

導(dǎo)讀
近年來,深度學(xué)習(xí)方法在特征抽取深度和模型精度上表現(xiàn)優(yōu)異,已經(jīng)超過了傳統(tǒng)方法,但無論是傳統(tǒng)機(jī)器學(xué)習(xí)還是深度學(xué)習(xí)方法都依賴大量標(biāo)注數(shù)據(jù)來訓(xùn)練模型,而現(xiàn)有的研究對(duì)少量標(biāo)注數(shù)據(jù)學(xué)習(xí)問題探討較少。本文將整理介紹四種利用少量標(biāo)注數(shù)據(jù)進(jìn)行命名實(shí)體識(shí)別的方法。
面向少量標(biāo)注數(shù)據(jù)的NER方法分類
基于規(guī)則、統(tǒng)計(jì)機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的方法在通用語料上能取得良好的效果,但在特定領(lǐng)域、小語種等缺乏標(biāo)注資源的情況下,NER 任務(wù)往往得不到有效解決。然而遷移學(xué)習(xí)利用領(lǐng)域相似性,在領(lǐng)域之間進(jìn)行數(shù)據(jù)共享和模型共建,為少量標(biāo)注數(shù)據(jù)相關(guān)任務(wù)提供理論基礎(chǔ)。本文從遷移的方法出發(fā),按照知識(shí)的表示形式不同,將少量標(biāo)注數(shù)據(jù)NER 方法分為基于數(shù)據(jù)增強(qiáng)、基于模型遷移、基于特征變換、基于知識(shí)鏈接的方法。如圖1所示,在這 20 多年間,四種方法的發(fā)文數(shù)量基本呈上升趨勢,整體而言,當(dāng)前的研究以數(shù)據(jù)增強(qiáng)、模型遷移為主,而其他的方法通常配合前兩種方法使用,在研究中也值得關(guān)注。
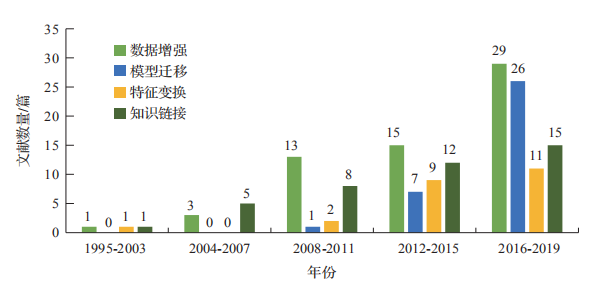
圖1 1995年-2019年四種方法的使用情況
基于數(shù)據(jù)增強(qiáng)的NER方法
數(shù)據(jù)增強(qiáng)的方法即:在少量數(shù)據(jù)集訓(xùn)練模型導(dǎo)致過擬合時(shí),通過樣本選擇、權(quán)重調(diào)整等策略以創(chuàng)建高質(zhì)量樣本集,再返回分類器中迭代學(xué)習(xí),使之能夠較好地完成學(xué)習(xí)任務(wù)的方法。
(1)樣本選擇。在面向少量標(biāo)注數(shù)據(jù)時(shí),最直接的策略是挑選出高質(zhì)量樣本以擴(kuò)大訓(xùn)練數(shù)據(jù)。其中,樣本選擇是數(shù)據(jù)增強(qiáng)式 NER 的核心模塊,它通過一定的度量準(zhǔn)則挑選出置信度高、信息量大的樣本參與訓(xùn)練,一種典型的思路為主動(dòng)學(xué)習(xí)采樣,例如 Shen 等利用基于“不確定性”標(biāo)準(zhǔn),通過挖掘?qū)嶓w內(nèi)蘊(yùn)信息來提高數(shù)據(jù)質(zhì)量。在實(shí)踐中,對(duì)于給定的序列 X=(x1, x2,…xi) 和標(biāo)記序列Y=(y1, y2,…yi),x 被預(yù)測為 Y 的不確定性可以用公式(1)來度量,其中 P(y) 為預(yù)測標(biāo)簽的條件分布概率,M 為標(biāo)簽的個(gè)數(shù),n 為序列的長度:
