 三種不同的3D數據表示的基本深度學習方法
三種不同的3D數據表示的基本深度學習方法
導讀:我們將專注于最近的深度學習技術,這些技術支持3D對象分類和語義分割。我們將首先回顧一些有關捕獲和表示3D數據的常用方法的背景信息。然后,我們將描述三種不同的3D數據表示的基本深度學習方法。最后,我們將描述有前途的新研究方向,并總結我們對該領域前進方向的看法。
假設你正在建造一輛需要了解周圍環境的自動駕駛汽車。為了能夠感知行人、騎自行車的人和周圍的其他車輛以便安全行駛,你將如何設計你的汽車?你可以使用相機,但這似乎并不特別有效,因為相機拍出來的照片是2D的,而你只能將3D“擠壓”為從相機捕獲的2D圖像,然后你嘗試從2D圖像信息(比如到你前面的行人或汽車的距離)中恢復實際的3D環境信息。通過將3D環境壓縮到2D圖像,你將丟棄對你最重要的許多信息。嘗試將這些信息重新組合在一起很困難,即使對于最先進的算法,也容易出錯。
相反,最好是能夠使用3D數據擴充你的2D世界視圖。你可以直接通過傳感器找到這些物體,而不是嘗試估算2D圖像與行人或其他車輛的距離。但現在感知這一部分是比較困難的。你如何在3D數據中真正識別人?如騎自行車的人和汽車等物體。傳統的深度學習技術,如卷積神經網絡(CNN),可以使這些物體在2D圖像中直接識別,需要適應3D工作。幸運的是,在過去的幾年里,人們已經對3D中的感知問題進行了相當多的研究,我們在本文中的任務是簡要概述這項工作。
特別是,我們將專注于最近的深度學習技術,這些技術支持3D對象分類和語義分割。我們將首先回顧一些有關捕獲和表示3D數據的常用方法的背景信息。然后,我們將描述三種不同的3D數據表示的基本深度學習方法。最后,我們將描述有前途的新研究方向,并總結我們對該領域前進方向的看法。
我們如何捕獲和表示3D數據?
很明顯,我們需要能夠直接在3D中運行的計算機視覺方法,但這提出了三個明顯的挑戰:感知,表示和理解3D數據。
感知
捕獲3D數據的過程很復雜。雖然2D相機便宜且廣泛,但3D感測通常需要專門的硬件設置。
立體視覺利用多臺攝像機,通過測量被感知物體位置的變化來計算深度信息(來源:愛丁堡大學)
1、立體視覺將兩個或以上攝像機相對于彼此固定在特定位置,并使用此設置捕獲場景的不同圖像,匹配相應的像素,并計算每個像素在圖像之間的位置差異以計算其在3D空間中的位置。這大致是人類感知世界的方式 - 我們的眼睛捕捉到現實世界中兩個獨立的“圖像”,然后我們的大腦會看到物體的位置在我們的左眼和右眼之間的位置如何不同以確定其3D位置。立體視覺很有吸引力,因為它涉及的硬件很簡單 - 只有兩個或以上普通相機。然而,在精度或速度很重要的應用中,這種方法并不是很好。
RGB-D相機輸出包含顏色信息和每像素深度的四通道圖像(來源:九州大學)
2、RGB-D涉及使用除了彩色圖像(“RGB”)之外還捕獲深度信息(“D”)的特殊類型的相機。具體來說,它捕獲了從普通2D相機獲得的相同類型的彩色圖像,但是,對于某些像素子集,它還會告訴你相機前面的距離。在內部,大多數RGB-D傳感器通過“結構光”進行工作,該結構光將紅外圖案投射到場景上并感知該圖案如何扭曲到幾何表面上,或者“飛行時間”,其觀察投射的紅外光多長時間需要返回相機。你可能聽說過的一些RGB-d相機包括?微軟Kinect?和iPhone X的?面部識別?傳感器。RGB-D很棒,因為這些傳感器相對較小且成本較低,卻很快速且不受視覺匹配誤差的影響。然而,由于遮擋(前景中的物體阻擋投影到其后面的物體上),RGB-D相機的深度輸出通常會有許多孔,圖案感應失敗和范圍問題(投影和感應都變得難以遠離相機)。
LIDAR使用多個激光束(同心圓感應)直接感知環境的幾何結構(來源:Giphy)
