 微流體壓縮通道陣列結合機器學習識別乳腺癌細胞
微流體壓縮通道陣列結合機器學習識別乳腺癌細胞
癌癥一直以來是威脅人們生命健康的首要疾病,隨著世界范圍內科技進步發展,自身因素導致的突變和外部因素誘導的癌癥患者數量大幅提升。目前各種抗癌藥物研發和治療手段的發展在臨床應用上起到了一定程度的效果,但癌細胞的抗藥性和抗治療方法特性也在不斷改變。針對患者自身的癌細胞擴散程度建立治療方案的“個性化醫療”和“精確醫療”理念也在不斷完善和發展。精確醫療需要在診斷病人癌細胞的擴散程度和轉移能力方面達到個性化識別。
微流體技術已經廣泛應用于細胞的識別,生物物理特性檢測,以及藥物治療效果的檢測分析。很多綜述文章討論過對于微流體通道本身的制造方法和結構的改進,用來促進不同種類細胞的識別和測量。這種器件可以同時處理大量樣品,同時保證達到單細胞精度,確保單個細胞通過多級的壓縮和舒張區域,達到對細胞骨架和細胞膜生物機械特性的測量。在細胞檢測數據的分析方面,引入機器學習和人工智能算法屬于未來醫療的趨勢。在醫院診斷方面,使用人工智能算法可以綜合大量數據作為分析和學習的數據庫,可以提供更精確的數據判斷結果。
圖1:(TOC圖)微流體壓縮通道陣列識別癌細胞
微流體芯片采用光敏樹脂SU-8 3005和3025作為硅片上的光刻材料,可以制造出寬6-10微米,高8-10微米的壓縮區通道,以及寬30-40微米,高20-30微米的舒張區。首先在清潔的硅片上添加SU-83025作為第一層,使用能量為300mJ/cm2的紫外光固化。經過SU-8洗滌清洗后干燥,再添加較厚的SU-8 3025作為第二層,使用能量為350mJ/cm2的紫外光固化,洗去不需要的結果之后,用異丙醇清洗整個硅片,同時在硅膠PDMS反向注模之前保持清潔。在確保沒有多余氣泡產生的情況下,PDMS在65°C 的加熱24小時,即可取下作為微流體的主要部分。經過氧氣的等離子處理表面70秒后,可與玻璃粘合成為微流體芯片。
在壓縮區中,所有細胞都會在流體壓力的情況下發生形變,其通過速度可以有高速照相機捕捉。當細胞進入舒張區時,較容易變形的細胞,比如癌細胞,更容易恢復其原有的形狀,當進入下一個壓縮區時,二次形變發生的程度都會有第一次形變有所不同,表現為在微流體通道中,通道壁與細胞表面的切應力發生非線性的變化,因而改變通過的速度。這一速度變化可以作為標示生物機械特性的一組變量。如果進入微流體通道的是正常細胞,通常正常上皮細胞有更結實的細胞骨架結構,更不容易發生形變,而在微流體壓力作用下發生形變之后,在舒張區不容易恢復其原有形態,所以可以更快地通過第二次壓縮變形,從而顯示出與癌細胞不一樣的速度分布。根據這種速度分布,我們可以總結出單個細胞的速度特性,而這種速度特性間接地表現出細胞結構的強度和楊氏模量等參數,從而間接的識別癌細胞與正常細胞。
圖2:實驗裝置示意圖(X.Ren,et al., ACS Sensors,2017, 2 (2), 290-299)。