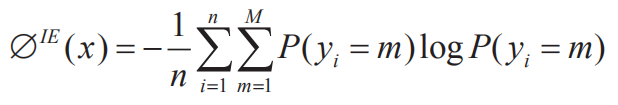
為了驗(yàn)證主動(dòng)學(xué)習(xí)采樣的性能,在人民日?qǐng)?bào)(1998 年)語料中進(jìn)行實(shí)驗(yàn),共迭代十次,其中 Random 為迭代中隨機(jī)采樣,ALL 為一次訓(xùn)練完所有數(shù)據(jù)的結(jié)果,Active-U 為利用數(shù)據(jù)增強(qiáng)的結(jié)果。實(shí)驗(yàn)結(jié)果(如圖 2)表明,利用數(shù)據(jù)增強(qiáng)方法在第 7 次迭代中就能達(dá)到擬合,節(jié)省了 30% 的標(biāo)注成本。
圖2基于數(shù)據(jù)增強(qiáng)方法的實(shí)例
也有不同學(xué)者利用其他的度量準(zhǔn)則,例如高冰濤等人通過評(píng)估源域樣本在目標(biāo)領(lǐng)域中的貢獻(xiàn)度,并使用單詞相似性和編輯距離,在源域樣本集和目標(biāo)樣本集上計(jì)算權(quán)值來實(shí)現(xiàn)迭代學(xué)習(xí)。Zhang 等人充分考慮領(lǐng)域相似性,分別進(jìn)行域區(qū)分、域依賴和域相關(guān)性計(jì)算來度量。這些方法利用無監(jiān)督模式通過降低統(tǒng)計(jì)學(xué)習(xí)的期望誤差來對(duì)未標(biāo)記樣本進(jìn)行優(yōu)化選擇,能夠有效減少標(biāo)注數(shù)據(jù)的工作量。此外,半監(jiān)督采樣也是一種新的思路。例如在主動(dòng)學(xué)習(xí)的基礎(chǔ)上加入自學(xué)習(xí)(Self-Training)、自步學(xué)習(xí)(Self-Paced Learning,SPL)過程,這些方式通過對(duì)噪聲樣本增大學(xué)習(xí)難度,由易到難地控制選擇過程,讓樣本選擇更為精準(zhǔn)。
(2)分類器集成。在數(shù)據(jù)增強(qiáng)中,訓(xùn)練多個(gè)弱分類器來獲得一個(gè)強(qiáng)分類器的學(xué)習(xí)方式也是一種可行的思路。其中典型的為 Dai 等人提出集成式 TrAdaBoost 方法,它擴(kuò)展了 AdaBoost 方法,在每次迭代的過程中,通過提高目標(biāo)分類樣本的采樣權(quán)重、降低誤分類實(shí)例樣本的權(quán)重來提高弱分類器的學(xué)習(xí)能力。