3、LiDAR涉及在物體上發射快速激光脈沖并測量它們返回傳感器所花費的時間。這類似于我們上面描述的RGB-D相機的“飛行時間”技術,但是LiDAR具有明顯更長的距離,捕獲更多的點,并且對來自其他光源的干擾更加具有魯棒性。如今,大多數3D LiDAR傳感器都是多線(最多64線)光束垂直對齊、可以快速旋轉,以便在傳感器周圍的所有方向上看到。這些是大多數自動駕駛汽車中使用的傳感器,因為它們的精度、范圍和堅固性,但是LiDAR傳感器的問題在于它們通常很大,很重且非常昂貴(?64光束傳感器)?大多數自動駕駛汽車的使用成本為75,000美元)。其結果是,許多公司正在努力開發更便宜的?“固態激光雷達”?系統,可以在3D感知,而不必旋轉。
3D表示
一旦捕獲了3D數據,你需要以一種有意義的方式表示它,作為您正在構建的處理管道的輸入。您應該知道四種主要表示形式:
3D數據的不同表示。(a)點云(來源:Caltech),(b)體素網格(來源:IIT Kharagpur),(c)三角網格(來源:UW),(d)多視圖表示(來源:斯坦福)
a、點云只是3D空間中點的集合;每個點由(xyz)位置指定,可與一些其他屬性(如rgb顏色)一起指定。它們是捕獲LiDAR數據的原始形式,立體和RGB-D數據(由標記為每像素深度值的圖像組成)通常在進一步處理之前轉換為點云。
b、體素網格源自點云。“體素”就像3D中的像素;將體素網格視為量化的固定大小的點云。雖然點云可以在空間中的任何位置具有無限數量的點與浮點像素坐標,但是體素網格是3D網格,其中每個單元格或“體素”具有固定大小和離散坐標。
c、多邊形網格由一組多邊形面組成,這些面具有接近幾何表面的共享頂點。將點云視為來自底層連續幾何表面的采樣3D點的集合;多邊形網格旨在以易于渲染的方式表示那些底層表面。雖然最初是為計算機圖形創建的,但多邊形網格也可用于3D視覺。有幾種方法可以從點云中獲得多邊形網格,包括Kazhdan等人的泊松曲面重構。
d、多視圖表示是從不同的模擬視點(“虛擬相機”)捕獲的渲染多邊形網格的2D圖像的集合,以便以簡單的方式傳達3D幾何。簡單地從多個攝像機(如立體聲)捕獲圖像和構建多視圖表示之間的區別在于多視圖需要實際構建完整的3D模型并從幾個任意視點渲染它以完全傳達底層幾何。與上面用于存儲和處理3D數據的其他三種表示不同,多視圖表示通常僅用于將3D數據轉換為用于處理或可視化的簡單格式。
理解
既然已經將3D數據轉換為易于理解的格式,那么你就需要構建一個計算機視覺管道來理解它。這里的問題是,根據數據的表示,擴展在2D圖像(如CNN)上運行良好的傳統深度學習技術可能很難處理,使得諸如對象檢測或分段之類的傳統任務具有挑戰性。
學習多視圖輸入
使用3D數據的多視圖表示是使2D深度學習技術適應3D的最簡單方法。這是將3D感知問題轉換為2D感知問題的一種聰明方式,但仍然允許您推斷對象的3D幾何結構。使用這種想法的早期基于深度學習的工作是Su等人的多視圖CNN一種簡單而有效的架構,可以從3D對象的多個2D視圖中學習特征描述符。與將單個2D圖像用于對象分類任務相比,該方法實現了該方法,提高了性能。這是通過將單個圖像輸入到在ImageNet上預訓練的VGG網絡來實現的,以便提取顯著特征,匯集這些產生的激活圖,并將該信息傳遞到附加的卷積層以進行進一步的特征學習。
多視圖CNN架構
但是,多視圖圖像表示具有許多限制。主要問題是你并沒有真正學習3D -固定數量的2D視圖仍然只是底層3D結構的不完美近似。因此,由于從2D圖像獲得的有限特征信息,諸如語義分割之類的任務(尤其是在更復雜的對象和場景上)的任務變得具有挑戰性。此外,這種可視化3D數據的形式對于計算受限的任務(如自動駕駛和虛擬現實)而言不可擴展 - 請記住,生成多視圖表示需要渲染完整的3D模型并模擬多個任意視點。最終,多視圖學習面臨許多缺點,這些缺點促使研究直接從3D數據學習的方法。
