 Keras實現:用部分卷積補全圖像不規則缺損
Keras實現:用部分卷積補全圖像不規則缺損
編者按:圖像補全是一個熱門研究領域,今年4月,NVIDIA發表了一篇精彩的論文:Image Inpainting for Irregular Holes Using Partial Convolutions。文章指出,以往圖像補全技術都是用殘缺位置周邊的有效像素統計信息填充目標區域,這種做法雖然結果平滑,但存在效果不逼真、有偽像,且后期處理代價昂貴的缺點。因此他們用大量不規則掩膜圖像訓練了一個深度神經網絡,它能為圖像生成合理掩膜,再結合僅以有效像素為條件的部分卷積(Partial Convolutions),最終模型的圖像補全效果遠超前人的成果。
而近日,有網友復現了這篇論文,并在GitHub上公開了他的Keras實現,感興趣的讀者前去一看:github.com/MathiasGruber/PConv-Keras
NVIDIA論文
環境
Python 3.6
Keras 2.2.0
Tensorflow 1.8
如何使用這個repo
repo中包含的PConv2Dkeras實現可以在libs/pconv_layer.py和libs/pconv_model.py中找到。除此之外,作者還提供了四個jupyter NoteBook,詳細介紹了實現網絡時經歷的幾個步驟,即:
step 1:創建隨機不規則掩膜
step 2:實現和測試PConv2D層
step 3:實現和測試采用UNet架構的PConv2D層
step 4:在ImageNet上訓練和測試最終模型
實現細節
在設計圖像補全算法時,研究人員首先要考慮兩個因素:從哪里找到可利用的信息;怎么評判整體補全效果。無論是天然破損的圖像,還是被人為打上馬賽克的圖像,這之中都涉及圖像語義上的預測。
這篇論文發表之前,學界在圖像補全上的最先進方法之一是利用剩余圖像的像素統計信息來填充殘缺部分,這利用了同一幅圖像素間的連接性,但缺點是只反映了統計上的聯系,無法真正實現語義上的估計。后來也有人引入深度學習的方法,訓練了一個深度神經網絡,以端到端的方式學習語義先驗和有意義的隱藏表示,但它仍局限于初始值,而且使用的是固定的替換值,效果依然不佳。
NVIDIA在論文中提出了一種新技巧:添加部分卷積層(Partial Convolutional Layer),并在這一層之后加上一個掩膜更新步驟。部分卷積層包含生成掩膜和重新歸一化,它類似圖像語義分割任務中的segmentation-aware convolutional(分段感知卷積),能在不改變輸入掩膜的情況下分割圖像信息。
簡而言之,給定給定一個二元掩膜,部分卷積層的卷積結果只取決于每一層的非殘缺區域。相比segmentation-aware convolutional,NVIDIA的創新之處是自動掩膜更新步驟,它可以消除部分卷積能夠在非掩膜值上操作的任何掩膜。
具體設計過程可以閱讀論文查看,下面我們只總結一些細節。
生成掩膜
為了訓練能生成不規則掩模的深度神經網絡,論文研究人員截取視頻中的兩個連續幀,用遮擋/解除遮擋創建了大量不規則掩膜,雖然他們在論文中稱將公開這個數據集,但現在我們還找不到相關資源。