TrAdaBoost 利用少量的標(biāo)簽數(shù)據(jù)來構(gòu)建對(duì)源域標(biāo)簽數(shù)據(jù)的樣本增強(qiáng),最后通過整合基準(zhǔn)弱分類器為一個(gè)強(qiáng)分類器來進(jìn)行訓(xùn)練,實(shí)現(xiàn)了少樣本數(shù)據(jù)的學(xué)習(xí)。之后的研究針對(duì) TrAdaBoost 進(jìn)行了相應(yīng)的改進(jìn)也取得了不錯(cuò)的效果。例如,王紅斌等人在分類器集成中增加遷移能力參數(shù),讓模型充分表征語義信息,在 NER 中提高精度也能顯著減少標(biāo)注成本。
基于模型遷移的NER方法
基于模型遷移的基本框架如圖 3 所示,其核心思想是利用分布式詞表示構(gòu)建詞共享語義空間,然后再遷移神經(jīng)網(wǎng)絡(luò)的參數(shù)至目標(biāo)領(lǐng)域,這是一種固定現(xiàn)有模型特征再進(jìn)行微調(diào)(Fine-Tuning) 的方法,在研究中共享詞嵌入和模型參數(shù)的遷移對(duì) NER 性能產(chǎn)生較大影響。
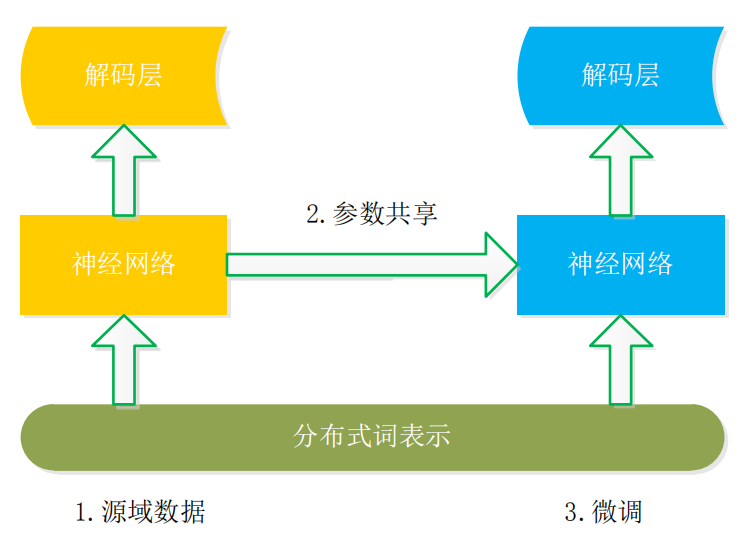
圖3模型遷移基本結(jié)構(gòu)
(1)共享詞嵌入。在 NLP 中,前期工作通常會(huì)借助語言預(yù)訓(xùn)練模型學(xué)習(xí)文本的詞義信息,這種方式構(gòu)建了公共的詞嵌入表示空間,詞嵌入在 NER 中通常作為輸入。詞向量是共享詞嵌入的初步形式,此后,ELMo模型利用上下文信息的方式能解決傳統(tǒng)詞向量不擅長的一詞多義問題,還能在一定程度上對(duì)詞義進(jìn)行預(yù)測逐漸受到人們關(guān)注。而 2018 年谷歌提出的 BERT預(yù)訓(xùn)練模型更是充分利用了詞義和語義特性,BERT 是以雙向 Transformer為編碼器棧的語言模型,它能強(qiáng)有力地捕捉潛在語義和句子關(guān)系,基于 BERT 的 NER 在多個(gè)任務(wù)上也取得 state-of-the-art,其基本網(wǎng)絡(luò)結(jié)構(gòu)如圖4所示。
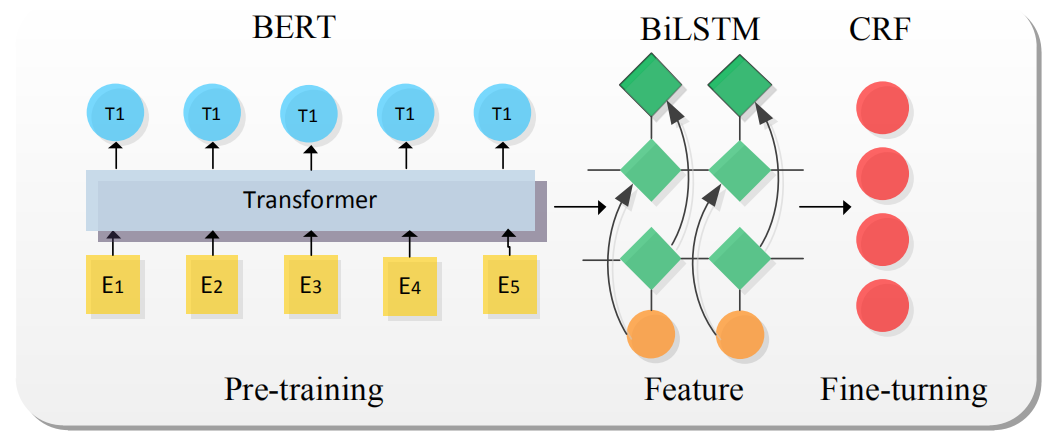
圖4模型遷移的基礎(chǔ)方法-BERT-BiLSTM-CRF
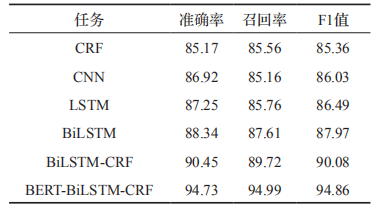
其中 BERT 作為語義表示輸入,BiLSTM抽取特征,CRF 獲取概率最大標(biāo)簽。與傳統(tǒng)的NER 模型相比,該模型最關(guān)鍵的是 BERT 語言模型的引入,BERT 通過無監(jiān)督建模的方式學(xué)習(xí)海量互聯(lián)網(wǎng)語義信息,能充分表征實(shí)體的語義信息。在人民日?qǐng)?bào)(1998年)語料中進(jìn)行實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果(如表 1)表明,基于 BERT 的預(yù)訓(xùn)練遷移學(xué)習(xí)模型能有效提高分類的準(zhǔn)確率。
