動這種方法來降低成本。
生成對抗網絡的訓練是如何調整批量數據的Large。
較大的批量數據(minibatch)有助于擴大圖像分類,那么它們也能幫助我們擴大生成對抗網絡嗎?對于有效地使用高度類似的硬件加速器,較大的批量數據可能尤其重要。
乍一看,似乎答案應該是贊同,畢竟大多數生成對抗網絡中的鑒別器只是一個圖像分類器。如果在梯度噪聲上遇到障礙,更多的批處理(batch)可以加速訓練。然而,生成對抗網絡有一個分類器沒有的障礙:訓練過程可能會出現偏差。所以,我們可以提出一些問題:

有證據表明,增加批訓練的數量可以提高定量結果并縮短訓練時間。如果這種現象很魯棒,那就表明梯度噪聲是一個主導因素。然而,這一點還沒有得到系統的研究,所以我們相信答案依然是開放的。
其它的訓練過程能更好地利用大批量批處理嗎?理論上,最佳傳輸生成對抗網絡比普通生成對抗網絡的收斂性更好,但由于它嘗試將批處理的樣本和訓練數據相對應地對齊,所以需要較大的批處理量。因此,它似乎很有希望成為大批量處理的備選項。
最后,異步SGD可能成為充分利用新硬件的好選擇。在此設置中,限制因素主要是得根據之前的參數來計算梯度更新。但是,GAN實際上應該是受益于對之前參數的訓練,所以我們可能會問異步SGD是否以一種特殊的方式與生成對抗網絡訓練模型相互作用的。
對抗生成網絡和對抗樣本的關系是怎樣的?
眾所周知,圖像分類器會受到對抗樣本的攻擊:也就是人類無法察覺的干擾,這些干擾添加到圖像中時會導致分類器錯誤輸出。我們還知道,分類問題通常是可以有效地學習的,但難以進行可靠的指數方式學習。
由于生成對抗網絡鑒別器是一種圖像分類器,所以人們可能會擔心它遇到對抗樣本。盡管有大量關于生成對抗網絡和對抗樣本的文獻,但它們之間似乎沒有多少聯系。因此,我們可以問這樣一個問題:

我們可以從何開始考慮這個問題呢?我們先假設一個固定的鑒別器為D。如果有一個生成器得到的樣本G(z) 被認為是假,而一個小的干擾項p,比如 G(z) + p被認為是真,那么這里將會存在一個對抗樣本D。對于生成對抗網絡,我們關注的則是,生成器的梯度更新將生成一個新的生成器 G’,滿足G’(z) = G(z) + p。
這種擔心現實嗎?這說明對生成模型的蓄意攻擊可能會起作用,但我們更擔心的是某些稱為“意外攻擊”的東西。我們有理由相信這些意外攻擊存在的可能性較小。首先,生成器只允許在鑒別器再次更新之前進行一次梯度更新;相反,當前的對抗樣本通常會進行數十次的更新。
第二,根據先驗的批處理樣本,發生器進行了優化,而它的批處理樣本在每次梯度步驟中都是不同的。最后,優化是在生成器的參數下,而不是像素下進行的。然而,這些論點中沒有一個能夠真正排除產生對抗樣本的發生器。我們認為這是一個意義重大的課題,有待進一步探索。
-
圖像
+關注
關注
2文章
1089瀏覽量
40529 -
GaN
+關注
關注
19文章
1956瀏覽量
73898
原文標題:關于GAN的靈魂七問
文章出處:【微信號:smartman163,微信公眾號:網易智能】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
生成式人工智能模型的安全可信評測

AN-715::走近IBIS模型:什么是IBIS模型?它們是如何生成的?

借助谷歌Gemini和Imagen模型生成高質量圖像

巨人網絡發布“千影QianYing”有聲游戲生成大模型
大語言模型優化生成管理方法
Llama 3 模型與其他AI工具對比
生成對抗網絡(GANs)的原理與應用案例
如何用C++創建簡單的生成式AI模型
生成式AI與神經網絡模型的區別和聯系
生成式 AI 進入模型驅動時代

深度學習生成對抗網絡(GAN)全解析
KOALA人工智能圖像生成模型問世
谷歌Gemini AI模型因人物圖像生成問題暫停運行
生成式人工智能和感知式人工智能的區別
Stability AI試圖通過新的圖像生成人工智能模型保持領先地位






 工商網監
工商網監
評論