 dropout帶來的模型的變化
dropout帶來的模型的變化
開篇明義,dropout是指在深度學習網絡的訓練過程中,對于神經網絡單元,按照一定的概率將其暫時從網絡中丟棄。注意是暫時,對于隨機梯度下降來說,由于是隨機丟棄,故而每一個mini-batch都在訓練不同的網絡。
dropout是CNN中防止過擬合提高效果的一個大殺器,但對于其為何有效,卻眾說紛紜。在下讀到兩篇代表性的論文,代表兩種不同的觀點,特此分享給大家。
▌組合派
參考文獻中第一篇中的觀點,Hinton老大爺提出來的,關于Hinton在深度學習界的地位我就不再贅述了,光是這地位,估計這一派的觀點就是“武當少林”了。注意,派名是我自己起的,各位勿笑。
▌觀點
該論文從神經網絡的難題出發,一步一步引出dropout為何有效的解釋。大規模的神經網絡有兩個缺點:
費時
容易過擬合
這兩個缺點真是抱在深度學習大腿上的兩個大包袱,一左一右,相得益彰,額不,臭氣相投。過擬合是很多機器學習的通病,過擬合了,得到的模型基本就廢了。而為了解決過擬合問題,一般會采用ensemble方法,即訓練多個模型做組合,此時,費時就成為一個大問題,不僅訓練起來費時,測試起來多個模型也很費時。總之,幾乎形成了一個死鎖。
Dropout的出現很好的可以解決這個問題,每次做完dropout,相當于從原始的網絡中找到一個更瘦的網絡,如下圖所示:
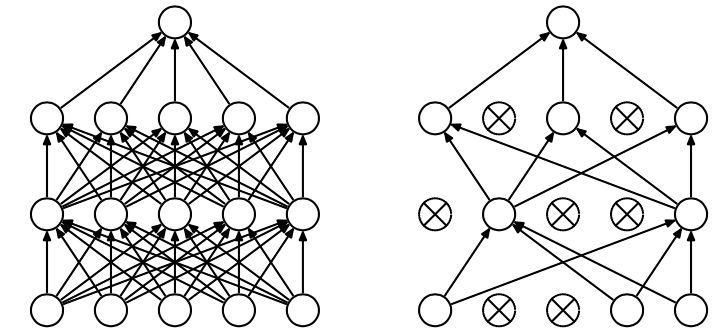
因而,對于一個有N個節點的神經網絡,有了dropout后,就可以看做是2n個模型的集合了,但此時要訓練的參數數目卻是不變的,這就解脫了費時的問題。
▌動機論
雖然直觀上看dropout是ensemble在分類性能上的一個近似,然而實際中,dropout畢竟還是在一個神經網絡上進行的,只訓練出了一套模型參數。那么他到底是因何而有效呢?這就要從動機上進行分析了。論文中作者對dropout的動機做了一個十分精彩的類比:
在自然界中,在中大型動物中,一般是有性繁殖,有性繁殖是指后代的基因從父母兩方各繼承一半。但是從直觀上看,似乎無性繁殖更加合理,因為無性繁殖可以保留大段大段的優秀基因。而有性繁殖則將基因隨機拆了又拆,破壞了大段基因的聯合適應性。
但是自然選擇中畢竟沒有選擇無性繁殖,而選擇了有性繁殖,須知物競天擇,適者生存。我們先做一個假設,那就是基因的力量在于混合的能力而非單個基因的能力。不管是有性繁殖還是無性繁殖都得遵循這個假設。為了證明有性繁殖的強大,我們先看一個概率學小知識。
比如要搞一次恐怖襲擊,兩種方式:
集中50人,讓這50個人密切精準分工,搞一次大爆破。
將50人分成10組,每組5人,分頭行事,去隨便什么地方搞點動作,成功一次就算。
哪一個成功的概率比較大? 顯然是后者。因為將一個大團隊作戰變成了游擊戰。
那么,類比過來,有性繁殖的方式不僅僅可以將優秀的基因傳下來,還可以降低基因之間的聯合適應性,使得復雜的大段大段基因聯合適應性變成比較小的一個一個小段基因的聯合適應性。
dropout也能達到同樣的效果,它強迫一個神經單元,和隨機挑選出來的其他神經單元共同工作,達到好的效果。消除減弱了神經元節點間的聯合適應性,增強了泛化能力。
個人補充一點:那就是植物和微生物大多采用無性繁殖,因為他們的生存環境的變化很小,因而不需要太強的適應新環境的能力,所以保留大段大段優秀的基因適應當前環境就足夠了。而高等動物卻不一樣,要準備隨時適應新的環境,因而將基因之間的聯合適應性變成一個一個小的,更能提高生存的概率。
▌dropout帶來的模型的變化
而為了達到ensemble的特性,有了dropout后,神經網絡的訓練和預測就會發生一些變化。
訓練層面
無可避免的,訓練網絡的每個單元要添加一道概率流程。