表1BERT-BiLSTM-CRF與其他方法的比較
(2)共享參數(shù)。共享詞嵌入側(cè)重于詞義的表示,而共享參數(shù)則側(cè)重于模型參數(shù)的遷移。例如,Jason 等人從神經(jīng)網(wǎng)絡(luò)遷移機(jī)制以及遷移哪些層進(jìn)行大量實(shí)驗(yàn),實(shí)驗(yàn)結(jié)論顯示淺層網(wǎng)絡(luò)學(xué)習(xí)知識(shí)的通用特征,具有很好的泛化能力,當(dāng)遷移到第 3 層時(shí)性能達(dá)到飽和,繼續(xù)遷移會(huì)導(dǎo)致“負(fù)遷移”的產(chǎn)生。Giorgi 等人基 于 LSTM 進(jìn)行網(wǎng)絡(luò)權(quán)重的遷移,首先將源領(lǐng)域模型參數(shù)遷移至目標(biāo)領(lǐng)域初始化,之后進(jìn)行微調(diào)使適應(yīng)任務(wù)需要。而 Yang 等人從跨領(lǐng)域、跨應(yīng)用、跨語言遷移出發(fā)測試模型遷移的可行性, 在 一 些 benchmarks 上實(shí)現(xiàn)了 state-of-the-art。整體而言,在處理 NER 任務(wù)時(shí)良好的語義空間結(jié)合深度模型將起到不錯(cuò)的效果,在遷移過程中模型層次的選擇和適應(yīng)是難點(diǎn)。
基于特征變換的NER方法
在面向少量標(biāo)注數(shù)據(jù) NER 任務(wù)時(shí),我們希望遷移領(lǐng)域知識(shí)以實(shí)現(xiàn)數(shù)據(jù)的共享和模型的共建,在上文中我們從模型遷移的角度出發(fā),它們?cè)诮鉀Q領(lǐng)域相近的任務(wù)時(shí)表現(xiàn)良好,但當(dāng)領(lǐng)域之間存在較大差異時(shí),模型無法捕獲豐富、復(fù)雜的跨域信息。因此,在跨領(lǐng)域任務(wù)中,一種新的思路是在特征變換上改進(jìn),從而解決領(lǐng)域數(shù)據(jù)適配性差的問題。基于特征變換的方法是通過特征互相轉(zhuǎn)移或者將源域和目標(biāo)域的數(shù)據(jù)特征映射到統(tǒng)一特征空間,來減少領(lǐng)域之間差異的學(xué)習(xí)過程,下面主要從特征選擇和特征映射的角度進(jìn)行探討。
(1)特征選擇。即通過一定的度量方法選取相似特征并轉(zhuǎn)換,在源域和目標(biāo)域之間構(gòu)建有效的橋梁的策略。例如 Daume 等人通過特征空間預(yù)處理實(shí)現(xiàn)目標(biāo)域和源域特征組合,在只有兩個(gè)域的任務(wù)中,擴(kuò)展特征空間 R^F 至 R^3F,對(duì)應(yīng)于域問題,擴(kuò)展特征空間至 R^(K+1)F。然而當(dāng) Yi 與 YJ 標(biāo)簽空間差異較大時(shí),這種線性組合效果可能不理想,Kim 等人從不同的角度出發(fā),進(jìn)行標(biāo)簽特征的變換,第一種是將細(xì)粒度標(biāo)簽泛化為粗粒度標(biāo)簽。例如源域標(biāo)簽中