除此之外,對于寬度超過細胞大小的舒張區可以給細胞完全恢復原有形態的機會,我們還可以設計出相對于這種“完全舒張區”的“部分舒張區”微流體通道。現有設計中30微米以上的舒張區可以改為9-12微米的部分舒張區。當細胞在舒張區試圖恢復原有形態的時候,部分舒張區只允許細胞恢復到9-12微米的柱狀,這種形態下,不同種類的細胞會表現出與完全舒張區不同的速度分布特性。對于我們使用機器學習方法的項目,產生這種更獨特的速度分布數據只會更有利于最終的結果分析。尤其是針對臨床樣品的癌細胞研究,當檢測某種特定的抗癌藥物的藥效時,盡可能精確的區分產生藥效的和為產生藥效,或者本身已經產生抵抗藥物的現象下的癌細胞就尤為重要。采用這種多級的微流體芯片能獲取盡可能多的細胞生物機械特性數據。
圖3:(a)微流體通道示意圖;(b)采集到的細胞速度。
Kernel模型的機器學習方法可以實現針對高維變量的大數據分析。主要采用三種方法:Ridge,NGK,和Lasso。其中Ridge和Lasso都是基于線性模型,而NGK突出非線性變量在模型中的權重。采集到的細胞生物機械特性由大量的速度變量組成,同時不同運算下的速度變量又可以產生大量的高維變量。傳統的數據處理和數據分析在處理這樣大量的數據結果時不容易捕捉到有效變量和有效的變量內在關系,所以使用機器學習的方法可以用于快速,有效地識別不同類型的細胞。
選取變量是第一步,比如間接描述生物機械特性的速度變量,在一個微流體通道中可以定義12個速度變量v1, v2, … , v12。進一步可以定義速度變化率,比如αm,n=(vm-vn)/vn, (m=1,2,…,12; n=1,2,…,12),這樣就可以再產生66個變量。
首先,將所有高維變量數據分為10組,以便于交叉運算。首先考慮對每種細胞類型t,t=1,…,T,做n次測量,得到p個變量的數據組(y,Xt), 其中 Xt=[x1t,x2t,…,xpt],定義xjt=[xj1t,xj2t,…,xjnt]T是一個第j組的n×1的向量,有j=1,…,p.對于Ridge和Lasso,根據變量產生線性模型:
其中H是函數,而且有:
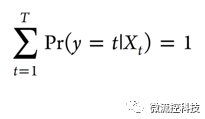
Ridge和Lasso分別采用L2絕對值||β||2和L1絕對值||β||,其中β=(β0,β1,…, βp)T。Ridge的目標函數是得到下面這個方程的最小值:
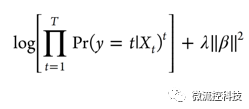
而Lasso的目標是得到下面這個方程的最小值:
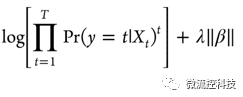
NGK與這兩種不同,NGK除了尋找高維變量的線性關系外,還加入非線性模型kernel函數,包含非顯著的隱藏變量,此模型表述為:
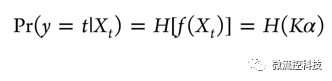
其中f(Xt)是未知函數,K是kernel矩陣對應的希爾伯特空間,而α是未知常數。這樣kernel模型可以表達為一個非線性方程:
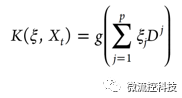
其中g是未知的高斯形態函數,Dj是第(k,l)個輸入的dklj=-(xjk-xjl)2組成的矩陣。這時選用變量ξ=(ξ0,ξ1,…, ξp),NGK的目標函數則是:
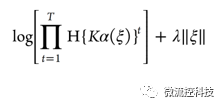