在這個Keras實現中,作者簡單創建了一個遮擋生成函數,用OpenCV繪制一些隨機的不規則形狀,以此作為掩膜數據,效果目前看來還不錯。
部分卷積層
這個實現中最關鍵的部分就是論文的重點“部分卷積層”。基本上,給定卷積filter W和相應的偏差b,部分卷積的形式是:
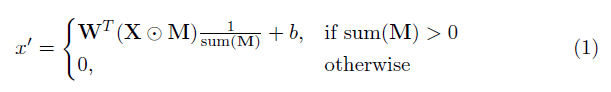
其中⊙表示點乘,即每個矩陣元素對應相乘,M是由0和1構成的二進制掩碼。在每次完成部分卷積操作后,掩膜要進行一輪更新。這意味著如果卷積能夠在至少一個有效輸入上調節其輸出,則在該位置移除掩碼:
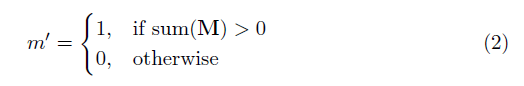
這樣做的結果是,在網絡夠深的情況下,最終掩碼將全部為0(消失)。
UNet架構
下圖是論文中提供的PConv整體架構,它類似UNet,只不過其中所有正常的卷積層都被部分卷積層代替,使圖像+掩膜無論何時都能一起通過網絡
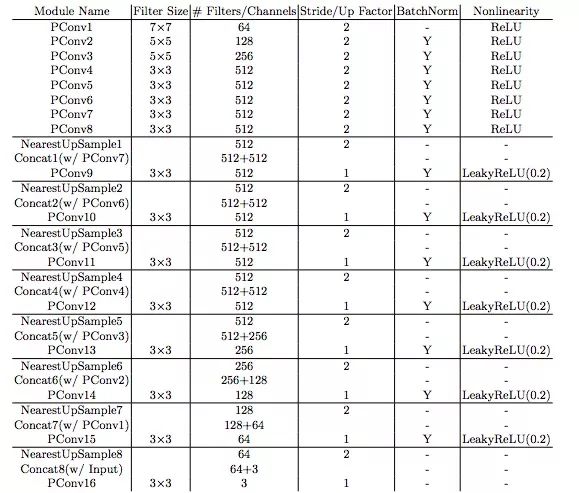
PConv整體架構
PConv彩色圖解
損失函數
論文涉及的損失非常多樣,簡而言之,它包括:
掩膜區(Lhole)和非掩膜區(Lvalid)的每個像素損失
基于ImageNet預訓練的VGG-16(pool1, pool2 and pool3 layers)的感知損失(Lperceptual)
VGG-16在預測圖像(Lstyleout)和計算圖像(Lstylecomp)上的風格損失(以非殘缺區像素為真實值)
殘缺區域每個像素擴張的總變差損失(Ltv),也就是1像素擴張區域的平滑懲罰
以上損失的權重如下:
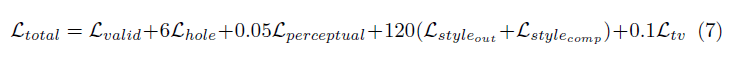
論文補全效果
下圖是論文中呈現的圖像補全效果,其中第一列是輸入圖像,第二列是GntIpt算法的輸出,第三列是NVIDIA論文的結果,第四列是真實完整圖像。可以發現,無論圖像缺失區域有多不規則,PConv的補全效果在顏色、紋理、形狀上都更逼真,也更平滑流暢。
小結
最后一點,也是最重要的一點,如果是在單個1080Ti上訓練模型,batch size為4,模型訓練總用時大約在10天左右,這是個符合論文所述的數據。所以如果有讀者想上手實踐,記得提前做好硬件和時間上的準備。
-
神經網絡
+關注
關注
42文章
4778瀏覽量
101018 -
圖像
+關注
關注
2文章
1089瀏覽量
40529 -
深度學習
+關注
關注
73文章
5511瀏覽量
121392
原文標題:Keras實現:用部分卷積補全圖像不規則缺損
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
教你設計不規則形狀的PCB
創建不規則窗體和控件
labview前面板部分透明,不規則界面
一種基于距離變換的不規則區域匹配算法
一種新的對不規則珠寶圖像的自動檢測方法
線積分卷積技術的詳細資料說明

基于密集卷積生成對抗網絡的圖像修復方法
基于生成式對抗網絡的圖像補全方法
OpenCV初學者如何提取這些不規則的ROI區域
基于差分卷積神經網絡的低照度車牌圖像增強網絡






 工商網監
工商網監
評論