(2)特征映射。即為了減少跨領(lǐng)域數(shù)據(jù)的偏置,在不同領(lǐng)域之間構(gòu)建資源共享的特征空間,并將各領(lǐng)域的初始特征映射到該共享空間上。利用預(yù)測的源標(biāo)簽嵌入至目標(biāo)領(lǐng)域是一種常見策略。例如,Qu 等人從領(lǐng)域和標(biāo)簽差異出發(fā),首先訓(xùn)練大規(guī)模源域數(shù)據(jù),再度量源域和目標(biāo)域?qū)嶓w類型相關(guān)性,最后通過模型遷移的方式微調(diào)。其基本步驟為:
1、通過 CRF學(xué)習(xí)大規(guī)模數(shù)據(jù)的知識(shí);
2、使用雙層神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)源域與目標(biāo)域的命名實(shí)體的相關(guān)性;
3、利用 CRF 訓(xùn)練目標(biāo)域的命名實(shí)體。
實(shí)驗(yàn)結(jié)果顯示相較于 Baseline 方法 Deep-CRF,TransInit 方法能提高 160% 的性能。
標(biāo)簽嵌入的方式在領(lǐng)域之間有較多共享標(biāo)簽特征時(shí)遷移效果不錯(cuò),但是這種假設(shè)在現(xiàn)實(shí)世界中并不普遍。一種新的思路是在編解碼中進(jìn)行嵌入適配(如圖 5),這種方式利用來自預(yù)訓(xùn)練源模型的參數(shù)初始化 Bi-LSTM-CRF 基礎(chǔ)模型,并嵌入詞語、句子和輸入級(jí)適配。具體而言,在詞級(jí)適配中,嵌入核心領(lǐng)域詞組以解決輸入特征空間的領(lǐng)域漂移現(xiàn)象。在句子級(jí)適配中,根據(jù)來自目標(biāo)域的標(biāo)記數(shù)據(jù),映射學(xué)習(xí)過程中捕獲的上下文信息。在輸出級(jí)適配中將來自 LSTM 層輸出的隱藏狀態(tài)作為其輸入,為重構(gòu)的 CRF 層生成一系列新的隱藏狀態(tài),進(jìn)而減少了知識(shí)遷移中的損失。
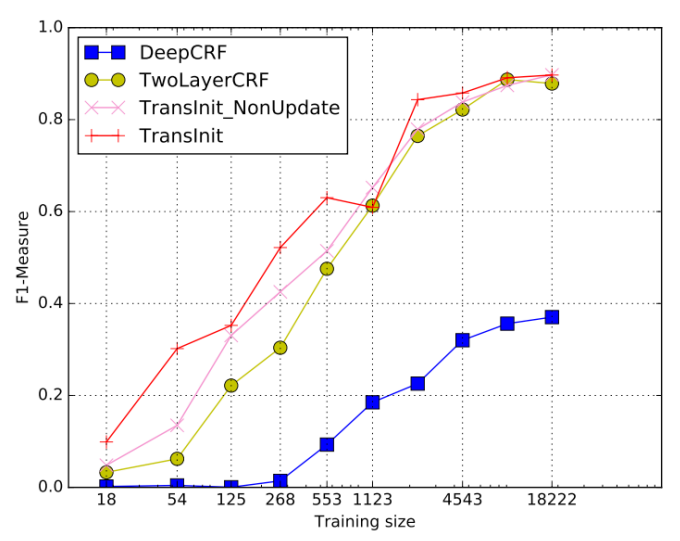
圖5特征變換方法TransInit實(shí)驗(yàn)結(jié)果
基于知識(shí)鏈接的NER方法