每次使用10組數據中的9組作為機器學習的訓練組,用剩余的1組作為檢驗組,通過反復選組10次,可以獲得預測值。包括最大值,最小值,Q25,Q50(中值),Q75,和平均值。
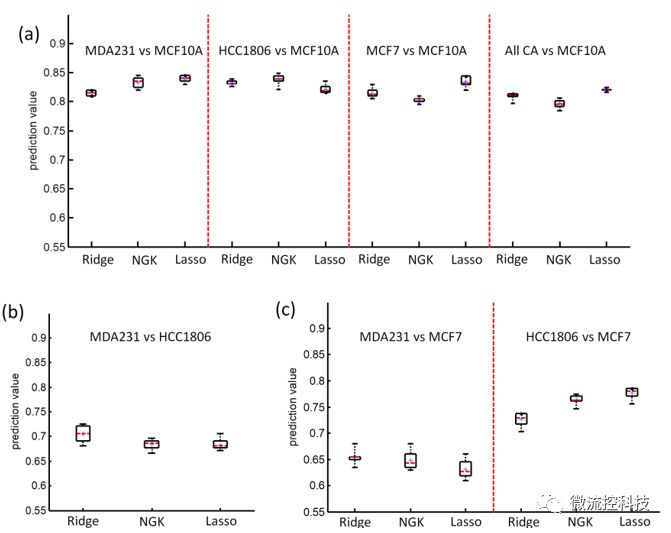
圖4:細胞系的Kernel機器學習預測結果。
僅使用16組微流體通道中細胞的速度變量作為目標的高維變量組,使用三種機器學習方法識別出的不同類型的細胞,TNBC乳腺癌細胞MDA-MB-231與普通上皮細胞MCF-10A的識別率為81-84%,其中NGK和Lasso方法比Ridge方法的結果更顯著。同樣對于TNBC的HCC-1806與普通細胞對比結果為82-85%;而ER+/PR+/Her2-的乳腺癌細胞MCF-7與普通細胞對比結果為80-84%。所以基于癌細胞和正常細胞的生物機械特性,機器學習方法就可以達到80%以上的識別率。
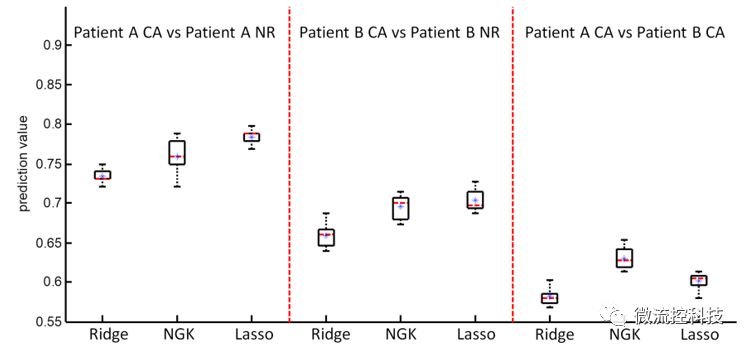
圖5:病人乳腺癌組織的Kernel機器學習預測結果。
同樣的方法應用于乳腺癌病人的活檢樣品上,由于淋巴細胞和巨噬細胞存在的情況,機器學習預測結果比細胞系較低,但仍能給活檢樣品提供轉移性和浸潤性提供數據支持。
文章信息:Xiang Ren, Parham Ghassemi, Yasmine M.Kanaan, Tammey Naab, Robert L. Copeland, Robert L. Dewitty, Inyoung Kim,Jeannine S. Strobl, and Masoud Agah. "Kernel-basedmicrofluidic constriction assay for tumor sample identification."ACS sensors,vol. 3, no. 8 (2018):1510-1521.
這篇2018年的文章延續了作者2017年發表在ACS Sensors上的文章。
-
芯片
+關注
關注
456文章
51155瀏覽量
426299 -
機器學習
+關注
關注
66文章
8438瀏覽量
132929 -
微流體
+關注
關注
0文章
35瀏覽量
8566
原文標題:微流體壓縮通道陣列結合機器學習識別乳腺癌細胞
文章出處:【微信號:Microfluidics-Tech,微信公眾號:微流控科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
HE染色乳腺癌組織病理圖像分析
DeepMind通過機器學習技術有助于改善乳腺癌
谷歌DeepMind放下圍棋 轉攻乳腺癌
英特爾攜手匯醫慧影,利用AI技術檢查乳腺癌
乳腺鉬靶AI落地臨床,乳腺癌患者的福音
如何使用機器學習方法進行乳腺癌的輔助診斷

MIT研究員最新AI模型可提前5年預測乳腺癌風險!
人工智能乳腺癌診斷能力精確 在防控乳腺癌的長期戰斗中取得突破
復旦腫瘤醫院與華米聯手研究:可穿戴設備可促進乳腺癌康復

利用微流控技術模擬骨仿生微環境促進乳腺癌進展機理研究






 工商網監
工商網監
評論