學習體積表示法
使用體素網格進行學習可以解決多視圖表示的主要缺點。體素網格彌合了2D和3D視覺之間的差距- 它們是最接近圖像的3D表示,使得將2D深度學習概念(如卷積算子)與3D相匹配變得相對容易。Maturana和Scherer的VoxNet是第一個在給定體素網格輸入的情況下在對象分類任務上獲得令人信服的結果的深度學習方法之一。VoxNet對概率占用網格進行操作,其中每個體素包含該體素在空間中占據的概率。該方法的益處在于其允許網絡區分已知自由的體素(例如,LiDAR束穿過的體素)和占用未知的體素(例如,LiDAR束撞擊的體素后面的體素)。
VoxNet架構
VoxNet的架構本身非常簡單,由兩個卷積層,一個最大池層和兩個完全連接的層組成,用于計算輸出類別得分向量。與大多數最先進的圖像分類網絡相比,該網絡更淺,參數更少,但它是從數百種可能的CNN架構的隨機搜索中選擇的。由于體素網格與圖像非常相似,因此它們采用的實際跨步卷積和合并算子是這些算子從2D像素到3D體素的簡單修改;卷積運算符使用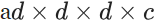 內核而不是內核
內核而不是內核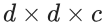 在2D CNN中使用的內核,并且池操作符考慮體素的非重疊3D塊而不是2D像素塊。
在2D CNN中使用的內核,并且池操作符考慮體素的非重疊3D塊而不是2D像素塊。
VoxNet的一個問題是該體系結構本身并不是旋轉不變的。雖然作者合理地假設傳感器保持直立,以便體素網格的軸與重力方向對齊,關于旋轉的旋轉不能做出這樣的假設 來自后面的對象仍然是同一個對象,即使體素網格中的幾何圖形與學習的卷積內核非常不同地相互作用。為了解決這個問題,他們采用了簡單的數據增強策略。在訓練過程中,他們多次旋轉每個模型并訓練所有副本;然后,在測試時,它們將最終完全連接層的輸出匯集到輸入的幾個旋轉中。他們指出,與匯集中間卷積層的輸出(如Su等人)相比,這種方法導致了類似的性能,但收斂速度更快。多視圖CNN在他們的“視圖池”步驟中,通過這種方式,VoxNet通過在輸入體素網格的不同旋轉上共享相同的學習卷積核權重來學習旋轉不變性。
來自后面的對象仍然是同一個對象,即使體素網格中的幾何圖形與學習的卷積內核非常不同地相互作用。為了解決這個問題,他們采用了簡單的數據增強策略。在訓練過程中,他們多次旋轉每個模型并訓練所有副本;然后,在測試時,它們將最終完全連接層的輸出匯集到輸入的幾個旋轉中。他們指出,與匯集中間卷積層的輸出(如Su等人)相比,這種方法導致了類似的性能,但收斂速度更快。多視圖CNN在他們的“視圖池”步驟中,通過這種方式,VoxNet通過在輸入體素網格的不同旋轉上共享相同的學習卷積核權重來學習旋轉不變性。
VoxNet代表了邁向真正3D學習的重要一步,但體素網格仍然存在許多缺點。首先,與點云相比,它們會失去分辨率,因為如果它們靠近在一起,則表示復雜結構的幾個不同點將被分類到一個體素中。同時,與稀疏環境中的點云相比,體素網格可能導致不必要的高內存使用,因為它們主動消耗內存來表示自由和未知空間,而點云僅包含已知點。
點云學習
PointNet