基于知識(shí)鏈接的 NER,即使用本體、知識(shí)庫等結(jié)構(gòu)化資源來啟發(fā)式地標(biāo)記數(shù)據(jù),將數(shù)據(jù)的結(jié)構(gòu)關(guān)系作為共享對(duì)象,從而幫助解決目標(biāo) NER 任務(wù),其本質(zhì)上是一種基于遠(yuǎn)程監(jiān)督的學(xué)習(xí)方式,利用外部知識(shí)庫和本體庫來補(bǔ)充標(biāo)注實(shí)體。例如 Lee 等人的框架(如圖 6),在 Distant supervision 模塊,將文本序列與 NE詞典中的條目進(jìn)行匹配,自動(dòng)為帶有 NE 類別的大量原始語料添加標(biāo)簽,然后利用 bagging和主動(dòng)學(xué)習(xí)完善弱標(biāo)簽語料,從而實(shí)現(xiàn)語料的精煉。一般而言,利用知識(shí)庫和本體庫中的鏈接信息和詞典能實(shí)現(xiàn)較大規(guī)模的信息抽取任務(wù),這種方法有利于快速實(shí)現(xiàn)任務(wù)需求。
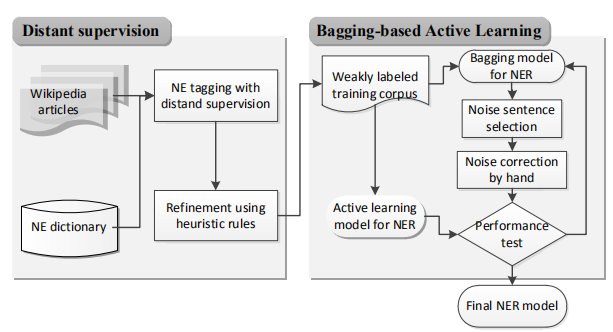
圖6知識(shí)鏈接與數(shù)據(jù)增強(qiáng)結(jié)合模型
(1)基于知識(shí)庫。這種方式通常借用外部的知識(shí)庫來處理 NER、關(guān)系抽取、屬性抽取等任務(wù),在現(xiàn)實(shí)世界中如 Dbpedia、YAGO、百度百科等知識(shí)庫存在海量結(jié)構(gòu)化信息,利用這些知識(shí)庫的結(jié)構(gòu)化信息框、日志信息可以抽取出海量知識(shí)。例如,Richman 等人利用維基百科知識(shí)設(shè)計(jì)了一種 NER 的系統(tǒng),這種方法利用維基百科類別鏈接將短語與類別集相關(guān)聯(lián),然后確定短語的類型。類似地,Pan 等人利用一系列知識(shí)庫挖掘方法為 200 多種語言開發(fā)了一種跨語言的名稱標(biāo)簽和鏈接結(jié)構(gòu)。在實(shí)踐中,較為普遍的是聯(lián)合抽取實(shí)體和實(shí)體關(guān)系。例如Ren 等的做法,該方法重點(diǎn)解決領(lǐng)域上下文
無關(guān)和遠(yuǎn)程監(jiān)督中的噪聲問題,其基本步驟為:
1、利用 POS 對(duì)文本語料進(jìn)行切割以獲得提及的實(shí)體;
2、生成實(shí)體關(guān)系對(duì);
3、捕獲實(shí)體與實(shí)體關(guān)系的淺層語法及語義特征;
4、訓(xùn)練模型并抽取正確的實(shí)體及關(guān)系。
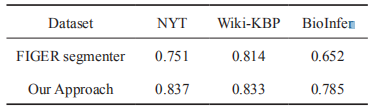
在 NYT 等語料上進(jìn)行實(shí)驗(yàn)(如表 2),基于知識(shí)庫的方法相較于基線方法有顯著提高。
表2不同語料下實(shí)體的F1值
