 寶信利用Spark Analytics Zoo對基于LSTM的時間序列異常檢測的探索
寶信利用Spark Analytics Zoo對基于LSTM的時間序列異常檢測的探索
摘要:寶信和英特爾相關團隊利用Analytics Zoo在無監督的基于時間序列異常檢測用例上進行了有益的合作探索,本文分享了合作項目的結果和經驗。
背景----
在工業制造行業,有多種方法來避免由于設備失效導致的生產中斷。常見的方法是定期檢修維護,或者提前更換設備零部件,這些方法都可能會增加設備維護和更換的投入。然而,另一個可行的方法是收集不同設備的大量振動數據,并使用這些數據自動檢測設備狀態的異常。因此,有效地收集大量的時間序列數據并且大規模地進行異常和失效檢測,對于降低工業制造行業中的的很多不必要的成本是非常關鍵的。
Recurrent neural networks (RNNs)循環神經網絡,特別是Long short term memory models (LSTMs)長短期記憶模型現在被廣泛應用于信號處理,時間序列分析等場景。作為connectionist模型,RNNs可以提取網絡節點中的動態序列。在這個項目中,我們利用LSTM來模擬震動信號的統計學規律, 并且使用了來自辛辛那提大學的IMS全生命周期數據 (http://ti.arc.nasa.gov/c/3/)來展示設備異常檢測的分析流程。
Analytics Zoo解決方案
Analytics Zoo (https://github.com/intel-analytics/analytics-zoo)是一個基于Apache Spark和BigDL等構建的analytics (分析)+AI(人工智能)的平臺,由英特爾開源,該平臺能夠方便地讓用戶將端到端的基于大數據的深度學習應用直接部署在已有的Hadoop/Spark的大數據集群上,而無需安裝專用的GPU設備。
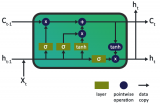
我們已經在Apache Spark和Analytics Zoo上創建了端到端的基于LSTM的異常檢測流程,可以應用于大規模時間序列數據的無監督深度學習。作為LSTM模型的輸入數據的是一系列設備震動信號,比如在當前時間點之前50秒的信號數據,通過這些信號數據,經過訓練的模型可以預測下一個數據點。當下一個數據點和模型預測的數據點有較大偏差,我們認為該數據為異常數據。圖1所示為一個端到端的數據處理流程。
| 圖1:基于Analytics Zoo的振動時間序列異常檢測處理流程. |
1. 處理流程從Spark集群讀取原始數據并構造RDD(resilient distributed datasets)彈性分布式數據集,并抽取特征,最后把特征輸出到Dataframe。在原始數據集中,每個數據描述了一個檢測失效(test-to-failure)的實驗,并包含了時長為1秒的20K赫茲采樣的即時振動信號(如圖2所示)。為了訓練深度學習模型,每一秒的統計數據被提取作為特征數據,包括均方根(Root Mean Square), 峰度(Kurtosis),峰值( Peak), 以及小波包分解得到的8個頻段的能量值。
2. 處理流程進一步在RDD中處理這些特征數據,包括數值的小波去噪處理、標準化處理(normalize)和滑動平均處理,以50秒為基準展開特征數據序列,以便于深度學習模型可以通過前50秒的模式來預測下一個數據點,并最終把數據轉換為Sample RDD。(https://bigdl-project.github.io/master/#APIGuide/Data/#sample).
3. 處理流程使用Analytics Zoo中提供的類Keras API來創建時間序列異常檢測模型,包括如圖所示的三個LSTM層和一個密集層,并通過數據訓練這個模型(前50個點訓練下一個點)。
val model = Sequential[Float]() model.add(LSTM[Float](8, returnSequences = true, inputShape = inputShape)) model.add(Dropout[Float](0.2)) model.add(LSTM[Float](32, returnSequences = true)) model.add(Dropout[Float](0.2)) model.add(LSTM[Float](15, returnSequences = false)) model.add(Dropout[Float](0.2)) model.add(Dense[Float](outputDim = 1))
4. 接下來是模型評估:使用測試數據或者全部數據來檢測異常。異常數據是指遠離RNN模型預測的數據點。在這個項目中,我們指定異常數據為整體數據集的10%,也就是距離模型預測數值最遠的那10%數據為異常數據。這個篩選比例設置為可調整參數,可以為每個單獨案例進行調整。
| 圖2:時間點2004.02.13.14.32.39上四通道的振動數據 |
測試結果
圖3顯示了原始振動數據和LSTM模型預測數據的對比。只有峰值和均方根這兩個統計數值顯示出來,其他統計數值具有相似的波動。圖中所示紅點為被識別的異常數據,橙色線條為LSTM模型的預測數值,藍色線條為原始數值。經過訓練的模型最終成功預測了設備的失效,以及在經過600個時間點之后的震動尖峰,在時間序列早期的一些波動可以作為設備失效的預警信息。
|
a), peak |
|
b), RMS |
| 圖3: RNN預測數值和原始震動數值的比較 |
結論
通過利用無監督深度學習,以及Analytics Zoo提供的端到端處理流程,我們可以有效地在大數據集和標準大數據集群(Hadoop, Spark等)上應用時間序列異常檢測。通過收集、處理大量的時間序列數據(比如日志,傳感器讀數等),應用RNN來學習數據模式,最終預判數據和判定異常數據,Analytics Zoo提供的端到端處理流程能夠為許多新興的智能系統如智能制造、智能運維、物聯網等提供解決方案。基于時間序列的異常檢測在設備的智能監控和
預測性維護上可以得到重要應用。
參考文獻
1. https://github.com/intel-analytics/analytics-zoo
2. https://github.com/intel-analytics/BigDL
3. https://www.kaggle.com/victorambonati/unsupervised-anomaly-detection
4. https://iwringer.wordpress.com/2015/11/17/anomaly-detection-concepts-and-techniques/
-
Hadoop
+關注
關注
1文章
90瀏覽量
15998 -
Apache
+關注
關注
0文章
64瀏覽量
12479 -
SPARK
+關注
關注
1文章
105瀏覽量
19938
發布評論請先 登錄
相關推薦
基于Intel Analytics Zoo上分布式TensorFlow的美的/KUKA工業檢測平臺
【「時間序列與機器學習」閱讀體驗】全書概覽與時間序列概述
【《時間序列與機器學習》閱讀體驗】+ 了解時間序列
介紹有關時間序列預測和時間序列分類
怎樣去搭建一套用于多步時間序列預測的LSTM架構?
如何基于Keras和Tensorflow用LSTM進行時間序列預測
Analytics Zoo: 統一的大數據分析+AI 平臺

一種多維時間序列汽車駕駛異常點檢測模型
一種新的無監督時間序列異常檢測方法
智能電網時間序列異常檢測:a survey

時間序列分析的異常檢測綜述





 工商網監
工商網監
評論