鑒于基于體素的方法存在這些問題,最近的工作主要集中在直接在原始點云上運行的架構上。最值得注意的是,Qi等人的 PointNet(2016)是最早提出的處理這種形式的不規則三維數據的方法之一。然而,正如作者所指出的,點云只是一組由xyz位置以3D表示的點。更具體地說,給定在點云中,網絡需要學習不變的獨特功能 輸入數據的排列,因為饋入網絡的點的排序不會影響基礎幾何。此外,網絡應該對點云的變換具有魯棒性 - 旋轉,平移和縮放不應影響預測。
為了確保輸入排序的不變性,PointNet背后的關鍵洞察力是使用簡單的對稱函數,為輸入的任何排序產生一致的輸出(此類函數中的示例包括加法和乘法)。在這種直覺的指導下,PointNet架構背后的基本模塊(稱為PointNet Vanilla)定義如下:

這里是是一個對稱函數,將輸入點轉換為維向量(用于對象分類)。這個功能可以近似,使得存在另一個對稱函數,在等式中是一個多層感知器(MLP),它將各個輸入點(及其相應的特征,如xyz位置,顏色,表面法線等)映射到更高維度的潛在空間。max-pooling操作用作對稱函數,將學習的特征聚合到點云的全局描述符中。傳遞這個單一特征向量另一個輸出對象預測的MLP。
為了解決學習對點云幾何變換不變的表示的挑戰,PointNet采用了一種稱為T-Net的迷你網絡,它將仿射變換應用于輸入點云。這個概念類似于Jaderberg等人的空間變壓器網絡。但更簡單,因為不需要定義新類型的圖層。T-Net由可學習的參數組成,使PointNet能夠將輸入點云轉換為固定的規范空間 - 確保整個網絡即使是最輕微的變化也能保持穩健。
PointNet架構
整個PointNet架構將vanilla方法和T-Net與多個MLP層集成在一起,為層云創建特征表示。然而,除了對象分類之外,PointNet還支持對象和場景的語義分割。為實現此目的,該體系結構將來自最大池對稱函數的全局特征向量與輸入數據通過幾個MLP后學習的每點特征相結合。通過連接這兩個向量,每個點都知道其全局語義和本地特征,使網絡能夠學習更有意義的功能,以幫助進行分段。
使用PointNet的室內場景的語義分割結果
PointNet ++
盡管PointNet取得了令人矚目的成果,但其中一個主要缺點是架構無法捕獲點鄰域內的底層局部結構- 這一想法類似于使用CNN從圖像中增加感知域大小來提取特征。為了解決這個問題,齊等開發了PointNet ++(2017),從PointNet架構衍生出來,但也能夠在點云中學習本地區域的功能。這種方法背后的基礎是一個分層特征學習層,它有三個關鍵步驟。它(1)采樣點作為局部區域的質心,(2)基于距質心的距離對這些局部區域中的相鄰點進行分組,以及(3)使用迷你PointNet對這些區域的特征進行編碼。
逐步重復這些步驟,以便在點云內的不同大小的點組中學習特征。通過這樣做,網絡可以更好地理解整個點云中本地點集群內的底層關系 - 最終有助于提高泛化性能。這項工作的結果表明,PointNet ++能夠對包括PointNet在內的現有方法進行重大改進,并在3D點云分析基準測試(ModelNet40和ShapeNet)上實現了最先進的性能。
有希望的新研究領域—圖CNN
目前關于處理三維數據的深度學習架構的研究主要集中在點云表示上,最近的大部分工作都是從PointNet / PointNet ++擴展思路,并從其他領域中汲取靈感,以進一步提高性能。一篇這樣的論文的例子是Wang等人的動態圖形細胞神經網絡(2018),其使用基于圖的深度學習方法來改進點云中的特征提取。想法是PointNet和PointNet ++無法捕獲各個點之間的幾何關系,因為這些方法需要保持不同輸入排列的不變性。然而,通過考慮一個點并將它作為有向圖周圍的最近鄰居,Wang等人。構造EdgeConv,一個在數據中的點之間生成唯一特征的運算符。