(2)基于本體系統(tǒng)。該方式通過一定的規(guī)則,將本體庫中的概念映射為實(shí)體。例如史樹敏等人通過構(gòu)建的 MPO 本體,首先利用CRF 獲得高召回率的實(shí)體,再融合規(guī)則過濾噪聲,最終獲得較為精確的匹配模式。相似地,Lima 等人通過開發(fā)出 OntoLPER 本體系統(tǒng),并利用較高的表達(dá)關(guān)系假設(shè)空間來表示與實(shí)體—實(shí)體關(guān)系結(jié)構(gòu),在這個(gè)過程中利用歸納式邏輯編程產(chǎn)生抽取規(guī)則,這些抽取規(guī)則從基
于圖表示的句子模型中抽取特定的實(shí)體和實(shí)體關(guān)系實(shí)例。同樣地,李貫峰等人首先從 Web網(wǎng)頁提取知識(shí)構(gòu)建農(nóng)業(yè)領(lǐng)域本體,之后將本體解析的結(jié)果應(yīng)用在 NER 任務(wù)中,使得 NER 的結(jié)果更為準(zhǔn)確。這些方法利用本體中的語義結(jié)構(gòu)和解析器完成實(shí)體的標(biāo)準(zhǔn)化,在面向少量標(biāo)注的 NER 中也能發(fā)揮出重要作用。
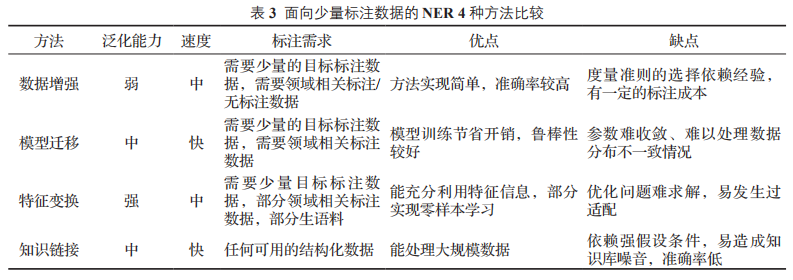
四種方法比較
上述所介紹的 4 種面向少量標(biāo)注的 NER 方法各有特點(diǎn),本文從領(lǐng)域泛化能力、模型訓(xùn)練速度、對(duì)標(biāo)注數(shù)據(jù)的需求和各方法的優(yōu)缺點(diǎn)進(jìn)行了細(xì)致地比較,整理分析的內(nèi)容如表 3 所示。
面向少量標(biāo)注數(shù)據(jù) NER,最直接的方法是數(shù)據(jù)增強(qiáng),通過優(yōu)先挑選高質(zhì)量樣本參與訓(xùn)練,這種方法在窄域中能實(shí)現(xiàn)較高的準(zhǔn)確率。但是針對(duì)不同領(lǐng)域所需的策略也不同,領(lǐng)域的泛化能力一般。模型遷移從海量無結(jié)構(gòu)化文本中獲取知識(shí),這種方式對(duì)目標(biāo)領(lǐng)域的數(shù)據(jù)需求較少,只需“微調(diào)”模型避免了重新訓(xùn)練的巨大開銷,但是它依賴領(lǐng)域的強(qiáng)相關(guān)性,當(dāng)領(lǐng)域差異性太大時(shí),容易產(chǎn)生域適應(yīng)問題。
相較于模型遷移,特征變換更加注重細(xì)粒度知識(shí)表示,這種方法利用特征重組和映射,豐富特征表示,減少知識(shí)遷移中的損失,在一定程度上能實(shí)現(xiàn)“零樣本”學(xué)習(xí),但是這種方法往往難以求出優(yōu)化解,過適配現(xiàn)象也會(huì)造成消極影響。知識(shí)鏈接能利用任何結(jié)構(gòu)化信息,通過知識(shí)庫、本體庫中的語義關(guān)系來輔助抽取目標(biāo)實(shí)體,但是這種方法易產(chǎn)生噪聲,實(shí)體的映射匹配依賴強(qiáng)假設(shè)條件,所需的知識(shí)庫通常難以滿足領(lǐng)域?qū)嶓w的抽取。
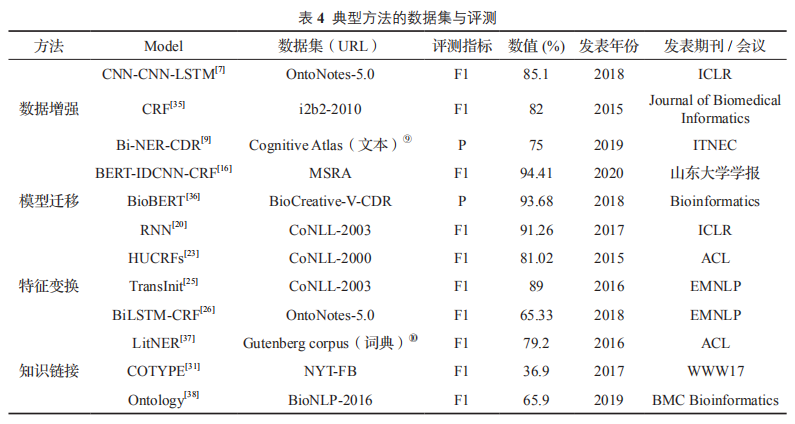