對應的公式變化如下如下:
沒有dropout的神經網絡

dropout的神經網絡
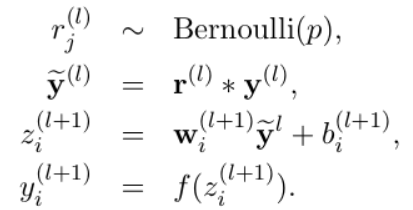
測試層面
預測的時候,每一個單元的參數要預乘以p。

▌論文中的其他技術點
防止過擬合的方法:
提前終止(當驗證集上的效果變差的時候)
L1和L2正則化加權
soft weight sharing
dropout
dropout率的選擇
經過交叉驗證,隱含節點dropout率等于0.5的時候效果最好,原因是0.5的時候dropout隨機生成的網絡結構最多。
dropout也可以被用作一種添加噪聲的方法,直接對input進行操作。輸入層設為更接近1的數。使得輸入變化不會太大(0.8)
訓練過程
對參數w的訓練進行球形限制(max-normalization),對dropout的訓練非常有用。
球形半徑c是一個需要調整的參數。可以使用驗證集進行參數調優
dropout自己雖然也很牛,但是dropout、max-normalization、large decaying learning rates and high momentum組合起來效果更好,比如max-norm regularization就可以防止大的learning rate導致的參數blow up。
使用pretraining方法也可以幫助dropout訓練參數,在使用dropout時,要將所有參數都乘以1/p。
部分實驗結論
該論文的實驗部分很豐富,有大量的評測數據。
maxout 神經網絡中得另一種方法,Cifar-10上超越dropout
文本分類上,dropout效果提升有限,分析原因可能是Reuters-RCV1數據量足夠大,過擬合并不是模型的主要問題
dropout與其他standerd regularizers的對比
L2 weight decay
lasso
KL-sparsity
max-norm regularization
dropout
特征學習
標準神經網絡,節點之間的相關性使得他們可以合作去fix其他節點中得噪聲,但這些合作并不能在unseen data上泛化,于是,過擬合,dropout破壞了這種相關性。在autoencoder上,有dropout的算法更能學習有意義的特征(不過只能從直觀上,不能量化)。
產生的向量具有稀疏性。
保持隱含節點數目不變,dropout率變化;保持激活的隱節點數目不變,隱節點數目變化。
數據量小的時候,dropout效果不好,數據量大了,dropout效果好。
模型均值預測
使用weight-scaling來做預測的均值化
使用mente-carlo方法來做預測。即對每個樣本根據dropout率先sample出來k個net,然后做預測,k越大,效果越好。
Multiplicative Gaussian Noise
使用高斯分布的dropout而不是伯努利模型dropout
dropout的缺點就在于訓練時間是沒有dropout網絡的2-3倍。
進一步需要了解的知識點
dropout RBM
Marginalizing Dropout
具體來說就是將隨機化的dropout變為確定性的,比如對于Logistic回歸,其dropout相當于加了一個正則化項。
Bayesian neural network對稀疏數據特別有用,比如medical diagnosis, genetics, drug discovery and other computational biology applications
▌噪聲派
參考文獻中第二篇論文中得觀點,也很強有力。
觀點
觀點十分明確,就是對于每一個dropout后的網絡,進行訓練時,相當于做了Data Augmentation,因為,總可以找到一個樣本,使得在原始的網絡上也能達到dropout單元后的效果。 比如,對于某一層,dropout一些單元后,形成的結果是(1.5,0,2.5,0,1,2,0),其中0是被drop的單元,那么總能找到一個樣本,使得結果也是如此。這樣,每一次dropout其實都相當于增加了樣本。
稀疏性
知識點A
首先,先了解一個知識點:
When the data points belonging to a particular class are distributed along a linear manifold, or sub-space, of the input space, it is enough to learn a single set of features which can span the entire manifold. But when the data is distributed along a highly non-linear and discontinuous manifold, the best way to represent such a distribution is to learn features which can explicitly represent small local regions of the input space, effectively “tiling” the space to define non-linear decision boundaries.
大致含義就是:
在線性空間中,學習一個整個空間的特征集合是足夠的,但是當數據分布在非線性不連續的空間中得時候,則學習局部空間的特征集合會比較好。
知識點B
假設有一堆數據,這些數據由M個不同的非連續性簇表示,給定K個數據。那么一個有效的特征表示是將輸入的每個簇映射為特征以后,簇之間的重疊度最低。使用A來表示每個簇的特征表示中激活的維度集合。重疊度是指兩個不同的簇的Ai和Aj之間的Jaccard相似度最小,那么:
當K足夠大時,即便A也很大,也可以學習到最小的重疊度
當K小M大時,學習到最小的重疊度的方法就是減小A的大小,也就是稀疏性。
上述的解釋可能是有點太專業化,比較拗口。主旨意思是這樣,我們要把不同的類別區分出來,就要是學習到的特征區分度比較大,在數據量足夠的情況下不會發生過擬合的行為,不用擔心。但當數據量小的時候,可以通過稀疏性,來增加特征的區分度。
因而有意思的假設來了,使用了dropout后,相當于得到更多的局部簇,同等的數據下,簇變多了,因而為了使區分性變大,就使得稀疏性變大。
為了驗證這個數據,論文還做了一個實驗,如下圖:

該實驗使用了一個模擬數據,即在一個圓上,有15000個點,將這個圓分為若干個弧,在一個弧上的屬于同一個類,一共10個類,即不同的弧也可能屬于同一個類。改變弧的大小,就可以使屬于同一類的弧變多。
實驗結論就是當弧長變大時,簇數目變少,稀疏度變低。與假設相符合。
個人觀點:該假設不僅僅解釋了dropout何以導致稀疏性,還解釋了dropout因為使局部簇的更加顯露出來,而根據知識點A可得,使局部簇顯露出來是dropout能防止過擬合的原因,而稀疏性只是其外在表現。
論文中的其他技術知識點
將dropout映射回得樣本訓練一個完整的網絡,可以達到dropout的效果。
dropout由固定值變為一個區間,可以提高效果
將dropout后的表示映射回輸入空間時,并不能找到一個樣本x*使得所有層都能滿足dropout的結果,但可以為每一層都找到一個樣本,這樣,對于每一個dropout,都可以找到一組樣本可以模擬結果。
dropout對應的還有一個dropConnect,公式如下:
dropout
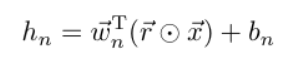
ropConnect
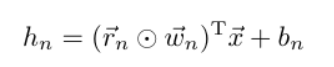
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101052 -
Dropout
+關注
關注
0文章
13瀏覽量
10060
原文標題:詳解 | Dropout為何能防止過擬合?
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Dropout如何成為SDR的特殊情況
關于Dropout、BN及數據預處理方案
手勢帶來什么變化
TF之CNN:利用sklearn使用dropout解決學習中overfitting的問題+Tensorboard顯示變化曲線
請問LM337IMP的Dropout Voltage是多少?
dropout正則化技術介紹
理解神經網絡中的Dropout
基于動態dropout的改進堆疊自動編碼機方法
一種針對街景變化檢測的神經網絡模型
改進Hinton的Dropout:可以用來減輕欠擬合了
AI大模型,將為智慧城市帶來哪些新變化?
訓練大語言模型帶來的硬件挑戰






 工商網監
工商網監
評論