SPLATNet
SPLATNet架構
另一方面,一些研究已經遠離PointNet / PointNet ++中提出的經典特征提取方法,選擇設計一種處理點云的新方法。蘇等人的SPLATNet(2018)體系結構是點云研究中這一新焦點的一個很好的例子 - 作者設計了一種新穎的體系結構和卷積運算符,而不是直接在點云上運行。本文背后的關鍵見解是將“感受野”的概念轉化為不規則點云,這使得即使在稀疏區域也能保留空間信息(PointNet / PointNet ++的一個關鍵缺點)。特別令人著迷的是,SPLATNet可以將從多視圖圖像中提取的特征投影到3D空間中,將這些2D數據與端到端可學習架構中的原始點云融合在一起。使用這種2D-3D聯合學習,SPLATNet實現了語義分割的最新技術。
Frustum PointNets
可視化從2D邊界框估計生成的3D平截頭體
第三個有希望的研究方向涉及擴展我們上面描述的基本架構構建塊,以構建更復雜的網絡,用于3D等物體檢測等有用任務。基于使用2D和3D數據的想法,Qi等人的 Frustum PointNets(2017)提出了一種融合RGB圖像和點云的新方法,以提高在大型3D場景中定位對象的效率。用于該任務的常規方法通過直接在整個點云上對滑動窗口執行分類來確定對象的可能3D邊界框,這在計算上是昂貴的并且使得實時預測變得困難。齊等人做出兩個關鍵貢獻。
首先,他們建議最初使用標準CNN在2D圖像上進行物體檢測,擠出對應于檢測到的物體可能存在的點云區域的3D平截頭體,然后僅對此“切片”執行搜索過程。點云。這顯著縮小了邊界框估計的搜索空間,降低了錯誤檢測的可能性并大大加快了處理流水線,這對于自動駕駛應用至關重要。
其次,Qi等人不是在邊界框搜索過程中執行典型的滑動窗口分類。設計一種新穎的基于PointNet的架構,可以直接執行實例分割(將點云分割成單個對象),并在一次通過中對整個3D平截頭體進行邊界框估計,使得它們的方法對于遮擋和稀疏性都快速且穩健。最終,作為這些改進的結果,這項工作在出版KITTI和SUN RGB-D 3D檢測基準時的表現優于所有先前的方法。
一點想法
在過去的5年中,3D深度學習方法已經從使用派生(多視圖)到3D數據的原始(點云)表示。在此過程中,我們已經從簡單適應2D CNN的方法轉變為3D數據(多視圖CNN甚至VoxNet),再到手工制作3D(PointNet和其他點云方法)的方法,大大提高了任務的性能喜歡對象分類和語義分割。這些結果很有希望,因為它們證實了在3D中觀察和表現世界確實有價值。
然而,這一領域的進步才剛剛開始。當前的工作不僅側重于提高這些算法的準確性和性能,還側重于確保穩健性和可擴展性。雖然目前的大部分研究都是由自主車輛應用推動的,但直接在點云上運行的新方法將在3D醫學成像、虛擬現實和室內地圖中發揮重要作用。
-
3D
+關注
關注
9文章
2910瀏覽量
107800 -
自動駕駛
+關注
關注
784文章
13923瀏覽量
166831 -
深度學習
+關注
關注
73文章
5512瀏覽量
121414
原文標題:自動駕駛技術之——3D感知環境的深度學習方法
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

深度學習的三種基本結構及原理詳解

深度解析機器學習三類學習方法
深度學習的三種學習模式介紹
深度學習:四種利用少量標注數據進行命名實體識別的方法
傳統CV和深度學習方法的比較

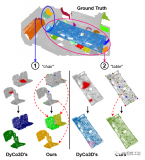
兩種應用于3D對象檢測的點云深度學習方法






 工商網監
工商網監
評論