方法評(píng)測比較
如表4所示四類面向少量標(biāo)注數(shù)據(jù)的典型方法與評(píng)測信息如下:
結(jié)語
當(dāng)有大量標(biāo)注數(shù)據(jù)可供模型訓(xùn)練時(shí),NER任務(wù)往往能夠得到很好的結(jié)果。但是在一些專業(yè)領(lǐng)域比如生物醫(yī)藥領(lǐng)域,標(biāo)注數(shù)據(jù)往往非常稀缺,又由于其領(lǐng)域的專業(yè)性,需要依賴領(lǐng)域?qū)<疫M(jìn)行數(shù)據(jù)標(biāo)注,這將大大增加數(shù)據(jù)的標(biāo)注成本。而如果只用少量的標(biāo)注數(shù)據(jù)就能得到同等效果甚至更好的效果,這將有利于降低數(shù)據(jù)標(biāo)注成本。
參考資料:
[1]石教祥,朱禮軍,望俊成,王政,魏超.面向少量標(biāo)注數(shù)據(jù)的命名實(shí)體識(shí)別研究[J].情報(bào)工程,2020,6(04):37-50.
責(zé)任編輯:xj
原文標(biāo)題:綜述 | 少量標(biāo)注數(shù)據(jù)下的命名實(shí)體識(shí)別研究
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7232瀏覽量
90714 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5546瀏覽量
122281 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22408
原文標(biāo)題:綜述 | 少量標(biāo)注數(shù)據(jù)下的命名實(shí)體識(shí)別研究
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
風(fēng)華電容命名方法深度解析
標(biāo)貝數(shù)據(jù)標(biāo)注案例分享:車載語音系統(tǒng)數(shù)據(jù)標(biāo)注

ASR與傳統(tǒng)語音識(shí)別的區(qū)別
AI大模型與深度學(xué)習(xí)的關(guān)系
深度識(shí)別算法包括哪些內(nèi)容
pwm脈寬調(diào)制的四種方法有哪些
負(fù)反饋的四種類型及判斷方法
圖像識(shí)別算法都有哪些方法
基于Python的深度學(xué)習(xí)人臉識(shí)別方法
深度學(xué)習(xí)中的時(shí)間序列分類方法
深度學(xué)習(xí)中的無監(jiān)督學(xué)習(xí)方法綜述
人臉檢測與識(shí)別的方法有哪些
車載語音識(shí)別系統(tǒng)語音數(shù)據(jù)采集標(biāo)注案例





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論